













小數據,大前景 !美國智庫最新報告:長期被忽略的小數據人工智能潛力不可估量

本文轉自雷鋒網,如需轉載請至雷鋒網官網申請授權。
2021年9月,美國網絡安全和新興技術局(Center for Security and Emerging Technology,簡稱CSET)發布了研究報告《小數據人工智能的巨大潛力》(Small Data’s Big AI Potential )。報告指明一點:長期被忽略的小數據(Small Data)人工智能潛力不可估量!

小數據方法是一種只需少量數據集就能進行訓練的人工智能方法。它適用于數據量少或沒有標記數據可用的情況,減少對人們收集大量現實數據集的依賴。
這里所說的“小數據”并不是明確類別,沒有正式和一致認可的定義。學術文章討論小數據與應用領域相關性時,常與樣本大小相掛鉤,例如千字節或兆字節與 TB 數據。對許多數據的引用最終走向都是作為通用資源。然而,數據是不可替代的,不同領域的人工智能系統需要不同類型的數據和方法,具體取決待解決的問題。
本文主要從決策者的角度講述“小數據”。政府人員通常被看作是人工智能領域潛在的強力參與者,因為他們對社會運行規則更為了解并可以訪問大量數據——例如氣候監測數據、地質調查、邊境控制、社會保障、 選民登記、車輛和司機記錄等。人口眾多、數據收集能力強被認為是國家人工智能競爭能力的重要因素。
一些美國人認為,政府只有可以數字化、清理和標記大量數據,才能從人工智能的革命中受益。雖有些道理,但將AI的進展都歸功于這些條件是偏頗的。因為人工智能的未來不僅只與大數據有關聯,即使政府部門沒有對大數據基礎設施多加投資,人工智能的創新依舊可以誕生。
二、”小數據“方法的分類
“小數據”方法大致可分為五種:a) 遷移學習,b) 數據標記,c) 人工數據生成,d) 貝葉斯方法,以及 e) 強化學習。
遷移學習(Transfer learning )的工作原理是先在數據豐富的環境中執行任務,然后將學到的知識“遷移”到可用數據匱乏的任務中。
比如,開發人員想做一款用于識別稀有鳥類物種應用程序,但每種鳥可能只有幾張標有物種的照片。運用遷移學習,他們先用更大、更通用的圖像數據庫(例如ImageNet)訓練基本圖像分類器,該數據庫具有數千個類別標記過的數百萬張圖像。當分類器能區分狗與貓、花與水果、麻雀與燕子后,他們就可以將更小的稀有鳥類數據集“喂養”給它。然后,該模型可以“轉移”圖像分類的知識,利用這些知識從更少的數據中學習新任務(識別稀有鳥類)。
數據標記(Data labeling)適用于有限標記數據和大量未標記數據的情況。使用自動生成標簽(自動標記)或識別標簽特別用途的數據點(主動學習)來處理未標記的數據。
例如,主動學習(active learning)已被用于皮膚癌診斷的研究。圖像分類模型最初在100張照片上訓練,根據它們的描述判定是癌癥皮膚還是健康皮膚從,而進行標記。然后該模型會訪問更大的潛在訓練圖像集,從中可以選擇 100 張額外的照片標記并添加到它的訓練數據中。
