庖丁解 InnoDB 之 Redolog
數據庫故障恢復機制的前世今生一文中提到,今生磁盤數據庫為了在保證數據庫的原子性(A, Atomic) 和持久性(D, Durability)的同時,還能以靈活的刷盤策略來充分利用磁盤順序寫的性能,會記錄REDO和UNDO日志,即ARIES方法。本文將重點介紹REDO LOG的作用,記錄的內容,組織結構,寫入方式等內容,希望讀者能夠更全面準確的理解REDO LOG在InnoDB中的位置。本文基于MySQL 8.0代碼。
一、為什么需要記錄REDO
為了取得更好的讀寫性能,InnoDB會將數據緩存在內存中(InnoDB Buffer Pool),對磁盤數據的修改也會落后于內存,這時如果進程或機器崩潰,會導致內存數據丟失,為了保證數據庫本身的一致性和持久性,InnoDB維護了REDO LOG。修改Page之前需要先將修改的內容記錄到REDO中,并保證REDO LOG早于對應的Page落盤,也就是常說的WAL,Write Ahead Log。當故障發生導致內存數據丟失后,InnoDB會在重啟時,通過重放REDO,將Page恢復到崩潰前的狀態。
二、需要什么樣的REDO
那么我們需要什么樣的REDO呢?首先,REDO的維護增加了一份寫盤數據,同時為了保證數據正確,事務只有在他的REDO全部落盤才能返回用戶成功,REDO的寫盤時間會直接影響系統吞吐,顯而易見,REDO的數據量要盡量少。其次,系統崩潰總是發生在始料未及的時候,當重啟重放REDO時,系統并不知道哪些REDO對應的Page已經落盤,因此REDO的重放必須可重入,即REDO操作要保證冪等。最后,為了便于通過并發重放的方式加快重啟恢復速度,REDO應該是基于Page的,即一個REDO只涉及一個Page的修改。
熟悉的讀者會發現,數據量小是Logical Logging的優點,而冪等以及基于Page正是Physical Logging的優點,因此InnoDB采取了一種稱為Physiological Logging的方式,來兼得二者的優勢。所謂Physiological Logging,就是以Page為單位,但在Page內以邏輯的方式記錄。舉個例子,MLOG_REC_UPDATE_IN_PLACE類型的REDO中記錄了對Page中一個Record的修改,方法如下:
- (Page ID,Record Offset,(Filed 1, Value 1) ... (Filed i, Value i) ... )
其中,PageID指定要操作的Page頁,Record Offset記錄了Record在Page內的偏移位置,后面的Field數組,記錄了需要修改的Field以及修改后的Value。
由于Physiological Logging的方式采用了物理Page中的邏輯記法,導致兩個問題:
1、需要基于正確的Page狀態上重放REDO
由于在一個Page內,REDO是以邏輯的方式記錄了前后兩次的修改,因此重放REDO必須基于正確的Page狀態。然而InnoDB默認的Page大小是16KB,是大于文件系統能保證原子的4KB大小的,因此可能出現Page內容成功一半的情況。InnoDB中采用了Double Write Buffer的方式來通過寫兩次的方式保證恢復的時候找到一個正確的Page狀態。這部分會在之后介紹Buffer Pool的時候詳細介紹。
