英偉達神秘「變形」GPU曝光!5nm工藝,兩種形態隨心變
近日,在英偉達團隊發表的新論文中提到了一個神秘的顯卡:GPU-N。
據網友推測,這很可能就是下一代Hopper GH100芯片的內部代號。

https://dl.acm.org/doi/10.1145/3484505
英偉達在這篇「GPU Domain Specialization via Composable On-Package Architecture」(通過可組合式封裝架構實現GPU領域的專業化)的論文中,談到了下一代GPU設計。
研究人員認為,當前要想提升深度學習性能,最實用的解決方案應該是最大限度地提高低精度矩陣計算的吞吐量。
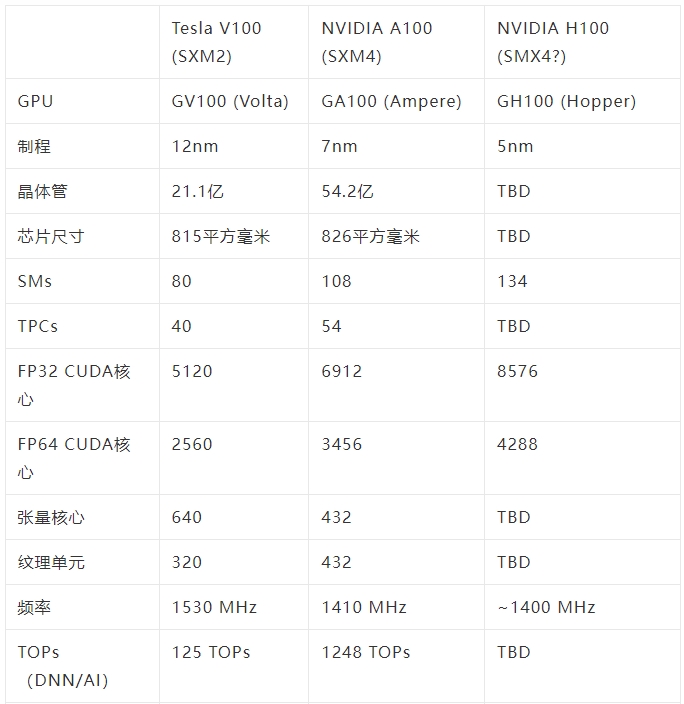
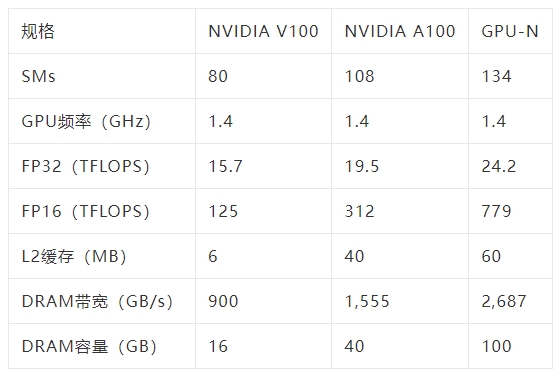
簡單來說,GPU-N有134個SM單元(A100中為104個SM);8576個CUDA核心(比A100多24%);60MB的二級緩存(比A100多50%);2.687TB/秒的DRAM帶寬(可擴展至6.3TB/秒);高達100GB的HBM2e(通過COPA實現可擴展到233GB),以及6144位內存總線。
全新COPA-GPU架構
「GPU-N」采用了一種叫COPA的設計。
目前,當GPU以擴大其低精度矩陣計算吞吐量的方式來提高深度學習(DL)性能時,吞吐量和存儲系統能力之間的平衡會被打破。
英偉達團隊最終得出一個結論,基于FP32(或更大)的HPC和基于FP16(或更小)的DL,兩者的工作負載是不一樣的。那么,運行兩種任務的GPU架構也不應該完全一樣。
