一文講清MySQL中的二級索引
主鍵索引是InnoDB存儲引擎默認給我們創建的一套索引結構,我們表里的數據也是直接放在主鍵索引里,作為葉子節點的數據頁。
但我們在開發的過程中,往往會根據業務需要在不同的字段上建立索引,這些索引就是二級索引,今天我們就給大家講講二級所有的原理。
比如,你給name字段加了一個索引,你插入數據的時候,就會重新搞一棵B+樹,B+樹的葉子節點,也是數據頁,但是這個數據頁里僅僅放了主鍵字段和name字段。
葉子節點的數據頁的name值,跟主鍵索引一樣的,都是按照大小排序的。同一個數據頁里的name字段值都是大于上一個數據頁里的name字段值。
name字段的B+樹也會構建多層索引頁,這個索引頁里放的是下一層的頁號和最小name字段值。就像這樣:
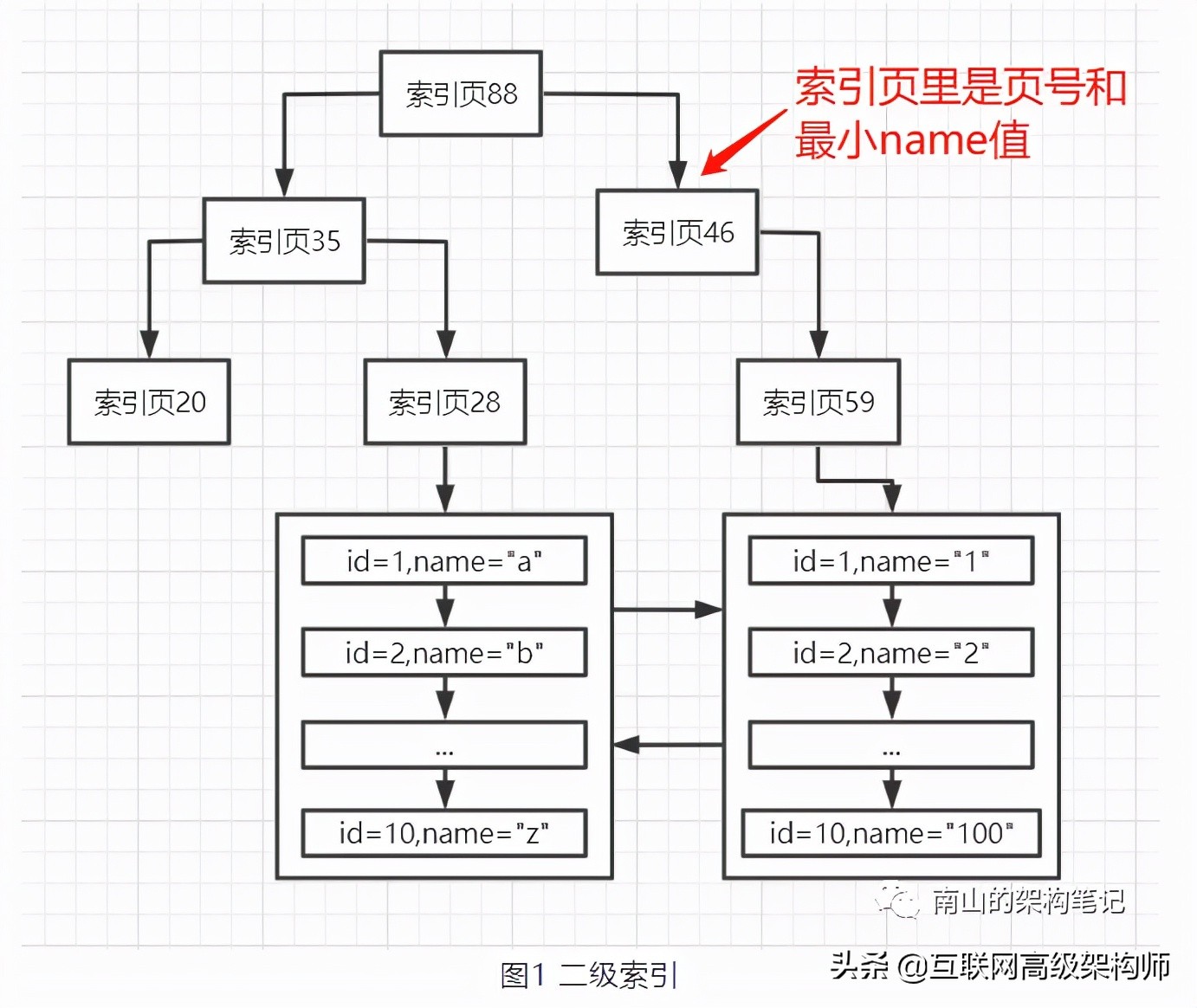
假設你要根據name字段來搜索數據,比如:select * from user where name=‘xxx',過程與主鍵索引一樣的。從name索引的根節點開始找,一層一層的向下找,一直找到葉子節點,定位到name字段值對應的主鍵值。
但此時葉子節點的數據頁沒有完整所有字段,就需要根據主鍵到主鍵索引里去查找,從主鍵索引的根節點一路找到葉子節點,就可以找到這行數據的所有字段了,這個過程就叫回表。
