盤點13種流行的數據處理工具
本文轉載自微信公眾號「大數據DT」,作者斯里瓦斯塔瓦 。轉載本文請聯系大數據DT公眾號。
數據分析是對數據進行攝取、轉換和可視化的過程,用來發掘對業務決策有用的洞見。
在過去的十年中,越來越多的數據被收集,客戶希望從數據中獲得更有價值的洞見。他們還希望能在最短的時間內(甚至實時地)獲得這種洞見。他們希望有更多的臨時查詢以便回答更多的業務問題。為了回答這些問題,客戶需要更強大、更高效的系統。
批處理通常涉及查詢大量的冷數據。在批處理中,可能需要幾個小時才能獲得業務問題的答案。例如,你可能會使用批處理在月底生成賬單報告。
實時的流處理通常涉及查詢少量的熱數據,只需要很短的時間就可以得到答案。例如,基于MapReduce的系統(如Hadoop)就是支持批處理作業類型的平臺。數據倉庫是支持查詢引擎類型的平臺。
流數據處理需要攝取數據序列,并根據每條數據記錄進行增量更新。通常,它們攝取連續產生的數據流,如計量數據、監控數據、審計日志、調試日志、網站點擊流以及設備、人員和商品的位置跟蹤事件。
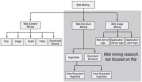
圖13-6展示了使用AWS云技術棧處理、轉換并可視化數據的數據湖流水線。
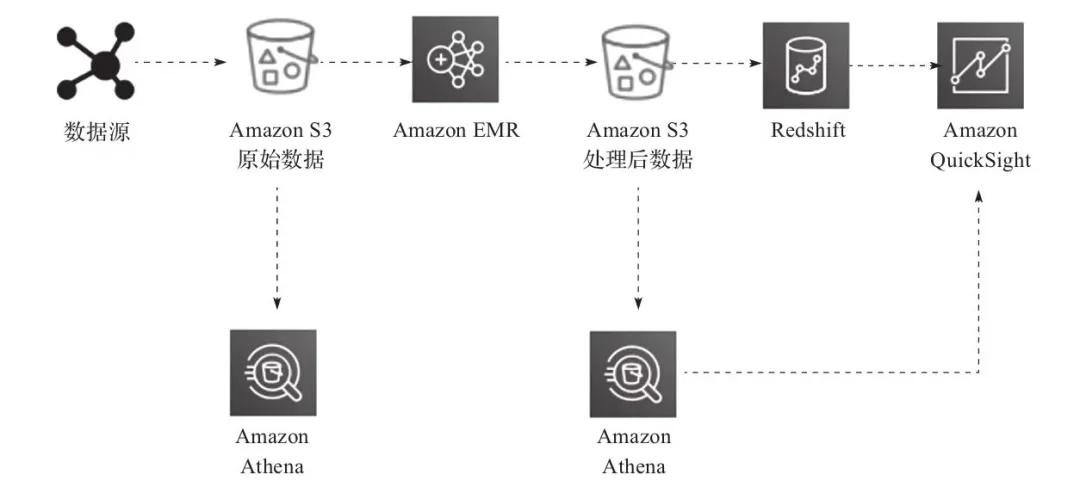
▲圖13-6 使用數據湖ETL流水線處理數據
在這里,ETL流水線使用Amazon Athena對存儲在Amazon S3中的數據進行臨時查詢。從各種數據源(例如,Web應用服務器)攝取的數據會生成日志文件,并持久保存在S3。然后,這些文件將被Amazon Elastic MapReduce(EMR)轉換和清洗成產生洞見所需的形式并加載到Amazon S3。
用COPY命令將這些轉換后的文件加載到Amazon Redshift,并使用Amazon QuickSight進行可視化。使用Amazon Athena,你可以在數據存儲時直接從Amazon S3中查詢,也可以在數據轉換后查詢(從聚合后的數據集)。你可以在Amazon QuickSight中對數據進行可視化,也可以在不改變現有數據流程的情況下輕松查詢這些文件。
以下是一些最流行的可以幫助你對海量數據進行轉換和處理的數據處理技術:
01 Apache Hadoop

