【51CTO.com快譯】如今,企業(yè)比以往任何時候都更加依賴數(shù)據(jù)。根據(jù)Gartner的最新數(shù)據(jù)質(zhì)量市場調(diào)查,那些糟糕的數(shù)據(jù)質(zhì)量,每年平均會給企業(yè)造成1500萬美元的巨大損失。而且錯誤的數(shù)據(jù)往往會讓企業(yè)失去商機、損毀市場聲譽、拉低客戶信心、甚至造成重大的財務(wù)損失。毋庸置疑,只有準確、一致、完整且可靠的數(shù)據(jù),才能真正為業(yè)務(wù)提供實際、有利的價值。為此,許多企業(yè)往往會使用數(shù)據(jù)質(zhì)量的相關(guān)工具。在本文中,我們將和您討論如下五種數(shù)據(jù)質(zhì)量類工具:
- Great Expectations
- Spectacles
- Datafold
- dbt(數(shù)據(jù)構(gòu)建工具)
- Evidently
在深入探討工具之前,讓我們首先了解一下保障數(shù)據(jù)質(zhì)量的相關(guān)概念。
數(shù)據(jù)問題從何而來?
從廣義上講,內(nèi)、外部因素都會導(dǎo)致數(shù)據(jù)出現(xiàn)質(zhì)量問題。其中,外部因素是指企業(yè)從諸如Meta、Google Analytics或AWS Data Exchange等,無法控制的第三方獲取數(shù)據(jù)。例如,不同公司的IT系統(tǒng)可能在合并或收購之后,需要進行數(shù)據(jù)整合。但是,由于未能審核這些來自第三方的數(shù)據(jù)質(zhì)量,或是因為應(yīng)用程序中的輸入驗證不當,則可能導(dǎo)致數(shù)據(jù)質(zhì)量出現(xiàn)問題。
而內(nèi)部原因則源于企業(yè)生態(tài)系統(tǒng)的內(nèi)部。例如,我們常聽說的企業(yè)數(shù)據(jù)孤島,就是一些鮮為人知的數(shù)據(jù)源。它們僅由組織內(nèi)的某些團隊或部門所使用。此外,缺乏適當?shù)臄?shù)據(jù)所有權(quán)管理,使用錯誤的數(shù)據(jù)類型和模型,甚至是軟件工程師在應(yīng)用程序的任何層更改字段、或引入破壞數(shù)據(jù)的代碼更新,都可能導(dǎo)致數(shù)據(jù)質(zhì)量的不佳和不一致。
衡量數(shù)據(jù)質(zhì)量
數(shù)據(jù)在企業(yè)中的質(zhì)量與價值,很大程度上取決于該企業(yè)如何定義它們,以及如何確定它們的優(yōu)先級。通常,我們有七個實用的質(zhì)量衡量指標。
- 相關(guān)性:數(shù)據(jù)與業(yè)務(wù)的相關(guān)程度。
- 準確性:數(shù)據(jù)的精準程度。
- 完整性:數(shù)據(jù)是否完整,是否處于穩(wěn)定狀態(tài)。
- 一致性:數(shù)據(jù)在整個組織中的是否能保持一致。如果使用同一個應(yīng)用程序,去轉(zhuǎn)換多個來源的同一條數(shù)據(jù),其輸出應(yīng)當始終相同。
- 合規(guī)性:數(shù)據(jù)是否符合業(yè)務(wù)規(guī)則所期望的標準和格式。
