













復(fù)旦大學(xué)聯(lián)合華為諾亞提出VidRD框架,實(shí)現(xiàn)迭代式的高質(zhì)量視頻生成
復(fù)旦大學(xué)聯(lián)合華為諾亞方舟實(shí)驗(yàn)室的研究者基于圖像擴(kuò)散模型(LDM)提出了一種迭代式生成高質(zhì)量視頻的方案 ——VidRD (Reuse and Diffuse)。該方案旨在對(duì)生成視頻的質(zhì)量和序列長(zhǎng)度上進(jìn)行突破,實(shí)現(xiàn)了高質(zhì)量、長(zhǎng)序列的可控視頻生成。有效減少了生成視頻幀間的抖動(dòng)問(wèn)題,具有較高的研究和實(shí)用價(jià)值,為當(dāng)前火熱的AIGC社區(qū)貢獻(xiàn)了一份力量。
潛在擴(kuò)散模型(LDM)是一種基于去噪自編碼器(Denoising Autoencoder)的生成模型,它可以通過(guò)逐步去除噪聲來(lái)從隨機(jī)初始化的數(shù)據(jù)生成高質(zhì)量的樣本。但由于在模型訓(xùn)練和推理過(guò)程中都存在著計(jì)算和內(nèi)存的限制,一個(gè)單獨(dú)的 LDM 通常只能生成數(shù)量非常有限的視頻幀。盡管現(xiàn)有的工作嘗試使用單獨(dú)的預(yù)測(cè)模型來(lái)生成更多的視頻幀,但這也會(huì)帶來(lái)額外的訓(xùn)練成本并產(chǎn)生幀級(jí)的抖動(dòng)。
在本文中,受到潛在擴(kuò)散模型(LDMs)在圖像合成方面的顯著成功的啟發(fā),提出了一個(gè)名為“Reuse and Diffuse”的框架,簡(jiǎn)稱(chēng)VidRD。該框架可以在 LDM 已經(jīng)生成的少部分視頻幀之后,產(chǎn)生更多的視頻幀,從而實(shí)現(xiàn)迭代式地生成更長(zhǎng)、更高質(zhì)量以及多樣化的視頻內(nèi)容。VidRD 加載了預(yù)訓(xùn)練的圖像 LDM 模型進(jìn)行高效訓(xùn)練,并使用添加有時(shí)序信息的 U-Net 網(wǎng)絡(luò)進(jìn)行噪聲去除。

- 論文標(biāo)題:Reuse and Diffuse: Iterative Denoising for Text-to-Video Generation
- 論文地址:https://arxiv.org/abs/2309.03549
- 項(xiàng)目主頁(yè):https://anonymous0x233.github.io/ReuseAndDiffuse/
本文的主要貢獻(xiàn)如下:
- 為了生成更加平滑的視頻,本文基于時(shí)序感知的 LDM 模型提出了一種迭代式的 “text-to-video” 生成方法。通過(guò)重復(fù)使用已經(jīng)生成視頻幀的潛空間特征以及每次都遵循先前的擴(kuò)散過(guò)程,該方法可以迭代式地生成更多的視頻幀。
- 本文設(shè)計(jì)了一套數(shù)據(jù)處理方法來(lái)生成高質(zhì)量的 “文本 - 視頻” 數(shù)據(jù)集。針對(duì)現(xiàn)有的動(dòng)作識(shí)別數(shù)據(jù)集,本文利用多模態(tài)大語(yǔ)言模型來(lái)為其中的視頻賦予文本描述。針對(duì)圖像數(shù)據(jù),本文采用隨機(jī)縮放和平移的方法來(lái)產(chǎn)生更多的視頻訓(xùn)練樣本。
