一張圖像百般變化,英偉達用GAN實現高精度細節P圖
在實現復雜且高精度圖像編輯效果的同時,EditGAN 還能保持較高的圖像質量和對象身份,英偉達在圖像處理領域果然「出手不凡」。
當前,AI 驅動的照片和圖像編輯技術有助于簡化攝影師和內容創作者的工作流程,并賦能更高水平的創意和數字藝術。基于 AI 的圖像編輯工具也已經以神經照片編輯過濾器(filter)的形式應用在消費級軟件上,并且深度學習研究社區積極地開發新的技術。其中,各式各樣基于生成對抗網絡(GAN)的模型和技術層出不窮,在實現原理上,領域研究人員要么將圖像嵌入到 GAN 的隱空間,要么直接使用 GAN 生成圖像。
大多數基于 GAN 的圖像編輯方法分為以下幾類。一些工作依賴于 GAN 在類標簽或像素級語義分割注釋上發揮作用,不同的條件會使輸出結果出現變動;另一些工作使用輔助的屬性分類器來指導圖像的合成和編輯。然而,訓練這種條件式 GAN 或外部分類器需要大規模的標注數據集。因此,這些方法目前僅適用于擁有大規模標注數據集的圖像類型,如肖像等。即使擁有足夠注釋的數據集,大多數方法也僅能提供有限的編輯控制,這是因為這些注釋通常僅包含高級的全局屬性或者比較粗糙的像素級分割。
另一些方法專注于對不同圖像的特征進行混合和插值,因此需要參照圖像作為編輯目標,通常也無法提供微調控制。還有一些方法仔細剖析 GAN 的隱空間,找出適合編輯的解耦隱變量或者控制 GAN 的網絡參數。但遺憾的是,這些方法無法實現精細的編輯,速度也通常較慢。
近日,英偉達、多倫多大學等機構在論文《EditGAN: High-Precision Semantic Image Editing》中克服了這些局限,并提出了一個全新的基于 GAN 的圖像編輯框架 EditGAN——通過允許用戶修改對象部件(object part)分割實現高精度的語義圖像編輯。
相關研究已被 NeurIPS 2021 會議接收,代碼和交互式編輯工具之后也會開源。

