???
【51CTO.com快譯】序幕
近些年,微服務風格的應用架構正在扎根并迅速成長,它們可能已散布在企業生態系統的方方面面。在多云環境中組織以及運維微服務,圍繞微服務組織數據,使數據盡可能實時傳輸,這些工作正成為我們面臨的挑戰。
由于事件驅動架構 (EDA) 平臺(例如 Kafka)和數據管理技術(例如 Data Meshes 和 Data Fabrics)的發展,設計基于微服務的應用會變得更加容易。
然而,為了確保這些基于微服務的應用在對應的級別上運行,必須確保在設計期間就考慮到關鍵的非功能需求(NFRs)。
在一系列博客文章中,我和我的同事 Tanmay Ambre、Harish Bharti試圖用統一的方法來描述NFR 設計。我們稱之為基于用例的方法。
在第一部分中,我們將聊聊“性能”的設計,它是最關鍵的NFR需求。本文會介紹如何對于大容量、低延遲處理為基礎的架構和設計進行決策。
為了讓決策過程清晰易懂,我們將使用銀行轉賬作為演示用例,在簡化了用例的同時,將關注點放到性能上。
用例
電子資金轉賬 (ETF) 是當今通過數字渠道消費的一種非常重要的匯款和收款方式。這也是為什么我們使用該用例來解釋與性能相關的決策,因為在用例中會涉及到海量請求以及多分布式協調等諸多問題,并且不用考慮誤差范圍(包括:可靠性和容錯問題)。
在過去,資金轉賬需要數天時間。還會涉及前往銀行或者開支票的過程。然而,隨著數字化、新支付機制、支付網關的出現以及相關規定的影響下,資金轉賬在瞬間就可以完成。例如,2021 年 9 月,在 UPI 網絡上就發生了 36 億筆交易,交易總價值 約合6.5 萬億印度盧比。客戶更趨向于通過各種渠道進行實時支付。PSD2、開放銀行和特定國家/地區已經通過相關法規,法規明確規定向受信任的第三方應用程序開發人員公開其支付機制。
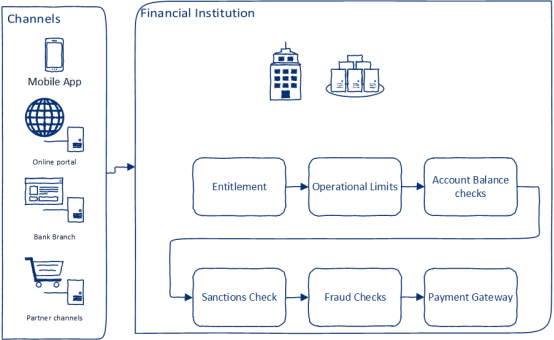
通常,銀行客戶會使用任意渠道(例如,移動應用程序、在線門戶或訪問機構)發起轉賬請求。當收到轉賬請求后,需要執行以下操作,如圖1 所示:
1. 鑒定轉賬資格(Entitlement)——檢查客戶是否具備轉賬的資格
2. 檢查操作權限(Operational limits)(是否具備使用轉賬通道和傳輸模式的權利)
3. 檢查余額并鎖定轉賬金額(Account Balance checks)
4. 制裁檢查(Sanctions Check) —— 交易是否符合法規以及制裁檢查
5. 欺詐檢查(Fraud Checks) —— 檢查交易是否具有欺詐性
6. 在支付網關中創建支付請求(Payment Gateway)
下圖對此進行了概述:
? ??
??
