













一個模型通殺八大視覺任務,一句話生成圖像視頻
本文經AI新媒體量子位(公眾號ID:QbitAI)授權轉載,轉載請聯系出處。
有這樣一個模型。
它可以做到一句話生成視頻:

不僅零樣本就能搞定,性能還直達SOTA。
它的名字,叫“NüWA”(女媧)。
“女媧女媧,神通廣大”,正如其名,一句話生成視頻只是這個模型的技能之一。
除此之外,一句話生成圖片,草圖生成圖像、視頻,圖像補全,視頻預測,圖像編輯、視頻編輯——
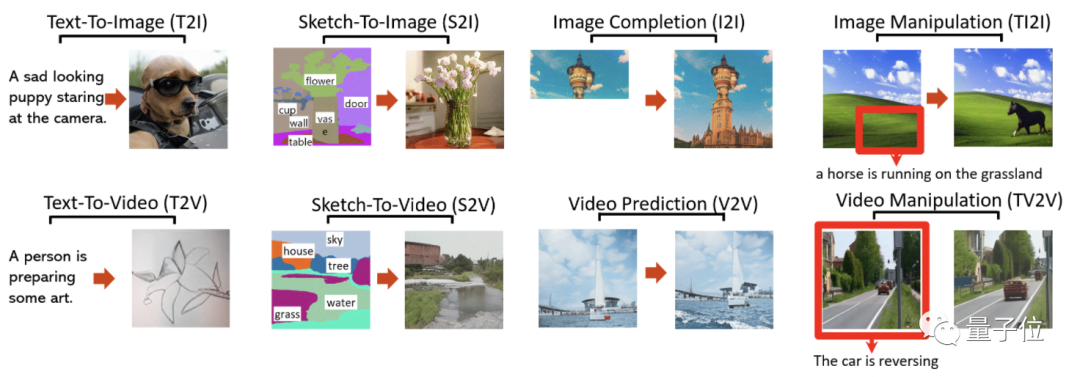
一共八種視覺任務,它其實全部都能搞定。
完全是一位不折不扣的“全能型選手”。
它,就是由微軟亞研院和北大聯合打造的一個多模態預訓練模型,在首屆微軟峰會上亮相。
目前,在推特上已“小有熱度”。

八項全能“女媧”,單拎出來也不差
所以這個全能型選手究竟表現如何?
直接與SOTA模型對比,來看看“她”在各項任務上的表現。
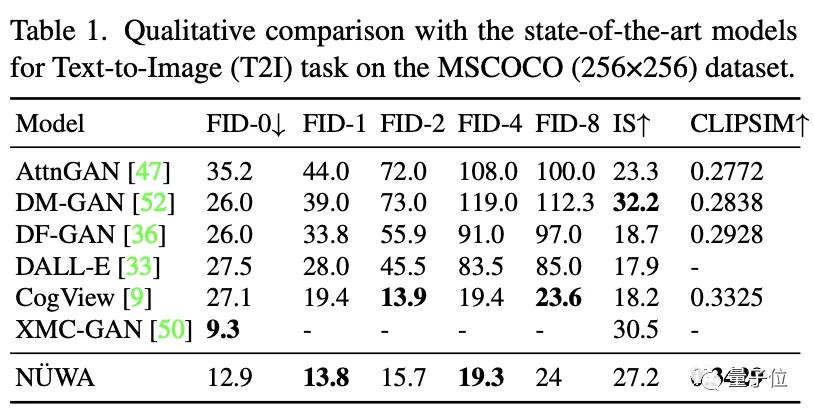
在文本生成圖像中,不得不說,即使“女媧”的FID-0得分不及XMC-GAN,但在實際效果中,“女媧”生成的圖肉眼可見的更好,清晰又逼真。

