吐血整理:盤點19種大數據處理的典型工具

大數據的生命周期分為數據獲取(data acquisition)、數據存儲(data storage)、數據分析(data analysis)以及結果(result),并且將前述大數據處理的三代技術中相關的工具映射至數據獲取、數據存儲和數據分析三個環(huán)節(jié)來進行分類討論,詳情如表1-2所示。
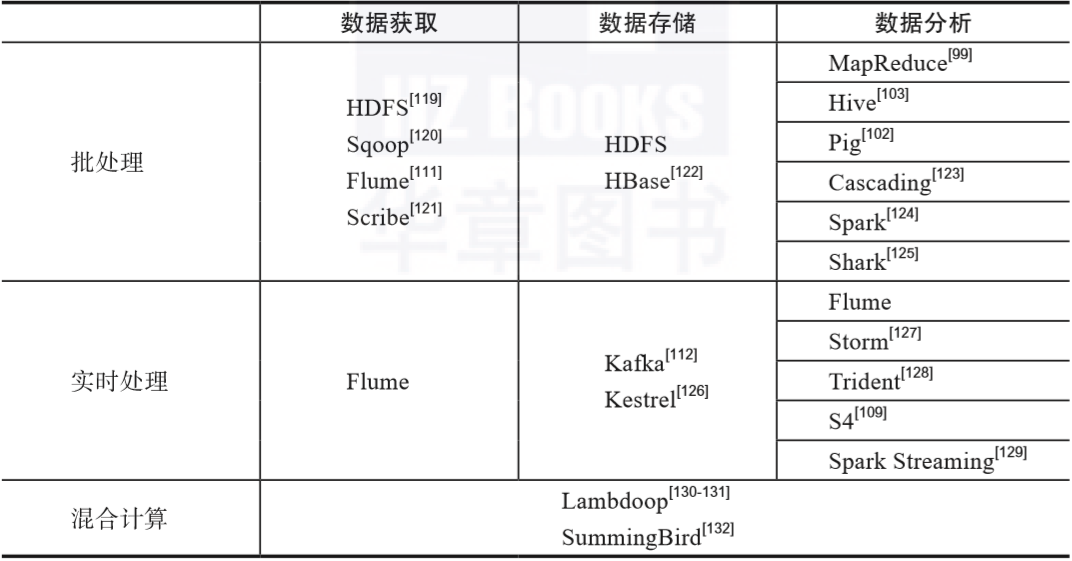
▲表1-2 大數據處理的典型工具
在數據獲取階段,通常涉及從多源異構的數據源獲取數據,這些數據源可能是批處理數據源,也有可能是實時流數據源;
在數據存儲階段,需要對前一階段已經獲取到的數據進行存儲,以便進行后續(xù)的分析與處理,常見的存儲方式有磁盤(disk)形式和無盤(diskless)形式。
在數據分析階段,針對不同的應用需求,會運用各類模型和算法來對數據進行分析與處理。
在表1-2中,三代技術中不同的處理階段所涉及的工具存在重疊。此外,對于混合計算技術,其本身同時涉及批處理技術和實時處理技術,實現混合計算模型的技術也要比單純的批處理技術和實時處理技術更加復雜;鑒于混合計算技術的上述特點,這里不對在數據的獲取、存儲與分析方面所涉及的具體工具做特別的劃分。
01 HDFS
Hadoop分布式文件系統(tǒng)(Hadoop Distributed File System,HDFS)目前是Apache Hadoop項目的一個子項目,與已有的分布式文件系統(tǒng)有很多相似之處。

