首個基于時序平移的視頻遷移攻擊算法,復旦大學研究入選AAAI 2022
近年來,深度學習在一系列任務中(例如:圖像識別、目標識別、語義分割、視頻識別等)取得了巨大成功。因此,基于深度學習的智能模型正逐漸廣泛地應用于安防監控、無人駕駛等行業中。但最近的研究表明,深度學習本身非常脆弱,容易受到來自對抗樣本的攻擊。對抗樣本指的是由在干凈樣本上增加對抗擾動而生成可以使模型發生錯誤分類的樣本。對抗樣本的存在為深度學習的應用發展帶來嚴重威脅,尤其是最近發現的對抗樣本在不同模型間的可遷移性,使得針對智能模型的黑盒攻擊成為可能。具體地,攻擊者利用可完全訪問的模型(又稱白盒模型)生成對抗樣本,來攻擊可能部署于線上的只能獲取模型輸出結果的模型(又稱黑盒模型)。此外,目前的相關研究主要集中在圖像模型中,而對于視頻模型的研究較少。因此,亟需開展針對視頻模型中對抗樣本遷移性的研究,以促進視頻模型的安全發展。
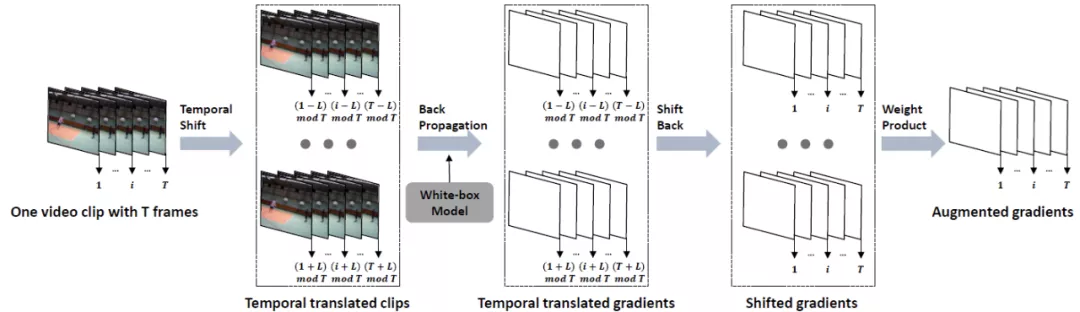
時序平移攻擊方法
與圖片數據相比,視頻數據具有額外的時序信息,該類信息能夠描述視頻中的動態變化。目前已有多種不同的模型結構(例如:Non-local,SlowFast,TPN)被提出,以捕獲豐富的時序信息。然而多樣化的模型結構可能會導致不同模型對于同一視頻輸入的高響應區域不同,也會導致在攻擊過程中所生成的對抗樣本針對白盒模型產生過擬合而難以遷移攻擊其他模型。為了進一步剖析上述觀點,來自復旦大學姜育剛團隊的研究人員首先針對多個常用視頻識別模型(video recognition model)的時序判別模式間的相似性展開研究,發現不同結構的視頻識別模型往往具有不同的時序判別模式。基于此,研究人員提出了基于時序平移的高遷移性視頻對抗樣本生成方法。

- 論文鏈接:https://arxiv.org/pdf/2110.09075.pdf
- 代碼鏈接:https://github.com/zhipeng-wei/TT
視頻模型的時序判別模式分析