人工數據生成(Artificial data generation)是通過創建新的數據點或其他相關技術,最大限度地從少量數據中提取更多信息。
一個簡單的例子,計算機視覺研究人員已經能用計算機輔助設計軟件 (CAD) ——從造船到廣告等行業廣泛使用的工具——生成日常事物的擬真 3D 圖像,然后用圖像來增強現有的圖像數據集。當感興趣的數據存在單獨信息源時,如本例中是眾包CAD模型時,這樣的方法可行性更高。
生成額外數據的能力不僅在處理小數據集時有用。任何獨立數據的細節都可能是敏感的(比如個人的健康記錄),但研究人員只對數據的整體分布感興趣,這時人工合成數據的優勢就顯現出來了,它可對數據進行隨機變化從而抹去私人痕跡,更好地保護了個人隱私。
貝葉斯方法(Bayesian methods)是通過統計學和機器學習,將有關問題的架構信息(“先驗”信息)納入解決問題的方法中,它與大多數機器學習方法產生了鮮明對比,傾向于對問題做出最小假設,更適用于數據有限的情況,但可以通過有效的數學形式寫出關于問題的信息。貝葉斯方法則側重對其預測的不確定性產生良好的校準估計。
作為貝葉斯推斷運用小數據的一個例子:貝葉斯方法被用于監測全球地震活動,對檢測地殼運動和核條約有著重大意義。通過開發結合地震學的先驗知識模型,研究人員可以充分利用現有數據來改進模型。貝葉斯方法是一個龐大的族群,不是僅包含了擅長處理小數據集的方法。對其的一些研究也會使用大數據集。
強化學習(Reinforcement learning)是一個廣義的術語,指的是機器學習方法,其中智能體(計算機系統)通過反復試驗來學習與環境交互。強化學習通常用于訓練游戲系統、機器人和自動駕駛汽車。
例如,強化學習已被用于訓練學習如何操作視頻游戲的AI系統——從簡單的街機游戲(如 Pong)到戰略游戲(如星際爭霸)。系統開始時對玩游戲知之甚少或一無所知,但通過嘗試和觀察摸索獎勵信號出現的原因,從而不斷學習。(在視頻游戲的例子中,獎勵信號常以玩家得分的形式呈現。)
強化學習系統通常從大量數據中學習,需要海量計算資源,因而它們被列入其中似乎是一個非直觀類別。強化學習被襄括進來,是因為它們使用的數據通常是在系統訓練時生成的——多在模擬的環境中——而不是預先收集和標記。在強化學習問題中,智能體與環境交互的能力至關重要。
圖 1 展示了這些不同區域是如何相互連接的。每個點代表一個研究集群(一組論文),將其確定為屬于上述類別之一。連接兩個研究集群線的粗細代表它們之間引文鏈接的關聯度。沒有線則表示沒有引文鏈接。如圖所示,集群與同類別集群聯系最多,但不同類集群之間的聯系也不少。還可以從該圖看到,“強化學習”識別的集群形成了特別連貫的分組,而“人工數據”集群則更加分散。
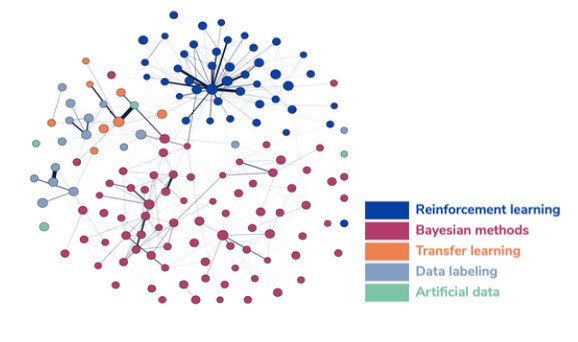
圖1所示,小數據研究集群網絡圖
資料來源:CSET 合并學術文獻語料庫,截至 2021 年 2 月 12 日。
三、“小數據“方法重要在哪里?