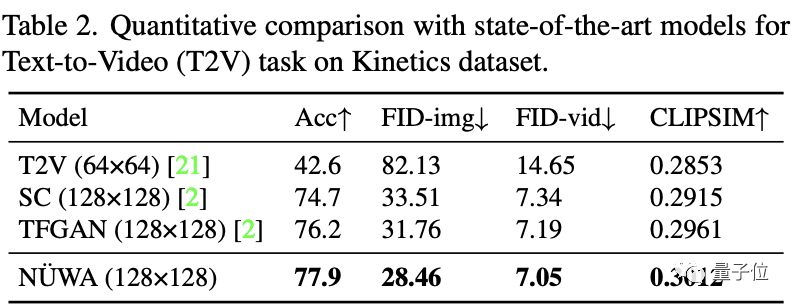
文本到視頻中,“女媧”每一項指標都獲得了第一名,從逐幀圖片來看,差距很明顯。

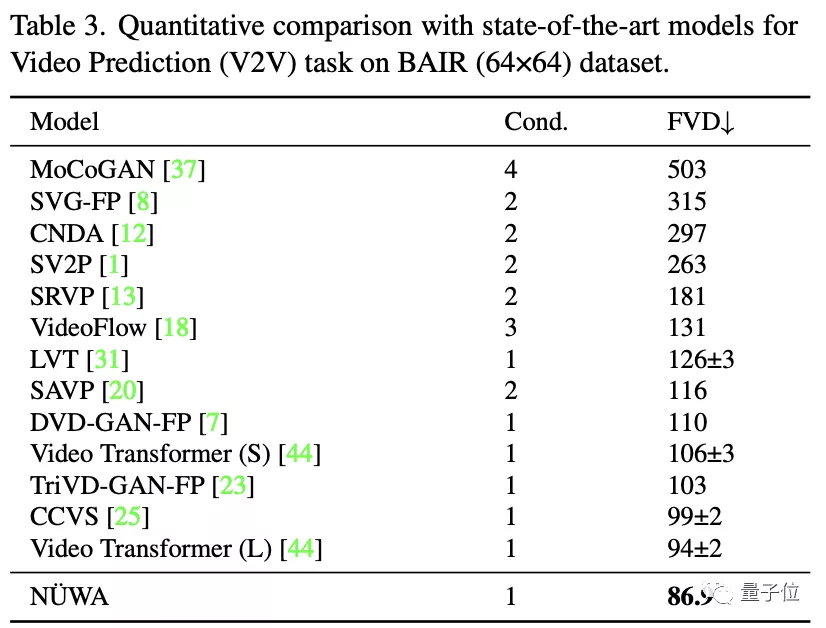
在視頻預測中,所有模型使用64x64的分辨率,Cond.代表供預測的幀數。
盡管只有1幀,“女媧”也將FVD得分從94±2降到86.9。

草圖轉圖像時,與SOTA模型相比,“女媧”生成的卡車都更逼真。

而在零樣本的圖像補全任務中,“女媧”擁有更豐富的“想象力”。

直接上效果:
并且,它的另一個優勢是推理速度,幾乎50秒就可以生成一個圖像;而Paint By Word在推理過程中需要額外的訓練,大約需要300秒才能收斂。

而草圖生成視頻以及文本引導的視頻編輯任務,是本次研究首次提出,目前還沒有可比對象。
直接上效果:

看,像上面這些僅用色塊勾勒輪廓的視頻草圖,經“女媧”之手就能生成相應視頻。
而輸入一段潛水視頻,“女媧”也能在文本指導下讓潛水員浮出水面、繼續下潛,甚至“游”到天上。

可以說,“女媧”不僅技能多,哪個單項拿出來也完全不賴。
如何實現?
這樣一個無論操作對象是圖像還是視頻,無論是合成新的、還是在已有素材上改造都能做到做好的“女媧”,是如何被打造出來的呢?
其實不難,把文字、圖像、視頻分別看做一維、二維、三維數據,分別對應3個以它們為輸入的編碼器。
另外預訓練好一個處理圖像與視頻數據的3D解碼器。
兩者配合就獲得了以上各種能力。
其中,對于圖像補全、視頻預測、圖像視頻編輯任務,輸入的部分圖像或視頻直接饋送給解碼器。
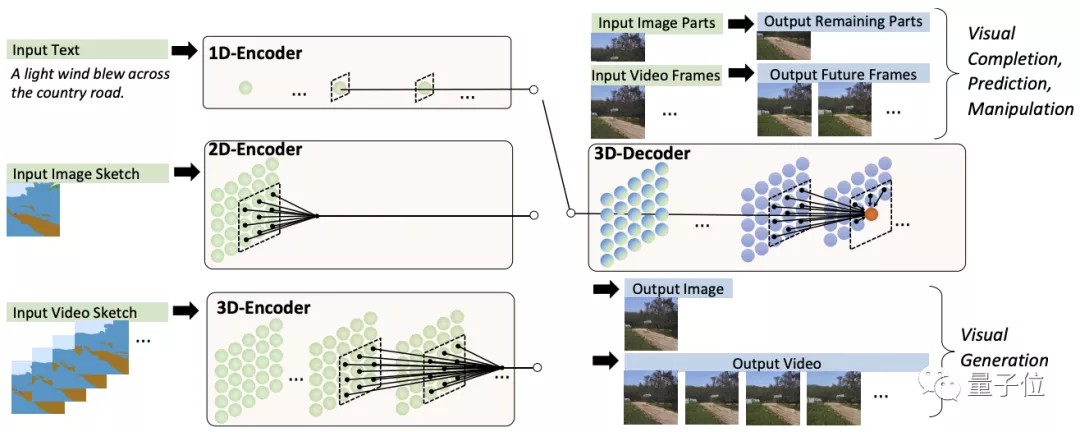
而編碼解碼器都是基于一個3D Nearby的自注意力機制(3DNA)建立的,該機制可以同時考慮空間和時間軸的上局部特性,定義如下:
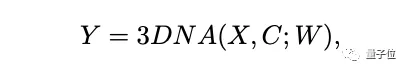
W表示可學習的權重,X和C分別代表文本、圖像、視頻數據的3D表示:
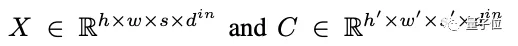
其中,h和w表示空間軸上的token數,s表時間軸上的token數(文本默認為1),d表示每個token的維數。
如果C=X,3DNA表示對目標X的自注意;如果C≠X,3DNA表示對在條件C下目標X的交叉注意。
該機制不僅可以降低模型的計算復雜度,還能提高生成結果的質量。
此外,模型還使用VQ-GAN替代VQ-VAE進行視覺tokenization,這也讓生成效果好上加好。
團隊介紹
一作Chenfei Wu,北京郵電大學博士畢業,現工作于微軟亞研院。
共同一作Jian Liang, 來自北京大學。
其余作者包括微軟亞研院的高級研究員Lei Ji,首席研究員Fan Yang,合作首席科學家Daxin Jiang,以及北大副教授方躍堅。
通訊作者為微軟亞研院的高級研究員&研究經理段楠。
論文地址:
https://arxiv.org/abs/2111.12417
