- 唯一性:相同數(shù)據(jù)的多個副本是否在企業(yè)中都可用,而且它是否來自唯一的真實數(shù)據(jù)源。
- 及時性:數(shù)據(jù)對于當前業(yè)務(wù)需求的及時性。
確保數(shù)據(jù)質(zhì)量
如前所述,企業(yè)通常使用一些自動化工具,來檢查數(shù)據(jù)的質(zhì)量。這些工具既可以是定制開發(fā)的,也可以是由供應(yīng)商直接提供的。這兩種選擇各有利弊。
如果擁有充沛的IT資源,并且明確地定義了數(shù)據(jù)質(zhì)量的要求,那么企業(yè)可以考慮采用定制化的開發(fā)方案,通過推出適合自己的工具,去減少持續(xù)的成本支出。當然,構(gòu)建自定義方案也可能比較耗時,而且容易超過最初的預(yù)算。
而如果公司需要快速、可靠的方案,且不想自行維護的話,那么購買現(xiàn)成的方案則是最好的選擇。說到這里,下面讓我們來討論五種典型的數(shù)據(jù)質(zhì)量工具。當然,市場上還有許多其他相似的工具。您可以選擇混合搭配的方式,來滿足自己的預(yù)算和真實使用場景。
1.Great Expectations
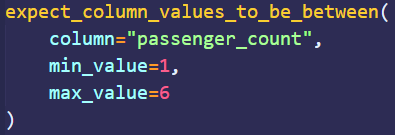
作為一個開源庫,Great Expectations可用于驗證、記錄和分析數(shù)據(jù)。用戶以期望(expectations)的形式定義斷言(assertions)。顧名思義,期望是您期望從數(shù)據(jù)中獲得的質(zhì)量;斷言則是用聲明性語言編寫的。例如,下圖的斷言示例定義了passenger_count列的值必須介于1和6之間。
Great Expectations的另一個功能是自動化數(shù)據(jù)分析。它可以根據(jù)統(tǒng)計數(shù)據(jù),自動從數(shù)據(jù)中生成期望。由于數(shù)據(jù)質(zhì)量工程師不必從頭開始編寫斷言,因此大幅節(jié)省了開發(fā)的時間。
一旦各種預(yù)期準備就緒,它們就可以被合并到數(shù)據(jù)管道中。例如,在Apache Airflow中,數(shù)據(jù)驗證步驟可以被定義為一個使用BashOperator的checkpoint script。它會在數(shù)據(jù)流經(jīng)管道時,觸發(fā)相應(yīng)的質(zhì)量檢查。目前,Great Expectations兼容大部分數(shù)據(jù)源,其中包括CSV文件、SQL數(shù)據(jù)庫、Spark DataFrames和Pandas等。
2.Spectacles
Spectacles是一種持續(xù)集成(CI)類工具,旨在驗證項目中LookML。此處的LookML是Looker類型的數(shù)據(jù)建模語言。而Looker是一個BI(業(yè)務(wù)智能)平臺,它允許那些不懂SQL的人員去分析和可視化數(shù)據(jù)。
