如何設計一個 A/B test?
實驗設計
AB Test 實驗一般有 2 個目的:
- 判斷哪個更好:例如,有 2 個 UI 設計,究竟是 A 更好一些,還是 B 更好一些,我們需要實驗判定
- 計算收益:例如,最近新上線了一個直播功能,那么直播功能究竟給平臺帶了來多少額外的 DAU,多少額外的使用時長,多少直播以外的視頻觀看時長等
我們一般比較熟知的是上述第 1 個目的,對于第 2 個目的,對于收益的量化,計算 ROI,往往對數據分析師和管理者非常重要。
對于一般的 ABTest 實驗,其實本質上就是把平臺的流量均勻分為幾個組,每個組添加不同的策略,然后根據這幾個組的用戶數據指標,例如:留存、人均觀看時長、基礎互動率等等核心指標,最終選擇一個最好的組上線。
實驗的幾個基本步驟一般如下:
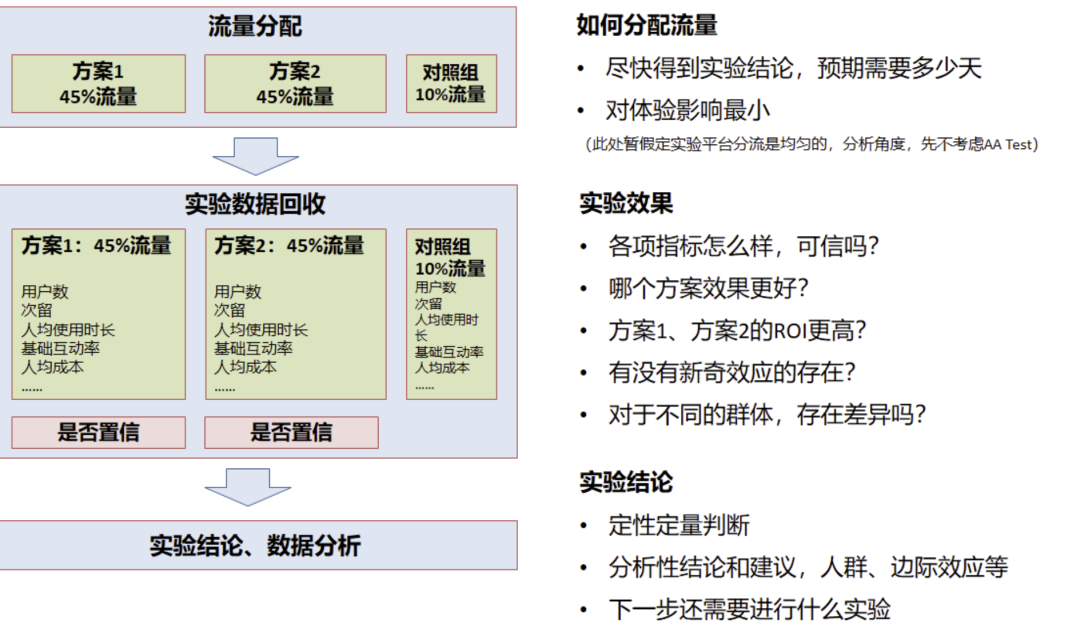
流量分配
實驗設計時有兩個目標:
- 希望盡快得到實驗結論,盡快決策