圖1 收到轉賬請求需要執行的操作
注意:就本文而言,以上用例所涉及到的操作會在發起請求的金融機構內部完成。它依賴于已存在的轉賬網關,支付網關并在此范疇內。
關鍵的非功能性需求
以下是關鍵的 NFR(非功能性需求):
1. 性能
- 事件的低延遲處理
- 高吞吐量
2. 彈性
- 可恢復性——從故障中恢復的能力。從故障點重新啟動并具有重放事件的能力。最小化 RTO(恢復時間目標)
- 零數據丟失
- 保證結果的可靠性和一致性。
3. 可用性和可擴展性
- 高可用和容錯——承擔故障(包括承擔數據中心/可用區域的中斷情況)
- 隨著負載增加而對系統進行水平擴展
- 能夠承受突發的流量激增(彈性可擴展性)
- 在符合法規的前提下持久化海量數據
4. 安全
- 應用中核心組件安全性——左移(Shifting left 未雨綢繆)(備注:軟件開發過程被視為一個從左到右的順序過程。例如:定義需求、分析、設計、編碼、測試和部署。左移就提前考慮某某問題,不要等到了這一步再思考這個問題,放到文中就是提前考慮核心組件安全性的問題。因此翻譯為“未雨綢繆”)
- 認證和授權
- 審計
- 傳輸層安全
- 保證數據在傳輸狀態和靜止狀態的安全性
架構
云原生技術的方方面面將會貫穿本案例的實現模型——例如:微服務、API、容器、事件流和分布式數據管理,以及使用最終一致性風格的數據持久化方式來保證數據的完整性。需要注意的是,基于事件驅動的微服務架構為本案例架構提供了最佳實踐。
以下是為實現此案例需要考慮的關鍵架構模式:
1. 分段事件驅動架構 (SEDA Staged Event-Driven Architecture)
2. 事件流處理
3. 事件溯源
4. SAGA
5. CQRS
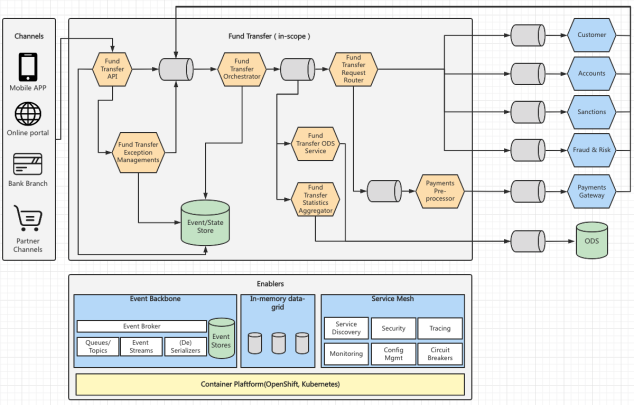
如圖2所示,為本案例解決方案架構圖:
? ??
??
圖2 案例架構圖
應用和數據流
應用架構是由一組可獨立運行的微服務組成。此外,協調器服務(Enablers)作為單獨的微服務負責協調整個事務,確保端到端流程執行到位。
資金轉賬(Fund Transfer)包含多個服務,作為轉賬事件的生產者、處理者和消費者它們相互連接。主要由如下 4 個主要處理器:
1. Fund Transfer Orchestrator (轉賬協調器)– 負責處理資金轉移事件并修改和維護資金轉賬請求的狀態。
2. Fund Transfer Request Router(轉賬請求路由器)–基于資金的狀態轉換請求生成事件,并確定事件所對應的路由。它可以將接受到的事件以多播的形式發送到一個或者多個系統。同時它也是一個可選組件,如果下游消費者不能從單個主題消費(例如,下游消費者是遺留服務或已經實現的服務,同時這些服務不能更改成從單個主題消費),則需要使用到它。
3. Fund Transfer Statistics Aggregator(轉賬統計聚合器) – 基于管理 KPI 所需的多維度進行匯總,并且維護轉賬過程中的統計數據。
4. Fund Transfer Exception Managements(轉賬異常管理) – 根據異常自動觸發轉賬請求中的用戶行為,包括取消轉賬,轉賬重試 。簡而言之是為用戶提供管理轉賬異常的功能。