而如果非得要求GPU滿足不同的架構要求,去做一個融合設計,會導致任何一個應用領域的配置都不是最優的。
因此,可以給每個領域提供專用的GPU產品的可組合的(COPA-GPU)架構是解決這些不同需求的最實用的方案。
COPA-GPU利用多芯片模塊分解,可以做到最大限度地支持GPU模塊復用,以及每個應用領域的內存系統定制化。
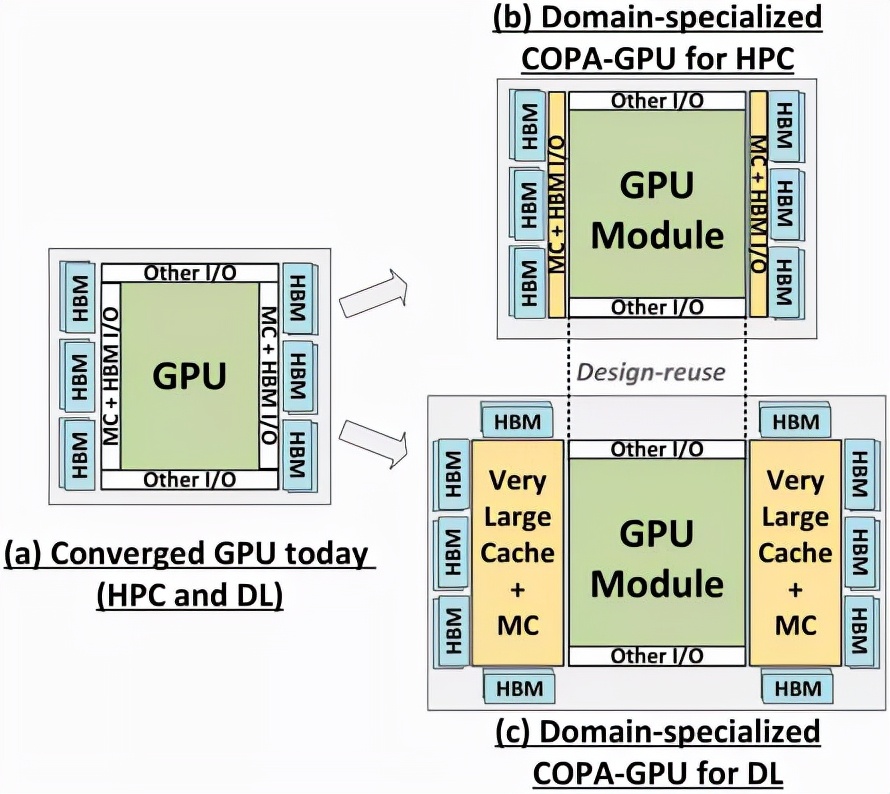
英偉達表示,COPA-GPU可以通過對基線GPU架構進行模塊化增強,使其具有高達4倍的片外帶寬、32倍的包內緩存和2.3倍的DRAM帶寬和容量,同時支持面向HPC的縮減設計和面向DL的專業化產品。
這項工作探索了實現可組合的GPU所必需的微架構設計,并評估了可組合架構為HPC、DL訓練和DL推理提供的性能增益。
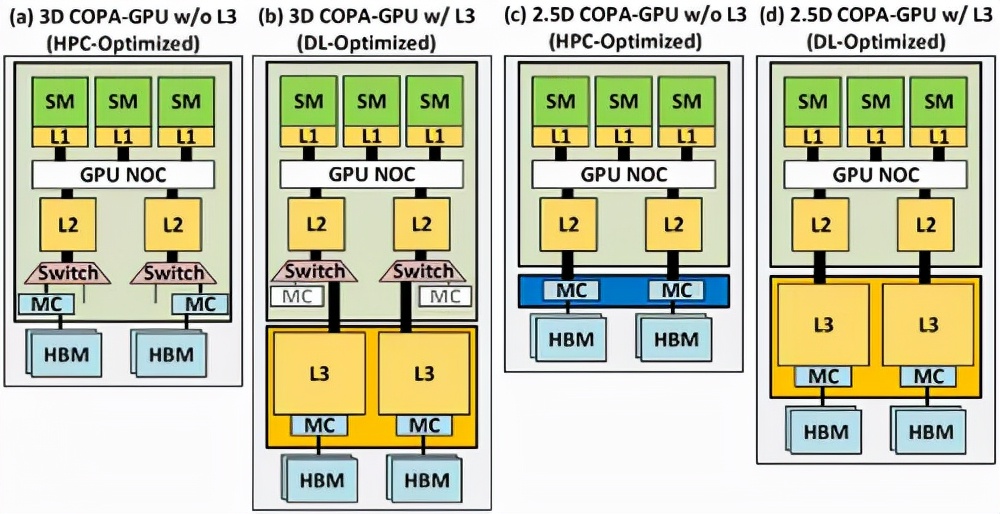
實驗表明,與一個融合的GPU設計相比,一個對DL任務進行過優化的COPA-GPU具有16倍大的緩存容量和1.6倍高的DRAM帶寬。
每個GPU的訓練和推理性能分別提高了31%和35%,并在擴展的訓練場景中減少了50%的GPU使用數量。
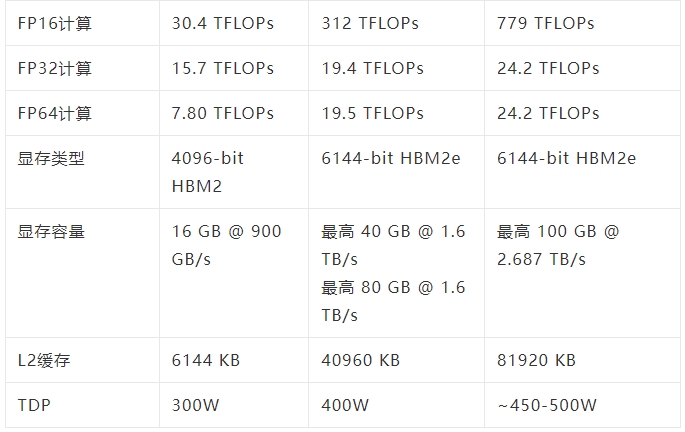
從紙面上的性能來看,「GPU-N」的時鐘頻率為1.4GHz(與A100的理論值相同),可以達到24.2 TFLOPs的FP32(是A100的1.24倍)和779 TFLOPs的FP16(是A100的2.5倍)。