2、需要保證REDO重放的冪等
Double Write Buffer能夠保證找到一個正確的Page狀態,我們還需要知道這個狀態對應REDO上的哪個記錄,來避免對Page的重復修改。為此,InnoDB給每個REDO記錄一個全局唯一遞增的標號LSN(Log Sequence Number)。Page在修改時,會將對應的REDO記錄的LSN記錄在Page上(FIL_PAGE_LSN字段),這樣恢復重放REDO時,就可以來判斷跳過已經應用的REDO,從而實現重放的冪等。
三、REDO中記錄了什么內容
知道了InnoDB中記錄REDO的方式,那么REDO里具體會記錄哪些內容呢?為了應對InnoDB各種各樣不同的需求,到MySQL 8.0為止,已經有多達65種的REDO記錄。用來記錄這不同的信息,恢復時需要判斷不同的REDO類型,來做對應的解析。根據REDO記錄不同的作用對象,可以將這65中REDO劃分為三個大類:作用于Page,作用于Space以及提供額外信息的Logic類型。
1、作用于Page的REDO
這類REDO占所有REDO類型的絕大多數,根據作用的Page的不同類型又可以細分為,Index Page REDO,Undo Page REDO,Rtree PageREDO等。比如MLOG_REC_INSERT,MLOG_REC_UPDATE_IN_PLACE,MLOG_REC_DELETE三種類型分別對應于Page中記錄的插入,修改以及刪除。這里還是以MLOG_REC_UPDATE_IN_PLACE為例來看看其中具體的內容:
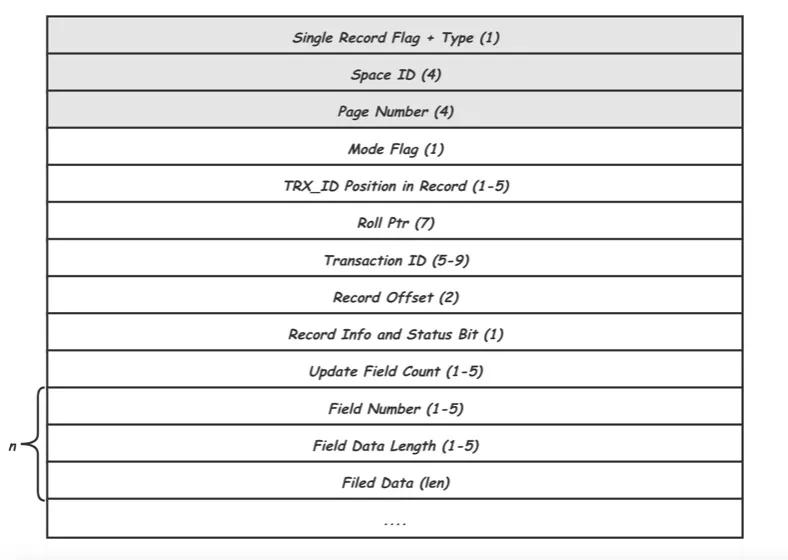
其中,Type就是MLOG_REC_UPDATE_IN_PLACE類型,Space ID和Page Number唯一標識一個Page頁,這三項是所有REDO記錄都需要有的頭信息,后面的是MLOG_REC_UPDATE_IN_PLACE類型獨有的,其中Record Offset用給出要修改的記錄在Page中的位置偏移,Update Field Count說明記錄里有幾個Field要修改,緊接著對每個Field給出了Field編號(Field Number),數據長度(Field Data Length)以及數據(Filed Data)。
2、作用于Space的REDO
這類REDO針對一個Space文件的修改,如MLOG_FILE_CREATE,MLOG_FILE_DELETE,MLOG_FILE_RENAME分別對應對一個Space的創建,刪除以及重命名。由于文件操作的REDO是在文件操作結束后才記錄的,因此在恢復的過程中看到這類日志時,說明文件操作已經成功,因此在恢復過程中大多只是做對文件狀態的檢查,以MLOG_FILE_CREATE來看看其中記錄的內容:

同樣的前三個字段還是Type,Space ID和Page Number,由于是針對Page的操作,這里的Page Number永遠是0。在此之后記錄了創建的文件flag以及文件名,用作重啟恢復時的檢查。
3、提供額外信息的Logic REDO
