為了生成唯一id,React18專門引入了新Hook:useId
大家好,我卡頌。
看看如下組件有什么問題:
- // App.tsx
- const id = Math.random();
- export default function App() {
- return <div id={id}>Hello</div>
- }
如果應用是CSR(客戶端渲染),id是穩定的,App組件沒有問題。
但如果應用是SSR(服務端渲染),那么App.tsx會經歷:
- React在服務端渲染,生成隨機id(假設為0.1234),這一步叫dehydrate(脫水)
- <div id="0.12345">Hello</div>作為HTML傳遞給客戶端,作為首屏內容
- React在客戶端渲染,生成隨機id(假設為0.6789),這一步叫hydrate(注水)
客戶端、服務端生成的id不匹配!
事實上,服務端、客戶端無法簡單生成穩定、唯一的id是個由來已久的問題,早在15年就有人提過issue:
Generating random/unique attributes server-side that don't break client-side mounting[1]
直到最近,React18推出了官方Hook——useId,才解決以上問題。他的用法很簡單:
- function Checkbox() {
- // 生成唯一、穩定id
- const id = useId();
- return (
- <>
- <label htmlFor={id}>Do you like React?</label>
- <input type="checkbox" name="react" id={id} />
- </>
- );
- );
雖然用法簡單,但背后的原理卻很有意思 —— 每個id代表該組件在組件樹中的層級結構。
本文讓我們來了解useId的原理。
React18來了,一切都變了
這個問題雖然一直存在,但之前一直可以使用自增的全局計數變量作為id,考慮如下例子:
- // 全局通用的計數變量
- let globalIdIndex = 0;
- export default function App() {
- const id = useState(() => globalIdIndex++);
- return <div id={id}>Hello</div>
- }
只要React在服務端、客戶端的運行流程一致,那么雙端產生的id就是對應的。
但是,隨著React Fizz(React新的服務端流式渲染器)的到來,渲染順序不再一定。
比如,有個特性叫 Selective Hydration,可以根據用戶交互改變hydrate的順序。
當下圖左側部分在hydrate時,用戶點擊了右下角部分:
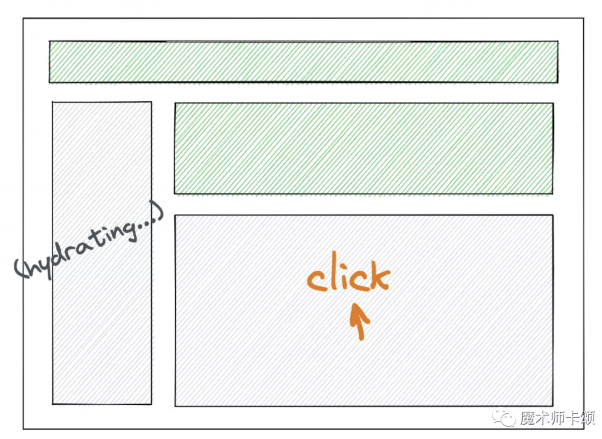
此時React會優先對右下角部分hydrate:
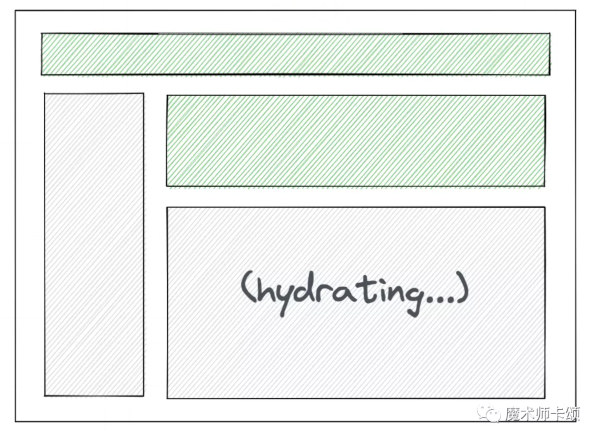
關于Selective Hydration更詳細的解釋見:New Suspense SSR Architecture in React 18[2]
如果應用中使用自增的全局計數變量作為id,那么顯然先hydrate的組件id會更小,所以id是不穩定的。
那么,有沒有什么是服務端、客戶端都穩定的標記呢?