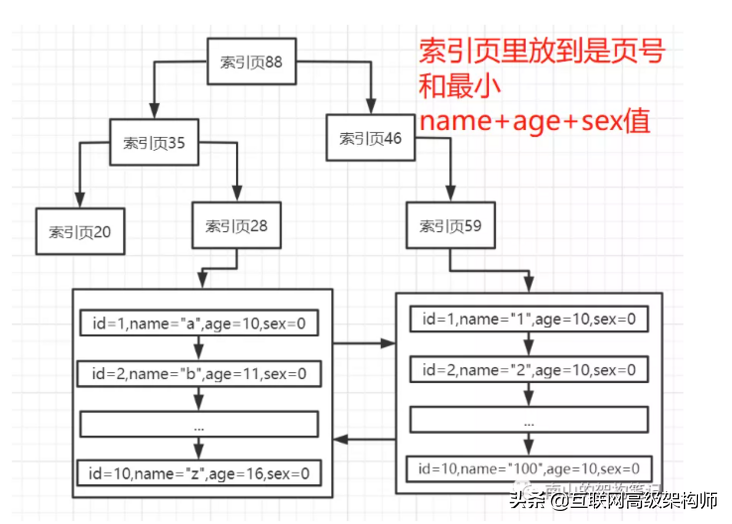
二級索引,可以對多個字段建立聯合索引,比如,name + age + sex
此時聯合索引與單個字段的索引原理是一樣的,只不過葉子節點的數據頁里放的是id + name + age + sex,然后默認按照name排序,name一樣就按age排序,age一樣就按sex排序。
每個name + age +sex的索引頁里,放的就是下層節點的頁號和最小的name + age + sex值。當你用name + age + sex搜索的時候,就會走name + age + sex聯合索引這棵樹,再回表查詢。
以上就是innoDB二級索引的原理了,有沒有感覺也不過如此?
索引的利弊
隨著我們不停的在表里插入數據,就會不停的在數據頁里插入數據,然后一個數據頁放滿了就會分裂成多個數據頁,這個時候就需要索引頁去指向各個數據頁。
如果數據頁太多了,那么索引頁里的數據頁指針也就會太多了,索引頁也必然會放滿的,此時索引頁也會分裂成多個,再形成更上層的索引頁。
這個過程跟主鍵索引是一模一樣的,所以你如果搞懂了主鍵索引,二級索引也很簡單的。
索引的好處是顯而易見的,查找數據的時候不需要全表掃描,性能是很高的。
但索引也有其缺點,如果用的不好,反而對會有副作用。