- 希望收益最大化,用戶體驗影響最小
因此經常需要在流量分配時有所權衡,一般有以下幾個情況:
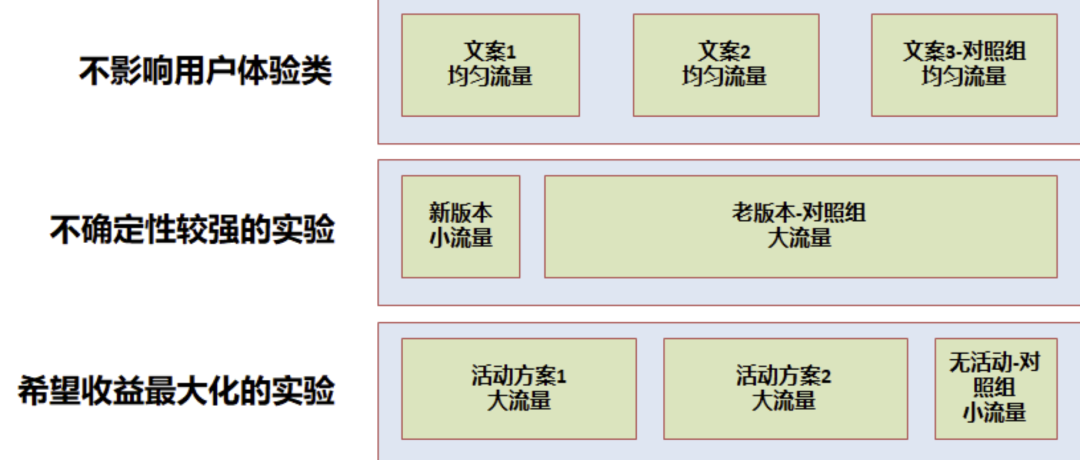
- 不影響用戶體驗:如 UI 實驗、文案類實驗等,一般可以均勻分配流量實驗,可以快速得到實驗結論
- 不確定性較強的實驗:如產品新功能上線,一般需小流量實驗,盡量減小用戶體驗影響,在允許的時間內得到結論
- 希望收益最大化的實驗:如運營活動等,盡可能將效果最大化,一般需要大流量實驗,留出小部分對照組用于評估 ROI
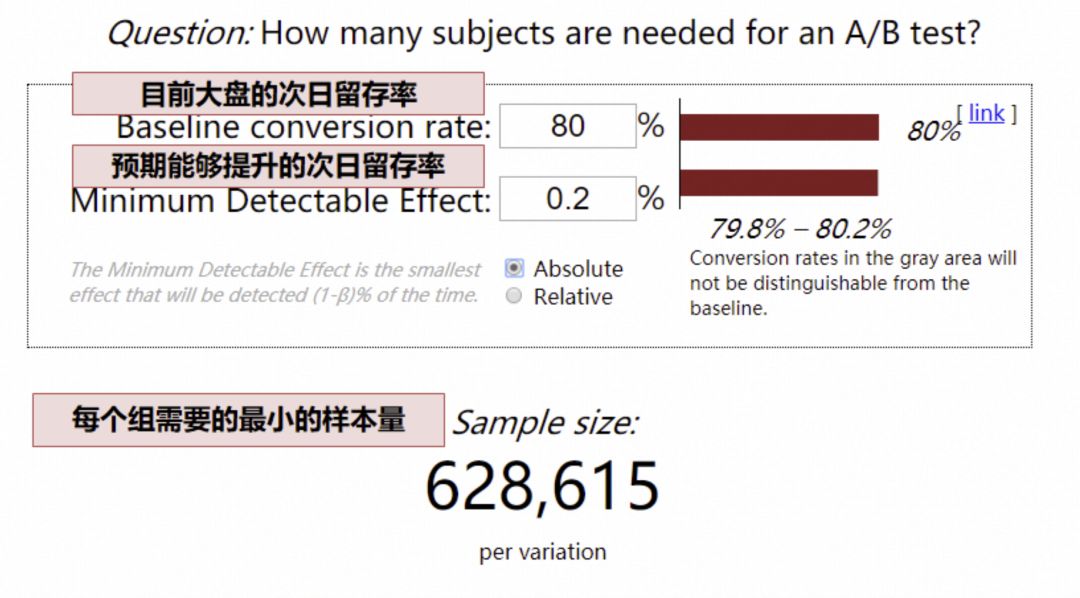
根據實驗的預期結果,大盤用戶量,確定實驗所需最小流量,可以通過一個網站專門計算所需樣本量:
- 以次日留存率為例,目前大盤次日留存率 80%,預期實驗能夠提升 0.2pp