Spectacles通過在后臺運行SQL查詢,并檢查錯誤,來驗證LookML。它能夠與GitHub、GitLab和Azure DevOps相集成。該工具適用手動調(diào)用、從拉取請求中觸發(fā),以及作為ETL作業(yè)的一部分運行等,幾乎任何類型的部署模式。而將Spectacles作為CI/CD工作流的一部分,意味著它能夠在將代碼部署到生產(chǎn)環(huán)境之前,自動驗證LookML的相關(guān)查詢。
3.Datafold
作為一個主動式的數(shù)據(jù)質(zhì)量平臺,Datafold由數(shù)據(jù)差異(Data Diff)、具有列級沿襲(lineage)的數(shù)據(jù)目錄(Data Catalog)、以及數(shù)據(jù)監(jiān)控(Data Monitoring),三個主要組件所構(gòu)成。
Data Diff允許您在合并到生產(chǎn)環(huán)境之前,對兩個數(shù)據(jù)集(例如dev和prod)進行比較。這有助于用戶采用更為主動的開發(fā)策略。它也可以被集成到團隊的CI/CD管道中,以便共享GitHub或GitLab中的代碼更改,并顯示出具體的差異。
我們來看一個例子,Datafold的沙箱環(huán)境中自帶有一個taxi_trips的數(shù)據(jù)集。如下圖所示,我們在數(shù)據(jù)集datadiff-demo.public.taxi_trips和datadiff-demo.dev.taxi_trips之間運行了Data Diff操作。
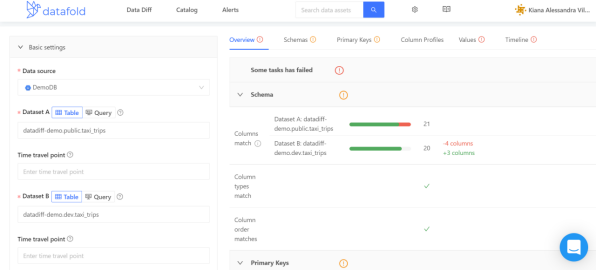
那么在右側(cè)帶有詳細信息的面板上,您將可以選擇不同的選項卡,以獲得針對結(jié)果的不同視角。其中,“Overview”選項卡將包含成功和失敗測試的概要。
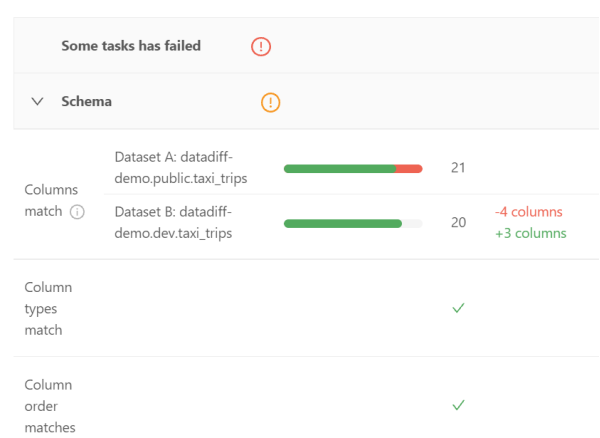
其Schema部分展示了兩個數(shù)據(jù)集的列(包括數(shù)據(jù)類型,以及出現(xiàn)的順序)是否相匹配。
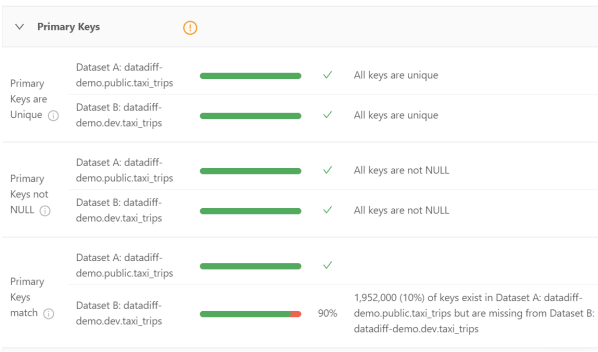
其Primary Keys部分顯示了主鍵的唯一性、非NULL、以及和兩個數(shù)據(jù)集之間匹配的百分比。
盡管Overview選項卡已經(jīng)充分展示了各種信息來源,但是其他選項卡也能提供更多實用的詳細信息。例如,Schemas選項卡就包含了如下方面:
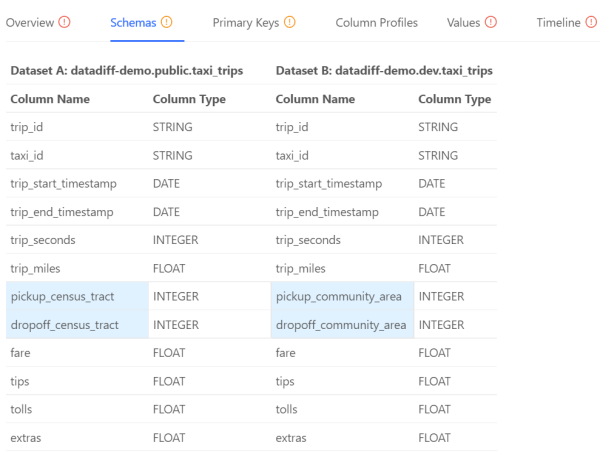
上圖突出顯示了具有兩個不同數(shù)據(jù)集的列。據(jù)此,數(shù)據(jù)工程師可以僅專注于這兩個領(lǐng)域的內(nèi)容,而節(jié)省寶貴的時間。
Data Catalog不但能夠列出所有注冊到Datafold的數(shù)據(jù)源,而且允許用戶使用過濾器,去查找和分析任何特定的數(shù)據(jù)集。對于擁有數(shù)百個、甚至是數(shù)千個數(shù)據(jù)集的組織來說,這無疑會大幅節(jié)省時間。作為一種發(fā)現(xiàn)異常的實用方法,它能夠針對數(shù)據(jù)沿襲(data lineage)功能,協(xié)助“回答”如下問題:
- 這個值從何而來?
- 這個值如何影響其他表?
- 這些表是如何關(guān)聯(lián)的?