論文地址:https://arxiv.org/pdf/2111.03186.pdf
項目主頁:https://nv-tlabs.github.io/editGAN/
具體而言,EditGAN 在最近提出的 GAN 模型基礎上構建,不僅基于相同的潛在隱編碼來共同地建模圖像及其語義分割,而且僅需要 16 個標注示例,從而可以擴展至很多目標類和部件標簽。研究者根據預期編輯結果來修改分割掩碼,并優化隱編碼以與新的分割保持一致,這樣就可以高效地改變 RGB 圖像。
此外,為了實現效率,他們通過學習隱空間中的編輯向量(editing vector)來實現編輯,并在無需或僅需少量額外優化步驟的情況下直接在其他圖像上應用。因此,研究者預訓練了一個感興趣編輯的庫以使得用戶可以在交互工具中直接使用。
研究者表示,EditGAN 是首個同時實現以下目標的 GAN 驅動的圖像編輯框架:
提供非常高精度的編輯;
僅需極少量的標注訓練數據,并且不依賴額外的分類器;
實時交互運行;
多個編輯的直接語義合成;
在真實的嵌入式、GAN 生成的甚至域外(out-of-domain)圖像上運行。
研究者在包括汽車、貓、鳥和人臉等在內的廣泛圖像上應用了 EditGAN,最終都展現出了前所未有的高精度編輯。他們還將 EditGAN 與多個基準方法進行定量比較,并在身份和質量保持、目標屬性準確性等指標上勝過它們,同時需要的標注訓練數據少了數個量級。
在項目主頁中,研究者展示了多個 EditGAN 相關的 Demo 視頻,如下動圖(左)為編輯向量插值效果,圖(右)為在域外圖像上應用 EditGAN 編輯向量的效果。

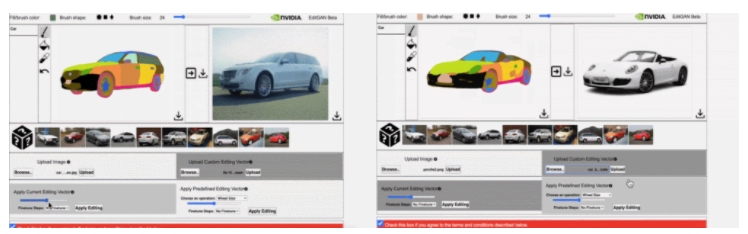
下圖(左)為交互 demo 工具中使用 EditGAN 的效果,圖(右)為使用 EditGAN 時可以實現多個編輯和預定義編輯向量。
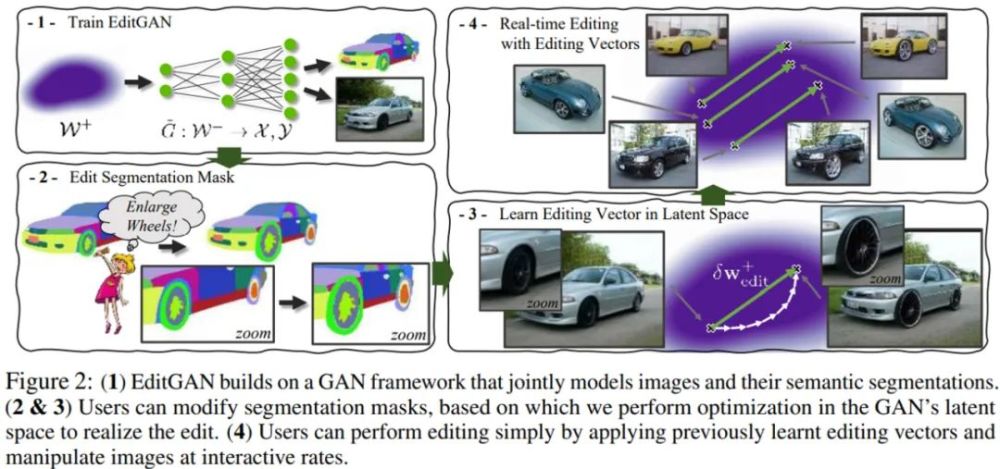