1. 縮短大小實體間AI能力差距
AI 應用程序的大型數據集價值在不斷增長,不同機構收集、存儲和處理數據的能力差異缺令人擔憂。人工智能的“富人”(如大型科技公司)和“窮人”之間也因此拉開差距。如果遷移學習、自動標記、貝葉斯方法等能夠在少量數據的情況下應用于人工智能,那么小型實體進入數據方面的壁壘會大幅降低,這可以縮減大、小實體之間的能力差距。
2. 減少個人數據的收集
大多數美國人認為人工智能會吞并個人隱私空間。比如大型科技公司愈多收集與個人身份相關的消費者數據來訓練它們的AI算法。某些小數據方法能夠減少收集個人數據的行為,人工生成新數據(如合成數據生成)或使用模擬訓練算法的方法,一個不依賴于個人生成的數據,另一個則具有合成數據去除敏感的個人身份屬性的能力。雖然不能將所有隱私擔憂都解決,但通過減少收集大規模真實數據的需要,讓使用機器學習變得更簡單,從而讓人們對大規模收集、使用或披露消費者數據不再擔憂。
3. 促進數據匱乏領域的發展
可用數據的爆炸式增長推動了人工智能的新發展。但對于許多亟待解決的問題,可以輸入人工智能系統的數據卻很少或者根本不存在。比如,為沒有電子健康記錄的人構建預測疾病風險的算法,或者預測活火山突然噴發的可能性。小數據方法以提供原則性的方式來處理數據缺失或匱乏。它可以利用標記數據和未標記數據,從相關問題遷移知識。小數據也可以用少量數據點創建更多數據點,憑借關聯領域的先驗知識,或通過構建模擬或編碼結構假設去開始新領域的冒險。
4. 避免臟數據問題
