為什么MySQL要升級組復制?一分鐘系列
之前發了《Galera,MySQL主從之外的另一種選擇》之后,很多朋友在評論里留言:
- “這不就是Oracle Rac嗎?”
- “這不就是MGR嗎?”
- …
思路比結論重要,為什么比是什么重要,今天就花1分鐘,說下這里面架構演進的思路。
畫外音:大家不想聽底層細節,就不深入細節了。
最早的數據庫都是單機的,其最大的痛點是啥?
無法線性擴展。
磁盤能力無法線性擴展,內存能力無法線性擴展,計算能力無法線性擴展。
如今,喜歡創造概念的架構師們,把這種架構稱為“Shared Everything”架構。
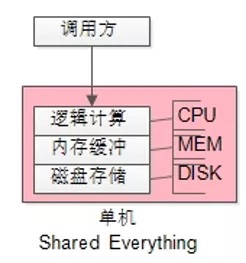
如上圖所示,DISK/MEM/CPU 都耦合在一個DBMS進程內,必須部署在一臺服務器上,完全處于競爭態,無法線性擴展,并行處理較差。
數據庫單機部署,就是典型的“Shared Everything”架構。
如何來提升系統的并行能力呢?
最容易想到的,就是把無狀態的邏輯計算部分,從DBMS進程內拆分出來,做成可擴展的微服務集群,實現“計算與存儲分離”。
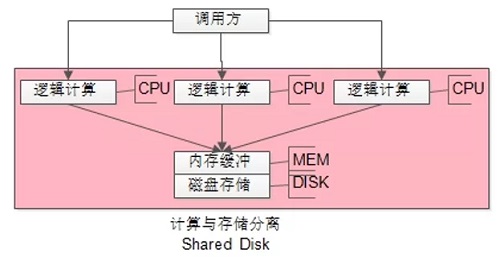
如上圖所示:
(1)CPU邏輯計算拆分出了獨立的進程,可以集群部署,能夠線程擴展;
(2)DISK/MEM 仍耦合在一個進程內,仍處于競爭態,無法線性擴展;
Oracle Rac,就是典型的“Shared Disk”架構,核心思路是“計算與存儲分離”。
存儲部分磁盤IO仍有集中的資源競爭,還有沒有進一步的優化空間呢?
最容易想到的,就是把數據打散,分布到不同的數據庫實例上,每部分數據享有單獨的資源。
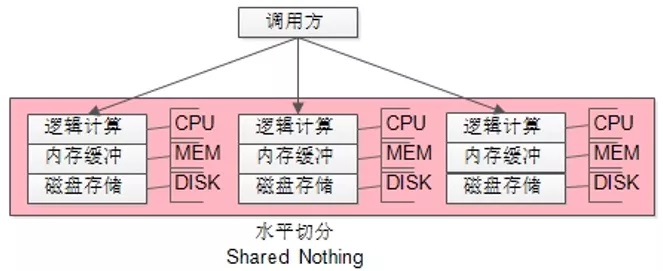
如上圖所示:
(1)把整體數據存儲分為了N份,每份之間沒有交集;
(2)每份數據的 DISK/MEM/CPU 都在一個DBMS進程內,部署在一臺服務器上;
(3)每份數據的資源之間的沒有競爭;
沒錯,這就是“水平切分”,它是典型的”Shared Nothing”架構。
對 Shared Everything/Disk/Nothing 這些高大上的名詞,進一步認識了不?
事情還沒完,水平切分存在什么問題呢?
水平切分雖然是一種可擴展架構,能夠實現線性擴展資源,但它會使得調用方失去數據的全局視野,使得調用方能力受限:
(1)無法實現全局JOIN;
(2)無法實現全局排序;
(3)無法支持集函數;
(4)原訪問一次DBMS的操作,需要調用多次;
(5)…
并把一些原本屬于DBMS職責的工作,轉嫁到調用方。
如何解決“線性擴展能力”,同時又解決“失去全局視野”與“調用方能力受限”的問題呢?
