程序員必備的幾種常見排序算法和搜索算法總結
前言
最近為了鞏固一下自己的算法基礎,又把算法書里的基本算法刷了一遍, 特地總結一下前端工程師需要了解的排序算法和搜索算法知識,雖然還有很多高深算法需要了解, 但是基礎還是要好好鞏固一下的.本文將以圖文的形式為大家介紹如下算法知識,希望在讀完之后大家能有所收獲:
- 冒泡排序及其優化
- 選擇排序
- 插入排序
- 歸并排序
- 快速排序
- 順序搜索
- 二分搜索
正文
我想對于每個前端工程師來說, 最頭疼的就是算法問題, 但是算法往往也是衡量一個人編程能力的一個很重要的指標.目前很多主流框架和庫都應用了大量的算法和設計模式,為了讓自己的段位更高,我們只能不斷的"打怪"(也就是刷算法)升級,才能成為"最強王者".
其實前端發展這么多年, 越來越偏向于精細化開發, 很多超級應用(比如淘寶,微信)都在追求極致的用戶體驗, 時間就是金錢,這要求工程師們不能像以前那樣,開發的程序只要能用就行, 我們往往還要進行更加細致的測試(包括單元測試, 性能測試等),就拿排序來說, 對于大規模數據量的排序, 我們采用冒泡排序肯定是要被瘋狂吐槽的,因為冒泡排序的性能極差(復雜度為O(n^2).在真實項目中我們往往不會采用冒泡排序,更多的會用快速排序或者希爾排序.關于排序算法性能問題我在
《前端算法系列》如何讓前端代碼速度提高60倍
有詳細介紹. 接下來就讓我們來一起學習如何實現文章開頭的幾個常用排序和搜索算法吧.
1. 冒泡排序及其優化
我們在學排序算法時, 最容易掌握的就是冒泡排序, 因為其實現起來非常簡單,但是從運行性能的角度來看, 它卻是性能最差的一個.
冒泡排序的實現思路是比較任何兩個相鄰的項, 如果前者比后者大, 則將它們互換位置.
為了更方便的展示冒泡排序的過程和性能測試,筆者先寫幾個工具方法,分別為動態生成指定個數的隨機數組, 生成元素位置序列的方法,代碼如下:
- // 生成指定個數的隨機數組
- const generateArr = (num = 10) => {
- let arr = []
- for(let i = 0; i< num; i++) {
- let item = Math.floor(Math.random() * (num + 1))
- arr.push(item)
- }
- return arr
- }
- // 生成指定個數的元素x軸坐標
- const generateArrPosX = (n= 10, w = 6, m = 6) => {
- let pos = []
- for(let i = 0; i< n; i++) {
- let item = (w + m) * i
- pos.push(item)
- }
- return pos
- }
有了以上兩個方法,我們就可以生成任意個數的數組以及數組項坐標了,這兩個方法接下來我們會用到.
我們來直接寫個乞丐版的冒泡排序算法:
- bubbleSort(arr = []) {
- let len = arr.length
- for(let i = 0; i< len; i++) {
- for(let j = 0; j < len - 1; j++) {
- if(arr[j] > arr[j+1]) {
- // 置換
- [arr[j], arr[j+1]] = [arr[j+1], arr[j]]
- }
- }
- }
- return arr
- }
接下來我們來測試一下, 我們用generateArr方法生成60個數組項的數組, 并動態生成元素坐標:
- // 生成坐標
- const pos = generateArrPosX(60)
- // 生成60個項的數組
- const arr = generateArr(60)
執行代碼后會生成下圖隨機節點結構:

有關css部分這里就不介紹了,大家可以自己實現.接下來我們就可以測試我們上面寫的冒泡排序了,當我們點擊排序時,結果如下:
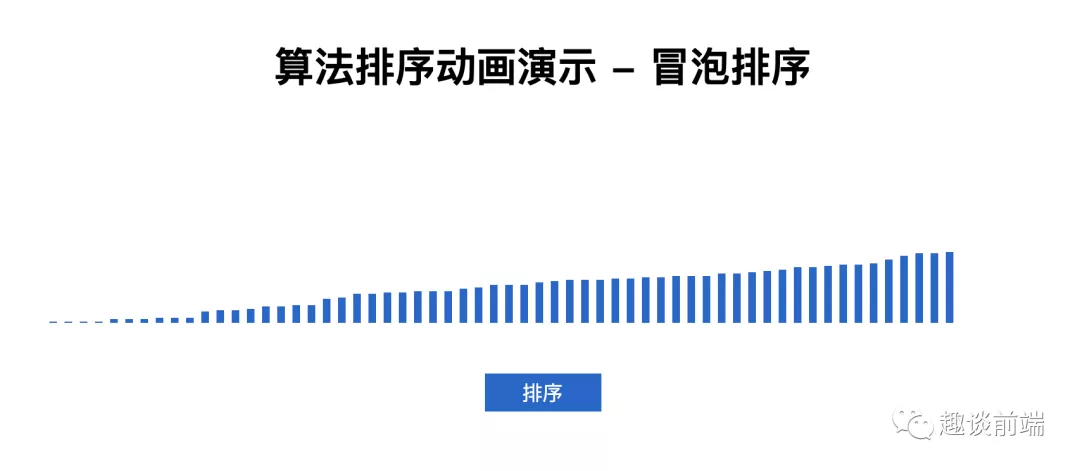
可以看到數組已按照順序排好了,我們可以使用console.time來測量代碼執行所用的時間,上面"乞丐版"冒泡排序耗時為0.2890625ms.