首先,要創建索引,就要占用存儲空間。我們每創建一個索引,MySQL就會搞出一個B+樹,每棵B+樹都要占用很多的磁盤空間啊,所以搞太多索引,也是很耗費磁盤空間的。
其次,你在進行增刪改查的時候,每次都需要維護各個索引的數據有序性,因為每個B+樹都要求頁內是按照值大小來排序的,頁之間也是有序的。所以你不停的增刪改查,各個索引的數據頁要不停的分裂、增加新的索引頁,如果你一個表里搞太多索引,增刪改的性能就會比較差
所以綜合上面兩個原因,我們不建議給一張表搞太多索引的。
聯合索引查詢原理
之所以要講聯合索引的查詢原理,是想帶著讀者們更清晰的理解索引的工作原理,我們平時設計索引也大多是設計的聯合索引。
假如有一個索引KEY(class, name, course),對學生班級、姓名、科目名稱建立的聯合索引。聯合索引的示意圖如下:
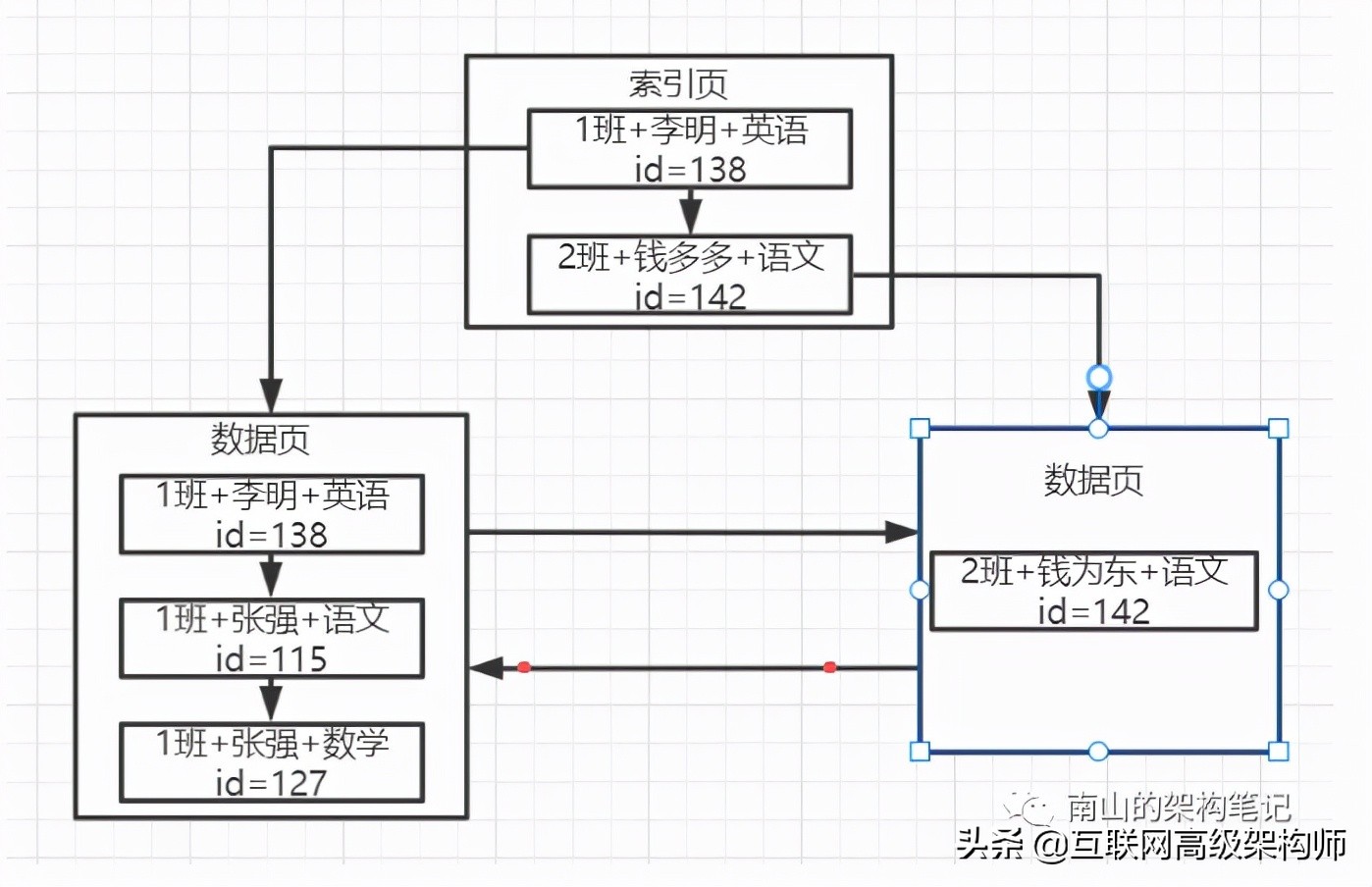
每個數據頁都包含了聯合索引的三個字段值和主鍵值,數據頁內部也是按照順序來排序的。
首先按照班級值來排序,如果一樣則按照學生姓名來排序,如果一樣,則按照科目名稱來排序,所以數據頁內部都是按照這三個字的值來排序的。
數據頁內部與數據頁之間也是有序的,數據頁內部組成單向鏈表,數據頁之間組成雙向鏈表。
圖中索引頁分別指向兩個數據頁,索引頁放的是數據頁里最小的那個數據值。