最容易想到的方案是,數據庫主從集群,每份數據都進行復制,每個實例都獨享 DISK/MEM/CPU資源,避免實例之間的資源競爭。
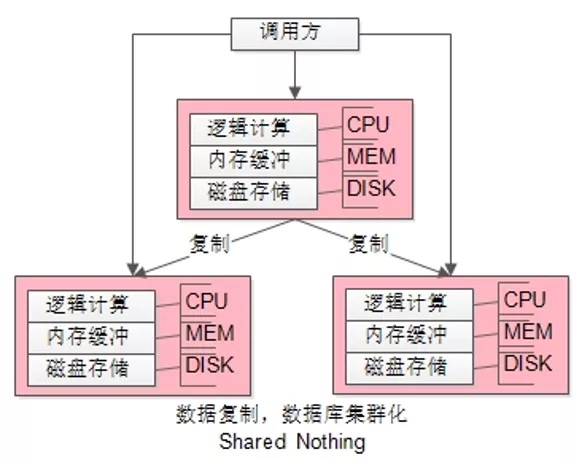
如上圖所示:
(1)把整體數據存儲分復制了N份,每份之間數據都一樣;
(2)每份數據的 DISK/MEM/CPU 都在一個DBMS進程內,部署在一臺服務器上;
(3)每份數據的資源之間的沒有競爭;
理想很豐滿,現實很骨干,思路沒問題,但實際執行“復制”的過程中,會碰到一些問題。
以MySQL為例,有3種常見的復制方式:
(1)異步復制
(2)半同步復制
(3)組復制
第一種,異步復制(Asynchronous Replication)
又叫主從復制(Primary-Secondary Replication),是互聯網公司用的最多的數據復制與數據庫集群化方法,它的思路是,從庫執行串行化后的主庫事務。
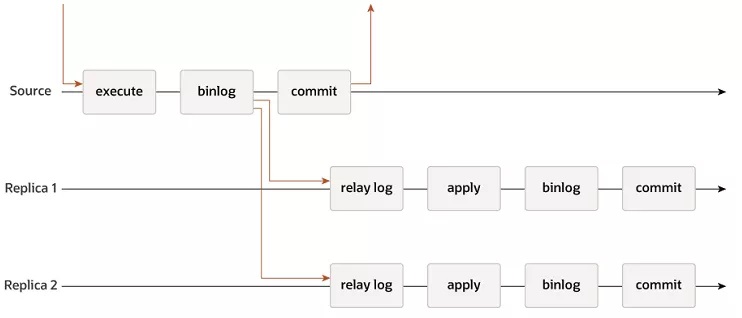
其核心原理如上圖所示:
(1)第一條時間線:主庫時間線;
- 主庫執行事務
- 主庫事務串行化binlog
- binlog同步給從庫
- 主庫事務提交完成
(2)第二條/第三條時間線:從庫時間線;
- 收到relay log
- 執行和主庫一樣的事務
- 生成自己的binlog(還可以繼續二級從庫)
- 從庫事務提交完成
從這個時間線可以看到:
(1)主庫事務提交
(2)從庫事務執行
是并行執行的,主庫并不能保證從庫的事務一定執行成功,甚至不能保證從庫一定收到相關的請求,這也是其稱作“異步復制”的原因。
第二種,半同步復制(Semi-synchronous Replication)
為了解決異步復制中“不能保證從庫一定收到請求”等問題,對異步復制做了升級。
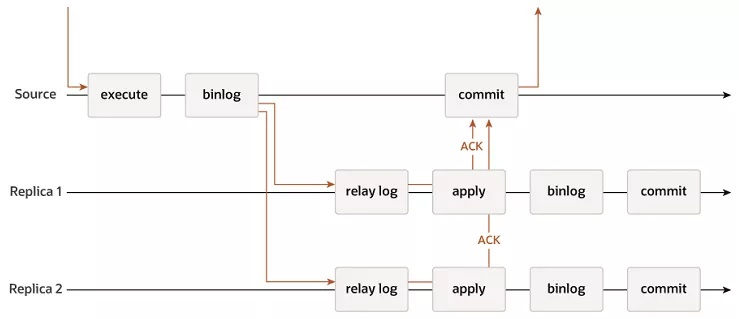
其核心原理如上圖所示:
(1)第一條時間線:主庫時間線;
- 主庫執行事務
- 主庫事務串行化binlog
- binlog同步給從庫
- 等從庫確認收到請求,主庫事務才提交完成
(2)第二條/第三條時間線:從庫時間線;
- 收到relay log
- 執行和主庫一樣的事務,并給主庫一個確認
- 生成自己的binlog(還可以繼續二級從庫)
- 從庫事務提交完成
從這個時間線可以看到:
(1)主庫收到從庫的ACK,才會提交;
(2)從庫收到請求后,事務提交前,會給主庫一個ACK;
半同步復制存在什么問題呢?