此外,作為專門針對商業(yè)化硬件(commodity hardware)設計的文件系統(tǒng),HDFS的獨特之處也很明顯:首先其具有很高的容錯性,其次可以部署在較為廉價的硬件上,最后能夠提供高吞吐量的應用數據訪問能力。
對于終端用戶而言,HDFS就是一個傳統(tǒng)的文件系統(tǒng),具有文件和目錄的創(chuàng)建、修改、刪除等常規(guī)操作。
HDFS采用主/從(Master/Slave)體系結構。單個HDFS集群僅包含一個名稱節(jié)點(NameNode),其提供元數據服務,管理文件系統(tǒng)的命名空間(namespace),并引導用戶對文件的訪問。此外,單個HDFS集群可以包含多個數據節(jié)點(DataNode),數據節(jié)點負責管理與自身相關聯的存儲空間。
HDFS對外給出文件系統(tǒng)的命名空間作為用戶對數據進行訪存的接口。
在HDFS內部,單個文件通常被分割成多個塊(block),這些塊存儲在一系列數據節(jié)點上。由名稱節(jié)點在整個HDFS集群的命名空間上執(zhí)行文件和目錄的打開、讀取和關閉等操作。文件的塊與數據節(jié)點之間的映射也是由名稱節(jié)點管理的。數據節(jié)點基于名稱節(jié)點的指令來實施塊的創(chuàng)建、復制和刪除等。
02 Sqoop
Sqoop是一個在Hadoop和關系數據庫服務器之間傳送數據的工具,方便大量數據的導入導出工作,其支持多種類型的數據存儲軟件。

Sqoop的核心功能為數據的導入和導出。
- 導入數據:從諸如MySQL、SQL Server和Oracle等關系數據庫將數據導入到Hadoop下的HDFS、Hive和HBase等數據存儲系統(tǒng)。
- 導出數據:從Hadoop的文件系統(tǒng)中將數據導出至關系數據庫。
Sqoop的一個顯著特點是可以使用MapReduce將數據從傳統(tǒng)的關系數據庫導入到HDFS中。Sqoop作為一個通用性的工具,只需要在一個節(jié)點上安裝,因此安裝和使用十分便捷。
03 Flume
Flume是由Hadoop生態(tài)系統(tǒng)中著名的軟件公司Cloudera于2011年發(fā)布,該軟件能夠支持分布式海量日志的采集、集成與傳輸,以實時的方式從數據發(fā)送方獲取數據,并傳輸給數據接收方。

Flume具有兩個顯著的特點:可靠性和可擴展性。
- 針對可靠性,其提供了從強到弱的三級保障,即End-to-end、Store on failure和Best effort。
- 針對可擴展性,其采用三層的體系結構,即Agent、Collector和Storage,每層都可以在水平方向上進行擴展。
Flume以Agent的方式運行,單個Agent包含Source、Channel和Sink三個組件,由Agent對數據進行收集,然后交付給存儲機制。從多個數據源收集到的日志信息依次經過上述三個組件,然后存入HDFS或HBase中。因此,通過Flume可以將數據便捷地轉交給Hadoop體系結構。
04 Scribe
Scribe是由Facebook開發(fā)的分布式日志系統(tǒng),在Facebook內部已經得到了廣泛的應用。Scribe能夠針對位于不同數據源的日志信息進行收集,然后存儲至某個統(tǒng)一的存儲系統(tǒng),這個存儲系統(tǒng)可以是網絡文件系統(tǒng)(Network File System,NFS),也可以是分布式文件系統(tǒng)。

Scribe的體系結構由三部分組成:Scribe Agent、Scribe和Storage。
- 第一部分Scribe Agent為用戶提供接口,用戶使用該接口來發(fā)送數據。
- 第二部分Scribe接收由Scribe Agent發(fā)送來的數據,根據各類數據所具有的不同topic再次分發(fā)給不同的實體。
- 第三部分Storage包含多種存儲系統(tǒng)和介質。
Scribe的日志收集行為只包括主動寫入的日志,Scribe自身沒有主動抓取日志的功能。因此,用戶需要主動向Scribe Agent發(fā)送相關的日志信息。
05 HBase
HBase的全稱為Hadoop Database,是基于谷歌BigTable的開源實現,其使用Hadoop體系結構中的HDFS作為基本的文件系統(tǒng)。谷歌根據BigTable的理念設計實現了谷歌文件系統(tǒng)GFS,但是該方案未開源。HBase可以稱為BigTable的山寨版,是開源的。

