不知道 Insert Buffer 的請舉手
Buffer Pool 緩沖池回顧
在講插入緩沖這個振奮人心的 InnoDB 新特性之前,我們有必要先來回顧下 Buffer Pool(緩存池)的概念。
前文說過,InnoDB 存儲引擎是基于磁盤存儲的,并將其中的記錄按照頁的方式進行管理。因此可將其視為基于磁盤的數據庫系統(Disk-base Database)。為了緩解 CPU 與磁盤速度之間的矛盾,基于磁盤的數據庫系統通常使用緩沖池技術來提高數據庫的整體性能。
緩沖池其實就是一塊內存區域,沒什么特別的。
- 對于數據庫中頁的讀取操作,首先會將從磁盤讀到的頁存放在緩沖池中,這個過程也稱為將頁 FIX 在緩沖池中。這樣,下一次再讀相同的頁時,如果該頁是否在緩沖池中,則直接讀取該頁就行了,不用去磁盤上讀取。
- 對于數據庫中頁的修改操作,則首先修改在緩沖池中的頁,然后再以一定的頻率刷新到磁盤上。
簡單來說,緩沖池就是通過內存的速度來彌補磁盤速度較慢對數據庫性能的影響。
當然了,緩沖池畢竟不是無限大的,不能把所有的數據都存在緩沖池上面,InnoDB 通過一種稱為 Checkpoint 的機制來決定哪些數據該從緩沖池移出去(移到磁盤上),這個在前面文章中我們也解釋過啦,遺忘的小伙伴可以翻看下前文。
Insert Buffer 插入緩沖
Insert Buffer 這個名字可能會讓小伙伴們認為它是 Buffer Pool 中的一個組成部分。其實不然,Insert Buffer 是物理頁的一個組成部分,是一顆 B+ 樹,頁是存在磁盤中的,而 Buffer Pool 它是一塊內存區域。
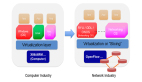
不過,需要注意的是,Buffer Pool 中會包含 Insert Buffer 的某些信息,來看下 InnoDB 存儲引擎的內存結構:
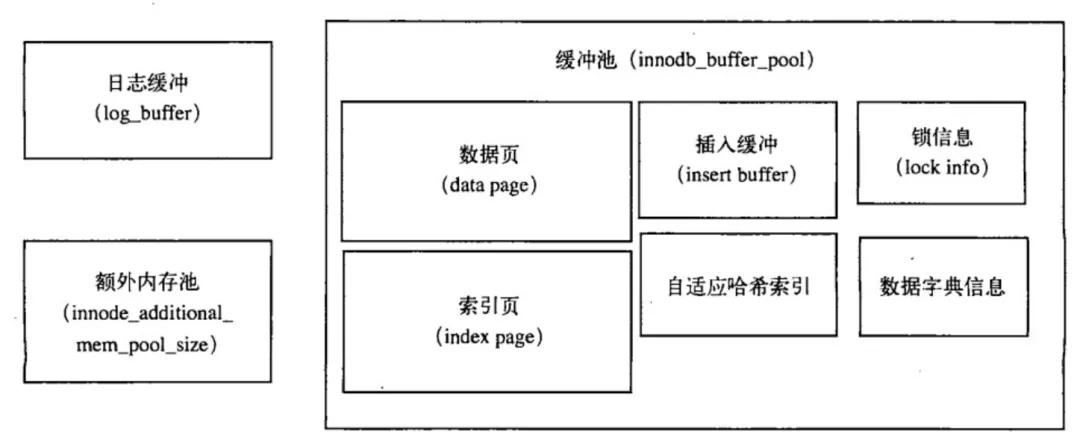
可以看到,Innodb Buffer Pool 包含的數據頁類型有:索引頁,數據頁,undo 頁,Insert Buffer,自適應哈希索引,鎖信息,數據字典信息等。
以問題為導向,對于 Insert Buffer,我們需要弄清楚的其實就 2 個問題:
- Insert Buffer 能解決什么問題?
- 什么情況下能夠使用 Insert Buffer?