(這里的留存率可以轉換為點擊率、滲透率等等,只要是比例值就可以,如果估不準,為了保證實驗能夠得到結果,此處可低估,不可高估,也就是 0.2pp 是預期能夠提升地最小值)
- 網站計算,最少樣本量就是 63W
(這里的最少樣本量,指的是最少流量實驗組的樣本量)
- 如果我們每天只有 5W 的用戶可用于實驗(5W 的用戶,指最少流量實驗組是 5W 用戶),63/ 5 = 13 天,我們需要至少 13 天才能夠得到實驗結論
如果我們預期提升的指標是人均時長、人均 VV 等,可能就比較復雜了,我們需要運用 t 檢驗反算,需要的樣本量:
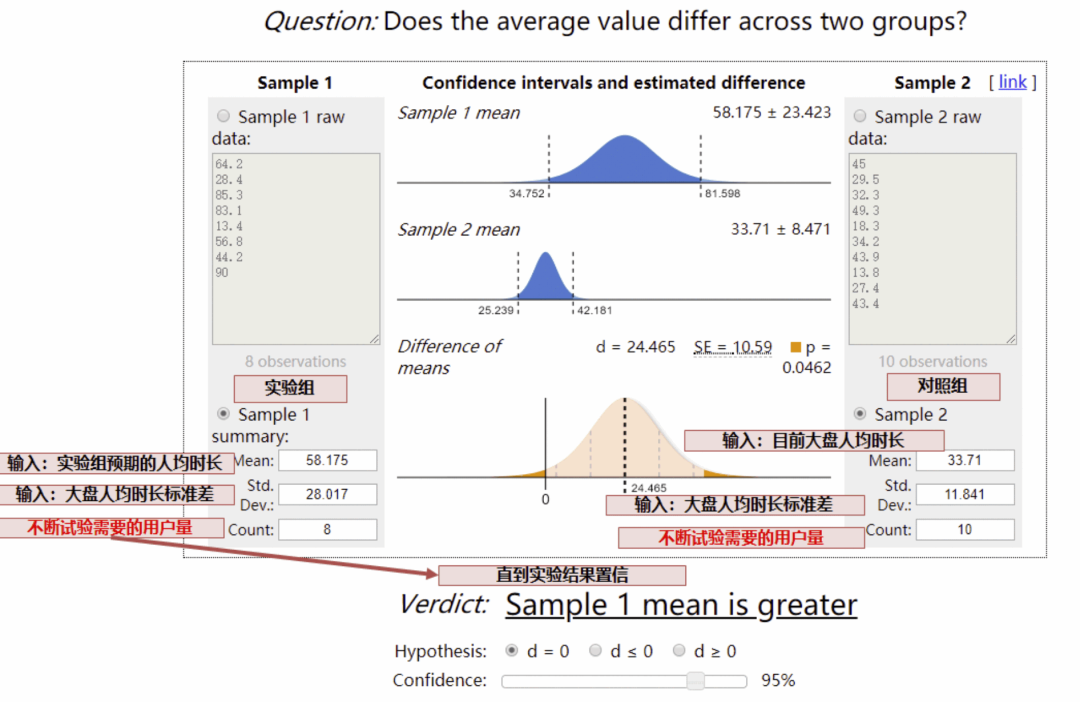
實驗效果
我們以一個稍復雜點的運營活動實驗為例,活動有方案 1、方案 2,同時為了量化 ROI,對照組沒有運營活動。

需要回答幾個問題
- 方案 1 和方案 2,哪個效果更好?
- 哪個 ROI 更高?
- 長期來看哪個更好?
- 不同群體有差異嗎?
第 1 個問題,方案 1 和方案 2,哪個效果更好?