HBase在Hadoop體系結構中的位置介于HDFS和MapReduce之間,其架構為主/從形式,內部的兩個核心構件為Master和RegionServer。
HBase是建立在HDFS之上的分布式面向列的數據庫,能夠針對海量結構化數據實現隨機的實時訪問,其設計理念和運行模式都充分利用了HDFS的高容錯性。
由于HBase是面向列的,因此它在數據庫的表中是按照行進行排序的。在HBase中,所有的存儲內容都是字節(jié),任何要存儲的內容都需要先轉換成字節(jié)流的形式,此外數據庫的行鍵值按照字節(jié)進行排序,同時形成了索引。
06 MapReduce
MapReduce是Hadoop體系結構中極為重要的核心構件之一。作為一個分布式的并行計算模型,MapReduce包含的兩個單詞分別具有特定的含義:“Map”表示“映射”;“Reduce”表示“歸約”。上述兩個概念的基本理念源于函數式編程語言(functional programming language)。

與傳統(tǒng)的編程語言不同,函數式編程語言是一類非馮諾依曼式的程序設計語言,其編程范式的抽象程度很高,主要由原始函數、定義函數和函數型構成。
MapReduce的這種設計思想使分布式并行程序設計的難度得以簡化,用戶將已有的代碼稍加修改就能夠運行在分布式環(huán)境下。在實際應用場景中,大多數情況下收集到的大量多源異構數據都不具有特定的規(guī)律和特征。
MapReduce的工作過程能夠在一定程度上將上述數據按照某種規(guī)律進行歸納和總結。在“Map”階段,通過指定的映射函數提取數據的特征,得到的結果的形式為鍵值對 。在“Reduce”階段,通過指定的歸約函數對“Map”階段得到的結果進行統(tǒng)計。對于不同的具體問題,所需要的歸約函數的個數可能千差萬別。
總體來說,MapReduce具有開發(fā)難度低、擴展性強和容錯性高三個顯著特點。盡管其分布式并行計算模型能大幅度提高海量數據的處理速度,但受限于大數據的規(guī)模,通常MapReduce的作業(yè)例程的執(zhí)行時間為分鐘級,隨著數據量的增加,耗時若干天也很普遍。
07 Hive
Hive針對數據倉庫來提供類似SQL語句的查詢功能,其能夠將以結構化形式存儲的數據映射成數據庫表,主要應用場景為多維度數據分析和海量結構化數據離線分析。Hive的體系結構主要包含用戶接口、元數據存儲、解釋器、編譯器、優(yōu)化器和執(zhí)行器。

雖然使用MapReduce也能夠實現查詢,但是對于邏輯復雜度高的查詢,用戶在實現時難度較大。Hive提供類似于SQL的語法接口,降低了學習成本,提高了開發(fā)效率。
Hive基于SQL的語法來定義名為HiveQL或HQL的查詢語言,其支持常規(guī)的索引化和基本的數據查詢,更重要的是能夠將基于SQL的查詢需求轉化為MapReduce的作業(yè)例程。
除了自身具有的功能之外,用戶可以在Hive中編寫自定義函數,具體來說分為三種:
- 用戶自定義函數(User Defined Function,UDF)
- 用戶自定義聚合函數(User Defined Aggregation Function,UDAF)
- 用戶自定義表生成函數(User Defined Table-generating Function,UDTF)
08 Pig
Pig是一個面向過程的高級程序設計語言,能夠分析大型數據集,并將結果表示為數據流,其內置了多種數據類型,并且支持元組(tuple)、映射(map)和包(package)等范式。