答案是:組件的層次結構。
useId的原理
假設應用的組件樹如下圖:
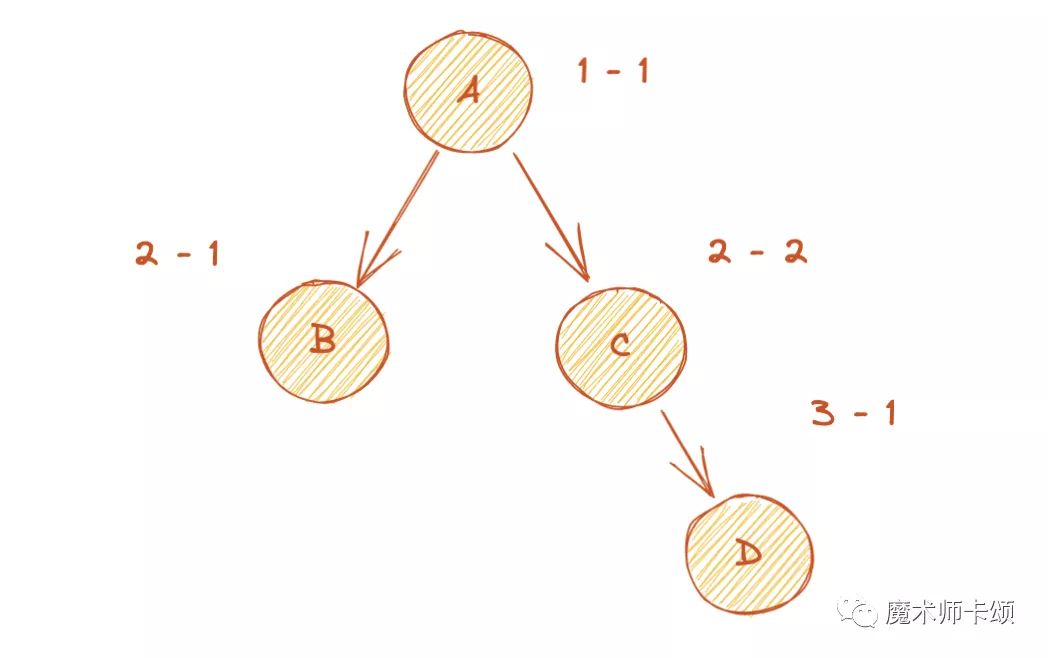
不管B和C誰先hydrate,他們的層級結構是不變的,所以「層級」本身就能作為服務端、客戶端之間不變的標識。
比如B可以使用2-1作為id,C使用2-2作為id:
- function B() {
- // id為"2-1"
- const id = useId();
- return <div id={id}>B</div>;
- }
實際需要考慮兩個要素:
1. 同一個組件使用多個id
比如這樣:
- function B() {
- const id0 = useId();
- const id1 = useId();
- return (
- <ul>
- <li id={id0}></li>
- <li id={id1}></li>
- </ul>
- );
- }
2. 要跳過沒有使用useId的組件
還是考慮這個組件樹結構:
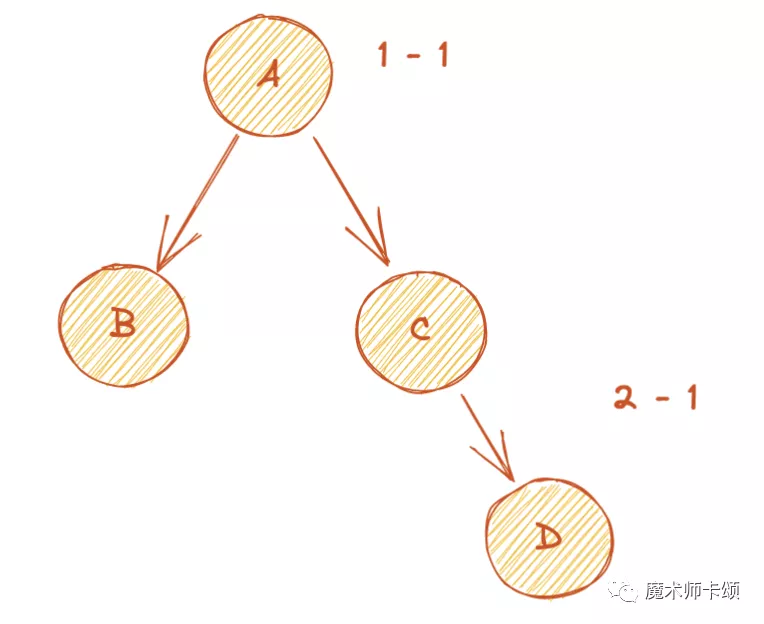
如果組件A、D使用了useId,B、C沒有使用,那么只需要為A、D劃定層級,這樣就能「減少需要表示層級」。
在useId的實際實現中,層級被表示為「32進制」的數。
之所以選擇「32進制」,是因為選擇盡可能大的進制會讓生成的字符串盡可能緊湊。比如:
- const a = 18;
- // "10010" length 5
- a.toString(2)
- // "i" length 1
- a.toString(32)
具體的useId層級算法參考useId[3]
總結
React源碼內部有多種棧結構(比如用于保存context數據的棧)。
useId 棧的邏輯是其中比較復雜的一種。
誰能想到用法如此簡單的API背后,實現起來居然這么復雜?
React團隊搗鼓「并發特性」,真挺不容易的...
參考資料
[1]Generating random/unique attributes server-side that don't break client-side mounting:
https://github.com/facebook/react/issues/4000
[2]New Suspense SSR Architecture in React 18:
https://github.com/reactwg/react-18/discussions/37
[3]useId:
https://github.com/facebook/react/pull/22644