在圖像模型中,常常利用 CAM(Class activation mapping)來可視化模型對于某張圖片的判別區域。然而在視頻模型的判別模式由于額外的時序維度而難以可視化,且難以在不同模型間進行比較。為此,研究人員定義視頻幀的重要性排序作為視頻模型的時序判別模式。如果兩個模型共享相似的時序判別模式,那么視頻幀重要性的分布會更加相似。
視頻幀的重要性計算
研究人員使用了三種途徑衡量視頻幀對于模型決策的重要性:Grad-CAM,Zero-padding 和 Mean-padding。Grad-CAM 在由 CAM 計算得到的 attention map 中針對每一幀進行均值計算,該均值則為視頻各幀的重要性度量。而 Zero-padding 使用 0 來替換第i視頻幀中的所有像素值,并計算替換前后的損失值的變化程度。變化程度越高說明第 i 視頻幀越重要。類似地,Mean-padding 使用臨近幀的均值替換第i視頻幀。通過以上三種方式,可計算得到在不同模型下視頻幀的重要性程度,并以此作為模型的時序判別模式。
時序判別模式相似度計算
由上述方法計算視頻數據x在模型A上的視頻幀重要性得分為
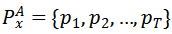
,其中T表示輸入視頻幀的數目。那么針對模型A和模型B,可得到
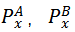
,結合 Spearman’s Rank Correlation,可計算模型間時序判別模式的相似性
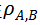
,即
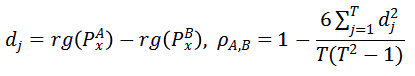
其中,
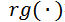
執行基于重要性值的排序操作并返回視頻各幀的排序值。
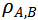
的值在-1和1之間,當其等于0時表示模型A和模型B間的判別模式不存在關系,而-1或者1則表示明確的單調關系。