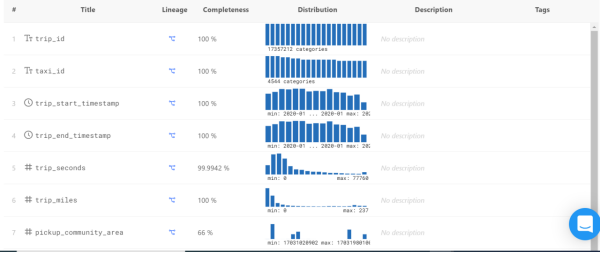
Data Catalog提供了如下儀表板。通過滾動鼠標,您可以看到每一列的詳細信息,其中包括:
- 完整性(Completeness)-- 不為NULL值的百分比。
- 分布(Distribution)-- 顯示了出現(xiàn)得最多與最少的值,以及偏向某個范圍的值。
單擊Lineage下的圖標,您會看到如下內(nèi)容:
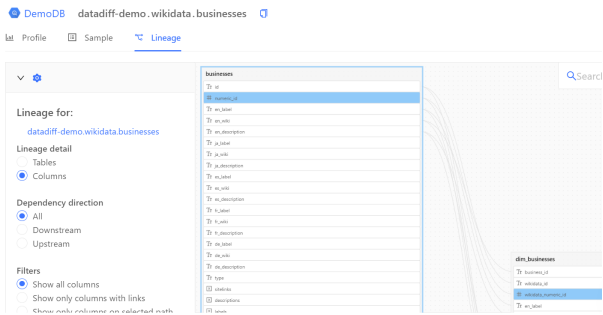
圖形沿襲圖(graphical lineage diagram)可以協(xié)助數(shù)據(jù)工程師快速找到列值的來源。您可以檢查表、所有(或特定)列、以及與上下游有關(guān)的各種沿襲。
Datafold的Data Monitoring功能允許數(shù)據(jù)工程師通過編寫SQL命令,來查找異常,并創(chuàng)建自動警報。這些警報由機器學(xué)習(xí)提供支持。而機器學(xué)習(xí)通過研究數(shù)據(jù)的趨勢和周期性,能夠準確地發(fā)現(xiàn)某些異常情況。下圖顯示了此類查詢:
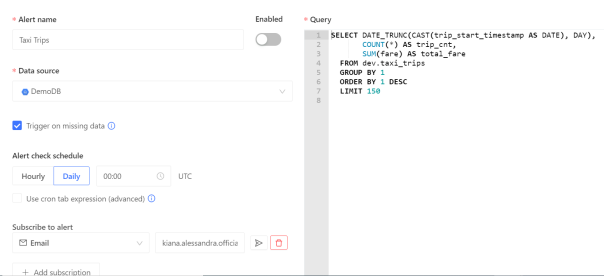
該查詢是由Datafold自動生成的。它跟蹤了出租車數(shù)據(jù)集中的每日總車費,以及總行程的趟數(shù)。
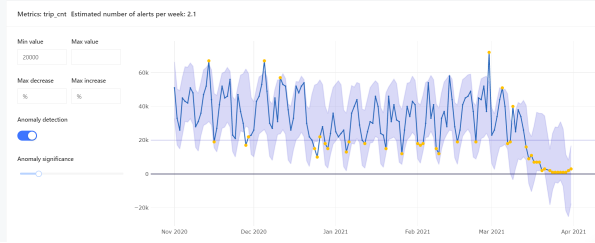
如下圖所示,Datafold還允許用戶去檢查異常跟隨時間變化的趨勢。其中,黃點表示相對于最小和最大值的各種異常。
4.Dbt
Dbt是一個數(shù)據(jù)轉(zhuǎn)換類工作流工具。它在部署之前,能夠針對目標數(shù)據(jù)庫執(zhí)行數(shù)據(jù)轉(zhuǎn)換的代碼,顯示代碼將如何影響數(shù)據(jù),并突出顯示各種潛在的問題。也就是說,Dbt通過運行SELECT語句,以基于轉(zhuǎn)換的邏輯,去構(gòu)建數(shù)據(jù)的結(jié)束狀態(tài)。
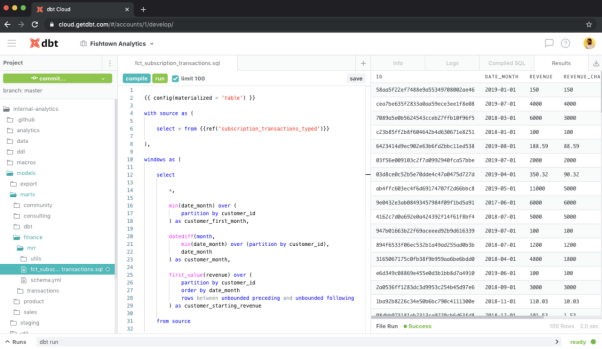
Dbt不但容易被集成到現(xiàn)代化的BI棧中,并且可以成為CI/CD管道的重要組成部分。它既可以根據(jù)拉取請求或按計劃自動運行,又具有自動化回滾的功能,可以阻止在部署過程中,具有潛在破壞性的代碼更改。
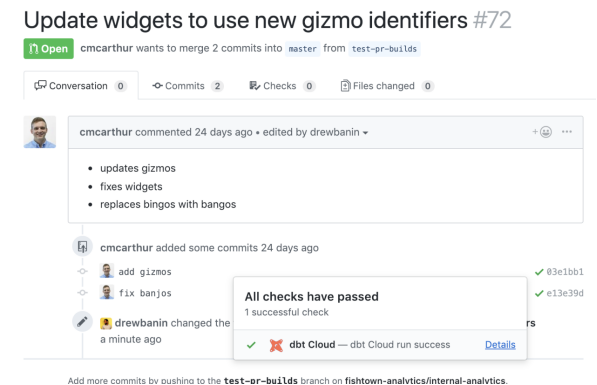
值得一提的是,Datafold和Dbt可以一起用于自動化的數(shù)據(jù)質(zhì)量測試。與Dbt類似,Datafold也可以被集成到CI/CD管道中。在協(xié)同使用時,它們會顯示目標代碼是如何影響數(shù)據(jù)的。
