一文講清大模型AI應用架構
本文轉載自微信公眾號「 產品二姐」,作者產品二姐。轉載本文請聯系產品二姐公眾號。
如果說 2023 年是大模型大爆發的一年,這一年的機會主要給了大廠或者拿到大筆融資的創業者;那么 2024 年將是 AI 應用大爆發的一年,也意味著普通人有更多的機會加入這一浪潮。今天結合基于大模型的 AI 產品架構來看看普通人的機會在哪里,這些普通人包括:
- AI 應用開發者
- AI 產品經理、提示詞工程師
- 希望通過 AI 來提效增收的中小老板
在講述 AI 產品架構之前,我們先來看看客戶的訴求。因為一切的設計都是從需求出發,大模型AI 產品也不例外。
1、從 AI 產品的訴求出發看 AI 產品設計
最近接觸到最多的訴求是:如何基于自己的知識庫構建自己的問答機器人,比如:
- 繪本館老板希望通過機器人對話來推薦書籍,提高社群活躍度。
- 面向大學生的留學咨詢機構希望通過機器人解答專業論文難題來獲取留學線索。
- 企業內部的 HR 希望通過機器人來進行日常的答疑解惑。
實際上,這些需求早已存在,只是一直沒有被很好地解決,大模型之前做出來的機器人是"人工智障",大模型出來之后,"人工智障"變成了"人工幻覺"。可喜的是現在"幻覺"這一現象某種程度上正在被更好地解決,這一點本文會講到,而解決幻覺問題也是 2024 年 AI 技術的一大趨勢。
1.1為什么不用 ChatGPT
你可能會說:問答工具用 ChatGPT 不就好了嗎?
但如果你讓一個繪本館老板評價 ChatGPT 推薦書籍的能力,他估計會一笑了之,一是 ChatGPT 的推薦能力值得商榷,二是 ChatGPT 并不能讓用戶落在自己的繪本館里。繪本館老板真正的訴求是:
- 為什么 ChatGPT 不能按照我的資料庫推薦,我的資料比 ChatGPT 專業多了。
- 我有精準的用戶數據,比如用戶之前看了什么書,用戶的孩子多大了,而且還要結合館內的庫存狀態給每個用戶做不同的推薦。
- 我這里還有豐富的書籍的推薦話術,但是我希望結合每個客戶的不同習慣,同一本書籍用不同的話術推薦。
以上幾點構成了基于大模型 AI 產品的三個訴求:
- 個性化訴求:問答中所用到的知識庫和數據(客戶標簽,客戶閱讀歷史)希望用自己的。
- 需要結合傳統互聯網數據洞察能力給出更精準的回答。
- 強大的知識檢索、整合、表達能力,其實只有最后一點才是"大模型特色"的能力。
而解決這三個問題的背后要依托的是一個完整 AI 產品架構,架構的每一層里都可以負責解決不同的問題。
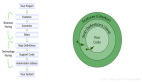
2、一圖說明基于大模型的 AI 產品架構
下面這張圖就是我總結的優秀的 AI 產品架構(以問答機器人為例),如果你比較了解 AI 應用的現狀,應該很容易理解。
 圖片
圖片
接下來的內容就主要圍繞這張圖的深入討論,你會發現看似簡單的產品背后其實并不容易。首先我們按照調用時序來展開產品每一層的動作,以及由誰來做哪些事情。
2.1用戶層(前端)提問
這一層的目標是營造良好的用戶體驗,主要是產品經理,UE,UI 負責,和傳統互聯網產品沒有區別。
需要注意的是,讓用戶感受不到 AI 的存在是最好的。在問答這個產品中,可能就是一個簡單的對話框,甚至可能融入微信、釘釘等產品中。而推送僅僅在必要時進行,比如在繪本館的這個例子中,我們僅僅在借閱書籍即將到期進行提醒,同時推薦合適的書籍。
當然,也有可能用戶會主動提問:"有哪些適合 3-5 歲男孩看的繪本",這時用戶層就會喚起應用層。
2.2應用層提問
這一層是不同于傳統互聯網的一層,也是 AI 應用開發者,產品經理的重頭戲。它的目標是將用戶的提問加工,發給適合模型層的 Prompt 提示詞,這里會分幾步走:
第一步:將 "有哪些適合 3-5 歲男孩看的繪本"這個問題轉化成專業提示詞。
比如按照 CRISPE 結構進行提問(CRISPE 是一種提示詞結構,可百度),這一步主要由提示詞工程師完成,在小產品中由產品經理兼任,提示詞能力是大模型 AI 產品經理的必備技能。
提示詞需要根據不同領域、不同場景、不同的知識庫、不同模型進行反復實驗,同時要具備結構化特征,抽象成模板,以適用于不同的參數值,比如把"3-5 歲"抽象為參數 Age,把"男孩"抽象為參數"gender" 。專業提示詞的目標是讓開發能用,同時還能讓應用給出的回答盡可能準確、可控。
以下是一個提示詞模板的示例(摘自 Github 9000 STAR 的項目:https://github.com/yzfly/wonderful-prompts?tab=readme-ov-file#prompt-%E5%B7%A5%E7%A8%8B%E5%B8%88) 。
 圖片
圖片
實際中你絕對不可能讓用戶輸入這么長的提示詞。作為產品經理出身,稍后也會有文章專門講提示詞的各種套路(關注我不迷路)。
第二步:根據提示詞去檢索客戶已有知識庫,數據庫的內容。
這一步是解決用戶的個性化訴求,即引用自有知識庫、數據庫內容,同時著重降低幻覺。
當下解決這一問題的武器主要是 RAG(Retrieval-Augmented Generation,檢索增強生成,Augmented AI 也被認為是 2024 年 AI 發展的大趨勢之一)。這一步的工作最繁重,會涉及三項:
- 第一項:客戶(希望通過 AI 來提效增收的中小老板)準備適合大模型理解和閱讀的知識庫,通常需要條理清晰,結構化,圖片視頻要配文字等,這里不僅僅是為了讓機器人的回答更準確,更重要的是一定程度上可以節約大模型 token 的消耗成本。后面會整理文章專門說這一點,或許也可以找到合適的工具來做這個事情。
- 第二項:主要是研發同學來做,負責知識庫導入、分塊、向量化處理(Embedding),建索引、檢索等,而這其中的每一步都有不同方法,且會影響回答的效果(參考文章《RAG行業交流中發現的一些問題和改進方法》)。
- 第三項:因為不同方法會有不同效果,所以最后還需要拉上產品經理同學一起進行評測(參考文章《LangChain應用開發指南-TruLens用量化對抗幻覺》)。
實際中,做好這三項是比較繁瑣、困難的,也需要進行大量的實驗。
第三步:將第一步、第二步里的內容合成提示詞,加上問答上下文等,形成新的提示詞。
所以最終你會看到客戶的一個簡短問題,變成了一個專業問題發給了大模型。這時一個新的問題誕生了,提示詞越長,token 消耗越高,成本就越高(試問一次提問消耗 1 塊錢還會不會有老板想用)所以提示詞壓縮的技術實踐也應運而生。
第四步:壓縮提示詞
目前這塊研究不多,暫時引用 知乎上的一篇文章《壓縮你的Prompt,讓LLMs處理多達2倍的Context》大家可以自行知乎搜索了解一下(公眾號不能鏈接外部文章)。
經過四步處理,提示詞終于來到了模型層。
2.3模型層:
在這一層會有兩種模型:
- 一是直接使用通用大模型,眾所周知,它是建立在算法算力數據上的基礎設施
- 二是垂直大模型(比如法律、醫學、電商的垂直大模型),2023"百模大戰"里的模型大部分屬于這種。這些大模型一般是在通用大模型基礎上進行有監督學習、強化學習改變大模型的參數,也就是我們說的"微調"。但"微調"的算力成本并不"微",對于普通個體來說,也沒啥機會。
這一層主要是大模型廠商們的機會。在應用側的產品經理、研發同學更應該關注的是"如何為自己的應用挑選合適的大模型",這其中要主要考慮能力匹配和成本因素。