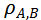
的值越大則模型間的判別模式越相似。基于此,可實現不同視頻模型時序判別模式間關系的度量。

不同視頻模型間判別模式的相似程度
上圖為 6 個視頻模型間的判別模式關系熱圖。在不同模型設計架構下,Non-Local、SlowFast 和 TPN 間的時序判別模式相似程度較低;而在相同設計架構下,分別使用 3D Resnet-50 和 3D Resnet-101 作為 backbone 的視頻模型具有更加相似的時序判別模式。以上趨勢在三種視頻幀重要性計算方法中都得到了驗證。由此,可在實驗上證明該論文的假設,即不同視頻模型結構會導致不同的時序判別模式。
時序平移攻擊方法
基于以上觀察,研究人員提出了基于時序平移的遷移攻擊方法。通過沿著時序維度移動視頻幀,來降低所生成對抗樣本與白盒模型特定判別模型之間的擬合程度,提高對抗樣本在黑盒模型上的攻擊成功率。
使用
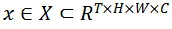
表示輸入視頻,
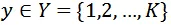
表示其對應真實標簽,其中T,H,W,C分別表示幀數,高度,寬度和通道數,K表示類別數目。使用
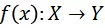
表示視頻模型對于視頻輸入的預測結果。定義
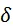
為對抗噪聲,那么攻擊目標可以定義為
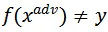
,其中
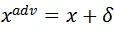
,且限制
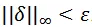
。定義
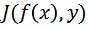
為損失函數。則非目標攻擊的目標函數可定義為:
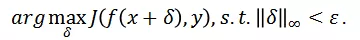
為了降低攻擊過程中對于白盒模型的過擬合現象,研究人員對時序移動后視頻輸入的梯度信息進行聚合:
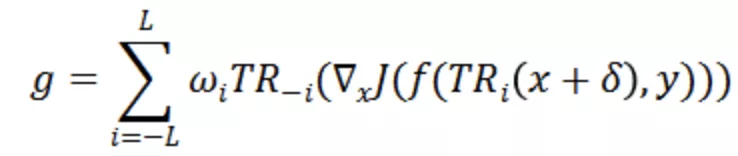
其中L表示最大平移長度,且
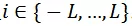
。函數
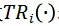
表示將所有的視頻輸入沿著時序維度平移i幀。當平移后的位置大于T時,設當前幀為第i幀,即t+i>T,則第t幀的位置變為第t+i-T幀,否則為第t+i幀。而在時序平移后的視頻輸入上計算完梯度后,仍會沿著時序維度平移回原始視頻幀序列,并通過w_i來整合來自不同平移長度的梯度信息。w_i可利用均一、線性、高斯三種方式生成(參考 Translation-invariant 攻擊方法)。
攻擊算法整體流程如下,其中
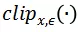
用來限制生成的對抗噪聲滿足
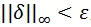
。

結果討論與分析
為了探究時序平移攻擊方法的性能,研究人員在 UCF-101 和 Kinetics-400 兩個數據集,Non-local,SlowFast,TPN 三種不同結構的視頻模型中進行對比實驗,其中視頻模型分別使用 3D Resnet-50 和 3D Resnet-101 作為 backbone。當使用某一種結構的視頻模型作為白盒模型時,計算所生成對抗樣本在其他結構的視頻模型上的攻擊成功率(Attack success rate,ASR),以此作為評價指標。
研究人員分別在單步攻擊和迭代攻擊方法下進行了實驗對比。可以看出時序平移攻擊方法在單步攻擊和迭代攻擊下都能取得更高的 ASR,表明所生成的對抗樣本具有高遷移性。此外,在視頻模型上,單步攻擊的效果好于迭代攻擊。這說明,在圖像模型中發展出的遷移攻擊方法不適用于更復雜的視頻模型。最后,當使用 TPN 模型作為白盒模型時,時序平移攻擊方法的性能提升較為有限,研究人員通過分析后認為 TPN 模型對于時序移動更加不敏感。