還是要運用假設檢驗,對于留存率、滲透率等漏斗類指標,采用卡方檢驗:
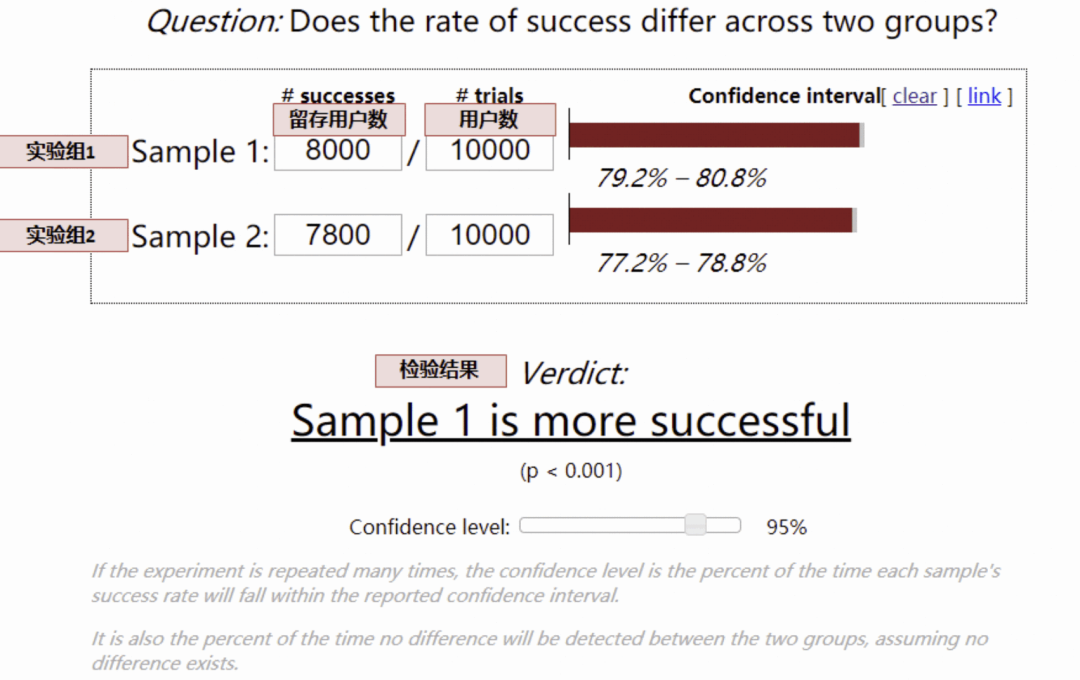
對于人均時長類等均值類指標,采用t 檢驗:
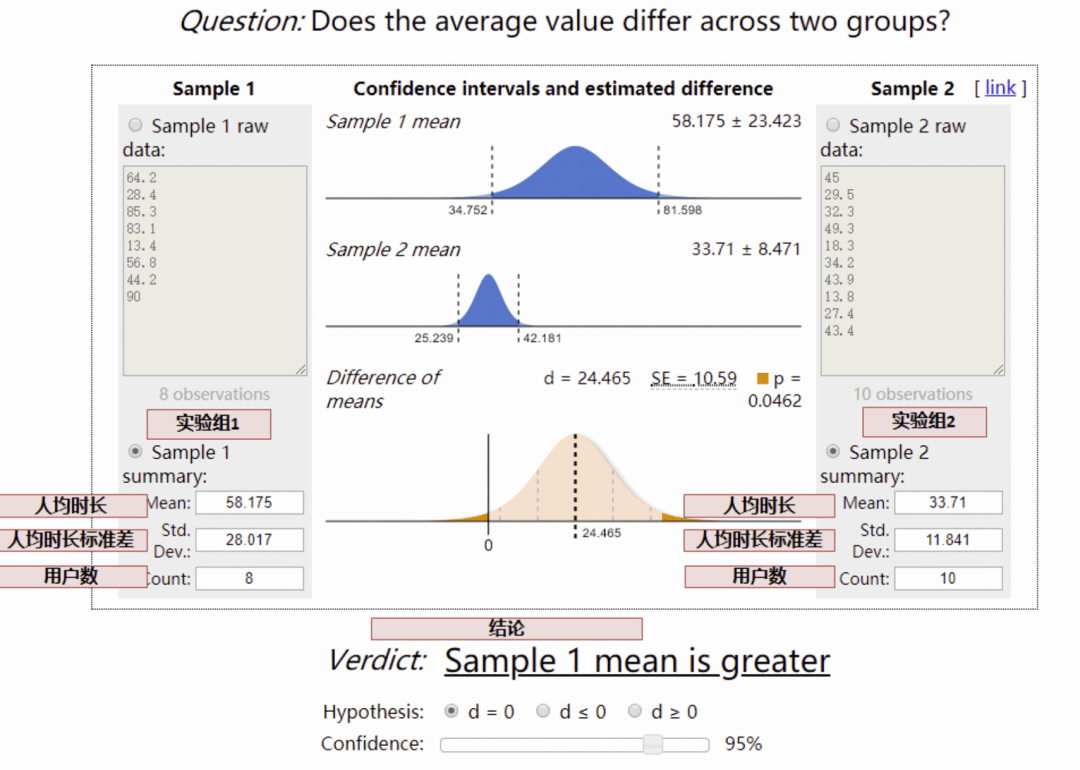
通過上假設檢驗,如果結論置信,我們就能夠得到方案 1 和方案 2 在哪像指標更好(有顯著性差異), 對于不置信的結論,盡管方案 1 和方案 2 的指標可能略有差異,但可能是數據正常波動產生。
第 2 個問題,哪個 ROI 更高?