- 能力匹配方面:可以參照各大模型評測機構的結果
- 成本方面:有個坑就是各大廠商的 token 的消耗量似乎尚未統一,甚至同一模型,同樣的提問, token 的消耗也不一樣,這一塊可能要做一些實驗才能得出結果。在經驗不足的時候,我們使用文心一言測試曾遭遇過一個問題一萬 token 的情況,合人民幣一塊錢。
接下來,就是生成回答的過程。
2.4生成回答的過程
這個過程比較簡單,主要集中在應用層收到模型層的回復后,需要做一層包裝,最終返回給用戶。這個包裝可能包括:
- 壓縮冗余信息:大模型一般會對自己的思路進行闡述,這是產品經理或者提示詞工程師調教時需要了解的信息,但對用戶來說不需要,所以需要壓縮。
- 結合客戶個性化需求,補充信息:比如在推薦書籍的同時,加上書籍的“在館狀態”等信息。
這一步也主要由產品經理來定義,與 UE,研發同學一起實現。
看完了整個過程,相信你對 AI 產品架構、架構每一層要實現的目標、主要角色和工作有了大概的理解。回應開頭的產品訴求來看:
- 個性化的訴求主要留給應用層的 RAG, 提示詞和傳統互聯網的思路來解決。模型層要做的是是否需要用垂直大模型。
- 強大的知識檢索、整合、表達能力主要由模型層來解決,主要考慮適用性和成本。
網上有個很好的比喻:模型相當于一個勤學苦讀的學生,學生要考試了,提示詞相當于解題技巧,RAG 相當于開卷考試中可以參考的資料。
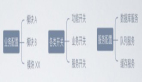
3、用人才成長階梯重新審視 AI 產品架構
我們也經常聽到一個比喻是"把大模型比作一個哈佛畢業的本科生"。我們以這個角色作為參照,再從底層到頂層來看大模型 AI 產品的架構,你會發現這其中每一層就像是從學校走向社會成為一個可用之才的過程。
 圖片
圖片
第一層:算法算力數據這一層相當于教育體系。這包括教學硬件(算力),優秀的老師(算法),和豐富的學習資源(數據)。
第二層:模型層相當于在這個教育體系下培養出來的本科生(通用大模型)、研究生(垂直大模型)。
不管是本科生,還是研究生,他們具備了強大的綜合知識,思維框架,和學習能力,還有一點,他們都是預訓練的,距離真正有用還有一點距離。
第三層:應用層是職業生涯的開始。
盡管畢業于同一專業,進入不同的公司,會有不同的業務領域。面對不同問題,會首先考慮公司是不是有現有資源(RAG)知識庫,再加上外部的通用知識,去提出解決方案。
可能在最初幾年,會迅速成長為一個領域專家。這個時候,通常是對客戶的問題進行專業分析,給出專業答案,但缺乏客戶的同理心,直接面對客戶會嚇跑客戶。
第四層:用戶層就是成為客戶喜歡的專家。
再過幾年,你開始會為客戶考慮,充分理解客戶的訴求,然后用客戶聽得懂的語言回答。最終成長為一個用戶喜歡的專家 ,這才是最終呈現給用戶的"產品"。
4、總結
寫到這里,也沒想到自己寫了這么長,過程中也給自己留了兩個作業:
1)AI 產品經理的知識結構之"提示詞工程",目前網上這一塊內容很多,大家可以參考 Github 9000star 的項目 ( https://github.com/yzfly/wonderful-prompts?tab=readme-ov-file#prompt-%E5%B7%A5%E7%A8%8B%E5%B8%88 )。后續會把自己一些特色實踐補上。
2)老板們如何準備適合大模型易讀的知識庫,這一塊內容不多,后面來補充。
最后來總結一下:
- 算法、算力、數據是科研教育機構的機會
- 模型層是大廠的機會
- 應用層才是大多數個體的機會。
你是否找到了自己的機會呢?