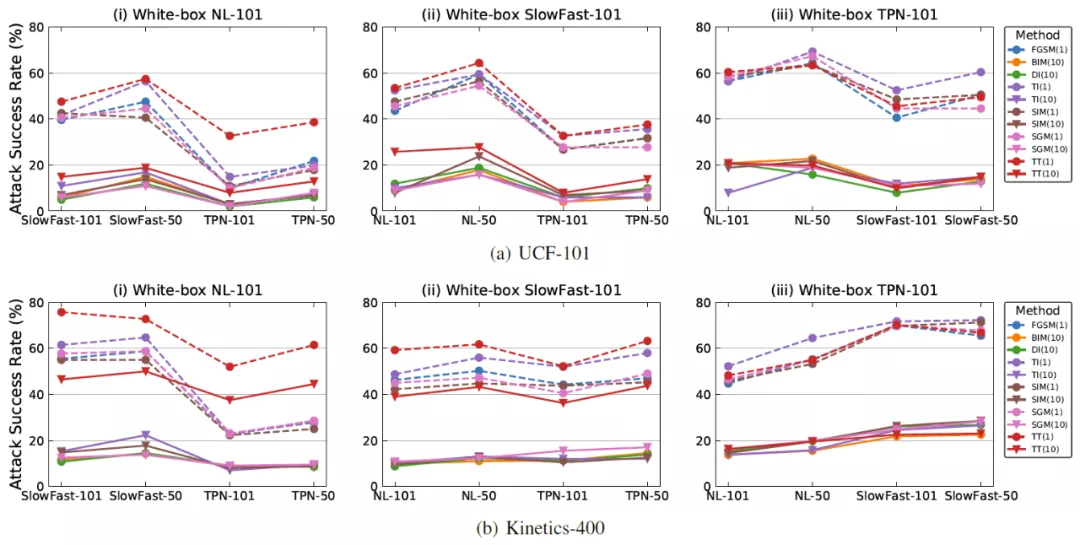
視頻識別模型上的 ASR 對比圖
下表展示了與 Translation-invariant(TI)攻擊方法、Attention-guided(ATA)攻擊方法和 Momentum iterative(MI)攻擊方法相結合后的性能比較。可以看出,時序平移方法可以輔助這些方法發揮更好的性能,起到補充的作用。
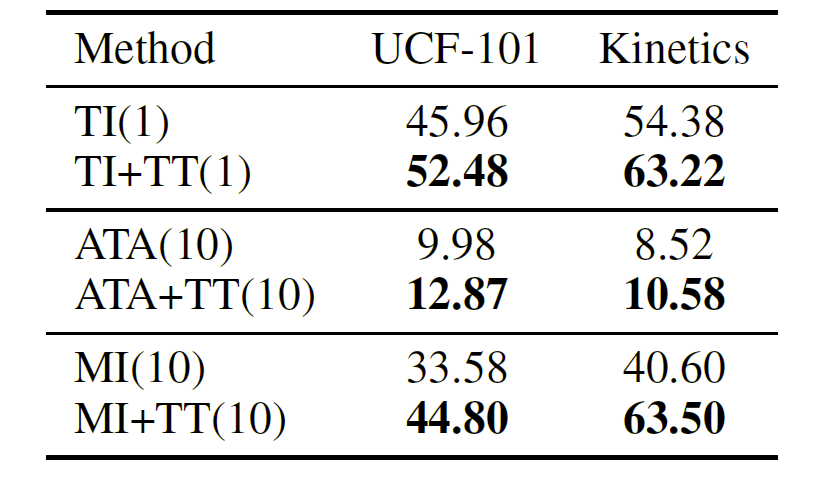
結合現有方法的平均 ASR 結果對比
此外,研究人員還針對不同的平移長度L、權重w_i生成策略及平移策略進行了消融實驗。
平移長度L決定了有多少個平移后的視頻輸入被用來進行特征聚合。當L=0時,時序平移方法將會退化為最基本的迭代攻擊方法。因此,針對平移長度的研究是十分有必要的。下圖展示了不同平移長度下時序平移攻擊方法在不同黑盒模型下的 ASR 變化情況。可以看到,Non-local Resnet-50 模型的曲線更加穩定,而其他黑盒模型的曲線呈現先上升再趨于穩定的特點。這是因為 Non-local Resnet-50 與 Non-local Resnet-101 共享相似的模型結構。為了平衡 ASR 和計算復雜度,研究人員最終選取L=7來進行實驗。
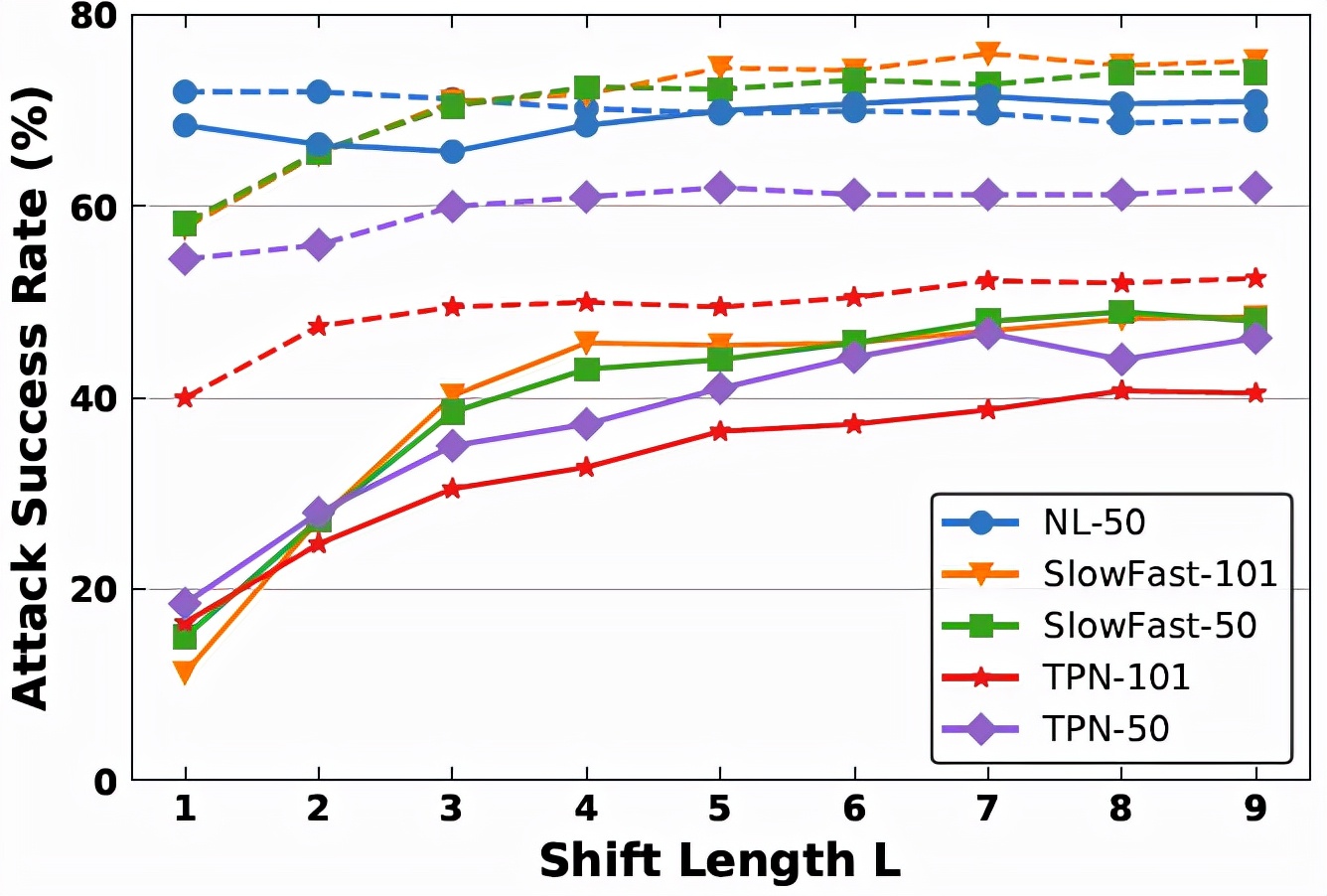
不同平移長度下的時序平移攻擊方法性能對比
下表展示的是對于權重生成策略和平移策略的消融實驗結果。從表中可以看出,當賦予具有更大時序平移長度的視頻輸入以更小的權重時,時序平移攻擊方法能取得較好的結果。此外,當平移策略變為隨機幀交換或遠距離交換時,時序平移攻擊方法會取得較差的結果。
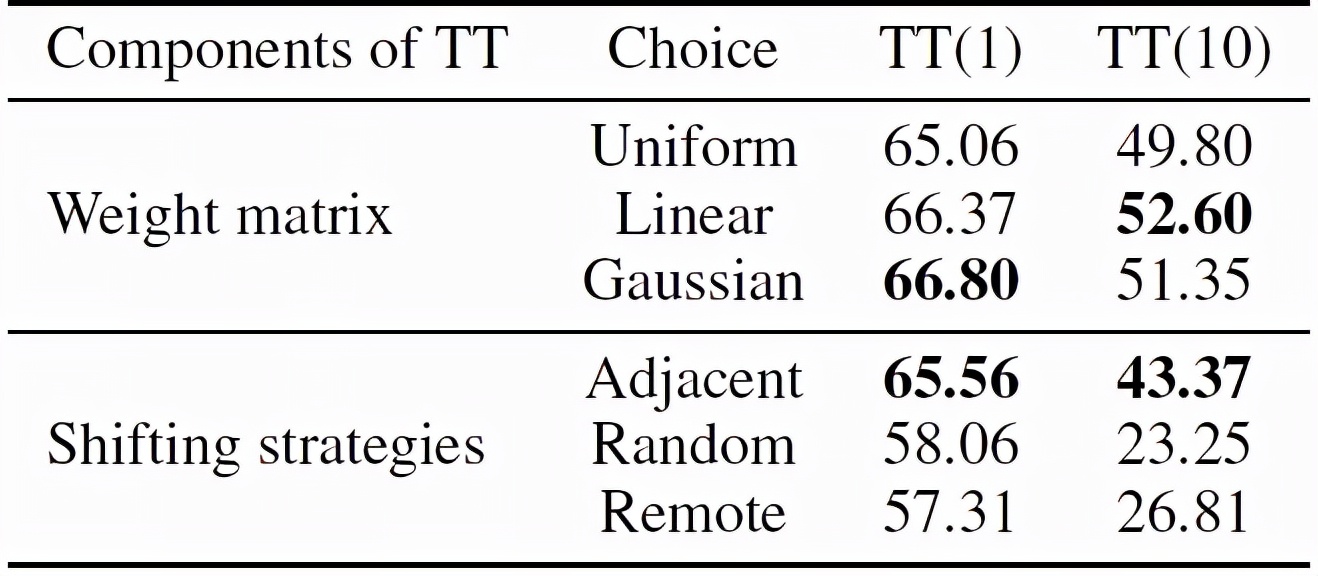
不同權重生成策略和平移策略下時序平移攻擊方法的性能對比