Pig有兩種工作模式:Local模式和MapReduce模式。
在Local模式下,Pig的運行獨立于Hadoop體系結構,全部操作均在本地進行。
在MapReduce模式下,Pig使用了Hadoop集群中的分布式文件系統(tǒng)HDFS。
作為一種程序設計語言,Pig能夠對數據進行加載、處理,并且存儲獲得的結果。Pig和Hive均能夠簡化Hadoop的常見工作任務。Hive通常應用在靜態(tài)數據上,處理例行性的分析任務。
Pig比Hive在規(guī)模上更加輕量,其與SQL的結合使得用戶能夠使用比Hive更加簡潔的代碼來給出解決方案。與MapReduce相比,Pig在接口方面提供了更高層次的抽象,具有更多的數據結構類型。此外,Pig還提供了大量的數據變換操作,MapReduce在這方面比較薄弱。
09 Cascading
Cascading是用Java語言編寫成的開源庫,能夠脫離MapReduce來完成對復雜數據工作流的處理。該開源庫提供的應用程序編程接口定義了復雜的數據流以及將這些數據流與后端系統(tǒng)集成的規(guī)則。此外,其還定義了將邏輯數據流映射至計算平臺并進行執(zhí)行的規(guī)則。

針對數據的提取、轉換和加載(Extract Transform Load,ETL),Cascading提供了6個基本操作:
- 復制(copy)
- 過濾(filter)
- 合并(merge)
- 計數(count)
- 平均(average)
- 結合(join)
初級的ETL應用程序通常涉及數據和文件的復制,以及不良數據的過濾。針對多種不同數據源的輸入文件,需要對它們進行合并。計數和平均是對數據和記錄進行處理的常用操作。結合指的是將不同處理分支中的處理結果按照給定的規(guī)則進行結合。
10 Spark
與Hadoop類似,Spark也是一個針對大數據的分布式計算框架。Spark可以用來構建大規(guī)模、低延遲的數據處理應用程序。

相對于Hadoop,Spark的顯著特點是能夠在內存中進行計算,因此又稱為通用內存并行計算框架,與MapReduce兼容,其主要構件包括SparkCore、SparkSQL、SparkStreaming、MLlib、GraphX、BlinkDB和Tachyon。
Hadoop存在磁盤I/O和序列化等性能瓶頸,在Spark的設計理念中,選用內存來存儲Hadoop中存儲在HDFS的中間結果。Spark兼容HDFS,能夠很好地融入Hadoop體系結構,被認為是MapReduce的替代品。
根據Spark官方網站的數據,Spark的批處理速度比MapReduce提升了近10倍,內存中的數據分析速度則提升了近100倍。
Spark模型所特有的彈性分布式數據集(Resilient Distributed Dataset,RDD)使得針對數據的災難恢復在內存和磁盤上都可以實現。
總體來說,Spark的編程模型具有以下四個特點:速度(speed)、簡易(ease of use)、通用(generality)和兼容(runs everywhere)。
- 在速度方面,Spark使用基于有向無環(huán)圖(Directed Acyclic Graph,DAG)的作業(yè)調度算法,采用先進的查詢優(yōu)化器和物理執(zhí)行器提高了數據的批處理和流式處理的性能。
- 在簡易方面,Spark支持多種高級算法,用戶可以使用Java、Scala、Python、R和SQL等語言編寫交互式應用程序。
- 在通用方面,Spark提供了大量的通用庫,使用這些庫可以方便地開發(fā)出針對不同應用場景的統(tǒng)一解決方案,極大地降低了研發(fā)與運營的成本。
- 在兼容方面,Spark本身能夠方便地與現有的各類開源系統(tǒng)無縫銜接,例如已有的Hadoop體系結構中的HDFS和Hbase。
11 Shark
作為一個面向大規(guī)模數據的數據倉庫工具,Shark最初是基于Hive的代碼進行開發(fā)的。Hive在執(zhí)行交互查詢時需要在私有數據倉庫上執(zhí)行非常耗時的ETL操作,為了彌補這個性能問題,Shark成了Hadoop體系結構中的首個交互式SQL軟件。

Shark支持Hive包含的查詢語言、元存儲、序列化格式以及自定義函數。后來,Hadoop體系結構中MapReduce本身的結構限制了Shark的發(fā)展,研究者們中止了Shark的研發(fā),啟動了Shark SQL這個新項目。Shark SQL是基于Spark的一個組件,提供了針對結構化數據的便捷操作,統(tǒng)一了結構化查詢語言與命令式語言。
Shark在Spark的體系結構中提供了和Hive相同的HiveQL編程接口,因此與Hive兼容。通過Hive的HQL解析,將HQL轉換成Spark上的RDD操作。
12 Kafka
Kafka是一個分布式流處理平臺(distributed streaming platform),最初由領英公司開發(fā),使用的編程語言是Java和Scala。

