













Spark 性能調優核心原理,你會嗎?
用了這么久spark了,今天總結下他的一些優化方面的核心原理,今天我們分這么幾個方面來談:
一.RDD
RDD是彈性分布式數據集的簡稱,他是其他后來者,比如DataFrame,DataSet等的基礎。他有四大核心屬性,如下所示。
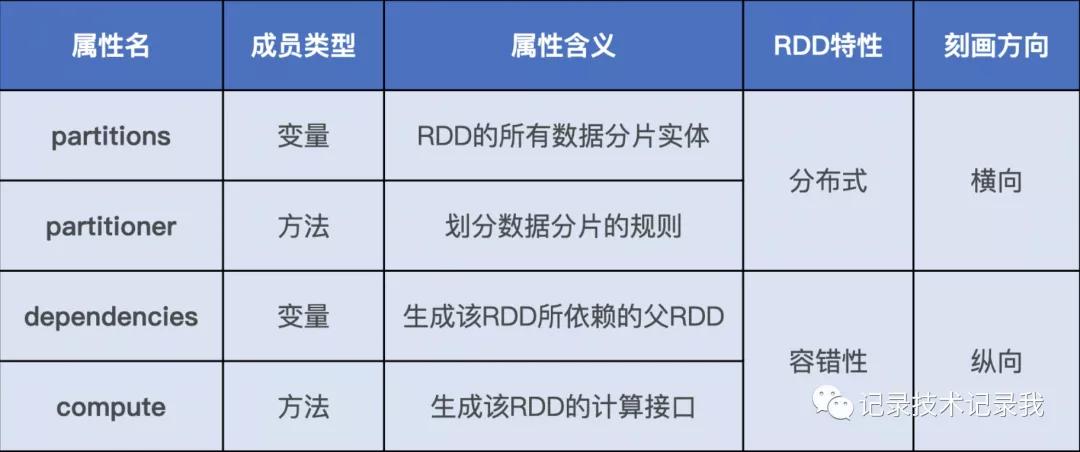
這4 大屬性又可以劃分為兩類,橫向屬性和縱向屬性。其中,橫向屬性錨定數據分片實體,并規定了數據分片在分布式集群中如何分布。
縱向屬性用于在縱深方向構建 DAG,通過提供重構 RDD 的容錯能力保障內存計算的穩定性。
其實RDD還有個特性:優先位置列表.算上他總共有5大特性。白話文總結就是:3個列表,2個函數。3個列表是分區列表,依賴列表和優先位置列表;2個函數就是:計算函數和分區函數。
二.內存計算
在 Spark 中,內存計算有兩層含義:第一層含義就是眾所周知的分布式數據緩存,第二層含義是 Stage 內的流水線式計算模式。
流水線計算模式指的是:在同一 Stage 內部,所有算子融合為一個函數,Stage 的輸出結果由這個函數一次性作用在輸入數據集而產生。
所謂內存計算,不僅僅是指數據可以緩存在內存中,更重要的是,通過計算的融合來大幅提升數據在內存中的轉換效率,進而從整體上提升應用的執行性能。
比如這個栗子:
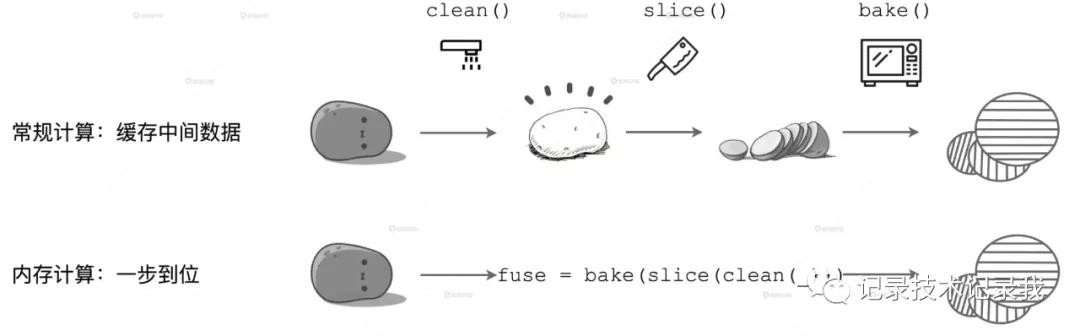
如圖所示,在上面的計算流程中,如果你把流水線看作是內存,每一步操作過后都會生成臨時數據,如圖中的 clean 和 slice,這些臨時數據都會緩存在內存里。但在下面的內存計算中,所有操作步驟如 clean、slice、bake,都會被捏合在一起構成一個函數。這個函數一次性地作用在“帶泥土豆”上,直接生成“即食薯片”,在內存中不產生任何中間數據形態。
補充下:從程序員的視角出發,DAG 的構建是通過在分布式數據集上不停地調用算子來完成的,DAG 以 Actions 算子為起點,從后向前回溯,以 Shuffle 操作為邊界,劃分出不同的 Stages。同一 Stage 內所有算子融合為一個函數,Stage 的輸出結果由這個函數一次性作用在輸入數據集而產生。