除了上述類型外,還有少數的幾個REDO類型不涉及具體的數據修改,只是為了記錄一些需要的信息,比如最常見的MLOG_MULTI_REC_END就是為了標識一個REDO組,也就是一個完整的原子操作的結束。
4、REDO是如何組織的
所謂REDO的組織方式,就是如何把需要的REDO內容記錄到磁盤文件中,以方便高效的REDO寫入,讀取,恢復以及清理。我們這里把REDO從上到下分為三層:邏輯REDO層、物理REDO層和文件層。
1) 邏輯REDO層
這一層是真正的REDO內容,REDO由多個不同Type的多個REDO記錄收尾相連組成,有全局唯一的遞增的偏移sn,InnoDB會在全局log_sys中維護當前sn的最大值,并在每次寫入數據時將sn增加REDO內容長度。如下圖所示:

2 )物理REDO層
磁盤是塊設備,InnoDB中也用Block的概念來讀寫數據,一個Block的長度OS_FILE_LOG_BLOCK_SIZE等于磁盤扇區的大小512B,每次IO讀寫的最小單位都是一個Block。除了REDO數據以外,Block中還需要一些額外的信息,下圖所示一個Log Block的的組成,包括12字節的Block Header:前4字節中Flush Flag占用最高位bit,標識一次IO的第一個Block,剩下的31個個bit是Block編號;之后是2字節的數據長度,取值在[12,508];緊接著2字節的First Record Offset用來指向Block中第一個REDO組的開始,這個值的存在使得我們對任何一個Block都可以找到一個合法的的REDO開始位置;最后的4字節Checkpoint Number記錄寫Block時的next_checkpoint_number,用來發現文件的循環使用,這個會在文件層詳細講解。Block末尾是4字節的Block Tailer,記錄當前Block的Checksum,通過這個值,讀取Log時可以明確Block數據有沒有被完整寫完。

Block中剩余的中間498個字節就是REDO真正內容的存放位置,也就是我們上面說的邏輯REDO。我們現在將邏輯REDO放到物理REDO空間中,由于Block內的空間固定,而REDO長度不定,因此可能一個Block中有多個REDO,也可能一個REDO被拆分到多個Block中,如下圖所示,棕色和紅色分別代表Block Header和Tailer,中間的REDO記錄由于前一個Block剩余空間不足,而被拆分在連續的兩個Block中。
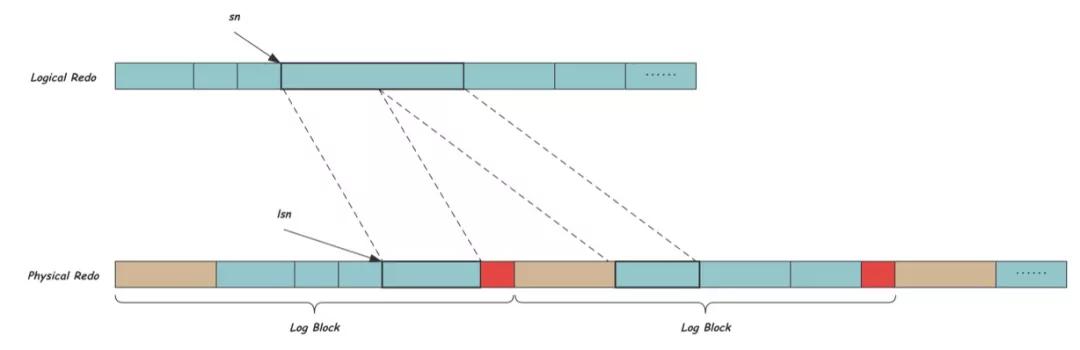
由于增加了Block Header和Tailer的字節開銷,在物理REDO空間中用LSN來標識偏移,可以看出LSN和SN之間有簡單的換算關系:
- constexpr inline lsn_t log_translate_sn_to_lsn(lsn_t sn) {
- return (sn / LOG_BLOCK_DATA_SIZE * OS_FILE_LOG_BLOCK_SIZE +
- sn % LOG_BLOCK_DATA_SIZE + LOG_BLOCK_HDR_SIZE);
- }
SN加上之前所有的Block的Header以及Tailer的長度就可以換算到對應的LSN,反之亦然。
3) 文件層
