清華打造足球AI:首次實(shí)現(xiàn)同時(shí)控制10名球員完成比賽,勝率94.4%
本文經(jīng)AI新媒體量子位(公眾號(hào)ID:QbitAI)授權(quán)轉(zhuǎn)載,轉(zhuǎn)載請(qǐng)聯(lián)系出處。
“只見4號(hào)球員在隊(duì)友的配合下迅速攻破后防,單刀直入,一腳射門,球,進(jìn)了!”
觀眾朋友們大家好,您現(xiàn)在看到的是谷歌AI足球比賽的現(xiàn)場,場上身著黃色球衣的是來自清華大學(xué)的AI球員。
這屆清華AI可不一般,他們?cè)谄D苦訓(xùn)練之下,不僅有個(gè)人能力突出的明星球員,也有世界上最強(qiáng)最緊密的團(tuán)隊(duì)合作。
在多項(xiàng)國際比賽中所向披靡,奪得冠軍。
“Oh,現(xiàn)在7號(hào)接過隊(duì)友傳來的助攻,臨門一腳,球又進(jìn)了!”
言歸正傳,以上其實(shí)是清華大學(xué)在足球游戲中打造的一個(gè)強(qiáng)大的多智能體強(qiáng)化學(xué)習(xí)AI——TiKick。
在多項(xiàng)國際賽事中奪得冠軍則是指,TiKick在單智能體控制和多智能體控制上均取得了SOTA性能,并且還是首次實(shí)現(xiàn)同時(shí)操控十個(gè)球員完成整個(gè)足球游戲。
這支強(qiáng)大的AI團(tuán)隊(duì)是如何訓(xùn)練出來的呢?
從單智能體策略中進(jìn)化出的多智能體足球AI
在此之前,先簡單了解一下訓(xùn)練所用的強(qiáng)化學(xué)習(xí)環(huán)境,也就是這個(gè)足球游戲:Google Research Football(GRF)。
它由谷歌于2019年發(fā)布,提供基于物理的3D足球模擬,支持所有主要的比賽規(guī)則,由智能體操控其中的一名或多名足球運(yùn)動(dòng)員與另一方內(nèi)置AI對(duì)戰(zhàn)。
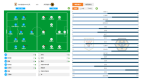
在由三千步組成的上下半場比賽中,智能體需要不斷決策出移動(dòng)、傳球、射門、盤球、鏟球、沖刺等19個(gè)動(dòng)作完成進(jìn)球。
在這樣的足球游戲環(huán)境中進(jìn)行強(qiáng)化學(xué)習(xí)難度有二:
一是因?yàn)槎嘀悄荏w環(huán)境,也就是一共10名球員(不含守門員)可供操作,算法需要在如此巨大的動(dòng)作空間中搜索出合適的動(dòng)作組合;
二是大家都知道足球比賽中一場進(jìn)球數(shù)極少,算法因此很難頻繁獲得來自環(huán)境的獎(jiǎng)勵(lì),訓(xùn)練難度也就大幅增大。
而清華大學(xué)此次的目標(biāo)是控制多名球員完成比賽。
他們先從Kaggle在2020年舉辦的GRF世界錦標(biāo)賽中,觀摩了最終奪得冠軍的WeKick團(tuán)隊(duì)數(shù)萬場的自我對(duì)弈數(shù)據(jù),使用離線強(qiáng)化學(xué)習(xí)方法從中學(xué)習(xí)。
這場錦標(biāo)賽只需控制場中的一名球員進(jìn)行對(duì)戰(zhàn)。
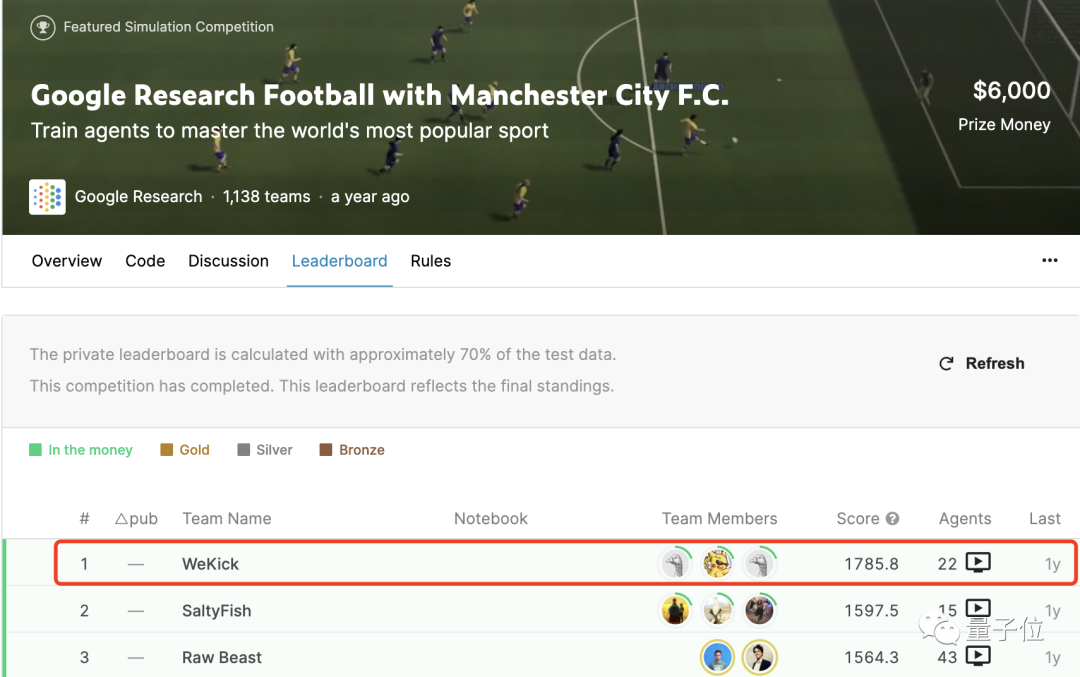
如何從單智能體數(shù)據(jù)集學(xué)習(xí)出多智能體策略呢?