使用 EditGAN 如何完成高精度語義圖像編輯?
下圖 2(1)為訓練 EditGAN 的流程;圖 2(2&3)分別為編輯分割掩碼和利用編輯向量的實時編輯,其中用戶可以修改分割掩碼,并由此在 GAN 的隱空間中進行優化以實現編輯;圖 2(4)為在隱空間中學習編輯向量,用戶通過應用以往學習到的編輯向量進行編輯,并可以交互式地操縱圖像。
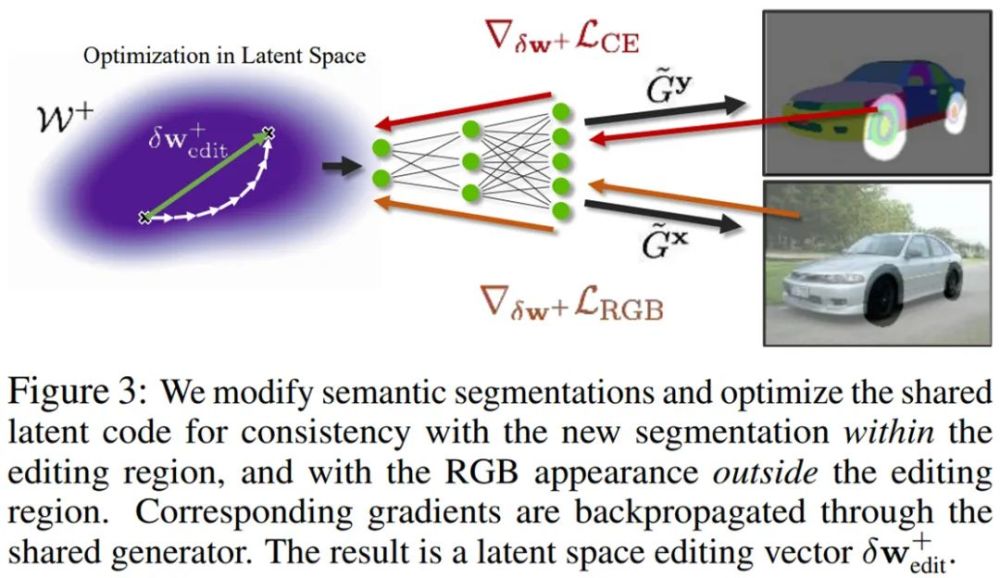
通過分割編輯在隱空間中找出語義
EditGAN 的核心思想是在實現高精度圖像編輯中利用圖像和語義分割的聯合分布 p(x, y)。給定一張待編輯的新圖像 x,我們可以將它嵌入到 EditGAN 的 W^+ 隱空間中。然后,分割部分將生成相應的分割 y,這是因為分割和 RGB 圖像共享相同的隱編碼 w^+。使用簡單的交互式數字繪畫或標注工具,即可根據預期的編輯手動修改分割。研究者將編輯的分割掩碼表示為了 y_edited。
例如,當修改右側汽車照片中的車輪時,Q_edit 將包含輪胎、輻條和輪轂等所有與車輪相關的零件的標簽:
推理過程中不同的編輯方法
總的來說,我們可以通過以下三種不同的模式使用 EditGAN 進行圖像編輯:
使用編輯向量進行實時編輯。對于局部解耦良好的編輯,僅通過應用先前學習的具有不同尺度的編輯向量即可進行編輯,并以交互式速率(interactive rate)操縱圖像;
利用自監督細化的向量編輯。對于未與圖像其他部分完美解耦的局部編輯,可以通過測試過程中的額外優化去除編輯偽影,同時使用學習到的向量初始化編輯;
基于優化的編輯。特定圖像和大規模的編輯不能通過編輯向量遷移到其他圖像。對于此類操作,則可以從零開始進行優化。
實驗結果
在實驗部分,研究者在四種不同類別的圖像上對 EditGAN 進行了廣泛的評估,它們分別是:
汽車(空間分辨率 384×512)
鳥(512×512)