最終REDO會被寫入到REDO日志文件中,以ib_logfile0、ib_logfile1...命名,為了避免創建文件及初始化空間帶來的開銷,InooDB的REDO文件會循環使用,通過參數innodb_log_files_in_group可以指定REDO文件的個數。多個文件收尾相連順序寫入REDO內容。每個文件以Block為單位劃分,每個文件的開頭固定預留4個Block來記錄一些額外的信息,其中第一個Block稱為Header Block,之后的3個Block在0號文件上用來存儲Checkpoint信息,而在其他文件上留空:
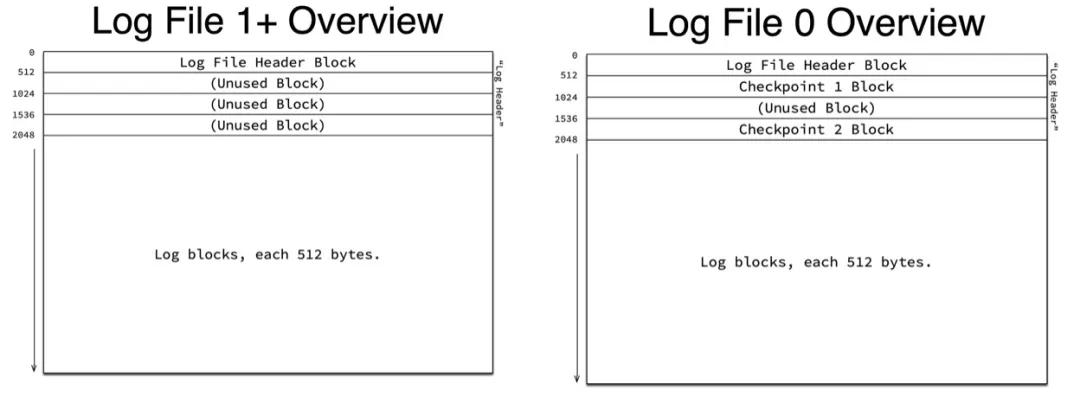
其中第一個Header Block的數據區域記錄了一些文件信息,如下圖所示,4字節的Formate字段記錄Log的版本,不同版本的LOG,會有REDO類型的增減,這個信息是8.0開始才加入的;8字節的Start LSN標識當前文件開始LSN,通過這個信息可以將文件的offset與對應的lsn對應起來;最后是最長32位的Creator信息,正常情況下會記錄MySQL的版本。

現在我們將REDO放到文件空間中,如下圖所示,邏輯REDO是真正需要的數據,用sn索引,邏輯REDO按固定大小的Block組織,并添加Block的頭尾信息形成物理REDO,以lsn索引,這些Block又會放到循環使用的文件空間中的某一位置,文件中用offset索引:
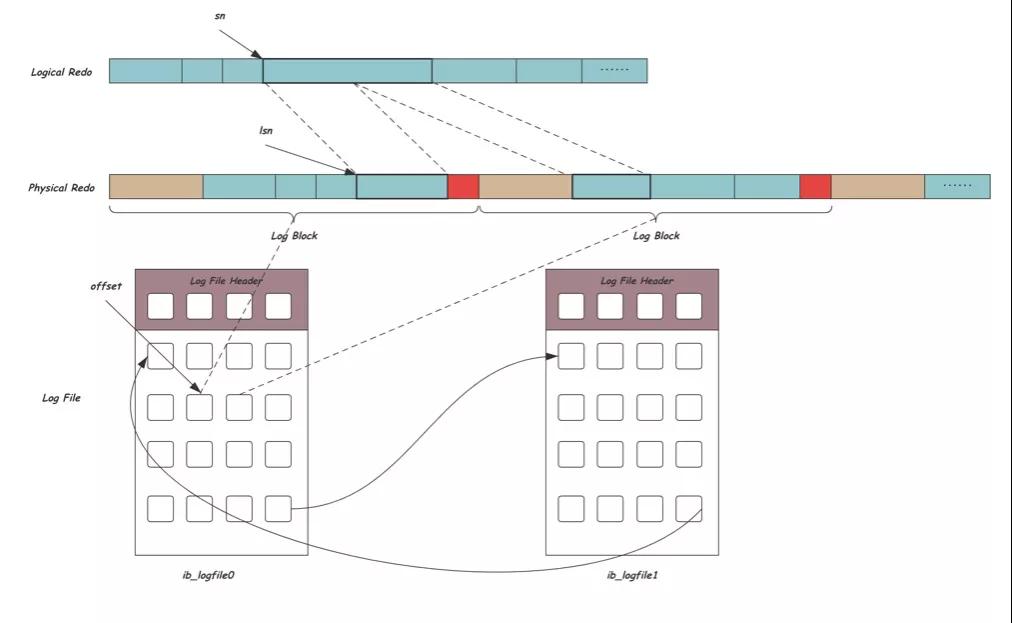
雖然通過LSN可以唯一標識一個REDO位置,但最終對REDO的讀寫還需要轉換到對文件的讀寫IO,這個時候就需要表示文件空間的offset,他們之間的換算方式如下:
- const auto real_offset =
- log.current_file_real_offset + (lsn - log.current_file_lsn);
切換文件時會在內存中更新當前文件開頭的文件offset,current_file_real_offset,以及對應的LSN,current_file_lsn,通過這兩個值可以方便地用上面的方式將LSN轉化為文件offset。注意這里的offset是相當于整個REDO文件空間而言的,由于InnoDB中讀寫文件的space層實現支持多個文件,因此,可以將首位相連的多個REDO文件看成一個大文件,那么這里的offset就是這個大文件中的偏移。
五、如何高效地寫REDO
作為維護數據庫正確性的重要信息,REDO日志必須在事務提交前保證落盤,否則一旦斷電將會有數據丟失的可能,因此從REDO生成到最終落盤的完整過程成為數據庫寫入的關鍵路徑,其效率也直接決定了數據庫的寫入性能。這個過程包括REDO內容的產生,REDO寫入InnoDB Log Buffer,從InnoDB Log Buffer寫入操作系統Page Cache,以及REDO刷盤,之后還需要喚醒等待的用戶線程完成Commit。下面就通過這幾個階段來看看InnoDB如何在高并發的情況下還能高效地完成寫REDO。
1、REDO產生