一般有活動相比無活動,留存、人均時長等各項指標均會顯著,我們不再重復上述的假設檢驗過程。
對于 ROI 的計算,成本方面,每個實驗組成本可以直接計算,對于收益方面,就要和對照組相比較,假定以總日活躍天(即 DAU 按日累計求和)作為收益指標,需要假設不做運營活動,DAU 會是多少,可以通過對照組計算,即:
- 實驗組假設不做活動日活躍天 = 對照組日活躍天 * (實驗組流量 / 對照組流量)
- 實驗組收益 = 實驗組日活躍天 - 實驗組假設不做活動日活躍天
這樣就可以量化出每個方案的 ROI。
第 3 個問題,長期來看哪個更好?
這里就要考慮新奇效應的問題了,一般在實驗上線前期,用戶因為新鮮感,效果可能都不錯,因此在做評估的時候,需要觀測指標到穩定態后,再做評估。
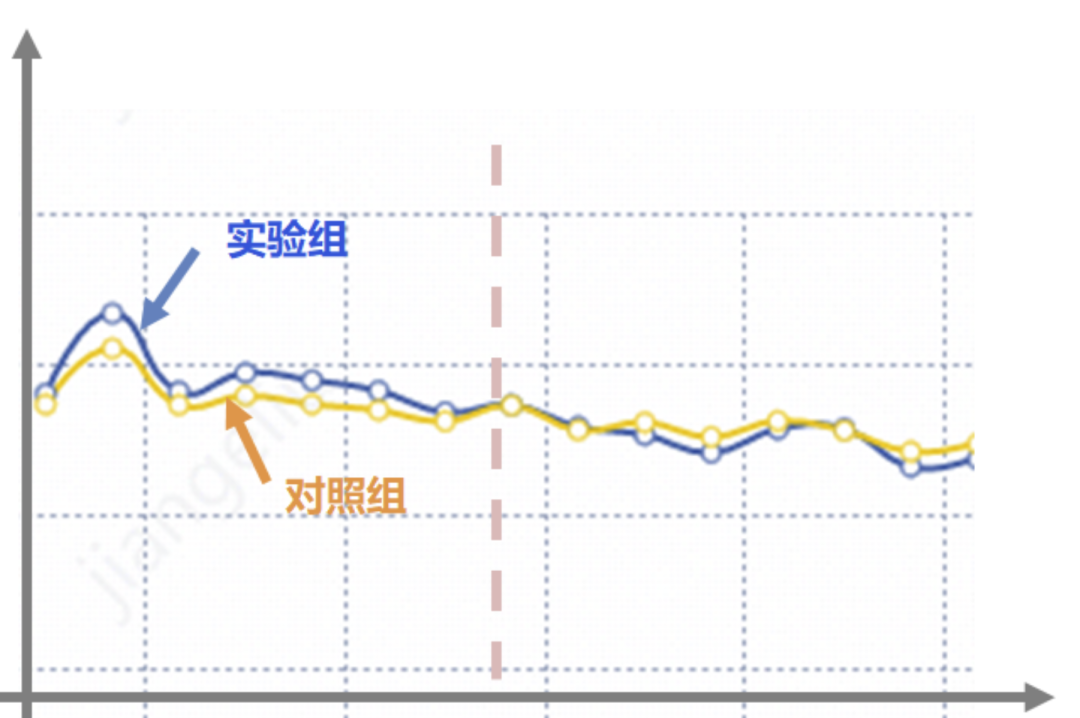
例如有的時候出現,剛剛上線前期,實驗組效果更好,但是經過以端時間,用戶的新鮮感過去了,實驗組的效果可能更差,因此,從長遠收益來看,我們應該選擇對照組,是實驗組的新奇效應欺騙了我們,在做實驗分析時,應剔除新奇效應的部分,待平穩后,再做評估
第 4 個問題,不同用戶群體有差異嗎?
