復(fù)旦博士寫了130行代碼,兩分鐘解決繁瑣核酸報告核查
本文經(jīng)AI新媒體量子位(公眾號ID:QbitAI)授權(quán)轉(zhuǎn)載,轉(zhuǎn)載請聯(lián)系出處。
2分鐘,“啪的一下”。
800多人的核酸完成截圖就審核完畢了。
這就是一位復(fù)旦大學(xué)生物醫(yī)學(xué)工程專業(yè)博士生,在最近共同抗疫期間開發(fā)的一項小程序發(fā)揮的作用。
而且僅僅是花費1小時、130行代碼的那種。
復(fù)旦大學(xué)官方對這個“抗疫利器”的評價是:
大大提高了核酸核查的效率和精度。
這位博士生的工作,也引來網(wǎng)友們的“膜拜”:
人民日報也對他的工作做出了評價,認為這波“操作火了”:

2分鐘搞定1小時工作
整件事的起因,是最近抗疫期間,復(fù)旦大學(xué)啟動了常態(tài)化核酸篩查工作。
而“痛點”也隨之而來。
也就是要核查每位學(xué)生“健康云”核酸完成截圖,需要花費大量的時間和人力。
但總的來說,這其實是一項重復(fù)性較高、單調(diào)且枯燥的工作:
一個班級的截圖可能就需要花上半小時核查,如果是人數(shù)多的院系可能需要更久,還可能會看錯看漏。
而復(fù)旦的這位博士生,身為學(xué)院2019級信息1班輔導(dǎo)員,在此期間負責(zé)的正是這項工作。
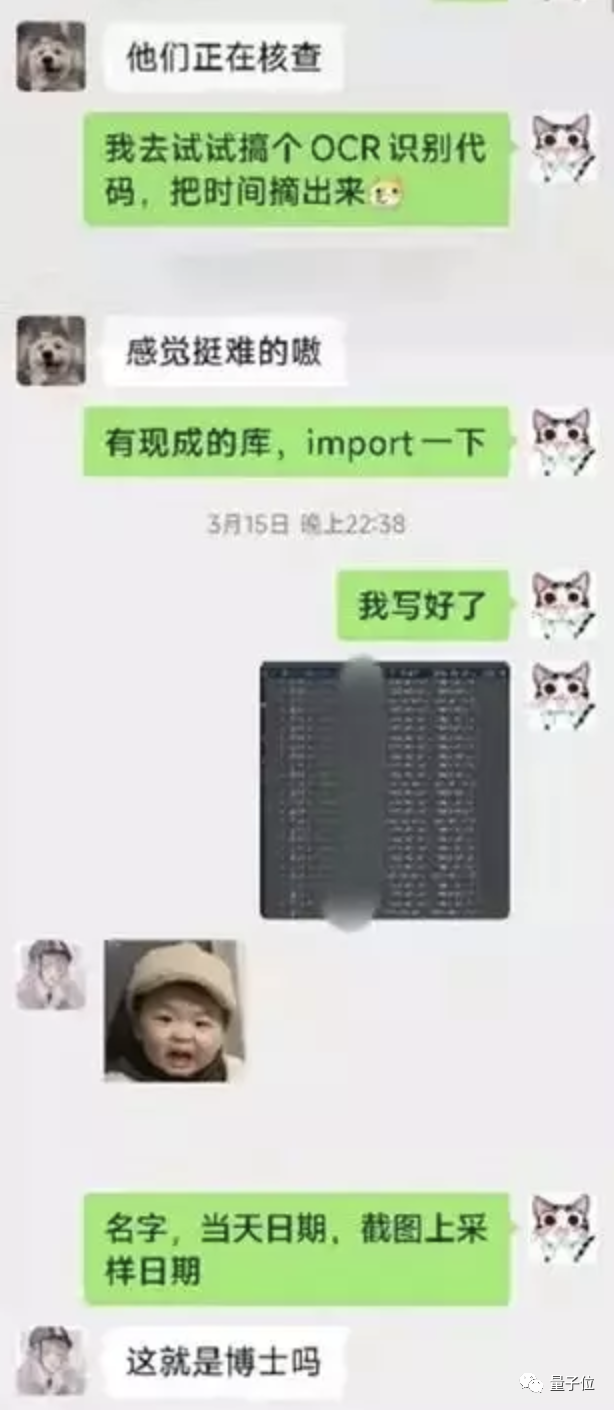
于是,他便心生一計——“搞個OCR識別代碼 ”。
”。
△圖源:復(fù)旦大學(xué)
最初與學(xué)工同事分享這個想法的時候,同事還擔(dān)心會不會太難了。
而他卻回復(fù)說:
有現(xiàn)成的庫,import一下就好了。
然后,1個小時過去了……
“我寫好了”。