- 在 UCF-101 數(shù)據(jù)集上,本文驗(yàn)證了 FVD 和 IS 兩種評(píng)價(jià)指標(biāo)以及可視化結(jié)果,定量和定性的結(jié)果顯示:相較于現(xiàn)有方法,VidRD 模型均取得了更好的效果。
方法介紹
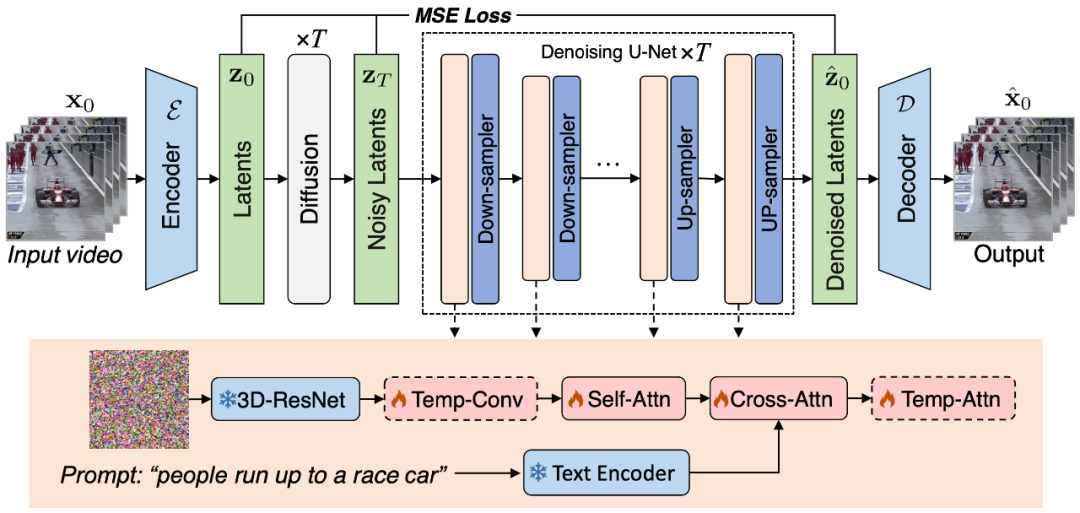
圖 1. 本文提出的 VidRD 視頻生成框架示意圖
本文認(rèn)為采用預(yù)訓(xùn)練的圖像 LDM 作為高質(zhì)量視頻合成的 LDM 訓(xùn)練起點(diǎn)是一種高效而明智的選擇。同時(shí),這一觀點(diǎn)得到了 [1, 2] 等研究工作的進(jìn)一步支持。在這樣的背景下,本文精心設(shè)計(jì)的模型基于預(yù)訓(xùn)練的穩(wěn)定擴(kuò)散模型構(gòu)建,充分借鑒并繼承了其優(yōu)良的特性。這其中包括一個(gè)用于精準(zhǔn)潛在表示的變分自編碼器(VAE)和一個(gè)功能強(qiáng)大的去噪網(wǎng)絡(luò) U-Net。圖 1 以清晰、直觀的方式展示了該模型的整體架構(gòu)。
在本文的模型設(shè)計(jì)中,一個(gè)顯著的特點(diǎn)是對(duì)預(yù)訓(xùn)練模型權(quán)重的充分利用。具體來(lái)說(shuō),大部分網(wǎng)絡(luò)層,包括 VAE 的各組件和 U-Net 的上采樣、下采樣層,均使用穩(wěn)定擴(kuò)散模型的預(yù)訓(xùn)練權(quán)重進(jìn)行初始化。這一策略不僅能顯著加速模型的訓(xùn)練過(guò)程,還能從一開(kāi)始就確保模型表現(xiàn)出良好的穩(wěn)定性和可靠性。本文的模型可以在一個(gè)初始的包含少量幀的視頻片段的條件下,通過(guò)重用原始的潛在特征和模仿之前的擴(kuò)散過(guò)程,迭代地生成額外的幀。此外,對(duì)于用于在像素空間和潛在空間之間進(jìn)行轉(zhuǎn)換的自編碼器,本文在其解碼器中注入了和時(shí)序相關(guān)的網(wǎng)絡(luò)層,并對(duì)這些層進(jìn)行了微調(diào),以提高時(shí)間一致性。
為了保證視頻幀間的連續(xù)性,本文在模型中添加了 3D Temp-conv 和 Temp-attn 層。Temp-conv 層緊跟在 3D ResNet 后面,該結(jié)構(gòu)可以實(shí)現(xiàn) 3D 卷積操作,以捕捉空間和時(shí)間的關(guān)聯(lián),進(jìn)而理解視頻序列匯總的動(dòng)態(tài)變化和連續(xù)性。Temp-Attn 結(jié)構(gòu)與 Self-attention 相似,用于分析和理解視頻序列中的幀間關(guān)系,使模型能夠精準(zhǔn)地同步幀間的運(yùn)行信息。這些參數(shù)在訓(xùn)練時(shí)隨機(jī)初始化,旨在為模型提供時(shí)序結(jié)構(gòu)上的理解和編碼。此外,為了適配該模型結(jié)構(gòu),數(shù)據(jù)的輸入也做了相應(yīng)的適配和調(diào)整。
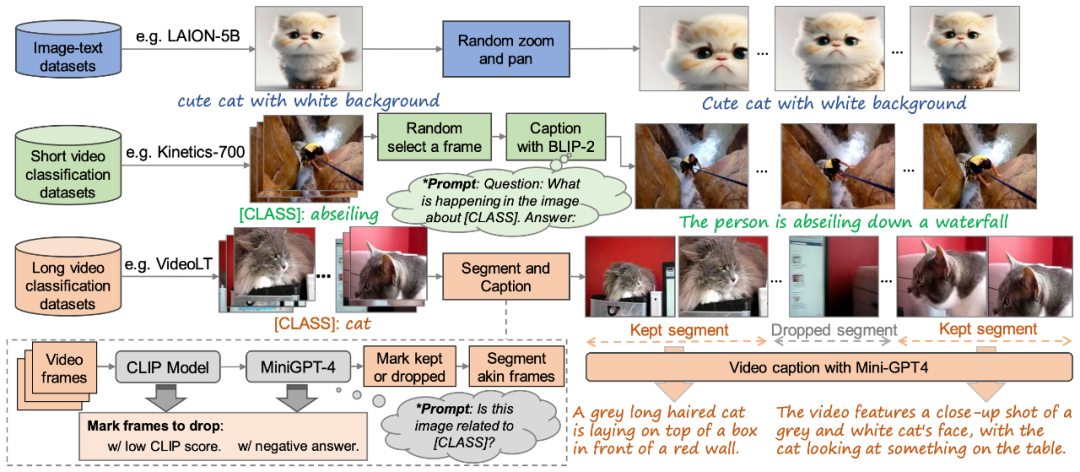
圖 2. 本文提出的高質(zhì)量 “文本 - 視頻” 訓(xùn)練數(shù)據(jù)集構(gòu)建方法
為了訓(xùn)練 VidRD 模型,本文提出了一種構(gòu)建大規(guī)模 “文本 - 視頻” 訓(xùn)練數(shù)據(jù)集的方法,如圖 2 所示,該方法可以處理 “文本 - 圖像” 數(shù)據(jù)和無(wú)描述的 “文本 - 視頻” 數(shù)據(jù)。此外,為了實(shí)現(xiàn)高質(zhì)量的視頻生成,本文也嘗試對(duì)訓(xùn)練數(shù)據(jù)進(jìn)行了去水印操作。