很多情況下,對新用戶可能實驗組更好,老用戶對照組更好;對年輕人實驗組更好,中年人對照組更好,
作為數據分析師,分析實驗結論時,還要關注用戶群體的差異。
實驗結束
實驗結束后需要:
- 反饋實驗結論,包括直接效果(滲透、留存、人均時長等)、ROI
- 充分利用實驗數據,進一步探索分析不同用戶群體,不同場景下的差異,提出探索性分析
- 對于發現的現象,進一步提出假設,進一步實驗論證
更高級的實驗
對于長線業務,可能同時有數十個實驗同時進行,不但對比每項小迭代的差異,同時對比專項對大盤的貢獻量、部門整體對大盤的貢獻量,這樣就需要運用到了實驗的層域管理模型。
- 對比每個產品細節迭代的結果
- 對比每個專項在一個階段的貢獻
- 對比整個項目在一個階段的貢獻
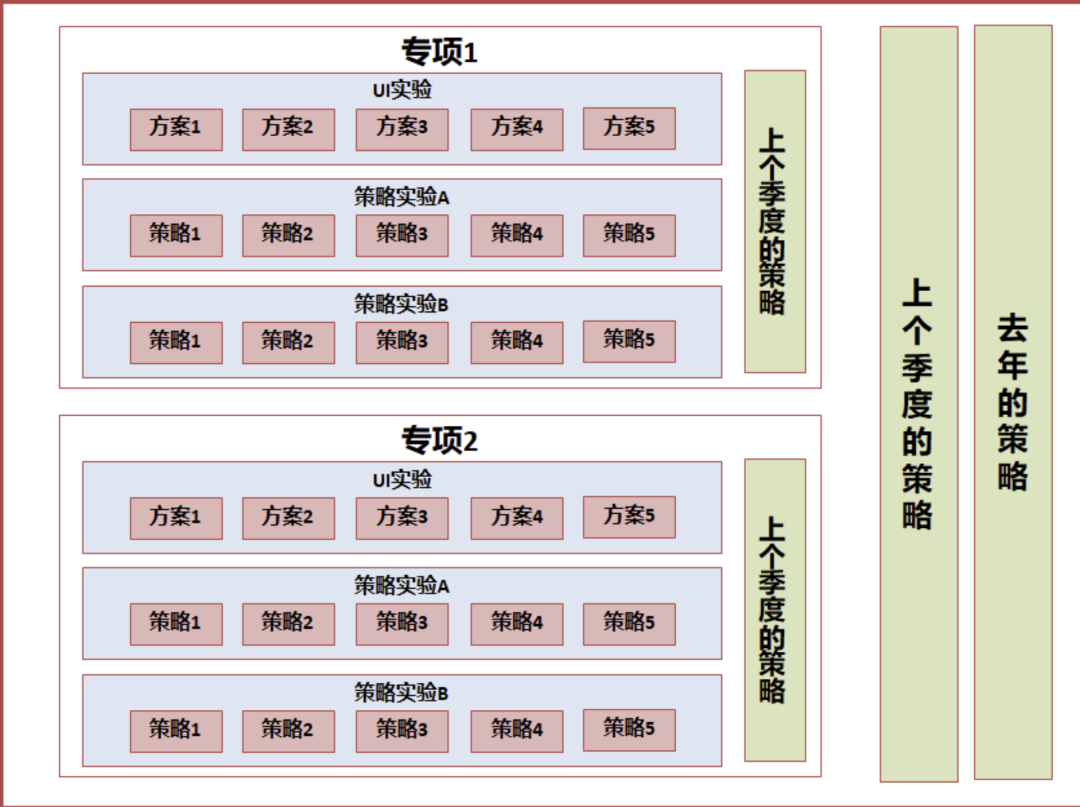
多個活動交集量化的實驗設計
作為數據分析師,多團隊合作中,經常遇到多業務交集的問題,以我近期主要負責的春節活動為例,老板會問:
- 春節活動-明星紅包子活動貢獻了多少 DAU?春節活動-家鄉卡子活動貢獻了多少 DAU?