5. Fund Transfer API (轉賬API)– 為不同轉賬渠道提供以下功能:(a) 請求轉賬,(b) 檢查轉賬狀態,(c) 管理轉賬(取消、重試等)。
API 向 Fund Transfer Orchestrator 的input topic(輸入主題)發布事件,該主題是 Fund Transfer 請求的主要協調器。發送的事件作為“一等公民”會被持久化到Event/State Store中,同時這些時間會在Event/State Store中不斷積累(啟用事件溯源架構模式)。根據事件上下文和有效載荷,Fund Transfer Orchestrator將事件進行轉換并將轉賬狀態發布到另一個topic(主題)中。同樣,轉賬記錄的狀態變更也會被持久化,在出現系統級故障時,可用于恢復轉賬狀態。
接著,由Fund Transfer Request Router(轉移請求路由器)處理通過topic 傳遞過來的轉賬狀態信息,并由Fund Transfer Request Router決定該狀態被路由到哪個系統中(單個或者多個)。這些系統(如圖2 右邊的Customer、Accounts、Sanctions等)將處理之后的結果作為事件發布到input topic(輸入主題),再由Fund Transfer Orchestrator(轉賬協調器)進行關聯和處理,最終完成轉賬狀態的更新。Fund Transfer Orchestrator (轉賬協調器)也能夠通過input topic 接受來自Fund Transfer Exception Managements(轉賬異常管理)的異常消息,并對其進行處理,然后更新轉賬請求的狀態。
Fund Transfer Statistics Aggregator(轉賬統計聚合器)也可以通過topic接受來自Fund Transfer Orchestrator (轉賬協調器)的轉賬事件,并且對轉賬記錄進行實時統計,Fund Transfer Statistics Aggregator(轉賬統計聚合器)還聚合了多維度的轉賬統計數據——以便運營團隊可以實時地查看轉賬的統計數據。
技術構件和技術棧
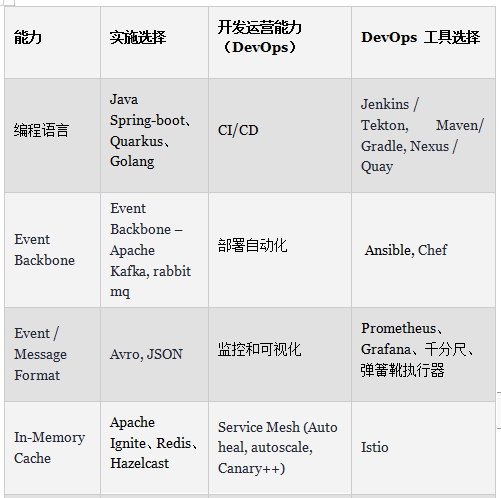
為了實現上述應用架構,需要使用關鍵的技術構件如下:
1. Event backbone——用于在服務之間的發送消息。它還將確保發送事件的排序和序列。它還提供了數據真實性的單一來源。發生故障時——系統可以從故障點重啟。它提供了構建事件和狀態存儲的機制。在發生重大中斷的情況下,所存儲的事件和狀態存儲可用于狀態恢復。
2. In-memory data-grid——是一個分布式緩存可以用來提高系統的性能。它擁有從服務中存儲和查找數據的能力。它使每個服務都有自己的一組緩存,并且這些緩存是可以被持久化(可選),支持“write-through”模式(同時往內存和磁盤寫入信息)。它具有彈性并且可以承受中斷。此外,在集群級故障(即整個緩存集群宕機)的情況下,緩存可以通過Event Backbone的持久化機制恢復(但是,需要處理器停止工作一段時間)。
3. Service Mesh——提供監控、安全和服務發現的能力。
我們可以通過如下技術棧來構建系統。技術棧中的工具大部分是開源的,也可以使用其他技術代替。例如,Quarkus 等。
? ??
??
? ??
??