5.Evidently
作為一個開源的Python庫,Evidently用于分析和監(jiān)控機器學(xué)習(xí)的模型。它能夠基于Panda DataFrames和CSV文件生成交互式的報告,可用于對模型進行故障排除和數(shù)據(jù)完整性檢查。這些報告會顯示模型的運行狀況、數(shù)據(jù)漂移、目標漂移、數(shù)據(jù)完整性、特征分析、以及分段性能等指標。
為了了解Evidently的具體功能,您可以在Google Colab上打開一個新的筆記本,然后復(fù)制如下代碼段:
- wine = datasets.load_wine()
- wine_frame = pd.DataFrame(wine.data, columns = wine.feature_names)
- number_of_rows = len(wine_frame)
- wine_data_drift_report = Dashboard(tabs=[DataDriftTab])
- wine_data_drift_report.calculate(wine_frame[:math.floor(number_of_rows/2)], wine_frame[math.floor(number_of_rows/2):], column_mapping = None)
- wine_data_drift_report.save("report_1.html")
該代碼段會在瀏覽器中生成并加載報告。報告的儀表板概覽界面,將顯示基于每項功能的參考值與當前值的分布。

Evidently還可以進行更多近距離的檢查。例如,下圖顯示了當前數(shù)據(jù)集和參考數(shù)據(jù)集不同的確切值。
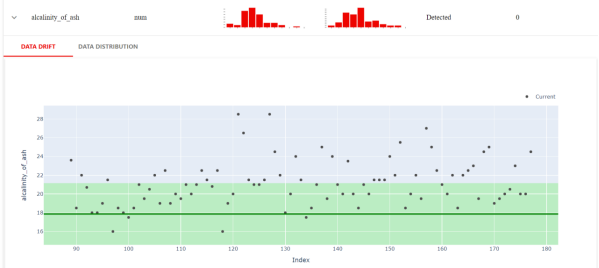
由此,我們可以進一步獲悉數(shù)值目標漂移、分類目標漂移、回歸模型性能、分類模型性能、以及概率分類模型等性能。
小結(jié)
隨著數(shù)據(jù)質(zhì)量標準和業(yè)務(wù)需求在不斷發(fā)展,數(shù)據(jù)質(zhì)量的保證已經(jīng)成為了一個持續(xù)的過程。上文和您討論的五種工具,通常可以被用于數(shù)據(jù)處理和使用的不同階段。您也可以根據(jù)自身業(yè)務(wù)和數(shù)據(jù)使用的實際需求,或是單獨采用,或是以不同的組合形式進行協(xié)同試用。
原文標題:Five Data Quality Tools You Should Know,作者:Michael Bogan
【51CTO譯稿,合作站點轉(zhuǎn)載請注明原文譯者和出處為51CTO.com】