Kafka支持分區(qū)(partition)和副本(replica),針對消息隊列進行處理。消息傳送功能包含連接服務(connection service)、消息的路由(routing)、傳送(delivery)、持久性(durability)、安全性(security)和日志記錄(log)。
Kafka的主要應用程序接口有如下四類:生產者(producer API)、消費者(consumer API)、流(stream API)和連接器(connector API)。
Kafka對外的接口設計理念是基于話題(topic)的,消息生成后被寫入話題中,用戶從話題中讀取消息。單個的話題由多個分區(qū)構成,當系統(tǒng)性能下降時,通常的操作是增加分區(qū)的個數。
分區(qū)之間的消息互相獨立,每個分區(qū)內的消息是有序的。新消息的寫入操作在具體實現中為相應文件內容的追加操作,該方式具有較強的性能。由于一個話題可以包含多個分區(qū),因此Kafka具有高吞吐量、低延遲的特性。
消息隊列包含兩個模型:點對點(point-to-point)和發(fā)布/訂閱(publish/subscribe)。
對于點對點模型,消息生成后進入隊列,由用戶從隊列中取出消息并使用。當消息被使用后,其生命周期已經結束,即該消息無法再次被使用。雖然消息隊列支持多個用戶,但一個消息僅能夠被一個用戶所使用。
對于發(fā)布/訂閱模型,消息生成后其相關信息會被發(fā)布到多個話題中,只要訂閱了相關話題的用戶就都可以使用該消息。與點對點模型不同,在發(fā)布/訂閱模型中一個消息可以被多個用戶使用。
13 Kestrel
Kestrel是由推特(Twitter)開發(fā)的開源中間件(middleware),使用的編程語言為Scala,其前身是名為Starling的輕量級分布式隊列服務器,同樣Kestrel也具有輕量化的特點。
Starling支持MemCache協議,其能夠方便地構建網絡訪問隊列。推特早期使用Starling來處理大量的隊列消息,后來推特將基于Ruby語言的Starling項目進行重構,使用Scala語言將其重新實現,得到Kestrel。
在協議支持性方面,Kestrel支持三類協議:MemCache、Text和Thrift,其中MemCache協議沒有完整地實現,僅支持部分操作。Kestrel本身運行在Java虛擬機(Java Virtual Machine,JVM)上,針對Java的各類優(yōu)化措施均可以使用。
為了改善性能,Kestrel中的隊列存儲在內存中,針對隊列的操作日志保存在硬盤中。雖然Kestrel本身是輕量化的,但其具有豐富的配置選項,能夠很方便地組成集群,集群中的節(jié)點互相之間是透明的,針對隊列中消息獲取的GET協議支持阻塞獲取和可靠獲取。
阻塞獲取是指用戶可以設置超時時間,在時間內有消息的話即刻返回,如果超時后還沒有消息就結束等待。可靠獲取是指隊列服務器只有在收到用戶明確的確認反饋后,才將相關的消息從隊列中永久刪除。
如果用戶使用GET操作從隊列獲取消息后隊列服務器馬上將該消息從隊列中刪除,那么此后需要用戶來確保該消息不會異常丟失,這對網絡狀態(tài)和系統(tǒng)運行的特定環(huán)境要求較為苛刻。因此,用戶可以采用可靠獲取的方式來消除上述疑慮。
14 Storm
Storm是使用Java和Clojure編寫而成的分布式實時處理系統(tǒng),其雛形是由Nathan Marz和BackType構建的,BackType是一家社交數據分析公司。2011年,推特收購BackType,并將Storm開源。