解決NFR(非功能性需求)的設計決策
為了解決高度動態和復雜的 NFR,提出最重要的三項設計決策。
- Event Backbone——為了實現用例和滿足架構要求需要建立Event backbone(事件主干)。其主要原因是可以讓不同的轉賬過程并行,從而降低處理時間。此外,使用行業級的event backbone(事件主干)將提供/支持某些開箱即用的高質量架構(例如容錯性、可恢復性、可擴展性和事件排序)。
- 數據流——使用in-memory data grid(內存數據網格)可以顯著減少數據庫請求。此外,數據和事件被分區的設計使得系統更容易擴展。為部署所有組件選擇相同的使用區域——大大減少了網絡延遲。
- 安全方面的“左移”–通過強制的手段保證每個組件的安全性。需要為每個組件(尤其是event backbone事件主干、in-memory data grid內存數據網格)實施適當的訪問控制和身份驗證機制。必須深入了解需要滿足的安全標準和法規(本案例包括:PCI-DSS、GDPR 等)。傳輸層的安全性對于確保數據在傳輸過程中的加密來說至關重要。此外,必須強制執行與數據(特別是敏感的私人信息)相關的控制。避免將敏感信息放入緩存中(盡管這可能會影響性能)。因此,在NFR 測試期間 – 需要對安全性進行測試。靜態代碼質量分析工作需要檢查代碼中的安全漏洞,針對組件鏡像的掃描也是為了檢查安全漏洞。防火墻、DMZ、VPC 需要通過適當的 IAM 解決方案進行配置。同時云原生架構也需要關注另一個安全方面的問題,就是機密、密鑰和證書管理。
上述三個設計決策將有助于解決以下類別的 NFR:
- 自動擴展——系統的每個組件(包括事件主干、內存數據網格)在容器化并部署在 Kubernetes 和 OpenShift 等平臺上之后都可以自動擴展。
- 容錯- 處理管道的每個組件都可以從故障點重新啟動。這并不需要特殊的實現。事件主干如 Apache Kafka就提供上述開箱即用的功能。此外,Kafka Topics 兼作事件和狀態的存儲工作。因此,可以更加容易地恢復處理狀態。此外,即便在集群丟失好幾個節點的情況下,通過Kafka 和 Ignite 的復制和重新調整功能也讓系統具備持續處理事件的能力。
- 高可觀察性- 系統的每個組件都被檢測起來,實時性能和資源利用率指標信息會被以流式的方式傳遞到 Prometheus 中。而 Grafana 會與Prometheus合作完成數據可視化和報警通知的工作。
- 彈性 – 有多級部署決策來處理彈性問題。每個組件都有多個實例運行在同一個可用區(包括 Kafka)。DR 位置維護在備用的不同可用區中。Kafka 的 active 和 dr 集群之間為 Kafka 啟用了集群級復制。
在下一節,我們將圍繞頂級 NFR – 性能的一些關鍵設計因素進行深入探討。后續我們將發布其他有關 NFR 的設計的文章。
滿足性能要求的設計要點
為了滿足性能要求,在設計和實施過程中需要考慮以下幾點:
性能建模 ——對性能目標有一個清晰的理解是很重要的。性能目標會影響到架構、技術、基礎設施和設計決策。隨著混合云和多云解決方案的日益普及,性能建模變得更加重要。由此產生了許多依賴于性能建模的架構折中方案。性能建模應涵蓋 – 事務/事件清單、工作負載建模(并發性、訪問峰量、不同事務/事件的預期響應時間)和基礎設施建模。構建性能模型有助于創建部署模型(尤其是與可擴展性相關的模型),它有助于搭建架構和設計優化從而減少訪問延遲,也有助于設計性能測試并驗證系統的性能和吞吐量。
避免單體怪物——單體架構的集中處理。這意味著無法獨立縮放不同的組件。事實上,服務的實現也需要使用 SEDA的方式將其分解為松耦合的組件,提供擴展每個組件的能力并使服務更具彈性。每個部署的組件都可以獨立擴展并部署到一個集群中,以提高系統的并發性和彈性。
事件主干的選擇——Event backbone(事件主干)的 選擇會影響系統性能。從性能的角度來看,以下 5個特征顯得尤為重要:
- 消息抽取的性能(特別是使消息持久化。即,將消息寫入到磁盤中)。此外,性能需要始終保持一致。
- 消費者消息消費的性能。
- 擴展能力(即在集群中添加新節點/代理的能力)
- 節點/代理失敗時重新調整所需的時間
- 當消費者實例離開或加入消費者組時重新調整所需的時間
Apache Kafka 是一個不錯的選擇,它在性能、容錯性、可擴展性和可用性等方面都經受住了考驗,因此從眾多候選者中脫穎而出。它能夠輕松面對上面提出的5個特征中的前三個,對于最后 2 點(重新平衡時間),Kafka 的性能處理效果視主題數據量而定。雖然Apache Pulsar 試圖解決這個問題,但是鑒于 Kafka 的良好表現并不會立即切換方案,但我們會密切關注 Apache Pulsar 的發展動向。