貓(256×256)
人臉(1024×1024)
其中,人臉示例的注釋細節如下圖 7 所示:
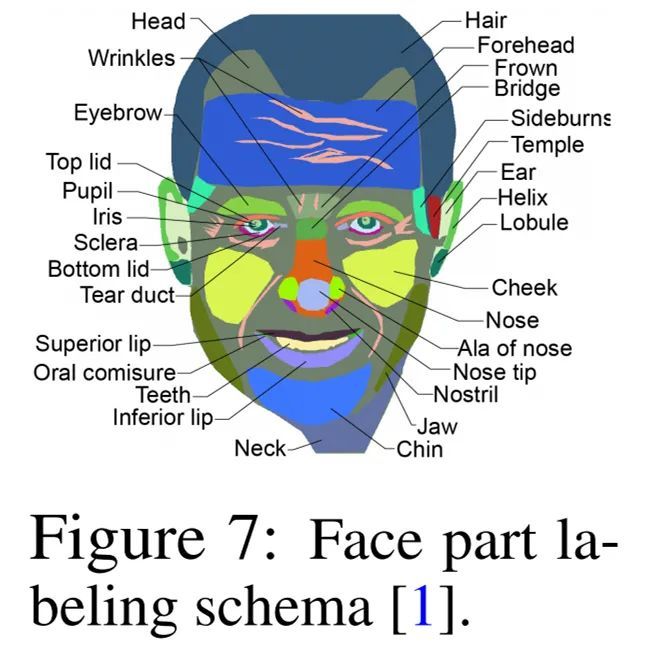
當僅基于優化或通過學習編輯向量完成編輯時,研究者通常使用 Adam 執行 100 steps 的優化。對于汽車、貓和人臉,他們使用 DatasetGAN 測試集中的真實圖像,使用這些非 GAN 訓練數據的圖像是為了驗證編輯功能;對于鳥,他們在 GAN 生成的圖像上展示編輯功能。
定性結果
首先來看域內(in-domain)結果。在下圖 4 中,研究者展示了當在新圖像上應用以往學習到的編輯向量并執行 30 steps 的優化細化時,EditGAN 框架的圖像編輯效果。結果顯示,使用 EditGAN 的編輯操作保持了高圖像質量并對所有類別的圖像實現了良好的解耦。
研究者表示,以往沒有任何一種方法可以做到像 EditGAN 那樣復雜且高精度的編輯,同時還能保持較高的圖像質量和對象身份。

如下圖 8 所示,使用 EditGAN,研究者甚至可以實現極高精度的編輯,例如旋轉汽車的輪輻(左)或者擴大人的瞳孔(右)。EditGAN 可以對那些像素極少對象的語義部分進行編輯,同時還能實現大規模的修改。

在下圖 9 中,研究者展示了僅通過修改分割掩碼和優化即可以去除汽車的車頂或將其改裝成旅行車。值得注意的是,通過一些編輯操作生成的圖像與 GAN 訓練數據中出現的圖像不同。

其次是域外結果。研究者在 MetFaces 數據集上展示 EditGAN 對域外數據的泛化能力。他們使用在 FFHQ 上訓練的 EditGAN 模型,并使用域內真實人臉數據創建編輯向量。接著嵌入域外 MetFaces 肖像(使用 100 steps 的優化),再通過 30 steps 的優化應用編輯向量。結果如下圖 6 所示,該研究的編輯操作無縫地遷移至相差甚遠的域外圖像示例。

定量結果