同事見狀甚至感慨說“這就是博士嗎”。
于是乎,他的代碼程序就開始在自己的班級中“上崗”了。
△圖源:復(fù)旦大學(xué)
在進行驗證之后,這段程序的準(zhǔn)確率還是很高的,甚至還發(fā)現(xiàn)了此前人工核查時沒有發(fā)現(xiàn)的問題。
最重要的是,這項工作的速度有了大幅的提高。
例如原先要核查800張截圖,幾個工作人員要花費1個多小時,而現(xiàn)在,2分鐘即可拿到結(jié)果!
至于原理,這位博士生謙虛地說“并不復(fù)雜”。
他所用到的技術(shù)主要是OCR (光學(xué)字符識別),代碼語言則是Python。
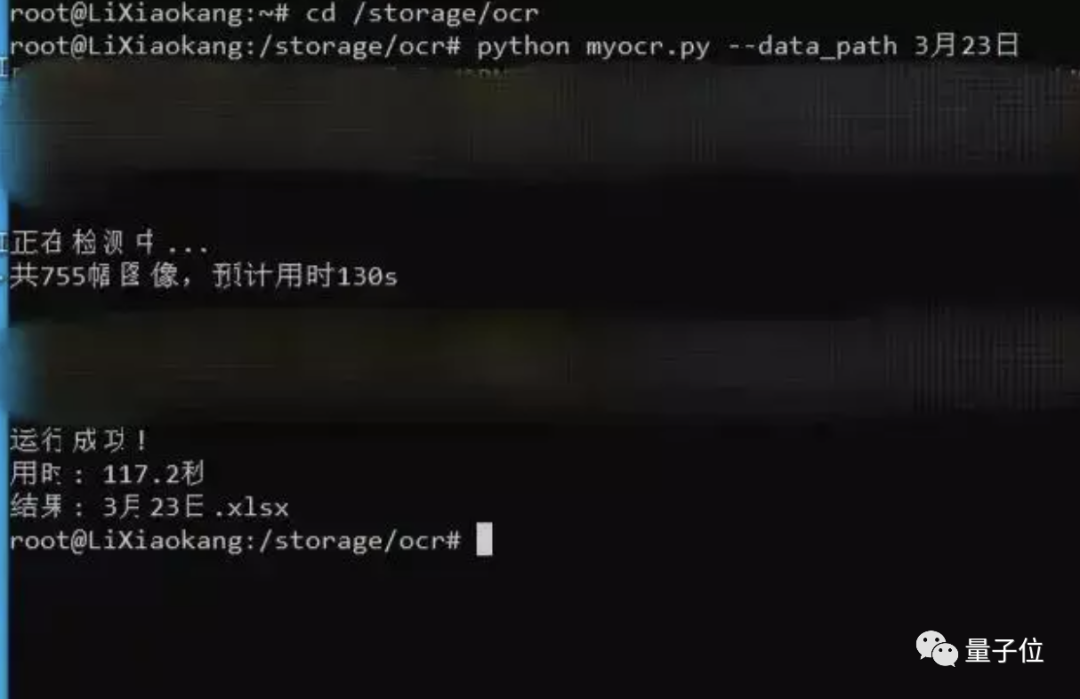
△圖源:復(fù)旦大學(xué)
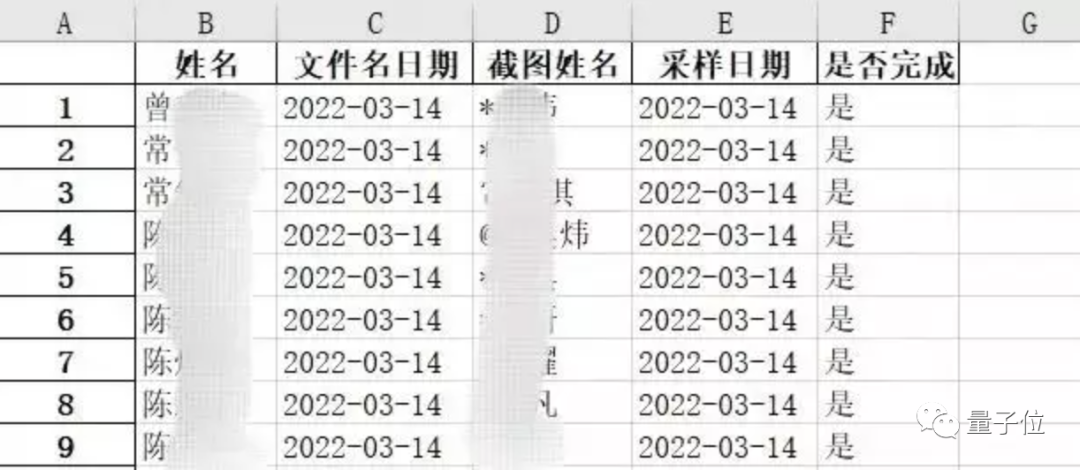
根據(jù)復(fù)旦官方的介紹,這位博士生更具體的是用到了Python中的正則表達式。
正則表達式可以把想要的信息從OCR識別的文本中篩選出來。
最后還會匯總到一張Excel文件中,方便工作人員確認。
而且為了他為了方便不會編程的同事使用,還把程序進行了封裝,只需要輸入一行命令就可以使用了。
來自復(fù)旦大學(xué)的博士生
開發(fā)這項“抗疫利器”的博士生,是來自復(fù)旦大學(xué)的李小康。
有意思的是,他并非是計算機專業(yè)的學(xué)生,而是生物醫(yī)學(xué)工程專業(yè)。
其研究方向是醫(yī)學(xué)影像與人工智能。

△圖源:復(fù)旦大學(xué)
對于這項工作,他認為:
雖然原理也很簡單,只要是會寫代碼的人第一時間就會明白是怎么回事,但是不做相關(guān)工作的感受不到這件事情的費時費力,自然也不會想出辦法。
我只是用我學(xué)到的知識解決實際工作中的困難。
△圖源:復(fù)旦大學(xué),李小康本人留言
據(jù)復(fù)旦大學(xué)官方介紹,在不久之后,師生可以不再手動收集核酸截圖,而是通過小程序直接上傳圖片了。
最后,引用李小康本人的話:這場戰(zhàn)“疫”我們一定可以勝利!