與AMD的MI200相比,GPU-N的FP32的性能還不到一半(95.7 TFLOPs vs 24.2 TFLOPs),但GPU-N的FP16的性能卻高出2.15倍(383TFLOPs vs 779TFLOPs)。
根據以往的信息可以推斷,NVIDIA的H100加速器將基于MCM解決方案,并且會基于臺積電的5nm工藝。
雖然不知道每個SM中的核心數量,但如果依然保持64個的話,那么最終就會有18,432個核心,比GA100多2.25倍。
Hopper還可以利用更多的FP64、FP16和Tensor內核,這將極大地提高性能。
GH100很可能會在每個GPU模塊上啟用144個SM單元中的134個。但是,如果不使用GPU稀疏性,英偉達不太可能達到與MI200相同的FP32或FP64 Flops。
此外,論文中還談到了兩種基于下一代架構的領域專用COPA-GPU,一種用于HPC,一種用于DL領域。
HPC變體采用的是非常標準的設計方案,包括MCM GPU設計和各自的HBM/MC+HBM(IO)芯片,但DL變體真的是一個很特殊的設計。
DL變體在一個完全獨立的芯片上安裝了一個巨大的緩存,與GPU模塊相互連接。具有高達960/1920 MB的LLC(Last-Level-Cache),HBM2e DRAM容量也高達233GB,帶寬高達6.3TB/s。
但是網友表示,英偉達似乎已經決定將重點放在DL性能上,因為FP32和FP64(HPC)性能的增長僅僅是來源于SM數量的增加。
這很可能在最后達不到傳聞中的3倍性能。
鑒于英偉達已經發布了相關的信息,Hopper顯卡很可能會在2022年GTC的大會上亮相。
規格預測