我們深入分析代碼就可以知道兩層for循環排序導致了很多多余的排序,如果我們從內循環減去外循環中已跑過的輪數,就可以避免內循環中不必要的比較,所以我們代碼優化如下:
- // 冒泡排序優化版
- bubbleSort(arr = []) {
- let len = arr.length
- // 優化
- for(let i = 0; i< len; i++) {
- for(let j = 0; j < len - 1 - i; j++) {
- if(arr[j] > arr[j+1]) {
- // 置換
- [arr[j], arr[j+1]] = [arr[j+1], arr[j]]
- }
- }
- }
- return arr
- }
經過優化的冒泡排序耗時:0.279052734375ms, 比之前稍微好了一丟丟, 但仍然不是推薦的排序算法.
2. 選擇排序
選擇排序的思路是找到數據結構中的最小值并將其放置在第一位,接著找到第二個最小值并將其放到第二位,依次類推.
我們還是按照之前的模式,生成一個60項的數組, 如下:
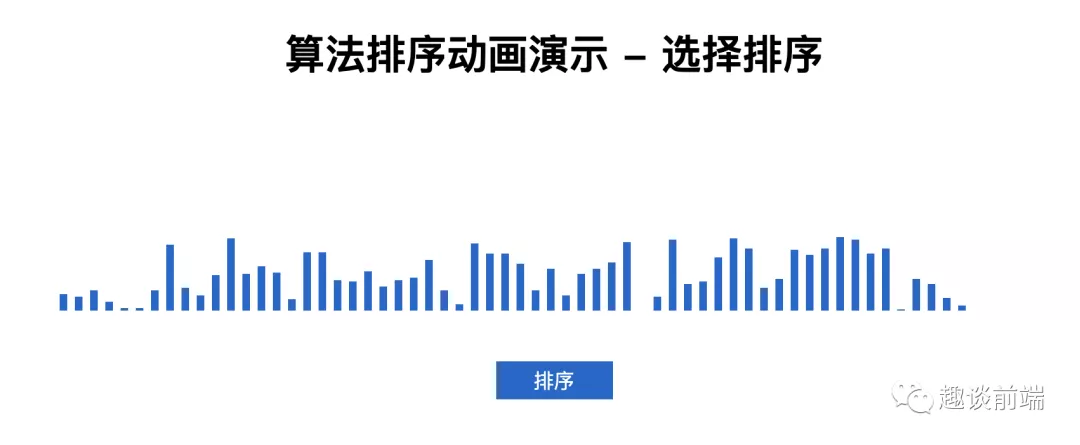
選擇排序代碼如下:
- selectionSort(arr) {
- let len = arr.length,
- indexMin
- for(let i = 0; i< len -1; i++) {
- indexMin = i
- for(let j = i; j < len; j++){
- if(arr[indexMin] > arr[j]) {
