













兩分鐘講透緩存穿透,你明白了嗎?

本文轉載自微信公眾號「后端技術小牛說」,作者后端技術小牛說 。轉載本文請聯系后端技術小牛說公眾號。
由于redis是內存型數據庫,往往會被當做緩存使用,那所以問到redis相關知識點,緩存這層是繞不開的。今天咱來嘮嘮緩存穿透。
先來看看緩存穿透的定義:緩存穿透,注意,關鍵在透這個詞上,就是不僅把緩存層打透了,也把數據庫打透了,即查詢一個數據庫也不存在的數據。
由于數據庫不存在這個值,那肯定緩存也不會有嘛,所以每次有這種垃圾查詢請求,都會打到數據庫上,對數據庫造成負擔。
那咋辦呢?
今天介紹兩個辦法:
- 布隆過濾器
- 緩存空對象
布隆過濾器
相信不少同學面試時被問過場景設計題:如果目前我們有個營銷垃圾郵箱的匯總表,我們希望設計一個高效的攔截過濾器,怎么設計呢?
大家肯定脫口而出:hashmap/hashset。
對,這個思路一點沒錯,如果我們的郵箱匯總表不大,當然可以這么干。但如果匯總表稍微大一點點比如上到10億,那就不能這么干了。一般來說面試官會回答:這么做占用空間太大,服務器內存撐不住,可以換一個思路,我們的這個業務可以允許一定的誤報。
既然面試官都給提示了,那咱就往擠壓內存占用的思路去考慮,既然又希望減少空間,又能接受誤報,可以考慮這個思路。
首先我們先設置一個空bit數組,初始全0:

設計k個hash映射函數,這k個映射函數各不相同,然后開啟一個for循環,把在匯總表中的郵箱通過這個映射函數得到數組指定位置,并置為1。比如這樣:
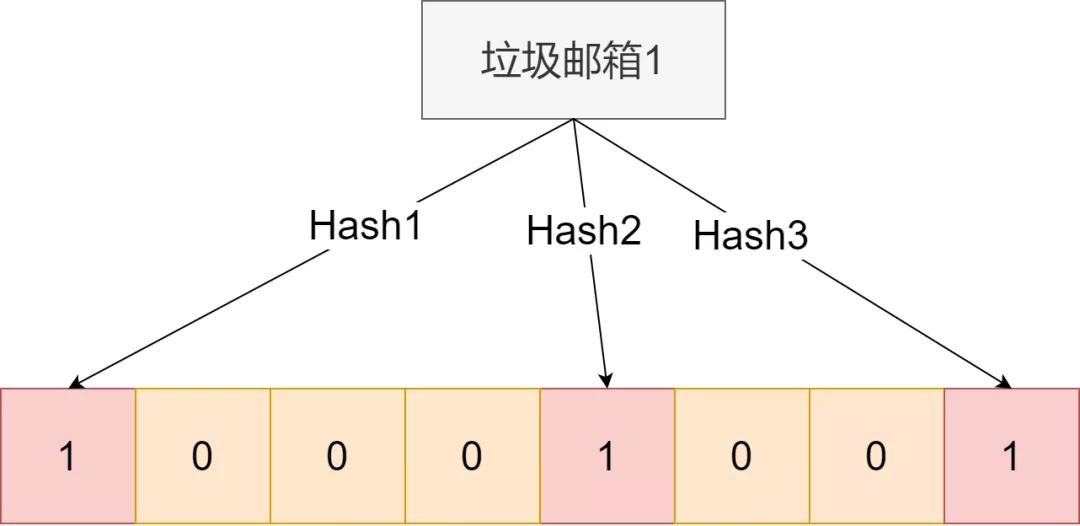
然后這樣
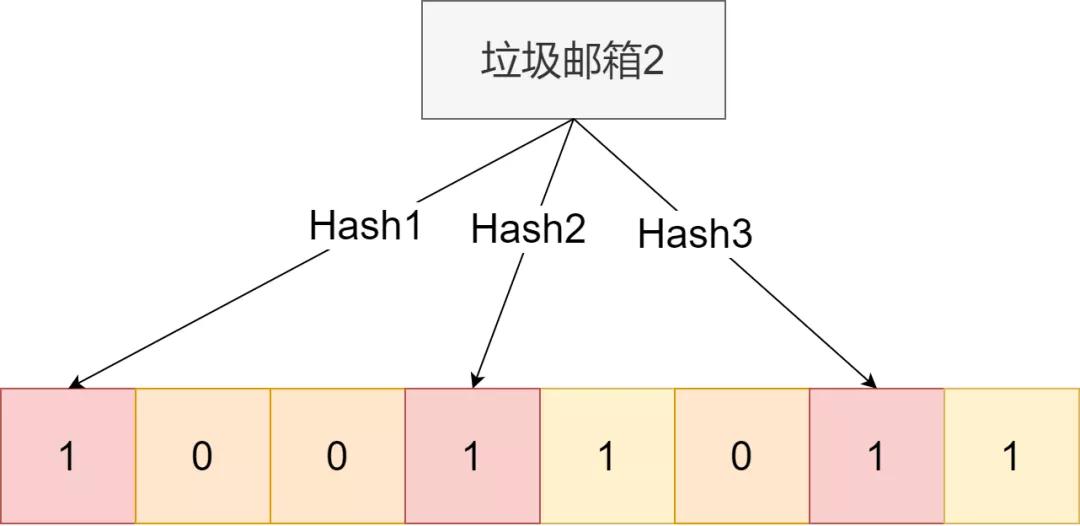
下次用戶有想查詢的郵箱,可以通過這一系列hash函數,判斷對應位置是否全為1。如果是,則很大概率就是垃圾郵箱了。為啥說是很大概率,因為完全不同的字段,在一個hash函數中,映射也會相同的。
那如何減少誤判概率?增加hash函數個數,增加這個數組長度。
最后提一下,這個數組可以就認為是布隆過濾器。
緩存空對象
這個就很好理解了。咱們一般定義的查詢邏輯,是這樣
- 用戶發送查詢請求
- 緩存層收到請求查看緩存是否存在該值,存在即返回,不存在走步驟3
- 數據庫收到查詢請求,查詢該值,如果存在,就返回,并把值添加到緩存層上。不存在直接返回
舉例來說,我們用了個員工id和其對應的工資表。如果員工有100個人,那我們id肯定是1-100排列。如果此時有個請求,想查詢id=1000的,那肯定啥也查不到,會被直接返回。
而緩存空對象,做的就是把這個值也緩存下來,即在緩存層中,添加一個id為1000,值為null的鍵值對。下次有對id為1000的請求,查詢直接打到緩存上,減少了數據庫壓力。
但這種操作會增加內存開銷,所以如果采用這種方法,一般空對象緩存的過期時間極短。
參考:
https://blog.csdn.net/qq_26222859/article/details/80831263
https://zhuanlan.zhihu.com/p/72378274

