我們知道事務在寫入數據的時候會產生REDO,一次原子的操作可能會包含多條REDO記錄,這些REDO可能是訪問同一Page的不同位置,也可能是訪問不同的Page(如Btree節點分裂)。InnoDB有一套完整的機制來保證涉及一次原子操作的多條REDO記錄原子,即恢復的時候要么全部重放,要不全部不重放,這部分將在之后介紹恢復邏輯的時候詳細介紹,本文只涉及其中最基本的要求,就是這些REDO必須連續。InnoDB中通過min-transaction實現,簡稱mtr,需要原子操作時,調用mtr_start生成一個mtr,mtr中會維護一個動態增長的m_log,這是一個動態分配的內存空間,將這個原子操作需要寫的所有REDO先寫到這個m_log中,當原子操作結束后,調用mtr_commit將m_log中的數據拷貝到InnoDB的Log Buffer。
2、寫入InnoDB Log Buffer
高并發的環境中,會同時有非常多的min-transaction(mtr)需要拷貝數據到Log Buffer,如果通過鎖互斥,那么毫無疑問這里將成為明顯的性能瓶頸。為此,從MySQL 8.0開始,設計了一套無鎖的寫log機制,其核心思路是允許不同的mtr,同時并發地寫Log Buffer的不同位置。不同的mtr會首先調用log_buffer_reserve函數,這個函數里會用自己的REDO長度,原子地對全局偏移log.sn做fetch_add,得到自己在Log Buffer中獨享的空間。之后不同mtr并行的將自己的m_log中的數據拷貝到各自獨享的空間內。
- /* Reserve space in sequence of data bytes: */
- const sn_t start_sn = log.sn.fetch_add(len);
3、寫入Page Cache
寫入到Log Buffer中的REDO數據需要進一步寫入操作系統的Page Cache,InnoDB中有單獨的log_writer來做這件事情。這里有個問題,由于Log Buffer中的數據是不同mtr并發寫入的,這個過程中Log Buffer中是有空洞的,因此log_writer需要感知當前Log Buffer中連續日志的末尾,將連續日志通過pwrite系統調用寫入操作系統Page Cache。整個過程中應盡可能不影響后續mtr進行數據拷貝,InnoDB在這里引入一個叫做link_buf的數據結構,如下圖所示:
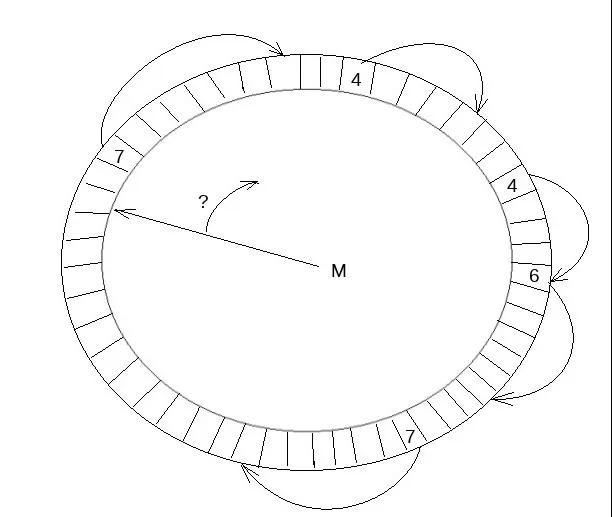
link_buf是一個循環使用的數組,對每個lsn取模可以得到其在link_buf上的一個槽位,在這個槽位中記錄REDO長度。另外一個線程從開始遍歷這個link_buf,通過槽位中的長度可以找到這條REDO的結尾位置,一直遍歷到下一位置為0的位置,可以認為之后的REDO有空洞,而之前已經連續,這個位置叫做link_buf的tail。下面看看log_writer和眾多mtr是如何利用這個link_buf數據結構的。這里的這個link_buf為log.recent_written,如下圖所示:
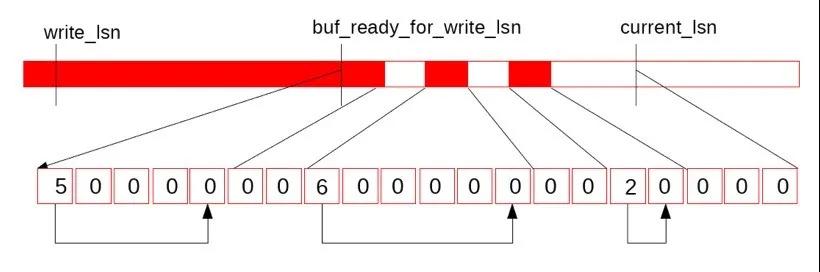