善用緩存– 數據庫查詢作為IO操作,其使用開銷是可想而知的。為了避免IO操作的開銷需要善用緩存機制。例如,Redis、Apache Ignite 等都是優秀的緩存實踐。通過使用緩存,可以創建有助于數據查找的“快速數據層”。所有關于數據的讀取操作都會首先訪問緩存,而不是從數據庫或其他遠程服務中獲取數據。流數據處理管道也可以實時地存放(或更新)到緩存。接下來事件處理器只需要引用緩存中的數據即可,而不用查詢數據庫或對記錄系統進行調用。事件處理器先將事件寫入到 Ignite中,然后持久化處理器再將數據異步寫入到數據庫中。這種數據處理方式極大地提高了系統的性能。
在本案例中,我們選擇了 Apache Ignite,因為它具備以下幾個特性:
- 它提供分布式緩存(支持數據分區)
- 水平可擴展
- 符合 ANSI SQL
- 便于使用
- 支持復制——提供一定程度的容錯
- Cloud-Ready(云就緒)
緩存可以持久化。即,緩存數據寫入磁盤。但它會影響性能。不使用 SSD 時,性能損失非常顯著。如果緩存是非持久性的,那么架構需要滿足從數據/事件存儲中重新混合緩存的需求。恢復性能對于減少平均恢復時間至關重要。在我們的架構中——利用 Kafka 主題來補充緩存。它們是我們的事件/狀態存儲。有一個多實例恢復組件,可以從 Kafka 主題中讀取數據并對緩存進行再水化。
配合處理——當事件的生產者、消費者和事件主干配合工作時,系統性能處于最佳狀態。然而,這意味著如果數據中心出現故障——它會導致整個平臺癱瘓。為了避免這種情況的方式可以對事件主干設置復制/鏡像。例如,Kafka MirrorMaker 2 (MM2) 就可用于設置跨數據中心/可用區的復制。
選擇正確的消息格式——對消息進行序列化和反序列化操作的快慢會對性能產生影響。雖然,消息格式有多種選擇,例如,XML、JSON、Avro、Protobuf、Thrift。但是對于本例而言,選擇 Avro的消息格式, 是因為它的緊湊性、序列化/反序列化的性能以及對消息模式演化的支持。
并發相關的決策——在本例的架構設計中,并發的關鍵參數如下:
- Kafka topic(主題)的分區數
- 每個消費組的實例數
- 消費者/生產者實例的線程數
這些參數會對系統吞吐量產生直接影響。在 Kafka 中,每個分區都可以被同一消費組中的單個線程所消費。在 Kafka brokers(代理)中存在多個分區和驅動器,它們有助于事件的傳播,同時也不必擔心消息的順序問題。在資源利用率限制(CPU、內存和網絡)范圍內,擁有多線程的消費者可以在一定程度上對性能提升有所幫助。在同一個消費者組中擁有多個實例從而將負載分攤到多個節點/服務器上,最終提升水平可擴展的能力。
使用分區——分區數越多,并發性越高。但是,在確定分區數時需要注意以下幾個方面的問題。重視分區鍵的選擇,它可以在不破壞事件排序的情況下在分區之間均勻分布事件。此外,在有些情況下過度分區會帶來不良后果,例如:在打開文件句柄的時候、由于broker(代理)故障造成 Kafka topic(主題)不可用的時候、端點延遲的時候以及消費者對內存有更高需要的時候。
執行性能測試從而定義系統性能的標準,通過測試推斷出所需的吞吐量和性能,它們有助于確定并發的 3 個關鍵參數的配置。
I/O 問題需要重視——I/O操作對系統延遲的影響很大,甚至說它影響到架構中的所有組件,包括事件主干、緩存、數據庫和應用程序組件。
對于使用了持久化的分布式緩存組件而言,I/O操作是影響性能的關鍵因素之一。例如,對于 Apache Ignite - 強烈建議使用 SSD(固態硬盤)并且開啟direct(直接) I/O模式,從而獲得良好的性能。非持久性緩存無疑是最快的緩存方案——但是缺點也很明顯,一旦緩存集群出現故障,緩存數據將會丟失。雖然,可以通過恢復過程來解決該問題 - 重新恢復緩存。然而,需要引起注意的是隨著恢復時間變長——流媒體管道中的延遲也會變大。除非,緩存的恢復過程必須非常快。因此,需要通過運行多個恢復實例同時還要避免任何轉換/業務邏輯的操作。
Kafka 不一定需要高性能磁盤(如 SSD)。建議使用多驅動器(和多個日志目錄)從而獲得良好的吞吐量。這里不建議與應用程序以及操作系統共享驅動器。此外,諸如配置“ noatime ”之類的掛載選項可以提升性能。下面鏈接討論了依賴于文件系統類型的其他掛載項:??https : //kafka.apache.org/documentation.html#diskandfs??