通常,我們在建表的時候,都會給主鍵定一個自增長(AUTO_INCREMENT)的特性,也即主鍵按照遞增的順序進行插入。上篇文章講過,聚集索引一般建立在主鍵上面,也就是說,插入聚集索引一般是順序的,不需要經過磁盤的隨機讀取。
舉個例子:
- CREATE TABLE user(
- id INT(11) AUTO_INCREMENT,
- username VARCHAR(30),
- PRIMARY KEY(id)
- );
id 是自增長的主鍵,我們在插入一個新的行記錄的時候,無須對 id 賦值或者說賦 NULL 值,存儲引擎會幫助我們將這個值自動增長。
同時頁中的行記錄是按照主鍵 id 的值進行順序存放的,所以,在我們插入新的行記錄的時候,一般來說磁盤是不需要去隨機讀取另一個頁中的記錄的,因此速度非常快。
當然了,并不是說所有的主鍵插入都是順序的。有些業務場景下可能需要用 UUID 這種作為主鍵,即使它被定義了自增長類型,如果每次插入的都是通過 UUID 生成的指定值,而不是 NULL,那么顯然它的插入就是隨機的了。
這樣分析下來似乎我們的插入性能會比較好,但是,不可能一張數據庫表上只有一個聚集索引吧,還有其他的輔助索引呢。事實上,輔助索引也確實是影響插入性能的關鍵。
舉個例子,我們定義一個非聚集的且不是唯一的索引 username:
- CREATE TABLE user(
- id INT(11) AUTO_INCREMENT,
- username VARCHAR(30),
- PRIMARY KEY(id),
- key(username)
- );
在進行插入操作時,數據頁的存放確實還是按自增長的主鍵 id 來進行順序存放的,這沒錯。
但是,索引的本質是什么?是 B+ 樹,是一個存在磁盤上的物理文件。那我們在構建輔助索引 username 的這棵 B+ 樹的時候,非聚集索引葉子節點的插入不再是順序的了,也就是說要去離散地訪問磁盤頁了。
正是由于隨機讀取的存在導致了插入操作性能下降。
和 “不是所有的主鍵插入都是順序的” 類似,在某些情況下,輔助索引的插入可能也是順序的,或者說是比較有順序的。
比如用戶表中有一個時間字段,用來表示用戶買下某個物品的時間。在通常情況下,用戶購買時間是一個輔助索引,用來根據時間條件進行查詢。但是在插入時卻是根據時間的遞增而插入的,因此插入也是比較有順序的。
至此,講了半天好像還沒有看見 Insert Buffer 的影子?
別急,這就來。
InnoDB 存儲引擎開創性地設計了 Insert Buffer。對于輔助索引的插入或更新操作,并不是每一次直接插入到索引頁(磁盤頁)中,而是先判斷插入的輔助索引頁是否在 Buffer Pool 中:
- 若在,則直接插入;
- 若不在,則先將其放入到一個 Insert Buffer 對象中,就好像騙了數據庫一波:告訴數據庫這個輔助索引的葉子節點了已經插入成功了(磁盤上),但是實際上并沒有,只是存放在內存里的 Insert Buffer 中。
當然,不能將這個葉子節點一直存在 Insert Buffer 中,對吧,這個輔助索引的 B+ 樹終歸還是得建立起來的。具體來說,InnoDB 會以一定的頻率和情況進行 Insert Buffer 和輔助索引頁子節點的 Merge(合并)操作,這時,就相當于將多個葉子節點插入操作合并到一個操作中(因為在一個索引頁中),這就大大提高了對于輔助索引插入性能
簡單概括下:Insert Buffer 就是一棵 B+ 樹,若需要實現插入記錄的輔助索引頁不在 Buffer Pool 中,那么需要將輔助索引記錄首先插入到這棵 B+ 樹中,然后在適當的情況下將其合并(Merge)到真正的輔助索引中。
舉個現實生活中的例子來說:
我們去圖書館還書,對于圖書館管理員來說,他需要做的就是 insert 操作,管理員在 1 小時內接受了 100 本書,這時候他有 2 種做法把還回來的書歸位到書架上:
- 每還回來一本書,就把這本書送回架上
- 暫時不做歸位操作,等到空閑下來了,再把這些書一次性送回書架上
用方法 1,管理員需要進出圖書管 100 次,不停的登高爬低完成圖書歸位操作,累死累活,效率很差。
用方法 2,管理員只需要對要歸位的書進行一個分類,進出圖書管 1 次,對同一個位置的書,不管多少,都只要爬一次樓梯,大大減輕了管理員的工作量。
那么,什么條件下可以使用 Insert Buffer 以此來提高插入操作的性能呢?
- 索引是輔助索引
- 索引不是唯一索引
為什么 Insert Buffer 不適用于唯一的輔助索引呢?
一個很簡單的套娃問題(滑稽):
如果輔助索引是唯一的,那么當把要插入的對象存到 Insert Buffer 時,數據庫就需要去磁盤上查找索引頁來判斷插入記錄的唯一性,顯然,如果去查找就會有離散讀取的情況發生,從而導致 Insert Buffer 失去了意義。
還以圖書管那個例子來說:
如果圖書館中所有的書只允許存在一本,那我們還一本書到圖書館的時候,管理員就必須爬到圖書管的指定位置去確認判斷一下這本書是不是唯一的,這個過程就相當于產生了一次 IO 操作了。
另外,Insert Buffer 有利有弊,考慮一種極端情況:
如果數據庫中涌入了大量的插入操作,并且這些都涉及了不唯一的非聚集索引,也就是使用了 Insert Buffer。若此時數據庫崩潰了,這時勢必有大量的 Insert Buffer 沒有被合并到實際的輔助索引中去,那么這時候的恢復就可能需要很長的時間。
Change Buffer
InnoDB 從 1.0.x 版本開始引入了 Change Buffer,現在有些博客上說的也是 Change Buffer,容易讓小白懵逼,其實就是 Insert Buffer 的升級版。
從這個版本開始,InnoDB 存儲引擎可以對 DML 操作 — INSERT、DELETE、UPDATE 都進行緩沖,他們分別對應的是:Insert Buffer、Delete Buffer、Purge buffer
同樣的,和之前 Insert Buffer 一樣,Change Buffer 適用的對象依然是非唯一的輔助索引。
對一條記錄進行 UPDATE 操作可能分為兩個過程:
- 將記錄標記為已刪除:對應 Delete Buffer
- 真正將記錄刪除:對應 Purge Buffer