Storm的主要功能是針對持續(xù)產生的數據流進行計算,進而彌補了Hadoop體系結構對實時性支持的缺失。Storm的處理速度快,具有良好的可擴展性和容錯性,其所處理的數據位于內存中。
用戶在Storm中設計的計算圖稱為拓撲(topology),拓撲中包含主節(jié)點和從節(jié)點,且以集群的形式呈現。Storm的主/從體系結構是由兩類節(jié)點實現的:控制節(jié)點(master node)和工作節(jié)點(worker node),調度相關的信息以及主從節(jié)點的重要工作數據都是由ZooKeeper集群來負責處理的。
控制節(jié)點為主節(jié)點,其上運行的Nimbus進程主要負責狀態(tài)監(jiān)測與資源管理,該進程維護和分析Storm的拓撲,同時收集需要執(zhí)行的任務,然后將收集到的任務指派給可用的工作節(jié)點。
工作節(jié)點為從節(jié)點,其上運行的Supervisor進程包含一個或多個工作進程(worker),工作進程根據所要處理的任務量來配置合理數量的執(zhí)行器(executor)以便執(zhí)行任務。Supervisor進程監(jiān)聽本地節(jié)點的狀態(tài),根據實際情況啟動或者結束工作進程。
拓撲中的數據在噴嘴(spout)之間傳遞,噴嘴把從外部數據源獲取到的數據提供給拓撲,因此是Storm中流的來源。數據流中數據的格式稱為元組(tuple),具體來說為鍵值對(key-value pair),元組用來封裝需要處理的實際數據。
針對數據流的計算邏輯都是在螺栓(bolt)中執(zhí)行的,具體的處理過程中除了需要指定消息的生成、分發(fā)和連接,其余的都與傳統(tǒng)應用程序類似。
15 Trident
Trident是位于Storm已有的實時處理環(huán)境之上更高層的抽象構件,提供了狀態(tài)流處理和低延遲的分布式查詢功能,其屏蔽了計算事務處理和運行狀態(tài)管理的細節(jié)。此外,還針對數據庫增加了更新操作的原語。
在Trident中,數據流的處理按照批次進行,即所謂的事務。一般來說,對于不同的數據源,每個批次的數據量的規(guī)模可達數百萬個元組。一個處理批次稱為一個事務,當所有處理完成之后,認為該事務成功結束;當事務中的一個或者多個元組處理失敗時,整個事務需要回滾(rollback),然后重新提交。
Trident的事務控制包含三個層次:非事務控制(non-transactional)、嚴格的事務控制(transactional)和不透明的事務控制(opaque-transactional)。
- 對于非事務控制,單個批次內的元組處理可以出現部分處理成功的情況,處理失敗的元組可以在其他批次進行重試。
- 對于嚴格的事務控制,單個批次內處理失敗的元組只能在該批次內進行重試,如果失敗的元組一直無法成功處理,那么進程掛起,即不包含容錯機制。
- 對于不透明的事務控制,單個批次內處理失敗的元組可以在其他批次內重試一次,其容錯機制規(guī)定重試操作有且僅有一次。
上述針對消息的可靠性保障機制使得數據的處理有且僅有一次,保證了事務數據的持久性。容錯機制使得失敗的元組在重試環(huán)節(jié)的狀態(tài)更新是冪等的,冪等性是統(tǒng)計學中的一個重要性能指標,其保證了即使數據被多次處理,從處理結果的角度來看和處理一次是相同的。
Trident的出現顯著減少了編寫基于Storm的應用程序的代碼量,其本身具有函數、過濾器、連接、分組和聚合功能。在組件方面,它保留了Spout,將Bolt組件中實現的處理邏輯映射為一些新的具體操作,例如過濾、函數和分組統(tǒng)計等。
數據的狀態(tài)可以保存在拓撲內部存儲當中(例如內存),也可以保存在外部存儲當中(例如磁盤),Trident的應用程序接口支持這兩種機制。
16 S4
S4項目是由雅虎(Yahoo)提出的,作為一個分布式流處理計算引擎,其設計的初衷是與按點擊數付費的廣告結合,基于實時的計算來評估潛在用戶是否可能對廣告進行點擊。
這里S4是指簡單的(Simple)、可擴展的(Scalable)、流(Streaming)以及系統(tǒng)(System)。在S4項目提出之前,雅虎已經擁有了Hadoop,但Hadoop的基本理念是批處理,即利用MapReduce對已經過存儲的靜態(tài)數據進行處理。盡管MapReduce的處理速度非常快,但是從本質上說,其無法處理流數據。
S4項目將流數據看作事件,其具體的實現中包含五個重要構件:處理節(jié)點(processing element)、事件(event)、處理節(jié)點容器(Processing Element Container,PEC)、機器節(jié)點(node)和機器節(jié)點集群(cluster)。
一個集群中包含多個機器節(jié)點,一個機器節(jié)點中包含一個處理節(jié)點容器,一個處理節(jié)點容器中包含多個處理節(jié)點。處理節(jié)點對事件進行處理,處理結果作為新的事件,其能夠被其他處理節(jié)點處理。上述的點擊付費廣告的應用場景具有很高的實時性要求,而Hadoop無法很好地應對這樣的要求。
具體來說,MapReduce所處理的數據是保存在分布式文件系統(tǒng)上的,在執(zhí)行數據處理任務之前,MapReduce有一個數據準備的過程,需要處理的數據會按照分塊依次進行運算,不同的數據分塊大小可以對所謂的實時性進行調節(jié)。
當數據塊較小時,可以獲得一定的低延遲性,但是數據準備的過程就會變得很長;當數據塊較大時,數據處理的過程無法實現較低的延遲性。諸如S4的流計算系統(tǒng)所處理的數據是實時的流數據,即數據源源不斷地從外部數據源到達處理系統(tǒng)。
流計算處理系統(tǒng)的主要目標是在保證給定的準確度和精確性的前提下以最快的速度完成數據的處理。如果流數據不能夠被及時處理,那么其潛在的價值就會大打折扣,隨著處理時間的增長,流數據的潛在價值保持遞減。軟件開發(fā)者能夠根據不同的場景和需求在S4的上層開發(fā)處理流數據的應用程序。
17 Spark Streaming
作為Spark的組成部分,Spark Streaming主要針對流計算任務,其能夠與Spark的其他構件很好地進行協作。