圖中上半部分是REDO日志示意圖,write_lsn是當前log_writer已經寫入到Page Cache中日志末尾,current_lsn是當前已經分配給mtr的的最大lsn位置,而buf_ready_for_write_lsn是當前log_writer找到的Log Buffer中已經連續的日志結尾,從write_lsn到buf_ready_for_write_lsn是下一次log_writer可以連續調用pwrite寫入Page Cache的范圍,而從buf_ready_for_write_lsn到current_lsn是當前mtr正在并發寫Log Buffer的范圍。下面的連續方格便是log.recent_written的數據結構,可以看出由于中間的兩個全零的空洞導致buf_ready_for_write_lsn無法繼續推進,接下來,假如reserve到中間第一個空洞的mtr也完成了寫Log Buffer,并更新了log.recent_written*,如下圖:
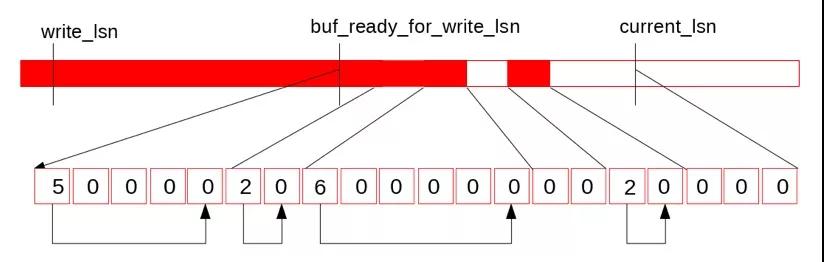
這時,log_writer從當前的buf_ready_for_write_lsn向后遍歷log.recent_written,發現這段已經連續:
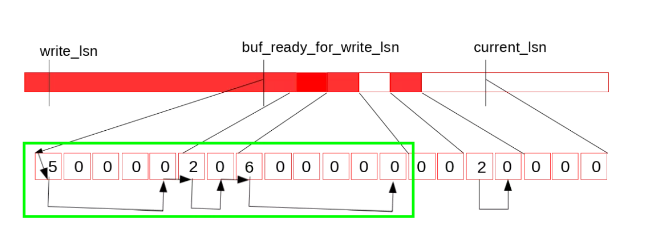
因此提升當前的buf_ready_for_write_lsn,并將log.recent_written的tail位置向前滑動,之后的位置清零,供之后循環復用:
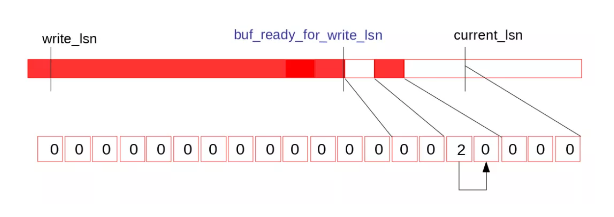
緊接log_writer將連續的內容刷盤并提升write_lsn。
4、刷盤
log_writer提升write_lsn之后會通知log_flusher線程,log_flusher線程會調用fsync將REDO刷盤,至此完成了REDO完整的寫入過程。
5、喚醒用戶線程
為了保證數據正確,只有REDO寫完后事務才可以commit,因此在REDO寫入的過程中,大量的用戶線程會block等待,直到自己的最后一條日志結束寫入。默認情況下innodb_flush_log_at_trx_commit = 1,需要等REDO完成刷盤,這也是最安全的方式。當然,也可以通過設置innodb_flush_log_at_trx_commit = 2,這樣,只要REDO寫入Page Cache就認為完成了寫入,極端情況下,掉電可能導致數據丟失。
大量的用戶線程調用log_write_up_to等待在自己的lsn位置,為了避免大量無效的喚醒,InnoDB將阻塞的條件變量拆分為多個,log_write_up_to根據自己需要等待的lsn所在的block取模對應到不同的條件變量上去。同時,為了避免大量的喚醒工作影響log_writer或log_flusher線程,InnoDB中引入了兩個專門負責喚醒用戶的線程:log_wirte_notifier和log_flush_notifier,當超過一個條件變量需要被喚醒時,log_writer和log_flusher會通知這兩個線程完成喚醒工作。下圖是整個過程的示意圖:
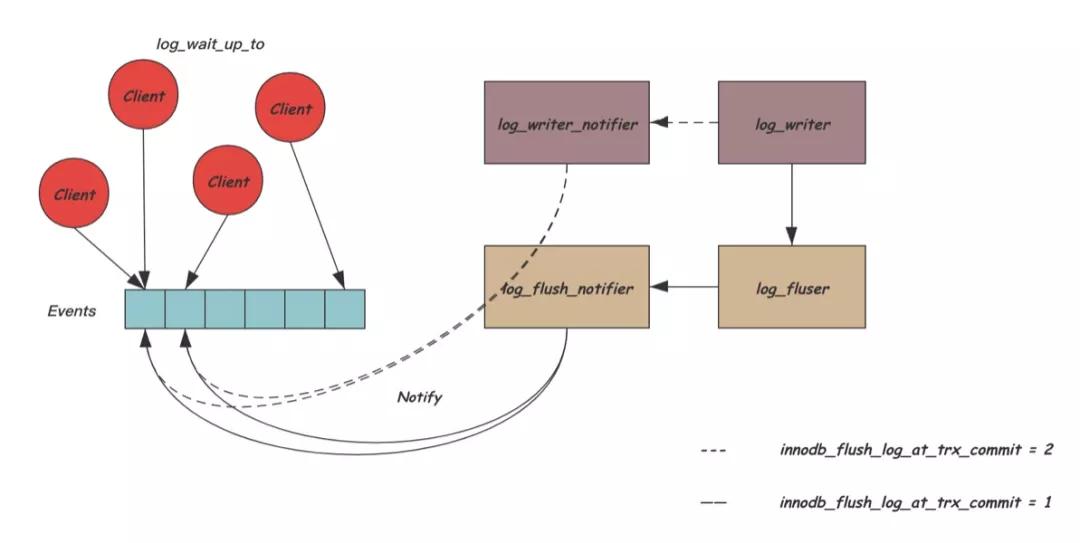
多個線程通過一些內部數據結構的輔助,完成了高效的從REDO產生,到REDO寫盤,再到喚醒用戶線程的流程,下面是整個這個過程的時序圖:
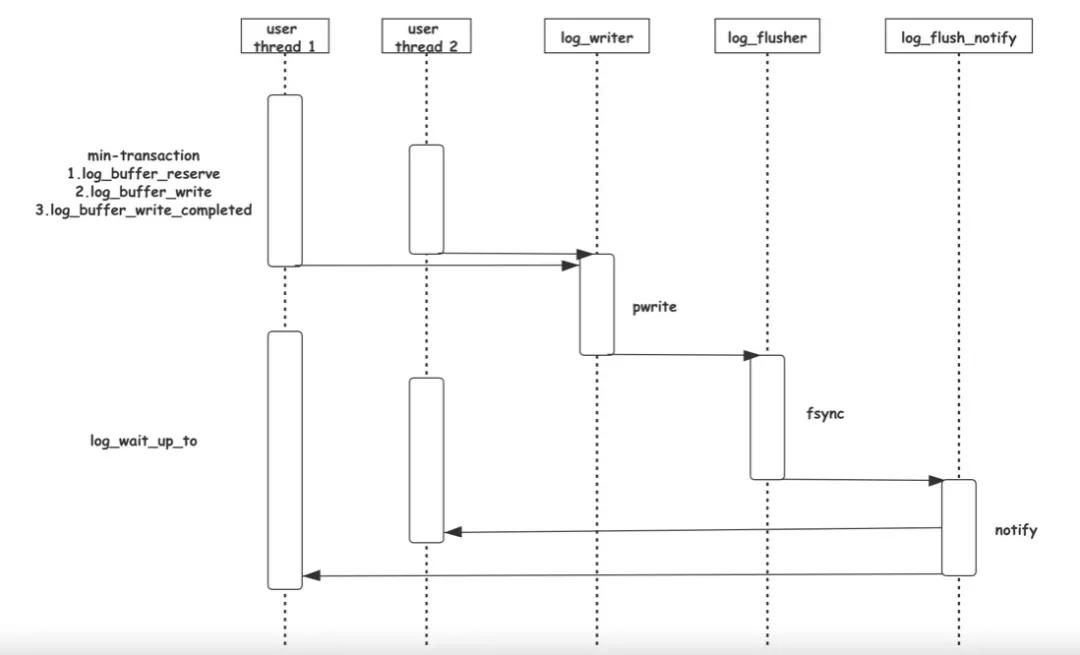