小數據方法能讓對“臟數據”煩不勝煩的大型機構受益。數據是一直存在的,但想要它干凈、結構整齊且便于分析就還有很長的路要走。比如由于孤立的數據基礎設施和遺留系統,美國國防部擁有不可計數的“臟數據”,需要耗費大量人力物力進行數據清理、標記和整理才能夠“凈化”它們。小數據方法中數據標記法可以通過自動生成標簽更輕松地處理大量未標記的數據。遷移學習、貝葉斯方法或人工數據方法可以通過減少需要清理的數據量,分別依據相關數據集、結構化模型和合成數據來顯著降低臟數據問題的規模。
對于從事人工智能工作的決策者而言,清楚地了解數據在人工智能發展中所扮演的角色和無法勝任的工作都至關重要。上述因素不適用于所有方法。例如,強化學習一般需要大量數據,但這些數據是在訓練過程中生成的(例如,當 AI 系統移動機器人手臂或在虛擬環境中導航時),并不是預先收集的。
四、研究進展
在研究量方面,過去十年中五種“小數據”方法的曲線變化有著非同尋常的軌跡。如圖2所示,強化學習和貝葉斯方法是論文數量最大的兩個類別。貝葉斯集群論文量在過去十年間穩步增長,強化學習相關集群的論文量從2015年才開始有所增長,2017—2019年期間的增長尤為迅速。因為深度強化學習一直處于瓶頸期,直到2015年經歷了技術性變革。相比之下,過去十年間,每年以集群形式發表的人工數據生成和數據標記研究論文數量一直是鳳毛麟角。最后,遷移學習類的論文在 2010 時的數量比較少,但到 2020 年已實現大幅增長。

圖2. 2010-2020 年小數據出版物的趨勢
資料來源:CSET 合并學術文獻語料庫,截至 2021 年 2 月 12 日。