一般來說,大數據的處理有兩類方式:批處理和流計算。
對于批處理,任務執(zhí)行的對象是預先保存好的數據,其任務頻率可以是每小時一次,每十小時一次,也可以是每二十四小時一次。批處理的典型工具有Spark和MapReduce。
對于流處理,任務執(zhí)行的對象是實時到達的、源源不斷的數據流。換言之,只要有數據到達,那么就一直保持處理。流處理的典型工具有Kafka和Storm。
作為Spark基礎應用程序接口的擴展,Spark Streaming能夠從眾多第三方應用程序獲得數據,例如Kafka、Flume和Kinesis等。在Spark Streaming中,數據的抽象表示是以離散化的形式組織的,即DStreams。DStreams可以用來表示連續(xù)的數據流。
在Spark Streaming的內部,DStreams是由若干連續(xù)的彈性數據集(Resilient Distributed Dataset,RDD)構成的,每個彈性數據集中包含的數據都是來源于確定時間間隔。Spark Streaming的數據處理模式是對確定時間間隔內的數據進行批處理。
由于部分中間結果需要在外存中進行存儲,因此傳統(tǒng)的批處理系統(tǒng)一般運行起來較為緩慢,但是這樣的處理模式可以具有很高的容錯性。
Spark Streaming的數據處理模式是基于彈性數據集進行的,通常將絕大部分中間結果保存在內存中,可以根據彈性數據集之間的互相依賴關系進行高速運算。這樣的處理模式也被稱為微批次處理架構,具體的特點是數據處理的粒度較為粗糙,針對每個選定的彈性數據集進行處理,對于批次內包含的數據無法實現進一步的細分。
18 Lambdoop
2013年,項目負責人Rubén Casado在巴塞羅那的NoSQL Matters大會上發(fā)布了Lambdoop框架。Lambdoop是一個結合了實時處理和批處理的大數據應用程序開發(fā)框架,其基于Java語言。