從應用程序的角度來看 - 將日志記錄保持在最低限度。專注于記錄異常信息而不是面面俱到。盡管大多數日志框架都能夠進行異步記錄,但仍然會對延遲產生影響。
內存調優——事件流架構在很大程度上依賴于內存調優。對于 Kafka brokers(代理)和 Apache Ignite 服務器節點尤為如此。因此為處理器、消費者、Kafka 代理以及內存數據網格節點分配足夠的內存空間就顯得非常重要。
調整操作系統的內存設置也有助于在一定程度上提高性能。關鍵參數之一是“ vm.swappiness”。它負責控制進程在內存中的交換。它的值介于 0 和 100 之間的值,數字越大,就表示內存交換越積極。建議將此數字保持在較低水平以減少交換。
在 Kafka 的使用場景下,由于它嚴重依賴頁面緩存,因此也可以調整“ vmdirty ratio”選項來控制數據刷新到磁盤的比例。
網絡優化 ——為了有效利用網絡,建議對大容量消息進行壓縮,因為這個大家伙會降低網絡利用率。但是對于大容量消息的壓縮可以提升生產者、消費者以及代理的CPU 利用率。例如,Kafka 支持 4 種不同的壓縮類型(gzip、lz4、snappy、zstd)。Snappy 的壓縮類型讓CPU 使用率、壓縮率、速度和網絡利用率處在折中的位置,讓它們之間保持一種平衡關系。
關注相關消息——在發布訂閱機制中,消費者有可能獲得他們不感興趣的消息,因此可以添加過濾器從而過濾掉他們不感興趣的消息,讓更多的注意力放到相關的消息上。即便如此仍然需要對事件進行反序列化后才能對時間內容進行過濾,為了提高效率避免無效的反序列化操作,可以通過在事件的標題中添加事件元數據來對事件進行描述。消費者通過查看事件標頭來決定是否對事件進行反序列化,并解析其中的內容。這種做法明顯提高了消費者處理事件的吞吐量并降低了對資源的使用,提升資源利用率。
解析需要的內容(尤其是 XML)– 在金融服務行業 – XML 被大量使用,事件流應用程序的輸入很可能就是 XML。然而,解析 XML屬于CPU 和內存密集型的操作。因此,XML 解析器的選擇是與性能和資源利用率相關的重要決策。針對大 XML 文檔的解析,建議使用 SAX 解析器。如果事件流應用程序不需要解析完全XML文檔,可以預先配置 xpath 來定位到所需數據,然后通過數據構建事件負載,這樣可能是一個更快的選擇。但是,如果需要解析整個XML 數據——那么最好一次性解析整個文檔并將其轉換為事件流應用程序的消息格式,解析的操作使用處理器的多個實例完成,而不是讓事件流管道中的每個處理器解析XML文檔。
監控和識別性能瓶頸的工具——識別性能瓶頸應該是一件很容易的事情。可以通過使用輕量級檢測框架(基于 AOP)來進行識別工作。在案例中,我們將 AOP 與 Spring-Boot Actuator 和 Micrometer 進行組合,并將接口暴露給Prometheus 端點。對于 Apache Kafka性能指標的采集,使用 Prometheus 的 JMX 導出器來完成。接著就是用 Grafana 構建一個內容豐富的儀表板,上面可以顯示生產者、消費者、Kafka 以及 Ignite(基本包括架構的所有組件)的性能指標。
上面這一系列的操作提供了快速查詢和展示瓶頸的能力,并不需要對日志進行分析,也不用將應用與日志進行關聯。
對Kafka配置進行微調 ——Kafka 有大量的配置參數用于代理、生產者、消費者和 Kafka 流信息。以下是用來配置Kafka 延遲和吞吐量的參數:
- Broker(代理)
- log.dirs – 在不同驅動器上設置多個目錄以加快 I/O讀寫速度。
- num.network.threads
- num.io.threads
- num.replica.fetchers
- socket.send.buffer.bytes
- socket.receive.buffer.bytes
- socket.request.max.bytes
- group.initial.rebalance.delay.ms
- Producer(消息生產者)
- linger.ms