出版物的絕對數量并不能代表論文的質量。因此,研究人員利用兩個指標來衡量每個類別集群中論文的質量:H指數和年限校正引用。H指數是常用的度量標準,表示論文的出版活動和總引用次數。H指數存在一個局限性是,沒有考慮到論文出版時限(即較早的論文能夠有更多的時間積累引用量的事實)。H指數低估了那些最有影響力且尚未收集引文的新發表論文集群。為調整上述問題,圖3還描繪了經年限校正的引文。僅就 H指數而言,強化學習和貝葉斯方法大致相當,但考慮到論文的時限,強化學習脫穎而出。就五種“小數據”方法而論,貝葉斯方法的累積影響似乎更高,強化學習因其相對近期論文產量和引用影響的激增而一騎絕塵。
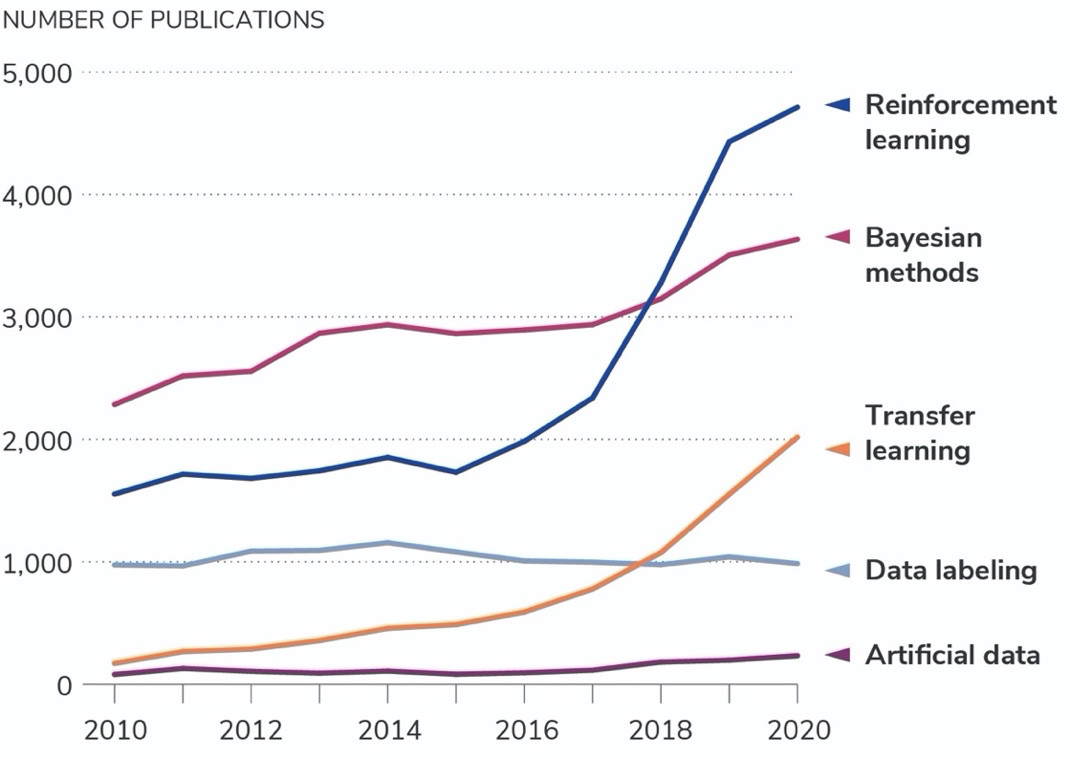
圖3. 2010-2020 年按類別劃分的 H 指數和年限校正引用
資料來源:CSET 合并學術文獻語料庫,截至 2021 年 2 月 1 日。
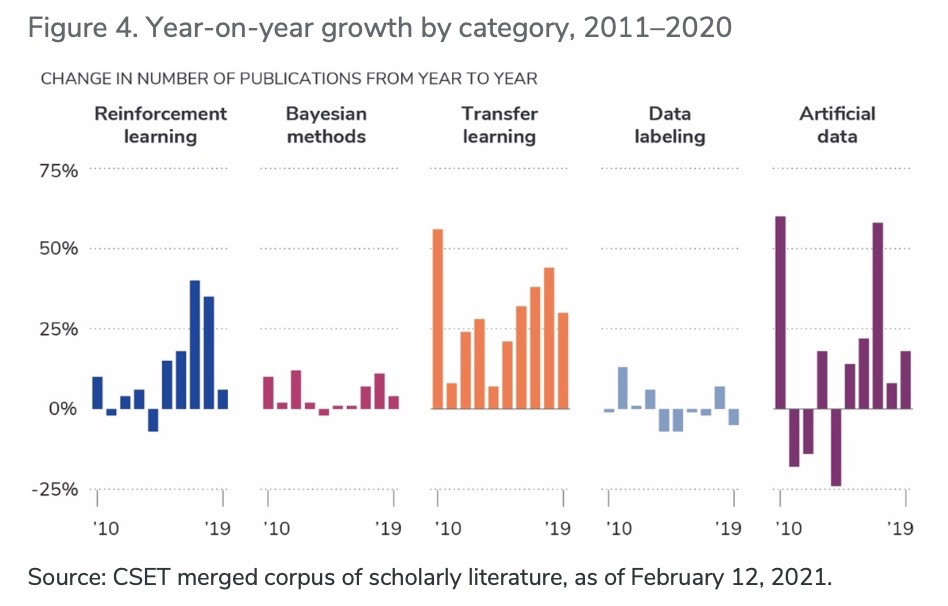
圖4. 2011-2020 年按類別劃分的同比增長
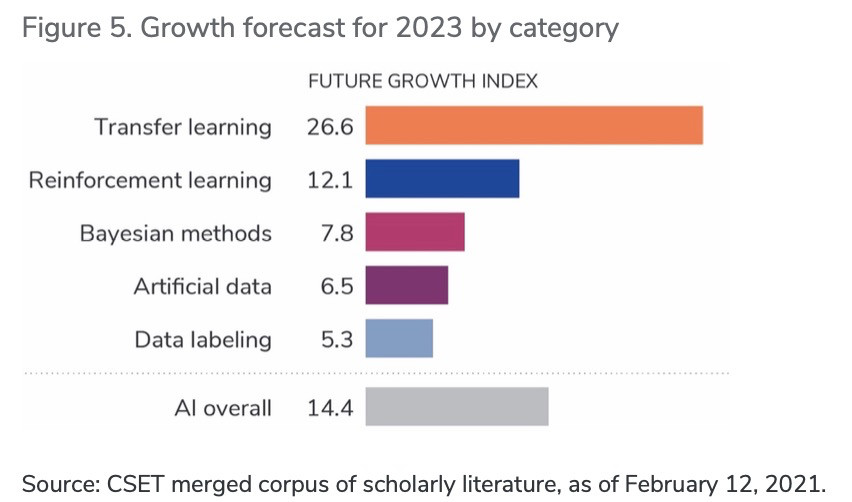
圖5. 按類別劃分的 2023 年增長預測
資料來源:CSET 合并學術文獻語料庫,截至 2021 年 2 月 12 日。
注:未來增長指數是根據 CSET 對研究集群增長的預測計算得出的。
五、國家競爭力
