動手實現一個Localcache-設計篇
本文轉載自微信公眾號「Golang夢工廠」,作者AsongGo 。轉載本文請聯系Golang夢工廠公眾號。
前言
哈嘍,大家好,我是asong。最近想動手寫一個localcache練練手,工作這么久了,也看過很多同事實現的本地緩存,都各有所長,自己平時也在思考如何實現一個高性能的本地緩存,接下來我將基于自己的理解實現一版本地緩存,歡迎各位大佬們提出寶貴意見,我會根據意見不斷完善的。
本篇主要介紹設計一個本地緩存都要考慮什么點,后續為實現文章,歡迎關注這個系列。
為什么要有本地緩存
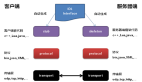
隨著互聯網的普及,用戶數和訪問量越來越大,這就需要我們的應用支撐更多的并發量,比如某寶的首頁流量,大量的用戶同時進入首頁,對我們的應用服務器和數據庫服務器造成的計算也是巨大的,本身數據庫訪問就占用數據庫連接,導致網絡開銷巨大,在面對如此高的并發量下,數據庫就會面臨瓶頸,這時就要考慮加緩存,緩存就分為分布式緩存和本地緩存,大多數場景我們使用分布式緩存就可以滿足要求,分布式緩存訪問速度也很快,但是數據需要跨網絡傳輸,在面對首頁這種高并發量級下,對性能要求是很高的,不能放過一點點的性能優化空間,這時我們就可以選擇使用本地緩存來提高性能,本地緩存不需要跨網絡傳輸,應用和cache都在同一個進程內部,快速請求,適用于首頁這種數據更新頻率較低的業務場景。
綜上所述,我們往往使用本地緩存后的系統架構是這樣的:
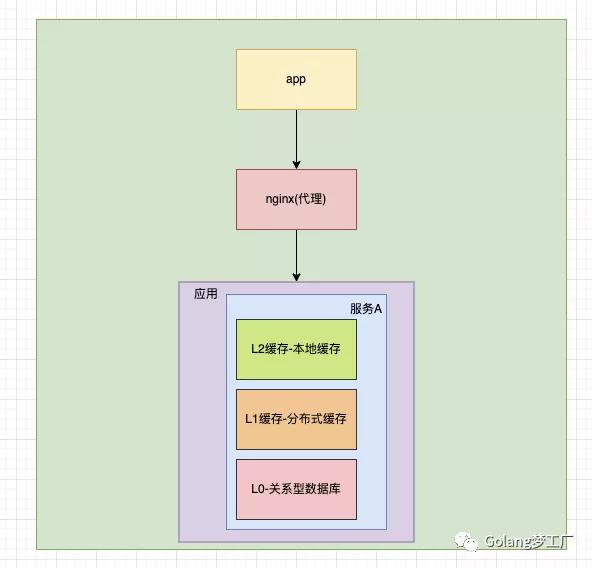
本地緩存雖然帶來性能優化,不過也是有一些弊端的,緩存與應用程序耦合,多個應用程序無法直接的共享緩存,各應用或集群的各節點都需要維護自己的單獨緩存,對內存是一種浪費,使用緩存的是我們程序員自己,我們要根據根據數據類型、業務場景來準確判斷使用何種類型的緩存,如何使用這種緩存,以最小的成本最快的效率達到最優的目的。
思考:如何實現一個高性能本地緩存
數據結構
第一步我們就要考慮數據該怎樣存儲;數據的查找效率要高,首先我們就想到了哈希表,哈希表的查找效率高,時間復雜度為O(1),可以滿足我們的需求;確定是使用什么結構來存儲,接下來我們要考慮以什么類型進行存儲,因為不同的業務場景使用的數據類型不同,為了通用,在java中我們可以使用泛型,Go語言中暫時沒有泛型,我們可以使用interface類型來代替,把解析數據交給程序員自己來進行斷言,增強了可擴展性,同時也增加一些風險。
總結:
- 數據結構:哈希表;
- key:string類型;
- value:interface類型;
并發安全
本地緩存的應用肯定會面對并發讀寫的場景,這是就要考慮并發安全的問題。因為我們選擇的是哈希結構,Go語言中主要提供了兩種哈希,一種是非線程安全的map,一種是線程安全的sync.map,為了方便我們可以直接選擇sync.map,也可以考慮使用map+sync.RWMutex組合方式自己實現保證線程安全,網上有人對這兩種方式進行比較,在讀操作遠多于寫操作的時候,使用sync.map的性能是遠高于map+sync.RWMutex的組合的。在本地緩存中讀操作是遠高于寫操作的,但是我們本地緩存不僅支持進行數據存儲的時候要使用鎖,進行過期清除等操作時也需要加鎖,所以使用map+sync.RWMutex的方式更靈活,所以這里我們選擇這種方式保證并發安全。
高性能并發訪問
加鎖可以保證數據的讀寫安全性,但是會增加鎖競爭,本地緩存本來就是為了提升性能而設計出來,不能讓其成為性能瓶頸,所以我們要對鎖競爭進行優化。針對本地緩存的應用場景,我們可以根據key進行分桶處理,減少鎖競爭。
我們的key都是string類型,所以我們可以使用djb2哈希算法把key打散進行分桶,然后在對每一個桶進行加鎖,也就是鎖細化,減少競爭。
對象上限
因為本地緩存是在內存中存儲的,內存都是有限制的,我們不可能無限存儲,所以我們可以指定緩存對象的數量,根據我們具體的應用場景去預估這個上限值,默認我們選擇緩存的數量為1024。
淘汰策略
因為我們會設置緩存對象的數量,當觸發上限值時,可以使用淘汰策略淘汰掉,常見的緩存淘汰算法有:
LFU
LFU(Least Frequently Used)即最近不常用算法,根據數據的歷史訪問頻率來淘汰數據,這種算法核心思想認為最近使用頻率低的數據,很大概率不會再使用,把使用頻率最小的數據置換出去。
存在的問題:
某些數據在短時間內被高頻訪問,在之后的很長一段時間不再被訪問,因為之前的訪問頻率急劇增加,那么在之后不會在短時間內被淘汰,占據著隊列前頭的位置,會導致更頻繁使用的塊更容易被清除掉,剛進入的緩存新數據也可能會很快的被刪除。
LRU
LRU(Least Recently User)即最近最少使用算法,根據數據的歷史訪問記錄來淘汰數據,這種算法核心思想認為最近使用的數據很大概率會再次使用,最近一段時間沒有使用的數據,很大概率不會再次使用,把最長時間未被訪問的數據置換出去
存在問題:
當某個客戶端訪問了大量的歷史數據時,可能會使緩存中的數據被歷史數據替換,降低緩存命中率。
FIFO
FIFO(First in First out)即先進先出算法,這種算法的核心思想是最近剛訪問的,將來訪問的可能性比較大,先進入緩存的數據最先被淘汰掉。
存在的問題:
這種算法采用絕對公平的方式進行數據置換,很容易發生缺頁中斷問題。
Two Queues
Two Queues是FIFO + LRU的結合,其核心思想是當數據第一次訪問時,將數據緩存在FIFO隊列中,當數據第二次被訪問時將數據從FIFO隊列移到LRU隊列里面,這兩個隊列按照自己的方法淘汰數據。
存在問題:
這種算法和LRU-2一致,適應性差,存在LRU中的數據需要大量的訪問才會將歷史記錄清除掉。
ARU
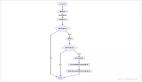
ARU(Adaptive Replacement Cache)即自適應緩存替換算法,是LFU和LRU算法的結合使用,其核心思想是根據被淘汰數據的訪問情況,而增加對應 LRU 還是 LFU鏈表的大小,ARU主要包含了四個鏈表,LRU 和 LRU Ghost ,LFU 和LFU Ghost, Ghost 鏈表為對應淘汰的數據記錄鏈表,不記錄數據,只記錄 ID 等信息。

截屏2021-12-04 下午6.52.05
當數據被訪問時加入LRU隊列,如果該數據再次被訪問,則同時被放到 LFU 鏈表中;如果該數據在LRU隊列中淘汰了,那么該數據進入LRU Ghost隊列,如果之后該數據在之后被再次訪問了,就增加LRU隊列的大小,同時縮減LFU隊列的大小。
存在問題:
因為要維護四個隊列,會占用更多的內存空間。
選擇
每一種算法都有自己特色,結合我們本地緩存使用的場景,選擇ARU算法來做緩存緩存淘汰策略是一個不錯的選擇,可以動態調整 LRU 和 LFU 的大小,以適應當前最佳的緩存命中。
過期清除
除了使用緩存淘汰策略清除數據外,還可以添加一個過期時間做雙重保證,避免不經常訪問的數據一直占用內存。可以有兩種做法:
數據過期了直接刪除
數據過期了不刪除,異步更新數據
兩種做法各有利弊,異步更新數據需要具體業務場景選擇,為了迎合大多數業務,我們采用數據過期了直接刪除這種方法更友好,這里我們采用懶加載的方式,在獲取數據的時候判斷數據是否過期,同時設置一個定時任務,每天定時刪除過期的數據。
緩存監控
很多人對于緩存的監控也比較忽略,基本寫完后不報錯就默認他已經生效了,這就無法感知這個緩存是否起作用了,所以對于緩存各種指標的監控,也比較重要,通過其不同的指標數據,我們可以對緩存的參數進行優化,從而讓緩存達到最優化。如果是企業應用,我們可以使用Prometheus進行監控上報,我們自測可以簡單寫一個小組件,定時打印緩存數、緩存命中率等指標。
GC調優
對于大量使用本地緩存的應用,由于涉及到緩存淘汰,那么GC問題必定是常事。如果出現GC較多,STW時間較長,那么必定會影響服務可用性;對于這個事項一般是具體case具體分析,本地緩存上線后記得經常查看GC監控。
緩存穿透
使用緩存就要考慮緩存穿透的問題,不過這個一般不在本地緩存中實現,基本交給使用者來實現,當在緩存中找不到元素時,它設置對緩存鍵的鎖定;這樣其他線程將等待此元素被填充,而不是命中數據庫(外部使用singleflight封裝一下)。
參考文章
https://zhuanlan.zhihu.com/p/352910565
https://cloud.tencent.com/developer/article/1676115
https://tech.meituan.com/2017/03/17/cache-about.html
https://www.cnblogs.com/vancasola/p/9951686.html
總結
真正想設計一個高性能的本地緩存還是挺不容易的,由于我也才疏學淺,本文的設計思想也是個人實踐想法,歡迎大家提出寶貴意見,我們一起做出來一個真正的高性能本地緩存。
下篇文章我將分享自己的寫的一個本地緩存,盡請期待!!!【編輯推薦】