淺析大數(shù)據(jù)即席查詢工具 Presto
本文轉(zhuǎn)載自微信公眾號「匠心獨運維妙維效」,作者侯強。轉(zhuǎn)載本文請聯(lián)系匠心獨運維妙維效公眾號。
數(shù)據(jù)業(yè)務現(xiàn)狀
隨著業(yè)務數(shù)據(jù)量越來越大、數(shù)據(jù)任務越來越多以及數(shù)據(jù)計算類型越來越豐富,G行的原有以Hadoop、MPP為核心的數(shù)據(jù)平臺現(xiàn)有組件表現(xiàn)出了一定的局限性。例如:大數(shù)據(jù)平臺和數(shù)據(jù)倉庫上任務總量已經(jīng)達到了3萬以上,而且還在急劇增長。由于數(shù)據(jù)存放在了不同數(shù)據(jù)源中,對于需要對多種數(shù)據(jù)源的查詢?nèi)蝿眨紫纫M行數(shù)據(jù)遷移操作,匯總到MPP或Hadoop后進行查詢操作,這一過程耗時費力,已經(jīng)很難滿足用戶快捷數(shù)據(jù)查詢的需求。
而數(shù)據(jù)平臺建設的一個重要目標就是滿足用戶方便快捷的使用數(shù)據(jù),用戶不需要關心數(shù)據(jù)的存放方式,能夠使用標準的數(shù)據(jù)調(diào)用接口,隨時使用自己關心的數(shù)據(jù)。為滿足對上述的多數(shù)據(jù)源無差別的查詢,使用遠端數(shù)據(jù)完成交互式查詢,G行選擇的方式是Presto。
Presto提供豐富的Connector,通過Connector機制可以將所連接的數(shù)據(jù)SQL化。Presto的Connector可以連接傳統(tǒng)的RDBMS數(shù)據(jù)庫,也可以連接HBase、Hive等大數(shù)據(jù)的開源軟件,還可以使用FileConnector連接本地文件。有了Connector,可以直接在Presto的客戶端發(fā)起查詢請求,通過Presto解析查詢語句對不同的數(shù)據(jù)源發(fā)起數(shù)據(jù)查詢。通過Connector的方式,避免了數(shù)據(jù)搬移,節(jié)省了大量的數(shù)據(jù)存儲空間,也避免了時間消耗。這個場景非常適合數(shù)據(jù)科學家對多種數(shù)據(jù)分析的需求。
Presto架構特點
執(zhí)行效率方面,Presto是一個開源的基于內(nèi)存的分布式SQL查詢的執(zhí)行引擎,可以支持TB到PB級數(shù)據(jù)量的秒級到分鐘級的快速響應。在查詢效率方面,比MapReduce的查詢引擎有很大的提升。
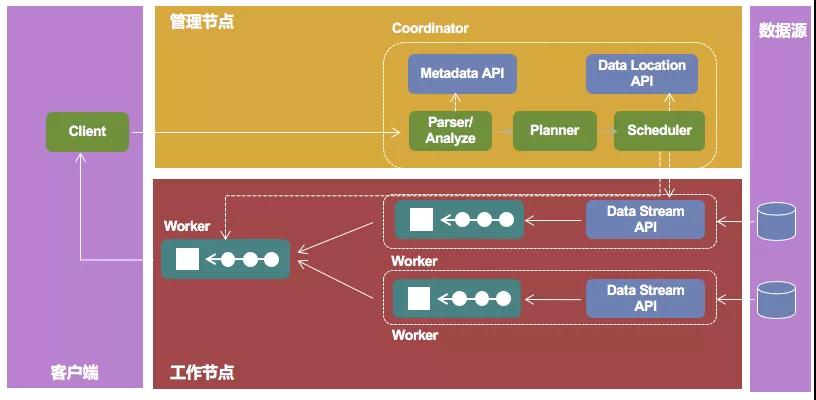
Presto查詢引擎是一個Master-Slave的架構,由一個Coordinator節(jié)點,多個Worker節(jié)點組成。Coordinator負責解析SQL語句,生成執(zhí)行計劃,Coordinator將一個完整的Query,拆分成了多個Stage,每個Stage拆分出多個可以并行的Task,分發(fā)執(zhí)行任務給Worker節(jié)點執(zhí)行。
Worker節(jié)點負責實際執(zhí)行查詢Task。通過配置外部數(shù)據(jù)源的Connector,部分Task負責到外部存儲系統(tǒng)拉取數(shù)據(jù),這部分Task會先執(zhí)行,之后再執(zhí)行那些負責計算的Task。Worker節(jié)點的數(shù)量影響到Presto執(zhí)行效率,可以通過增加worker節(jié)點的數(shù)量,提升數(shù)據(jù)查詢的的效率。而Coordinator在Presto只有一個,需要使用高可用的部署方法,進行災備保護。
Presto是一個原生的計算和存儲分離的分布式的SQL框架。Presto負責SQL的解析和執(zhí)行,數(shù)據(jù)本身都由外部數(shù)據(jù)源進行存儲和維護。這種存儲和計算分離的架構,在進行資源擴容時可以分別對存儲資源和計算資源進行單獨擴容,非常符合當今云計算的架構和發(fā)展方向。在設備選型時,可以針對IO密集型和CPU密集型采購不同的設備來滿足需求。
Presto提供了豐富的Connector,可以連接多種流行的數(shù)據(jù)源,比如MySql、Hive、Elasticsearch等。同時Presto還提供了API接口,開發(fā)人員可以根據(jù)自己的實際情況開發(fā)自己的應用接口。例如openlookeng,這個軟件提供了高斯數(shù)據(jù)庫的訪問接口,可以完成Hive和高斯數(shù)據(jù)庫之間的跨數(shù)據(jù)源的聯(lián)合查詢。
Presto存在的問題
Presto是一個完全基于內(nèi)存的SQL計算框架,在運行過程中采用高并發(fā)的查詢方式。當處理數(shù)據(jù)過于龐大、SQL需要的內(nèi)存超出了物理服務器承受能力時,會出現(xiàn)內(nèi)存溢出。如果需要穩(wěn)定運行長時間的任務,可以使用Hive的SQL引擎。此外,由于Presto在設計初始,就是為了OLAP業(yè)務而進行開發(fā),Presto雖然支持delete和insert,但內(nèi)部結構不適合頻繁的數(shù)據(jù)修改操作。
Presto未來發(fā)展
許多企業(yè)在大數(shù)據(jù)建設道路上都產(chǎn)生了相類似的多數(shù)據(jù)源匯總查詢的問題,數(shù)據(jù)分布在多種數(shù)據(jù)產(chǎn)品中,各種數(shù)據(jù)產(chǎn)品之間沒有直接交互的方法,需要通過數(shù)據(jù)遷移完成數(shù)據(jù)分析工作。而Presto的出現(xiàn),解決了多數(shù)企業(yè)面臨的問題。G行的即席查詢系統(tǒng)正是以Presto技術為核心構建的。隨著Presto應用范圍的擴大,穩(wěn)定性將隨之不斷的改善,相信會給各個企業(yè)在數(shù)據(jù)業(yè)務方面帶來更多的便利性。