六、如何安全地清除REDO
由于REDO文件空間有限,同時為了盡量減少恢復時需要重放的REDO,InnoDB引入log_checkpointer線程周期性的打Checkpoint。重啟恢復的時候,只需要從最新的Checkpoint開始回放后邊的REDO,因此Checkpoint之前的REDO就可以刪除或被復用。
我們知道REDO的作用是避免只寫了內存的數據由于故障丟失,那么打Checkpiont的位置就必須保證之前所有REDO所產生的內存臟頁都已經刷盤。最直接的,可以從Buffer Pool中獲得當前所有臟頁對應的最小REDO LSN:lwm_lsn。但光有這個還不夠,因為有一部分min-transaction的REDO對應的Page還沒有來的及加入到Buffer Pool的臟頁中去,如果checkpoint打到這些REDO的后邊,一旦這時發生故障恢復,這部分數據將丟失,因此還需要知道當前已經加入到Buffer Pool的REDO lsn位置:dpa_lsn。取二者的較小值作為最終checkpoint的位置,其核心邏輯如下:
- /* LWM lsn for unflushed dirty pages in Buffer Pool */
- lsn_t lwm_lsn = buf_pool_get_oldest_modification_lwm();
- /* Note lsn up to which all dirty pages have already been added into Buffer Pool */
- const lsn_t dpa_lsn = log_buffer_dirty_pages_added_up_to_lsn(log);
- lsn_t checkpoint_lsn = std::min(lwm_lsn, dpa_lsn);
MySQL 8.0中為了能夠讓mtr之間更大程度的并發,允許并發地給Buffer Pool注冊臟頁。類似與log.recent_written和log_writer,這里引入一個叫做recent_closed的link_buf來處理并發帶來的空洞,由單獨的線程log_closer來提升recent_closed的tail,也就是當前連續加入Buffer Pool臟頁的最大LSN,這個值也就是上面提到的dpa_lsn。需要注意的是,由于這種亂序的存在,lwm_lsn的值并不能簡單的獲取當前Buffer Pool中的最老的臟頁的LSN,保守起見,還需要減掉一個recent_closed的容量大小,也就是最大的亂序范圍,簡化后的代碼如下:
- /* LWM lsn for unflushed dirty pages in Buffer Pool */
- const lsn_t lsn = buf_pool_get_oldest_modification_approx();
- const lsn_t lag = log.recent_closed.capacity();
- lsn_t lwm_lsn = lsn - lag;
- /* Note lsn up to which all dirty pages have already been added into Buffer Pool */