直接學(xué)習(xí)WeKick中的單智能體操作并復(fù)制到每個(gè)球員身上顯然不可取,因?yàn)檫@樣大家都只會(huì)自顧自地去搶球往球門沖,根本就不會(huì)有團(tuán)隊(duì)配合。
又沒有后場非活躍球員動(dòng)作的數(shù)據(jù),那怎么辦?
他們?cè)趧?dòng)作集內(nèi)添加了第二十個(gè)動(dòng)作:build-in,并賦予所有非活躍球員此標(biāo)簽(比賽中若選用build-in作為球員的動(dòng)作,球員會(huì)根據(jù)內(nèi)置規(guī)則采取行動(dòng))。
接著采用多智能體行為克隆(MABC)算法訓(xùn)練模型。
對(duì)于離線強(qiáng)化學(xué)習(xí)來說,最核心的思想是找出數(shù)據(jù)中質(zhì)量較高的動(dòng)作,并加強(qiáng)對(duì)這些動(dòng)作的學(xué)習(xí)。
所以需在計(jì)算目標(biāo)函數(shù)時(shí)賦予每個(gè)標(biāo)簽不同的權(quán)重,防止球員傾向于只采用某個(gè)動(dòng)作作為行動(dòng)。
這里的權(quán)重分配有兩點(diǎn)考慮:
一是從數(shù)據(jù)集中挑選出進(jìn)球數(shù)較多的比賽、只利用這些高質(zhì)量的數(shù)據(jù)來訓(xùn)練,由于獎(jiǎng)勵(lì)較為密集,模型能夠加速收斂并提高性能。
二是訓(xùn)練出Critic網(wǎng)絡(luò)給所有動(dòng)作打分,并利用其結(jié)果計(jì)算出優(yōu)勢(shì)函數(shù),然后給予優(yōu)勢(shì)函數(shù)值大的動(dòng)作較高的權(quán)重,反之給予較低的權(quán)重。
此處為了避免梯度爆炸與消失,對(duì)優(yōu)勢(shì)函數(shù)做出了適當(dāng)?shù)牟眉簟?/p>
最終的分布式訓(xùn)練架構(gòu)由一個(gè)Learner與多個(gè)Worker構(gòu)成。
其中Learner負(fù)責(zé)學(xué)習(xí)并更新策略,而Worker負(fù)責(zé)搜集數(shù)據(jù),它們通過gRPC進(jìn)行數(shù)據(jù)、網(wǎng)絡(luò)參數(shù)的交換與共享。
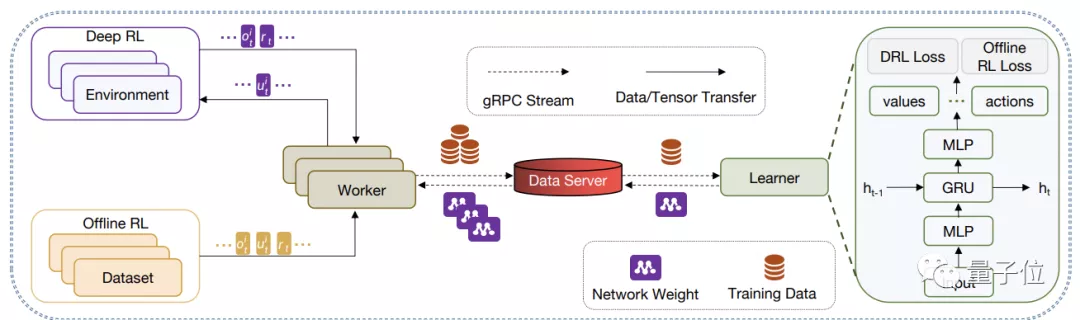
Worker可以利用多進(jìn)程的方式同時(shí)與多個(gè)游戲環(huán)境進(jìn)行交互,或是通過I/O同步讀取離線數(shù)據(jù)。