- 春節活動總共貢獻了多少 DAU?
嚴謹一點,我們采用了 AB 實驗的方式核算,最終可能會發現一個問題:春節活動各個子活動的貢獻之和,不等于春節活動的貢獻,為什么呢?
- 有的時候,活動 A 和活動 B,有著相互放大的作用,這個時候就會 1+1 > 2
- 還有的時候,活動 A 和活動 B,本質上是在做相同的事情,這個時候就會 1+1 < 2
這個時候,我們準確量化春節活動的貢獻,就需要一個【貫穿】所有活動的對照組,在 AB 實驗系統中通俗稱作貫穿層。

(說明:實驗中,各層的流量是正交的,簡單理解,例如,A 層的分流采用用戶 ID 的倒數第 1 位,B 層的分流采用用戶 ID 的倒數第 2 位,在用戶 ID 隨機的情況下,倒數第 1 位和倒數第 2 位是沒有關系的,也稱作相互獨立,我們稱作正交。當然,AB Test 實驗系統真實的分流邏輯,是采用了復雜的 hash 函數、正交表,能夠保證正交性。)
這樣分層后,我們可以按照如下的方式量化貢獻:
- 計算春節活動的整體貢獻:實驗填充層-填充層填充組 VS 貫穿層-貫穿層填充組
- 計算活動 A 的貢獻:活動 A 實驗層中,實驗組 VS 對照組
- 計算活動 B 的貢獻:活動 B 實驗層中,實驗組 VS 對照組
業務迭代的同時,如何與自身的過去比較
上面談到了【貫穿層】的設計,貫穿層的設計其實不但可以應用在多個活動的場景,有些場景,我們的業務需要和去年或上個季度的自身對比,同時業務還不斷在多個方面運用 AB Test 迭代。