- indexMin = j
- }
- }
- if(i !== indexMin) {
- [arr[i], arr[indexMin]] = [arr[indexMin], arr[i]]
- }
- }
- return arr
- }
點擊排序時, 結果如下:
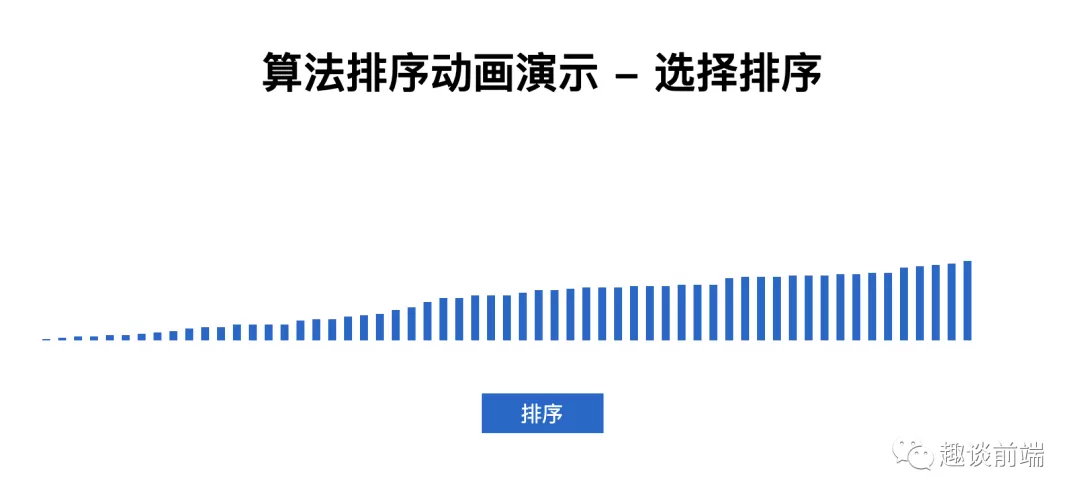
說明代碼運行正常, 可以實現排序, 控制臺耗時為: 0.13720703125ms, 明顯比冒泡排序性能要好.
3. 插入排序
插入排序 的思路是每次排一個數組項,假定第一項已經排序,接著它和第二項比較, 決定第二項的位置, 然后接著用同樣的方式決定第三項的位置, 依次類推, 最終將整個數組從小到大依次排序.
代碼如下:
- insertionSort(arr) {
- let len = arr.length,
- j,
- temp;
- for(let i = 1; i< len; i++) {
- j = i
- temp = arr[i]
- while(j > 0 && arr[j-1] > temp) {
- arr[j] = arr[j-1]
- j--
- }
- arr[j] = temp;
- }
- }
執行結果如下:
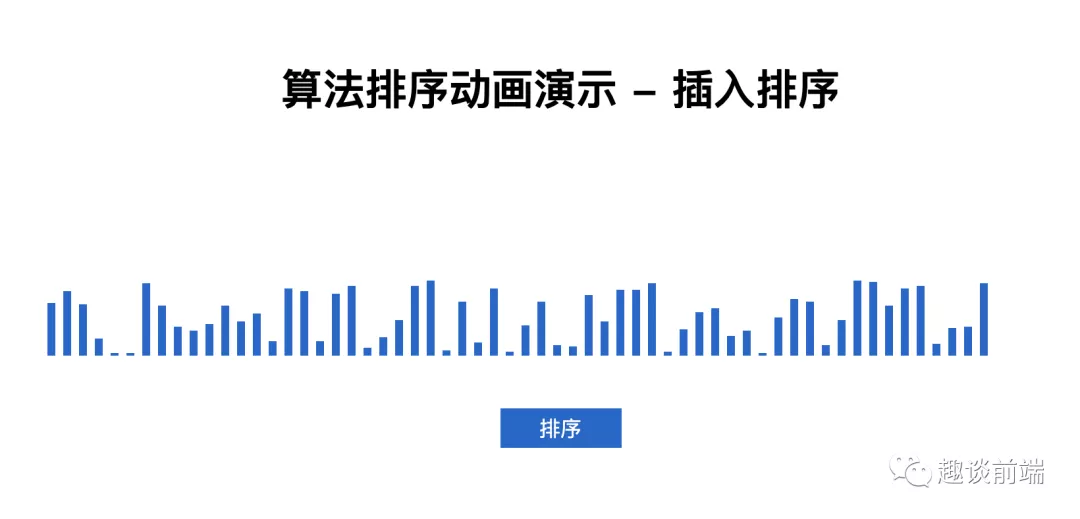

控制臺打印耗時為:0.09912109375ms.
4. 歸并排序
歸并排序算法性能比以上三者都好, 可以在實際項目中投入使用,但實現方式相對復雜.
