













文生3D模型大突破!MVDream重磅來襲,一句話生成超逼真三維模型
不得了了!
現在只用打幾個字就能創造精美、高質量的3D模型出來了?
這不,國外一篇博客引爆網絡,把一個叫MVDream的東西擺到了我們面前。
用戶只需要寥寥數語,就可以創造出一個栩栩如生的3D模型。

而且和之前不同的是,MVDream看起來是真的「懂」物理。
下面就來看看這個MVDream有多神奇吧~
MVDream
小哥表示,大模型時代,我們已經看到了太多太多文本生成模型、圖片生成模型。而且這些模型的性能也越來越強大。
后來,我們甚至還目睹了文生視頻模型的誕生,當然也包括今天要提到的3D模型。
試想一下,你只需要輸入一句話,就可以生成一個宛如存在于真實世界的物體模型,甚至還包含著所有必要細節,這個場景該有多酷。
而且這絕對不是一件簡單的事,尤其是用戶需要生成的模型所呈現的細節要足夠逼真。
先來看看效果~

同一個prompt,最右側就是MVDream的成品。
肉眼可見5個模型的差距。前幾個模型完全違背了客觀事實,只有從某幾個角度看才是對的。
比如前四張圖片,生成的模型居然有不止兩只耳朵。而第四張圖片雖然看起來細節更豐滿一點,但是轉到某個角度我們能發現,人物的臉是凹進去的,上面還插著一只耳朵。
誰懂啊,小編一下就想起了之前很火的小豬佩奇正視圖。

就是那種,某些角度是展示給你看的,別的角度千萬別看,會死人。
可最右邊MVDream的生成模型顯然不一樣。無論3D模型怎樣轉動,你都不會覺得有任何反常規的地方。
這也就是開頭所提到的,MVDream真懂物理常識,而不會為了保證在每個視圖下都有兩只耳朵而搞出一些奇奇怪怪的東西。
小哥指出,一個3D模型是否成功,最主要的就是觀察這個模型的不同視角是不是都足夠逼真,質量都足夠高。
而且還要保證模型在空間上的連貫性,而不是像上面多個耳朵的模型那樣。
生成3D模型的主要方法之一,就是對攝像機的視角進行模擬,然后生成某一視角下所能看到的東西。
換個詞,這就是所謂的2D提升(2D lifting)。就是將不同的視角拼接在一起,形成最終的3D模型。
出現上面多耳的情況,就是因為生成模型對整個物體在三維空間的樣態信息掌握的不充分。而MVDream恰恰就是在這方面往前邁了一大步。
新模型解決了之前一直出現的3D視角下的一致性問題。
分數蒸餾采樣
而用到的方法叫做分數蒸餾采樣(score distillation sampling),由DreamFusion開發。
在了解分數蒸餾采樣技術之前,我們需要先了解一下該方法所使用的架構。
簡而言之,這其實只是另一種二維圖像的擴散模型,同類的還有DALLE、MidJourney和Stable Diffusion模型。
更具體地說,一切的一切都是從預訓練好的DreamBooth模型開始的,DreamBooth是一個基于Stable Diffusion生圖的開源模型。
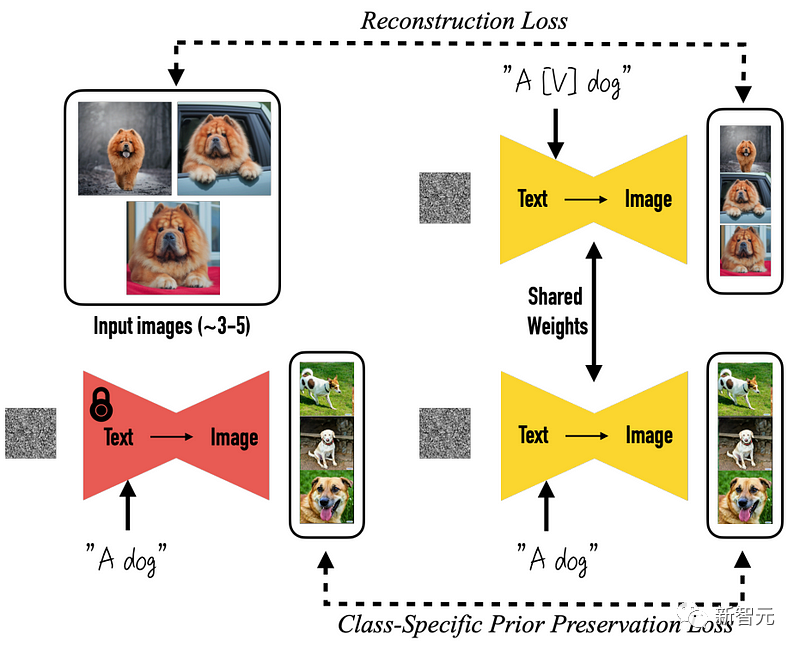
然后,改變來了。
研究團隊后續所做的是,直接渲染一組多視角圖像,而不是只渲染一張圖像,這一步需要有各種物體的三維數據集才可以完成。
在這里,研究人員從數據集中獲取了三維物體的多個視圖,利用它們來訓練模型,再使其向后生成這些視圖。
具體做法是將下圖中的藍色自注意塊改為三維自注意塊,也就是說,研究人員只需要增加一個維度來重建多個圖像,而不是一個圖像。
在下圖中,我們可以看到攝像機和時間步(timestep)也都被輸入到了每個視圖的模型中,以幫助模型了解哪個圖像將用在哪里,以及需要生成的是哪種視圖。
現在,所有圖像都連接在一起,生成也同樣在一起完成。因此它們就可以共享信息,更好地理解全局的情況。
然后,再將文本輸入模型,訓練模型從數據集中準確地重建物體。
而這里也就是研究團隊應用多視圖分數蒸餾采樣過程的地方。
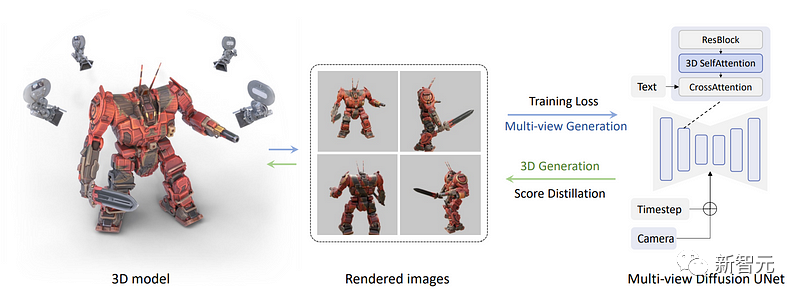
現在,有了一個多視圖的擴散模型,團隊可以生成一個物體的多個視圖了。
下一步,就是用這些視圖來重建一個和真實世界一致的三維模型,而不僅僅是視圖。
這里需要使用NeRF(neural radiance fields,神經輻射場)來實現,就像前面提到的DreamFusion一樣。
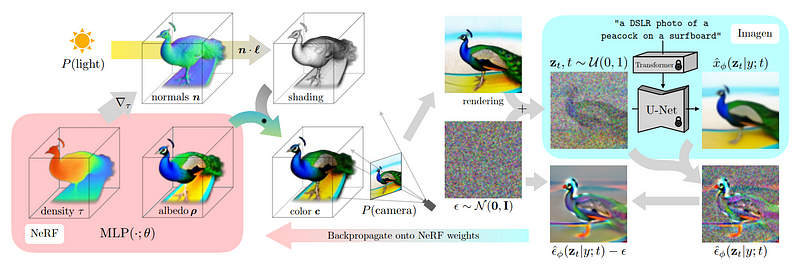
基本上這一步就是把前面訓練好的多視角擴散模型給凍住,也就是說,在這一步中,上面各個視角的圖片只是被「使用」,而不會被再「訓練」。
在初始渲染的引導下,研究人員開始使用多視角擴散模型生成一些添加了噪聲(noise)的初始圖像版本。
研究人員添加噪聲是為了讓模型知道,它需要生成不同版本的圖像,但同時仍能接收到背景信息。
然后,再使用該模型進一步生成更高質量的圖像。
添加用于生成該圖像的圖像,并移除我們手動添加的噪聲,以便在下一步中使用該結果來指導和改進NeRF模型。
這些步驟都是為了更好地理解NeRF模型應該集中在圖像的哪個部分,以便在下一步中生成更好的結果。
如此反復,直到生成出令人滿意的3D模型。