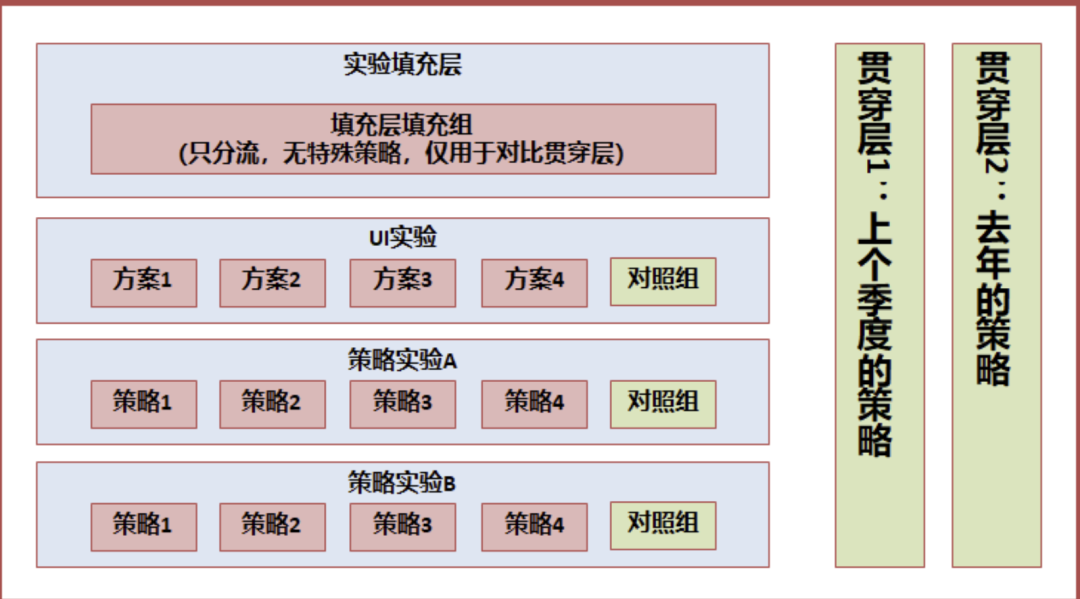
類似與上面這種層次設計,在推薦系統中較為常見,在某一些產品或系統中,貫穿層不能夠完全沒有策略,那么采用去年或上個季度的策略,代表著基準值,從而量化新一個周期的增量貢獻
我們可以量化:
- 每個小迭代對整個系統的貢獻:實驗層中的實驗組 VS 對照組
- 周期內,系統全部迭代與上個周期的比較:實驗填充層 VS 貫穿層 1(或貫穿層 2)
- 同時,可以量化去年策略的自然增長或下降,以衡量舊有系統是否具有長期的適用性(作為系統設計者,更應鼓勵設計具有長期適應性的系統):貫穿層 1(上個季度的策略)VS 貫穿層 2(去年的策略)
更為復雜的實驗設計
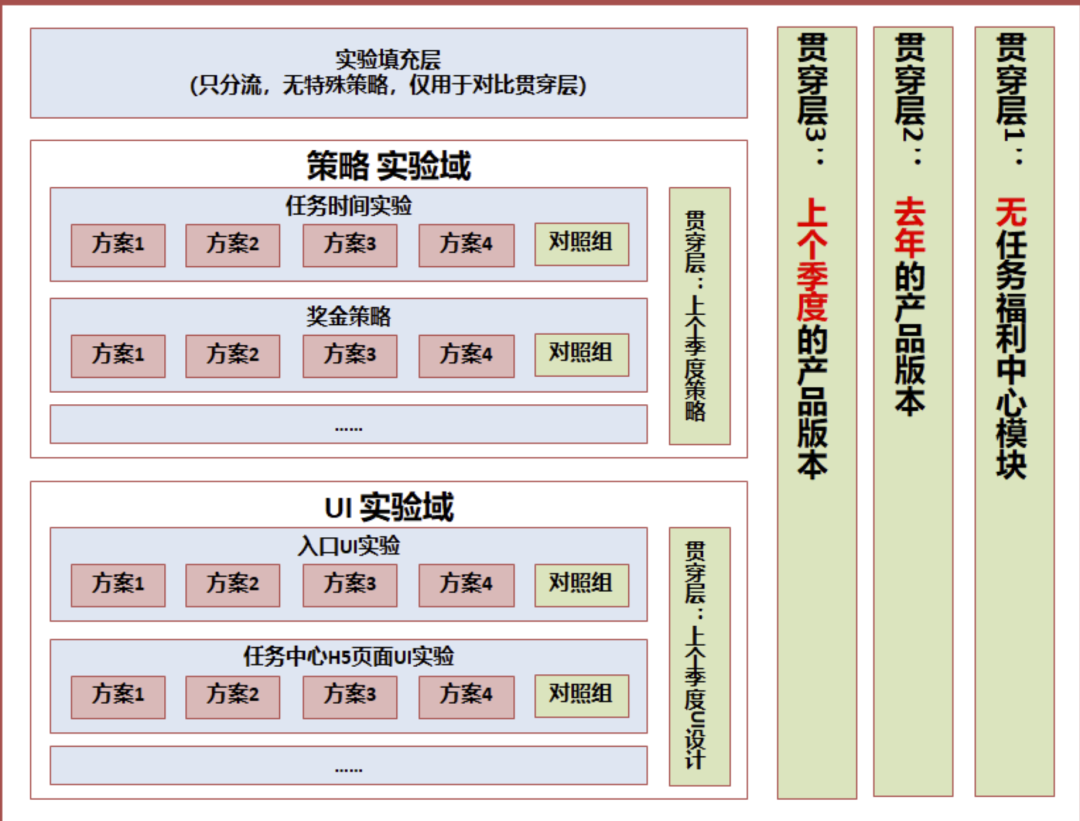
我以我目前負責的業務,微視任務福利中心的實驗設計為例,舉例一個更復雜的實驗系統設計,綜合了上面提到的 2 個目的:
- 量化每一個實驗迭代為系統帶來的增量貢獻
- 量化每一類迭代(如 UI 迭代、策略迭代),在一個階段的增量貢獻
- 量化系統整體在上一個周期(季度、年)的增量貢獻
- 量化任務福利中心的整體 ROI(本質上,是給用戶一些激勵,促進用戶活躍,獲得更多商業化收益,所以和推薦系統不同的是,需要有完全沒有任務福利中心的對照組,用戶量化 ROI)