歸并排序是一種分治算法,其思想是將原始數組切分成較小的數組,直到每個小數組只有一個元素,接著將小數組歸并成較大的數組,最后變成一個排序完成的大數組。
其實現過程如下圖所示:
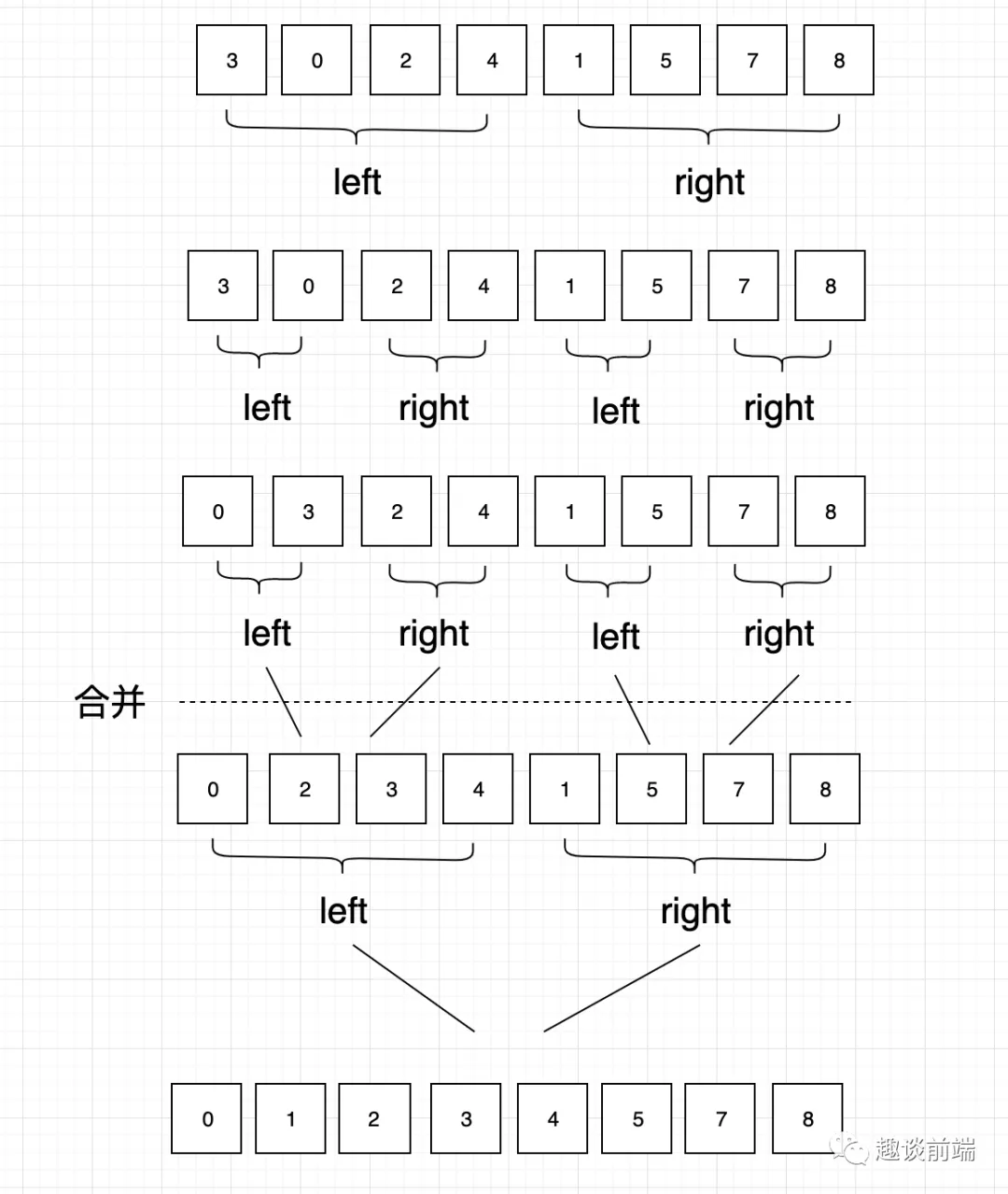
為了實現該方法我們需要準備一個合并函數和一個遞歸函數,具體實現如下代碼:
- // 歸并排序
- mergeSortRec(arr) {
- let len = arr.length
- if(len === 1) {
- return arr
- }
- let mid = Math.floor(len / 2),
- left = arr.slice(0, mid),
- right = arr.slice(mid, len)
- return merge(mergeSortRec(left), mergeSortRec(right))
- }
- // 合并方法
- merge(left, right) {
- let result = []
- l = 0,
- r = 0;
- while(l < left.length && r < right) {
- if(left[l] < right(r)) {
- result.push(left[l++])
- }else {
- result.push(right[r++])
- }
- }
- while(l < left.length) {
- result.push(left[l++])
- }
- while(r < right.length) {
- result.push(right[r++])
- }
- return result
- }
以上代碼中的遞歸作用是將一個大數組劃分為多個小數組直到只有一項,然后再逐層進行合并排序。如果有不理解的可以和筆者交流或者結合筆者畫的草圖進行理解。
5. 快速排序
快速排序是目前比較常用的排序算法,它的復雜度為O(nlog^n),并且它的性能比其他復雜度為O(nlog^n)的好,也是采用分治的思想,將原始數組進行劃分,由于快速排序實現起來比較復雜,這里講一下思路:
- 從數組中選擇中間項作為主元
- 創建兩個指針,左邊一個指向數組第一項,右邊一個指向數組最后一項,移動左指針直到我們找到一個比主元大的元素,移動右指針直到找到一個比主元小的元素,然后交換它們的位置,重復此過程直到左指針超過了右指針
- 算法對劃分后的小數組重復1,2步驟,直到數組完全排序完成。
代碼如下:
- // 快速排序
- quickSort(arr, left, right) {
- let index
- if(arr.length > 1) {
- index = partition(arr, left, right)
- if(left < index - 1) {
- quickSort(arr, left, index -1)
- }
- if(index < right) {
- quickSort(arr, index, right)
- }
- }
- }
- // 劃分流程
- partition(arr, left, right) {
- let part = arr[Math,floor((right + left) / 2)],
- i = left,
- j = right
- while(i <= j) {
- while(arr[i] < part) {
- i++
- }
- while(arr[j] > part) {
- j--
- }
- if(i <= j) {
- // 置換
- [arr[i], arr[j]] = [arr[j], arr[i]]
- i++
- j--
- }
- }
- return i
- }
7. 順序搜索
搜索算法也是我們經常用到的算法之一,比如我們需要查找某個用戶或者某條數據,不管是在前端還是在后端,都會使用搜索算法。我們先來介紹最簡單也是效率最低的順序搜索,其主要思想是將每一個數據結構中的元素和我們要查詢的元素做比較,然后返回指定元素的索引。
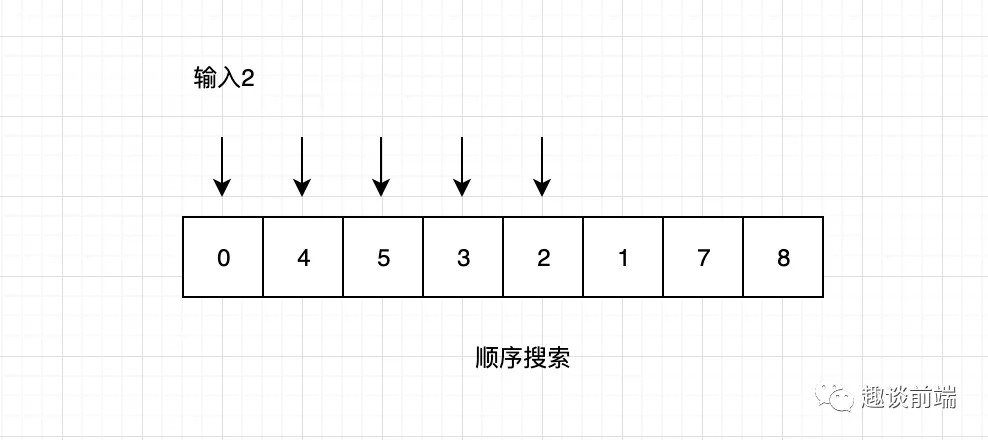
之所以說順序搜索效率低是因為每次都要從數組的頭部開始查詢,直到查找到要搜索的值,整體查詢不夠靈活和動態性。順序搜索代碼實現如下:
- sequentialSearch(arr, item) {
- for(let i = 0; i< arr.length; i++) {
- if(item === arr[i]) {
- return i
- }
- }
- return -1
- }
接下來我們看下面一種比較常用和靈活的搜索算法——二分搜索。
8. 二分搜索
二分搜索的思想有點“投機學”的意思,但是它是一種有理論依據的“投機學”。首先它要求被搜索的數據結構已排序,其次進行如下步驟:
- 找出數組的中間值
- 如果中間值是待搜索的值,那么直接返回中間值的索引
- 如果待搜索的值比中間值小,則返回步驟1,將區間范圍縮小,在中間值左邊的子數組中繼續搜索
- 如果待搜索的值比選中的值大,則返回步驟1,將區間范圍縮小,在中間值右邊的子數組中繼續搜索
- 如果沒有搜到,則返回-1
為了方便理解筆者畫了如下草圖:
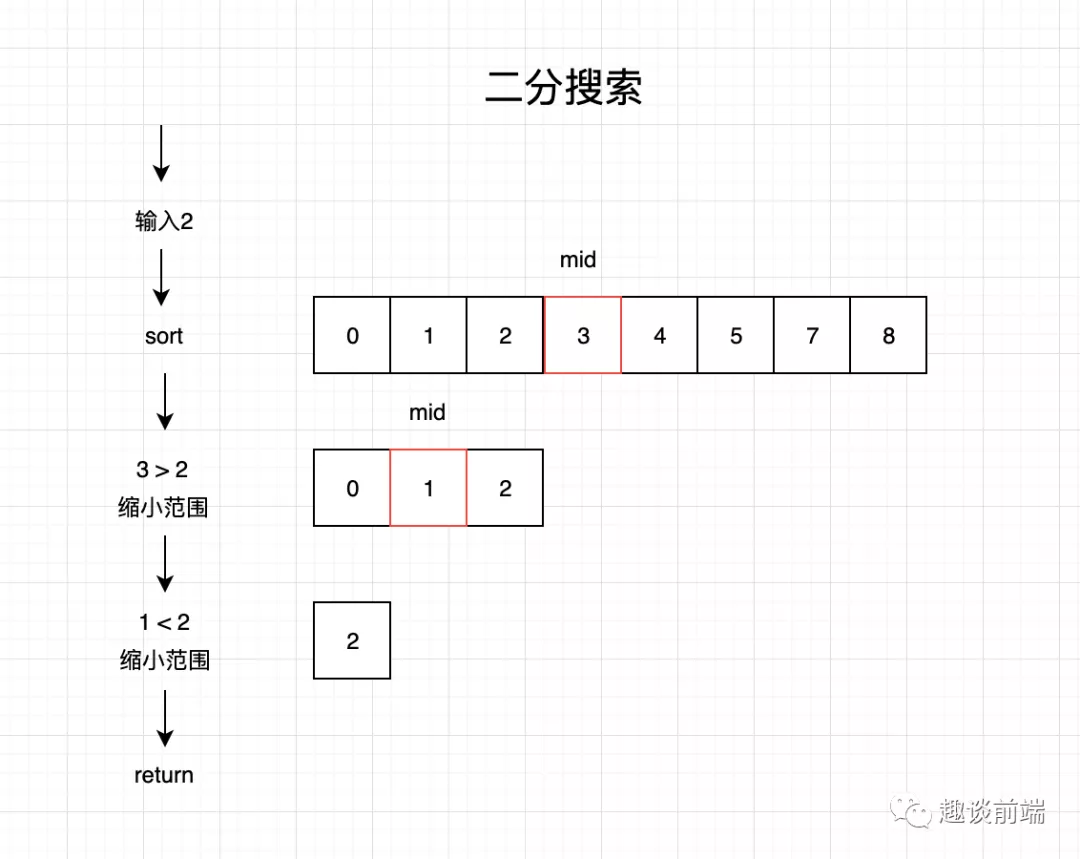
由上圖大家可以很容易的理解二分搜索的實現過程,接下來我們看下代碼實現:
- binarySearch(arr, item) {
- // 調用排序算法先對數據進行排序
- this.quickSort(arr)
- let min = 0,
- max = arr.length - 1,
- mid,
- el
- while(min <= max) {
- mid = Math.floor((min + max) / 2)
- el = arr[mid]
- if(el < item) {
- min = mid + 1
- }else if(el > item) {
- max = mid -1
- }else {
- return mid
- }
- }
- return -1
- }
其實還有很多搜索算法,筆者在js基本搜索算法實現與170萬條數據下的性能測試有具體介紹。
參考文獻:Learning JavaScript Data Structures and Algorithms
本文轉載自微信公眾號「趣談前端」