而對于多視角擴散模型的圖像生成質量的評估,以及不同的設計會如何影響其性能的判斷,該團隊是這么操作的。
首先,他們比較了用于建立跨視角一致性模型的注意力模塊的選擇。
這些選項包括:
(1)視頻擴散模型中廣泛使用的一維時間自注意;
(2)在現有模型中添加新的三維自注意模塊;
(3)重新使用現有的二維自注意模塊進行三維注意。
在本實驗中,為了清楚地顯示這些模塊之間的差異,研究人員使用了8幀的90度視角變化來訓練模型,這更加接近視頻的設置。
同時在實驗中,研究團隊還保持了較高的圖像分辨率,即512×512作為原始的標清模型。結果如下圖所示,研究人員發現,即使在靜態場景中進行了如此有限的視角變化,時間自注意力仍然會受到內容偏移的影響,無法保持視角的一致性。
團隊假設,這是因為時間注意力只能在不同幀的相同像素之間交換信息,而在視點變化時,相應像素之間可能相距甚遠。
另一方面,在不學習一致性的情況下,添加新的三維注意會導致嚴重的質量下降。
研究人員認為,這是因為從頭開始學習新參數會耗費更多的訓練數據和時間,不適合這種三維模型有限的情況。研究人員提出的重新使用二維自注意的策略在不降低生成質量的情況下實現了最佳的一致性。
團隊還注意到,如果將圖像大小減小到256,視圖數減小到4,這些模塊之間的差異會小得多。然而,為了達到最佳一致性,研究人員在以下實驗中根據初步觀察做出了選擇。

此外,對于多視角的分數蒸餾采樣,研究人員在threestudio(thr)庫中實現了多視角擴散的引導,該庫在統一框架下實現了最先進的文本到三維模型的生成方法。
研究人員使用threestudio中的隱式容積(implicit-volume)實現作為三維表示,其中包括多分辨率的哈希網格( hash-grid)。
對于攝像機視圖,研究人員采用了與渲染三維數據集時完全相同的方式對攝像機進行倆人采樣。
此外,研究人員還使用AdamW優化器對3D模型進行了10000步優化,學習率為0.01。
對于分數蒸餾采樣,在最初的8000 步中,最大和最小時間步長分別從0.98步降到了0.5步和0.02步。
渲染分辨率從64×64開始,經過5000步后逐步增加到了256×256。
更多案例如下:

以上就是研究團隊如何利用二維文本到圖像模型,將其用于多視角合成,最后利用它迭代,并創建出文本到3D模型的過程。
當然,目前這種新方法還存在一定的局限性,最主要的缺陷在于,現在生成的圖像只有256x256像素,分辨率可以說很低了。
此外,研究人員還指出,執行這項任務的數據集的大小在某種程度上一定會限制這種方法的通用性,因為數據集的太小的話,就沒辦法更逼真的反應我們這個復雜的世界。

