(1)主庫的性能,會受到較大的影響,事務提交之前,中間至少要等待2個主從之間的網絡TTL;
(2)從庫仍然有延時,主從之間數據仍然不一致;(3)主從角色有差異,主節點仍然是單點;
大數據量,高并發量的互聯網業務,一般不使用“半同步復制”,更多的公司仍然使用“異步復制”的模式。
最后是MySQL5.7里,新提出的MySQL組復制。
第三種,組復制(MySQL Group Replication,MGR)
MGR有一些帥氣的能力:
(1)解決了單點寫入的問題,一個分組內的所有節點都能夠寫入;
(2)最終一致性,緩解了一致性問題,可以認為大部分實例的數據都是最新的;
(3)高可用,系統故障時(即使是腦裂),系統依然可用;
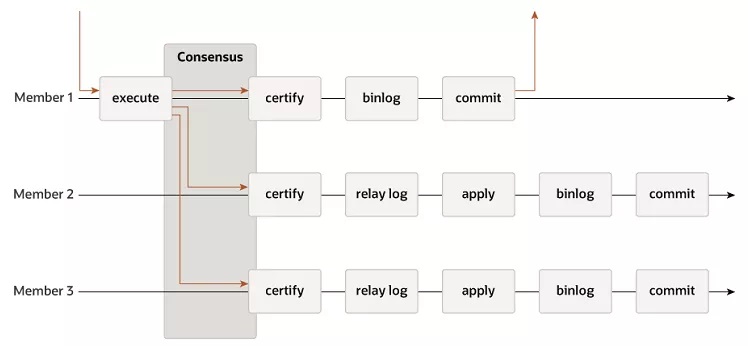
如上圖所示:
(1)首先,分組內的MySQL實例不再是“主從”關系,而是對等的“成員”關系,故每個節點都可以寫入;
(2)其次,增加了一個協商共識的認證(certify)環節,多數節點達成一致的事務才能提交;
畫外音:Garela也是此類機制。
和MySQL傳統的復制不同,MGR的核心是分布式共識算法,類似于Paxos。
基于上一篇《Galera,MySQL主從之外的另一種選擇》的留言,似乎大部分人都非常熟悉算法的底層內核,本篇就先不展開了。
畫外音:感興趣的人多的話,再展開細講。
不知不覺寫了幾千字了,收個尾做個總結吧。
三類常見數據庫架構
- Shared Everything:數據庫單機系統,資源競爭;
- Shared Disk:Oracle Rac,計算與存儲分離;
- Shared Nothing:水平切分,復制集群,資源完全隔離;
三類常見復制方式
- 異步復制:傳統主從,互聯網公司最常用;
- 半同步復制:從庫確認,主庫才提交;
- 組復制:MySQL 5.7的新功能,核心在于分布式共識算法;
知其然,知其所以然。思路比結論更重要。
畫外音:對不起,讀完本文不止1分鐘。
【本文為51CTO專欄作者“58沈劍”原創稿件,轉載請聯系原作者】