通過查看全球前10個國家在每種方法中取得的研究進展,可以推導出小數據方法的國家競爭力。以簡單的衡量指標,如發表論文數量和按年限調整的引用次數,初步了解各國在五種“小數據”方法的相應地位。
與AI研究的總體結果一致,中國和美國是研究“小數據”集群論文量前兩位,緊隨其后的是英國。中國在數據標記和遷移學習方法領域的學術出版物總數遙遙領先,而美國在貝葉斯方法、強化學習和人工數據生成方面較有優勢。除美國和中國外,其他小數據研究排名前10位的國家都是美國的盟友或合作伙伴,俄羅斯等國明顯缺席榜單。當前學術界常用論文引用量經衡量研究質量和影響。中國在所有小數據類別中的按年限調整引用量排名第二,在貝葉斯方法中的排名降至第七。
圖6顯示的是按國家細分的三年增長預測情況。相對于美國和世界其他地區,中國在遷移學習方法方面的增長預計會大幅提升。這一測如果準確,意味著中國會在遷移學習方面發展得更快更遠。
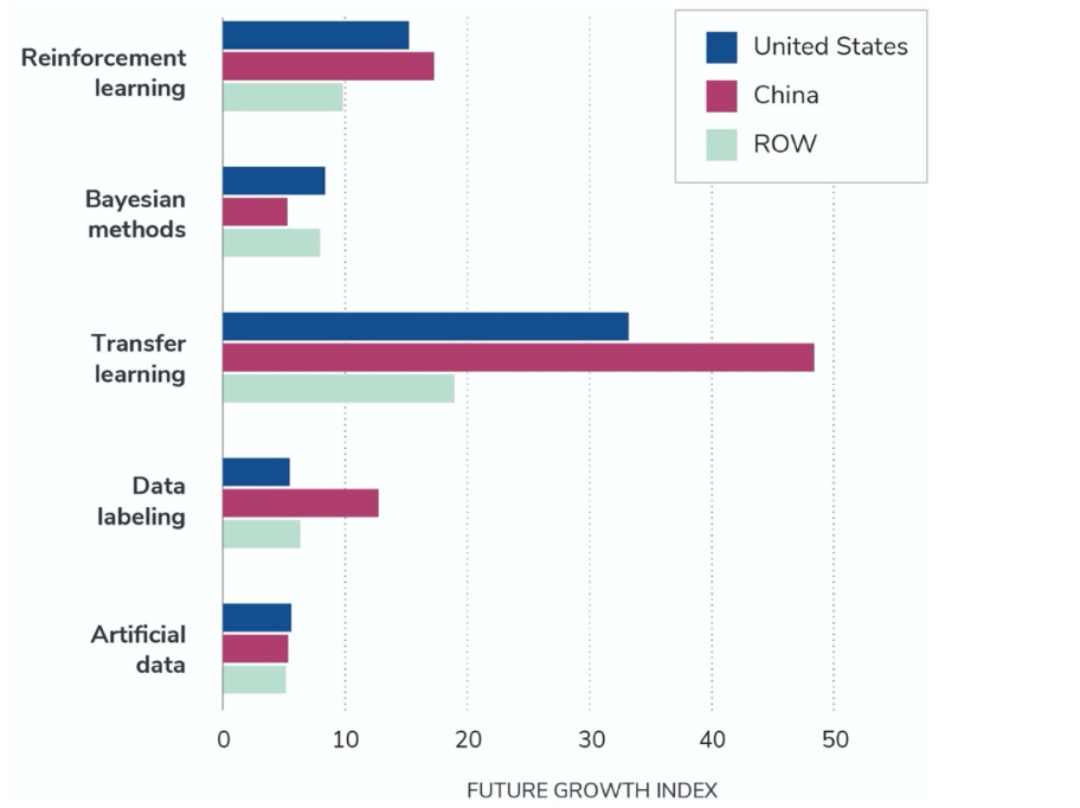
圖6. 2023 年美國、中國和世界其他地區(ROW)按類別劃分的增長預測
資料來源:CSET 合并學術文獻語料庫,截至 2021 年 2 月 12 日。
六、資金籌集
研究人員分析了可用于小數據方法的資助數據,以確定研究集群中資助論文實體類型的估量。對于上述調研結果,只有大約 20-30% 的論文的資助信息。
在各個領域中,在政府、公司、學術界和非營利組織中,政府人員一般是研究的重要資助者。在全球范圍內,政府資助在“小數據”方法集群中所占的比例遠高于人工智能整個領域。如圖7所示,在所有5大類別中,與AI研究整體的經費分解相比,政府資助的份額非常高。非盈利組織在用于小數據研究的資金中所占的比例比通常用于人工智能的其余部分要小。貝葉斯方法的資助模式與AI總體上最為相似。