Lambdoop中可供選擇的處理范式(processing paradigm)有三種:非實時批處理、實時流處理和混合計算模型。
Lambdoop實現了一個基于Lambda的體系結構,該結構為軟件開發(fā)者提供了一個抽象層(abstraction layer),使用與Lambda架構類似的方式來開發(fā)大數據相關的應用程序。
對于使用Lambdoop應用程序開發(fā)框架的用戶,軟件開發(fā)者在應用程序的開發(fā)過程中不需要處理不同技術、參數配置和數據格式等煩瑣的細節(jié)問題,只需要使用必需的應用程序接口。
此外,Lambdoop還提供了輔助的軟件工具,例如輸入/輸出驅動、數據可視化接口、聚類管理工具以及大量人工智能算法的具體實現。大多數已有的大數據處理技術關注于海量靜態(tài)數據的管理,例如前述的Hadoop、Hive和Pig等。此外,學界和業(yè)界也對動態(tài)數據的實時處理較為關注,典型的應用軟件有前述的Storm和S4。
由于針對海量靜態(tài)數據的批處理能夠考慮到更多相關信息,因此相應的處理結果具有更高的可靠性和健壯性,例如訓練出更加精確的預測模型。遺憾的是,絕大多數批處理過程耗時較長,在對響應時間要求較高的應用領域,批處理是不可行的。
從理論上來說,實時處理能夠解決上述問題,但實時處理有一個重大的缺陷:由于需要保證較小的延遲,實時處理所分析的數據量是十分有限的。在實際的生產環(huán)境中,通常需要實時處理和批處理兩種方式各自具有的優(yōu)點,這對軟件開發(fā)者來說是一個挑戰(zhàn)性的難題,同時這也是Lambdoop的設計初衷。
19 SummingBird
SummingBird是由推特于2013年開源的數據分析工具,大數據時代的數據處理分為批處理和實時處理兩大領域,這兩種方式各有利弊,僅采用一種處理方式無法滿足各類應用日益多樣化的需求。
作為能夠處理大規(guī)模數據的應用軟件,SummingBird的設計初衷是將上述兩種處理方式結合起來,最大限度地獲得批處理技術提供的容錯性和實時處理技術提供的實時性,其支持批處理模式(基于Hadoop/MapReduce)、流處理模式(基于Storm)以及混合模式。SummingBird最大的特點是無縫融合了批處理和流處理。
推特通過SummingBird整合批處理和流處理來降低在處理模式之間轉換帶來的開銷,提供近乎原生Scala和Java的方式來執(zhí)行MapReduce任務。
SummingBird作業(yè)流程包含兩種形式的數據:流(stream)和快照(snapshot),前者記錄了數據處理的全部歷史,后者為作業(yè)系統(tǒng)在單個時間戳上的快照。
簡單地說,SummingBird可以認為是Hadoop和Storm的結合,具體包含以下構件:
- Producer,即數據的抽象,傳遞給指定的平臺做MapReduce流編譯;
- Platform,即平臺的實例,由MapReduce庫實現,SummingBird提供了平臺對Storm和相關內存處理的支持;
- Source,即數據源;
- Store,即包含所有鍵值對的快照;
- Sink,即能夠生成包含Producer具體數值的非聚合流,Sink是流,不是快照;
- Service,即供用戶在Producer流中的當前數值上執(zhí)行查找合并(lookup join)和左端合并(left join)的操作,合并的連接值可以為其他Store的快照、其他Sink的流和其他異步功能提供的快照或者流;
Plan,由Platform生成,是MapReduce流的最終實現。對于Storm來說Plan是StormTopology的實例,對于Memory來說Plan是內存中的stream。
關于作者:高聰,男,1985年11月生,西安電子科技大學計算機科學與技術專業(yè)學士,計算機系統(tǒng)結構專業(yè)碩士、博士。自2015年12月至今,在西安郵電大學計算機學院任教,主要研究方向:數據感知與融合、邊緣計算和無線傳感器網絡。