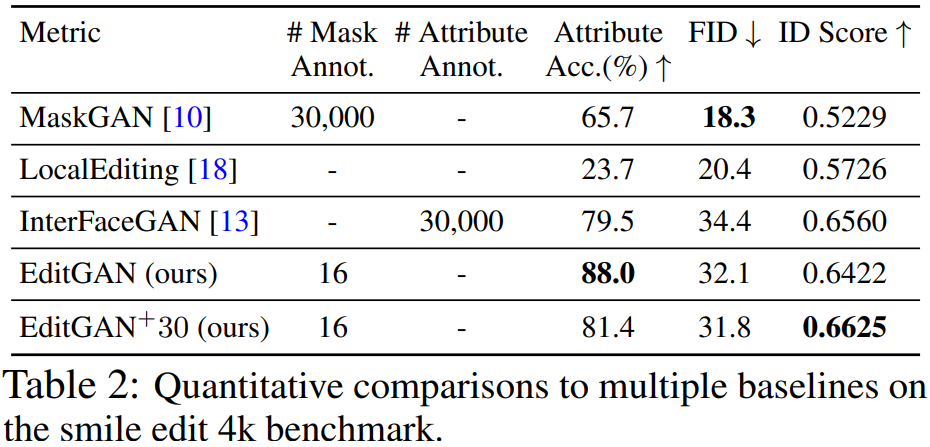
為了展示 EditGAN 的圖像編輯能力的定量評估結果,研究者使用了 MaskGAN 引入的笑臉編輯(smile edit)基準。中性表情的人臉被轉換為笑臉,并使用以下三項指標對性能進行度量,它們分別是:
語義正確性(Semantic Correctness)
分布級圖像質量(Distribution-level Image Quality)
身份保持(Identity Preservation)
研究者將 EditGAN 與三個強基準方法進行比較,分別是 MaskGAN2、LocalEditing 和 InterFaceGAN,最后還與 StyleGAN2 蒸餾做了比較。結果如下表 2 所示,EditGAN 在三項指標上均優于其他方法。此外,EditGAN 在身份保持和屬性分類準確率方面也優于 InterFaceGAN。在與 StyleGAN2 蒸餾的比較中,EditGAN 也表現出了強大的性能。
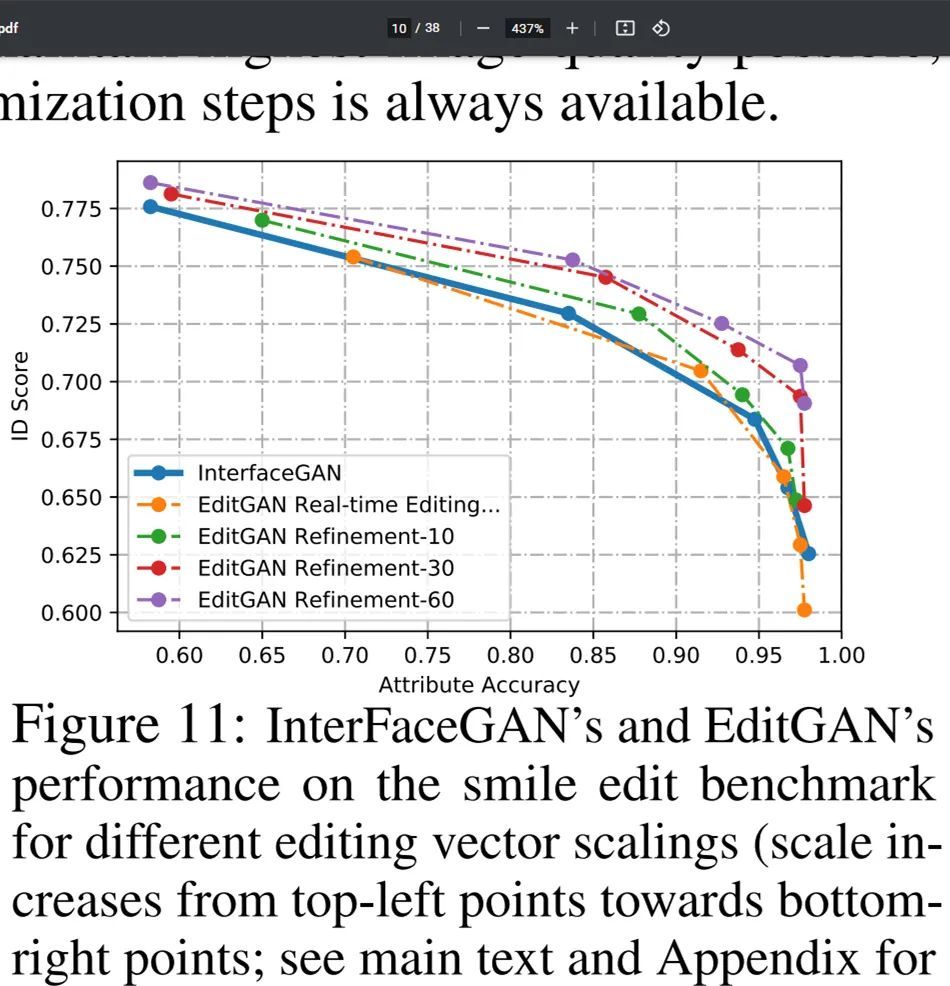
在下圖 11 中,研究者展示了與 InterFaceGAN 比較的更多細節,其中應用了具有從 0 到 2 不同尺度系數的笑臉編輯向量。當編輯向量尺度較小時,身份分數高但笑臉屬性分數低,這是對原始圖像修改最小化導致的。他們發現,使用編輯向量的實時編輯效果可以媲美 InterFaceGAN。
最后說下運行時間。研究者仔細記錄了 EditGAN 在 NVIDIA Tesla V100 GPU 上的運行時間。給定一個編輯好的分割掩碼的情況下,走完 30 (60) 個優化 steps 的條件式優化耗時 11.4 (18.9) 秒。這一操作為他們提供了編輯向量。此外,編輯向量的應用幾乎是瞬間完成的,僅耗時 0.4 秒,因此得以實現復雜的實時交互編輯。走完 10 (30) steps 的自監督細化將額外耗時 4.2 (9.5) 秒。