- batch.size
- buffer.memory
- compression.type
- Consumer(消息消費者)
- fetch.min.bytes - 如果設置為默認值 1,它將改善延遲但吞吐量不會很好。所以一定要做好平衡。
- max.poll.records
- Streams(流)
- num.stream.threads
- buffered.records.per.partition
- cache.max.bytes.buffering
有關調整 Kafka 代理、生產者和消費者的其他信息,請參閱提供的參考資料。
GC調優 – 垃圾收集器的調優對避免長時間停頓和過多的 GC 開銷也顯得尤為重要。從 JDK 8 開始,建議大多數應用程序(具有大內存的多處理器機器)使用Garbage-First Garbage Collector (G1GC) 模式。這種模式試圖實現暫停時間目標并試圖實現高吞吐量。此外,在啟動的時候不需要太多的配置。
我們確保為 JVM 擁有足夠的內存。在 使用Ignite時,會通過堆外內存來存儲數據。
-Xms 和 -Xmx 與“-XX:+AlwaysPreTouch”保持相同的值,以確保在啟動期間從操作系統分配所有內存。
G1GC 中還有其他參數,例如以下可用于進一步調整吞吐量(因為在 EDA 中吞吐量很重要):
- -XX:MaxGCPauseMillis(增加其值以提高吞吐量)
- -XX:G1NewSizePercent, -XX:G1MaxNewSizePercent
- -XX:ConcGCThreads
更多細節請參考??調優 G1GC??。
調整 Apache Ignite – Apache Ignite 調整在其??官方網站??上有詳細記錄。以下是我們為提高其性能而采取的一些措施:
- 80%:20% 原則,同時為 Ignite 服務器節點分配內存(80% 分配給 Ignite 進程。20% 保留給操作系統)
- 使用 zookeeper 進行集群發現
- 使用堆外內存來存儲數據
- 至少為 JVM 堆分配了 16GB
- 根據需求將堆外劃分為不同的數據區域(引用數據區域、輸入數據區域、輸出數據區域等)
- 引用數據保存在“副本”緩存中
- 輸入/輸出(即事務數據)保存在“分區”緩存中。
- 確保每個緩存都定義了一個關聯鍵,該鍵始終用于并置處理的查詢
- 使用上一節中的配置指南調整 JVM GC
- 將緩存組用于邏輯相關的數據
- 在 JDBC 驅動程序中啟用“延遲”加載
- 正確調整不同線程池的大小以提高性能
- 使用 JCache API 代替 SQL 查詢
- 確保游標關閉
- 使用“NearCache”配置獲取引用數據——這樣查找它的時候就不需要通過客戶端從遠程服務器獲取了。
- 增加索引的內聯大小
- 將 vm.swappiness 減少到 1
- 使用 Direct- IO
- 引用數據緩存啟用了本機持久化機制。但是,事務緩存不用開啟持久化機制,因為事務緩存需要備份在 Kafka 上。在集群網絡中斷的情況下,事務數據使用單獨的恢復處理器從 Kafka 恢復到 Ignite中。
結論
在本文中,我們專注于與性能相關的架構決策。因此保持架構每個組件的性能顯得非常重要,因為任何組件的問題都可能導致流信息阻塞。因此,架構的每個組件都需要在不影響其他 NFR 的情況下針對性能進行調優。所以對這些組件有深入的技術理解是必不可少的,只有這樣才能有效地進行調優工作。
譯者介紹
崔皓,51CTO社區編輯,資深架構師,擁有18年的軟件開發和架構經驗,10年分布式架構經驗。曾任惠普技術專家。樂于分享,撰寫了很多熱門技術文章,閱讀量超過60萬。??《分布式架構原理與實踐》??作者。
原文標題:Designing High-Volume Systems Using Event-Driven Architectures,作者:Ram Ravishankar,Harish Bharti,Tanmay Ambre
【51CTO譯稿,合作站點轉載請注明原文譯者和出處為51CTO.com】