Apache Hadoop使用分布式處理架構,將任務分發到服務器集群上進行處理。分發到集群服務器上的每一項任務都可以在任意一臺服務器上運行或重新運行。集群服務器通常使用HDFS將數據存儲到本地進行處理。
在Hadoop框架中,Hadoop將大的作業分割成離散的任務,并行處理。它能在數量龐大的Hadoop集群中實現大規模的伸縮性。它還設計了容錯功能,每個工作節點都會定期向主節點報告自己的狀態,主節點可以將工作負載從沒有積極響應的集群重新分配出去。
Hadoop最常用的框架有Hive、Presto、Pig和Spark。
02 Apache Spark

Apache Spark是一個內存處理框架。Apache Spark是一個大規模并行處理系統,它有不同的執行器,可以將Spark作業拆分,并行執行任務。為了提高作業的并行度,可以在集群中增加節點。Spark支持批處理、交互式和流式數據源。
Spark在作業執行過程中的所有階段都使用有向無環圖(Directed Acyclic Graph,DAG)。DAG可以跟蹤作業過程中數據的轉換或數據沿襲情況,并將DataFrames存儲在內存中,有效地最小化I/O。Spark還具有分區感知功能,以避免網絡密集型的數據改組。
03 Hadoop用戶體驗
Hadoop用戶體驗(Hadoop User Experience,HUE)使你能夠通過基于瀏覽器的用戶界面而不是命令行在集群上進行查詢并運行腳本。
HUE在用戶界面中提供了最常見的Hadoop組件。它可以基于瀏覽器查看和跟蹤Hadoop操作。多個用戶可以登錄HUE的門戶訪問集群,管理員可以手動或通過LDAP、PAM、SPNEGO、OpenID、OAuth和SAML2認證管理訪問。HUE允許你實時查看日志,并提供一個元存儲管理器來操作Hive元存儲內容。
04 Pig
Pig通常用于處理大量的原始數據,然后再以結構化格式(SQL表)存儲。Pig適用于ETL操作,如數據驗證、數據加載、數據轉換,以及以多種格式組合來自多個來源的數據。除了ETL,Pig還支持關系操作,如嵌套數據、連接和分組。
Pig腳本可以使用非結構化和半結構化數據(如Web服務器日志或點擊流日志)作為輸入。相比之下,Hive總是要求輸入數據滿足一定模式。Pig的Latin腳本包含關于如何過濾、分組和連接數據的指令,但Pig并不打算成為一種查詢語言。Hive更適合查詢數據。Pig腳本根據Pig Latin語言的指令,編譯并運行以轉換數據。
05 Hive

Hive是一個開源的數據倉庫和查詢包,運行在Hadoop集群之上。SQL是一項非常常見的技能,它可以幫助團隊輕松過渡到大數據世界。
Hive使用了一種類似于SQL的語言,叫作Hive Query語言(Hive Query Language,HQL),這使得在Hadoop系統中查詢和處理數據變得非常容易。Hive抽象了用Java等編碼語言編寫程序來執行分析作業的復雜性。
06 Presto
Presto是一個類似Hive的查詢引擎,但它的速度更快。它支持ANSI SQL標準,該標準很容易學習,也是最流行的技能集。Presto支持復雜的查詢、連接和聚合功能。
與Hive或MapReduce不同,Presto在內存中執行查詢,減少了延遲,提高了查詢性能。在選擇Presto的服務器容量時需要小心,因為它需要有足夠的內存。內存溢出時,Presto作業將重新啟動。
07 HBase