假如我們要執行語句:select * from student where class='1班‘ and student_name='張強' and course_name='數學'。
查詢時先到索引頁里去找,索引頁里有多個數據頁的最小值記錄,此時直接在索引頁里基于二分查找方法來找就可以了,先根據班級名來找1班這個值對應的數據頁,直接可以定位到所在的數據頁。
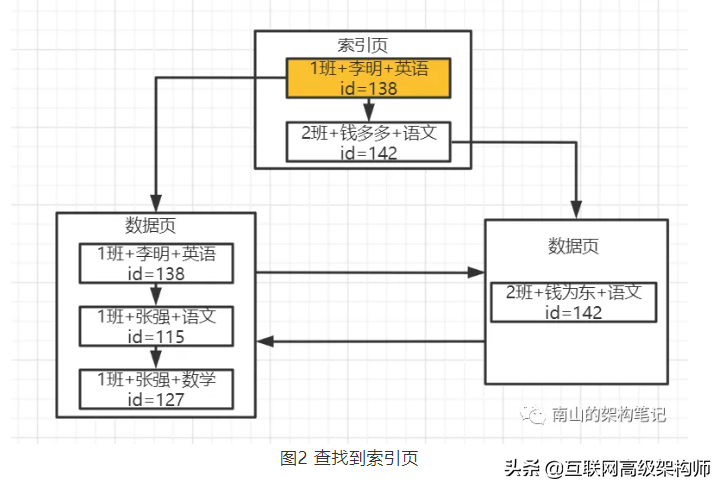
然后就可以找到索引指向的那個數據頁就可以了,在數據頁內部是一個單向鏈表, 你也是基于二分查找就可以了,先按1班這個值查詢,你發現有幾條數據都是1班,然后按照張強這個學生姓名查找,發現也有多條數據,接著按照科目名稱來二分查找。
很快就定位到一條數據了,對應的就是圖中的id=127的數據。
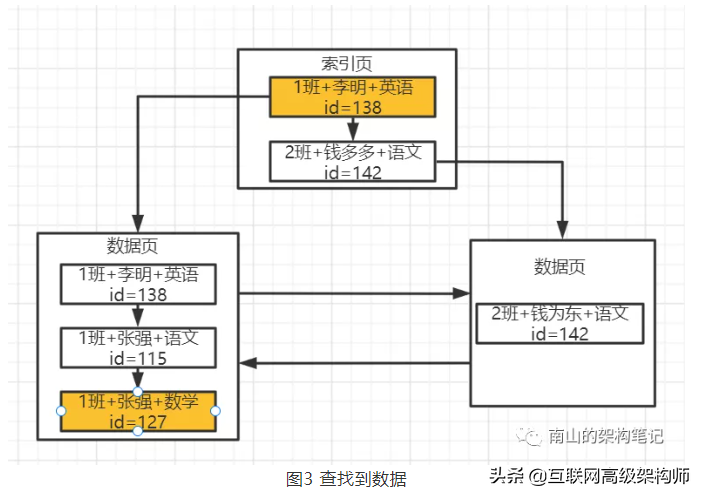
然后根據主鍵id=127回表查找完整的字段,在主鍵索引開始二分查找迅速定位到各層級的索引頁,再逐步向下定位到id=127的那條數據,就可以拿到所有字段的值了。
上面的過程就是聯合索引的查找過程。對于聯合索引,就是一次安裝各個字段來進行二分查找,先定位到第一個字段對應的值在哪個頁,如果第一個字段值一樣,就按第二個字段值來查找,以此類推,就找到最終的數據了。