這種并行化的執(zhí)行方式,也就大幅提升了數(shù)據(jù)搜集的速度,從而提升訓(xùn)練速度 (5小時(shí)就能達(dá)到別的分布式訓(xùn)練算法兩天才能達(dá)到的同等性能)。
另外,通過模塊化設(shè)計(jì),該框架還能在不修改任何代碼的情況下,一鍵切換單節(jié)點(diǎn)調(diào)試模式和多節(jié)點(diǎn)分布式訓(xùn)練模式,大大降低算法實(shí)現(xiàn)和訓(xùn)練的難度。
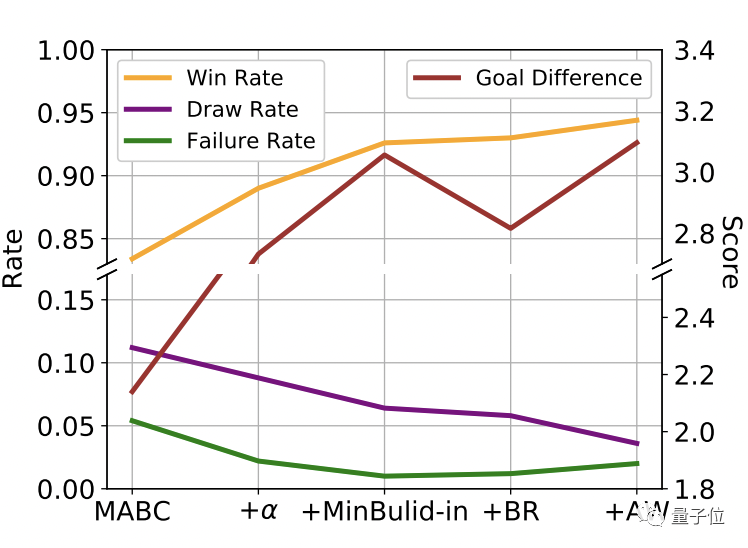
94.4%的獲勝率和場均3分的凈勝分
在多智能體(GRF)游戲上的不同算法比較結(jié)果中,TiKick的最終算法(+AW)以最高的獲勝率(94.4%)和最大的目標(biāo)差異達(dá)到了最佳性能。
TrueSkill(機(jī)器學(xué)習(xí)中競技類游戲的排名系統(tǒng))得分也是第一。

TiKick與內(nèi)置AI的對(duì)戰(zhàn)分別達(dá)到了94.4%的勝率和場均3分的凈勝分。
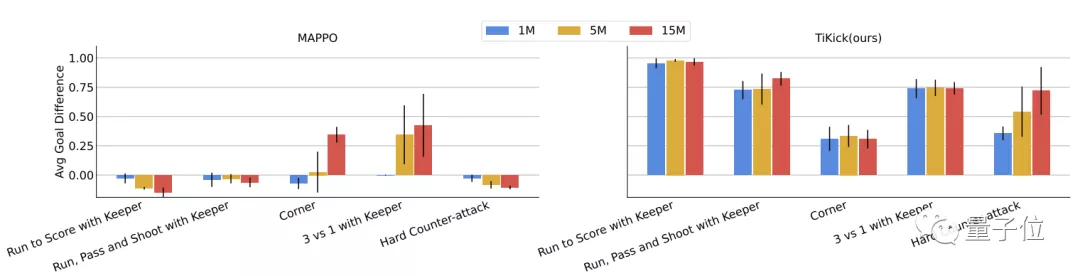
將TiKick與GRF學(xué)術(shù)場景中的基線算法進(jìn)行橫向比較后發(fā)現(xiàn),TiKick在所有場景下都達(dá)到了最佳性能和最低的樣本復(fù)雜度,且差距明顯。

與其中的基線MAPPO相比還發(fā)現(xiàn),在五個(gè)場景當(dāng)中的四個(gè)場景都只需100萬步就能達(dá)到最高分?jǐn)?shù)。
作者介紹
一作黃世宇,清華大學(xué)博士生,研究方向?yàn)橛?jì)算機(jī)視覺、強(qiáng)化學(xué)習(xí)和深度學(xué)習(xí)的交叉領(lǐng)域。曾在華為諾亞方舟實(shí)驗(yàn)室、騰訊AI、卡內(nèi)基梅隆大學(xué)和商湯工作。
共同一作也是來自清華大學(xué)的陳文澤。
此外,作者還包括來自國防科技大學(xué)的Longfei Zhang、騰訊AI實(shí)驗(yàn)室的Li Ziyang 、Zhu Fengming 、Ye Deheng、以及清華大學(xué)的Chen Ting。
通訊作者為清華大學(xué)的朱軍教授。
論文地址:
https://arxiv.org/abs/2110.04507
項(xiàng)目地址:
https://github.com/TARTRL/TiKick
參考鏈接:
https://zhuanlan.zhihu.com/p/421572915