- const lsn_t dpa_lsn = log_buffer_dirty_pages_added_up_to_lsn(log);
- lsn_t checkpoint_lsn = std::min(lwm_lsn, dpa_lsn);
這里有一個問題,由于lwm_lsn已經減去了recent_closed的capacity,因此理論上這個值一定是小于dpa_lsn的。那么再去比較lwm_lsn和dpa_lsn來獲取Checkpoint位置或許是沒有意義的。
上面已經提到,ib_logfile0文件的前三個Block有兩個被預留作為Checkpoint Block,這兩個Block會在打Checkpiont的時候交替使用,這樣來避免寫Checkpoint過程中的崩潰導致沒有可用的Checkpoint。Checkpoint Block中的內容如下:

首先8個字節的Checkpoint Number,通過比較這個值可以判斷哪個是最新的Checkpiont記錄,之后8字節的Checkpoint LSN為打Checkpoint的REDO位置,恢復時會從這個位置開始重放后邊的REDO。之后8個字節的Checkpoint Offset,將Checkpoint LSN與文件空間的偏移對應起來。最后8字節是前面提到的Log Buffer的長度,這個值目前在恢復過程并沒有使用。
七、總結
本文系統的介紹了InnoDB中REDO的作用、特性、組織結構、寫入方式已經清理時機,基本覆蓋了REDO的大多數內容。關于重啟恢復時如何使用REDO將數據庫恢復到正確的狀態,將在之后介紹InnoDB故障恢復機制的時候詳細介紹。
參考
[1] MySQL 8.0.11Source Code Documentation: Format of redo log
https://dev.mysql.com/doc/dev/mysql-server/8.0.11/PAGE_INNODB_REDO_LOG_FORMAT.html?spm=ata.21736010.0.0.600e6f95JcmTlA
[2] MySQL 8.0: New Lock free, scalable WAL design
https://mysqlserverteam.com/mysql-8-0-new-lock-free-scalable-wal-design/?spm=ata.21736010.0.0.600e6f95JcmTlA
[3] How InnoDB handles REDO logging
https://www.percona.com/blog/2011/02/03/how-innodb-handles-redo-logging/?spm=ata.21736010.0.0.600e6f95JcmTlA
[4] MySQL Source Code
https://github.com/mysql/mysql-server?spm=ata.21736010.0.0.600e6f95JcmTlA
[5] 數據庫故障恢復機制的前世今生
http://catkang.github.io/2019/01/16/crash-recovery.html?spm=ata.21736010.0.0.600e6f95JcmTlA