盡管當(dāng)前市場(chǎng)上高質(zhì)量的視頻描述數(shù)據(jù)集相對(duì)稀缺,但存在大量的視頻分類(lèi)數(shù)據(jù)集。這些數(shù)據(jù)集擁有豐富的視頻內(nèi)容,每段視頻都伴隨一個(gè)分類(lèi)標(biāo)簽。如 Moments-In-Time、Kinetics-700 和 VideoLT 就是三個(gè)代表性的大規(guī)模視頻分類(lèi)數(shù)據(jù)集。Kinetics-700 涵蓋了 700 個(gè)人類(lèi)動(dòng)作類(lèi)別,包含超過(guò) 60 萬(wàn)的視頻片段。Moments-In-Time 則囊括了 339 個(gè)動(dòng)作類(lèi)別,總共有超過(guò)一百萬(wàn)的視頻段落。而 VideoLT 則包含了 1004 個(gè)類(lèi)別和 25 萬(wàn)段未經(jīng)編輯的長(zhǎng)視頻。
為了充分利用現(xiàn)有的視頻數(shù)據(jù),本文嘗試對(duì)這些視頻進(jìn)行自動(dòng)化地更加詳細(xì)的標(biāo)注。本文采用了 BLIP-2、MiniGPT4 等多模態(tài)大語(yǔ)言模型,通過(guò)針對(duì)視頻中的關(guān)鍵幀,結(jié)合其原始的分類(lèi)標(biāo)簽,本文設(shè)計(jì)了許多 Prompts,以通過(guò)模型問(wèn)答的方式產(chǎn)生標(biāo)注。這種方法不僅增強(qiáng)了視頻數(shù)據(jù)的語(yǔ)音信息,而且可以為現(xiàn)有沒(méi)有詳細(xì)描述的視頻帶來(lái)更加全面、細(xì)致的視頻描述,從而實(shí)現(xiàn)了更加豐富的視頻標(biāo)簽生成,以幫助 VidRD 模型帶來(lái)更好的訓(xùn)練效果。
此外,針對(duì)現(xiàn)有的非常豐富的圖像數(shù)據(jù),本文也設(shè)計(jì)了詳細(xì)的方法將圖像數(shù)據(jù)轉(zhuǎn)換為視頻格式以進(jìn)行訓(xùn)練。具體操作為在圖像的不同位置、按照不同的速度進(jìn)行平移和縮放,從而為每張圖像賦予獨(dú)特的動(dòng)態(tài)展現(xiàn)形式,模擬現(xiàn)實(shí)生活中移動(dòng)攝像頭來(lái)捕捉靜止物體的效果。通過(guò)這樣的方法,可以有效利用現(xiàn)有的圖像數(shù)據(jù)進(jìn)行視頻訓(xùn)練。
效果展示
描述文本分別為:“Timelapse at the snow land with aurora in the sky.”、“A candle is burning.”、“An epic tornado attacking above a glowing city at night.”、以及“Aerial view of a white sandy beach on the shores of a beautiful sea.”。更多可視化效果可見(jiàn)項(xiàng)目主頁(yè)。

圖 3. 生成效果與現(xiàn)有的方法進(jìn)行可視化對(duì)比
最后,如圖 3 所示,分別為本文生成結(jié)果與現(xiàn)有方法 Make-A-Video [3] 和 Imagen Video [4] 的可視化比較,展現(xiàn)了本文模型質(zhì)量更好的生成效果。


