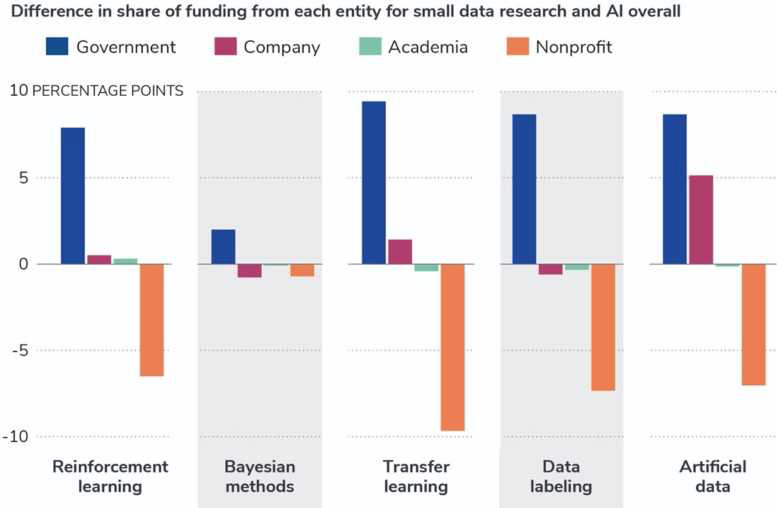
圖7. 與 AI 整體相關的數據方法的資金來源
資料來源:CSET 合并學術文獻語料庫,截至 2021 年 2 月 12 日。
圖 8 進一步按國家/地區細分了與政府相關的資金信息。研究結果表明,政府在小數據中投入資金所占比例總體呈上升趨勢,但整體來看,美國政府對小數據研究的資金份額低于其在人工智能方面的份額。個體機構、企業傾向于為美國的小數據研究提供比整個Al研究更大的份額。
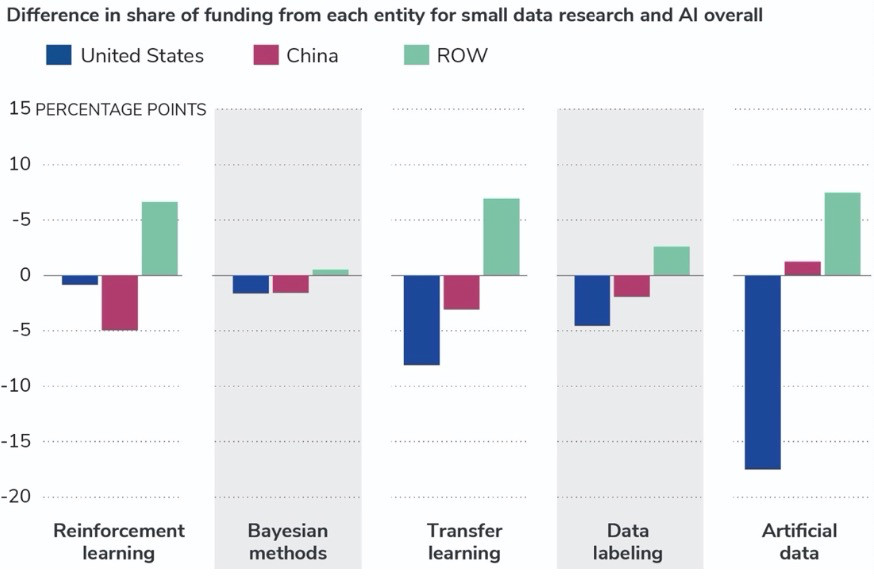
圖8. 中國、美國和世界其他地區(ROW)對于人工智能相關的小數據方法的政府資助
資料來源:CSET 合并學術文獻語料庫,截至 2021 年 2 月 12 日。
七、總結
a) 人工智能不等于大數據。
b) 對遷移學習的研究進展飛快,在未來遷移學習會更有效地被更廣泛應用。
c) 美國和中國在小數據方法方面的競爭非常激烈。美國在強化學習和貝葉斯方法這兩個類別中處于優勢,而中國在增長最快的遷移學習類別中一馬當先,并且將差距在逐漸加大。
d) 目前相對于整個人工智能領域的投資模式而言,美國在小數據方法上的投資份額更小,因此遷移學習可能是美國政府加大資金投入的前景目標。