HBase是作為開源Hadoop項目的一部分開發的NoSQL數據庫。HBase運行在HDFS上,為Hadoop生態系統提供非關系型數據庫。HBase有助于將大量數據壓縮并以列式格式存儲。同時,它還提供了快速查找功能,因為其中很大一部分數據被緩存在內存中,集群實例存儲也同時在使用。
08 Apache Zeppelin
Apache Zeppelin是一個建立在Hadoop系統之上的用于數據分析的基于Web的編輯器,又被稱為Zeppelin Notebook。它的后臺語言使用了解釋器的概念,允許任何語言接入Zeppelin。Apache Zeppelin包括一些基本的圖表和透視圖。它非常靈活,任何語言后臺的任何輸出結果都可以被識別和可視化。
09 Ganglia
Ganglia是一個Hadoop集群監控工具。但是,你需要在啟動時在集群上安裝Ganglia。Ganglia UI運行在主節點上,你可以通過SSH訪問主節點。Ganglia是一個開源項目,旨在監控集群而不影響其性能。Ganglia可以幫助檢查集群中各個服務器的性能以及集群整體的性能。
10 JupyterHub
JupyterHub是一個多用戶的Jupyter Notebook。Jupyter Notebook是數據科學家進行數據工程和ML的最流行的工具之一。JupyterHub服務器為每個用戶提供基于Web的Jupyter Notebook IDE。多個用戶可以同時使用他們的Jupyter Notebook來編寫和執行代碼,從而進行探索性數據分析。
11 Amazon Athena

Amazon Athena是一個交互式查詢服務,它使用標準ANSI SQL語法在Amazon S3對象存儲上運行查詢。Amazon Athena建立在Presto之上,并擴展了作為托管服務的臨時查詢功能。Amazon Athena元數據存儲與Hive元數據存儲的工作方式相同,因此你可以在Amazon Athena中使用與Hive元數據存儲相同的DDL語句。
Athena是一個無服務器的托管服務,這意味著所有的基礎設施和軟件運維都由AWS負責,你可以直接在Athena的基于Web的編輯器中執行查詢。
12 Amazon Elastic MapReduce
Amazon Elastic MapReduce(EMR)本質上是云上的Hadoop。你可以使用EMR來發揮Hadoop框架與AWS云的強大功能。EMR支持所有最流行的開源框架,包括Apache Spark、Hive、Pig、Presto、Impala、HBase等。
EMR提供了解耦的計算和存儲,這意味著不必讓大型的Hadoop集群持續運轉,你可以執行數據轉換并將結果加載到持久化的Amazon S3存儲中,然后關閉服務器。EMR提供了自動伸縮功能,為你節省了安裝和更新服務器的各種軟件的管理開銷。
13 AWS Glue
AWS Glue是一個托管的ETL服務,它有助于實現數據處理、登記和機器學習轉換以查找重復記錄。AWS Glue數據目錄與Hive數據目錄兼容,并在各種數據源(包括關系型數據庫、NoSQL和文件)間提供集中的元數據存儲庫。
AWS Glue建立在Spark集群之上,并將ETL作為一項托管服務提供。AWS Glue可為常見的用例生成PySpark和Scala代碼,因此不需要從頭開始編寫ETL代碼。
Glue作業授權功能可處理作業中的任何錯誤,并提供日志以了解底層權限或數據格式問題。Glue提供了工作流,通過簡單的拖放功能幫助你建立自動化的數據流水線。
小結
數據分析和處理是一個龐大的主題,值得單獨寫一本書。本文概括地介紹了數據處理的流行工具。還有更多的專有和開源工具可供選擇。
關于作者:所羅伯·斯里瓦斯塔瓦(Saurabh Shrivastava)是一位技術領導者、作家、發明家和公開演說家,在IT行業擁有超過16年的工作經驗。他目前在Amazon Web Services(AWS)擔任解決方案架構師團隊負責人,幫助全球咨詢合作伙伴和企業客戶展開云計算之旅。他還牽頭了全球技術伙伴的合作,并且擁有云平臺自動化領域的專利。
內拉賈利·斯里瓦斯塔夫(Neelanjali Srivastav)是一位技術領導者、敏捷教練和云計算從業者,在軟件行業擁有超過14年的經驗。她擁有昌迪加爾旁遮普大學生物信息學和信息技術專業的學士和碩士學位。
本文摘編自《解決方案架構師修煉之道》,經出版方授權發布。(ISBN:9787111694441)
作者:所羅伯·斯里瓦斯塔瓦(Saurabh Shrivastava)、內拉賈利·斯里瓦斯塔夫(Neelanjali Srivastav)
來源:大數據DT(ID:hzdashuju)