聊聊 Kafka: Consumer 源碼解析之 Rebalance 機制
一、前言
我們上一篇分析了 Consumer 如何加入 Consumer Group,其實上一篇是一個很宏觀的東西,主要講 ConsumerCoordinator 怎么與 GroupCoordinator 通信。等等,老周,ConsumerCoordinator 和 GroupCoordinator 是個啥玩意?這兩個組件分別是 Consumer、Kafka Broker 的協調器,說白了就是我們設計模式中的門面模式,具體的內容可以看上一篇回顧下。今天這一篇主要講上一篇 Consumer 如何加入 Consumer Group 中的 Rebalance 機制,其實上一篇講了大概了,這一篇更深入的來說一說 Rebalance 機制的具體細節。
如果你是一個有一定經驗的程序員,Rebalance 機制我覺得可以作為一道面試題來考察,而且還是有一定難度的。但是也不需要妄自菲薄,跟著老周的這篇文章下來,相信你一定可以拿下它的。
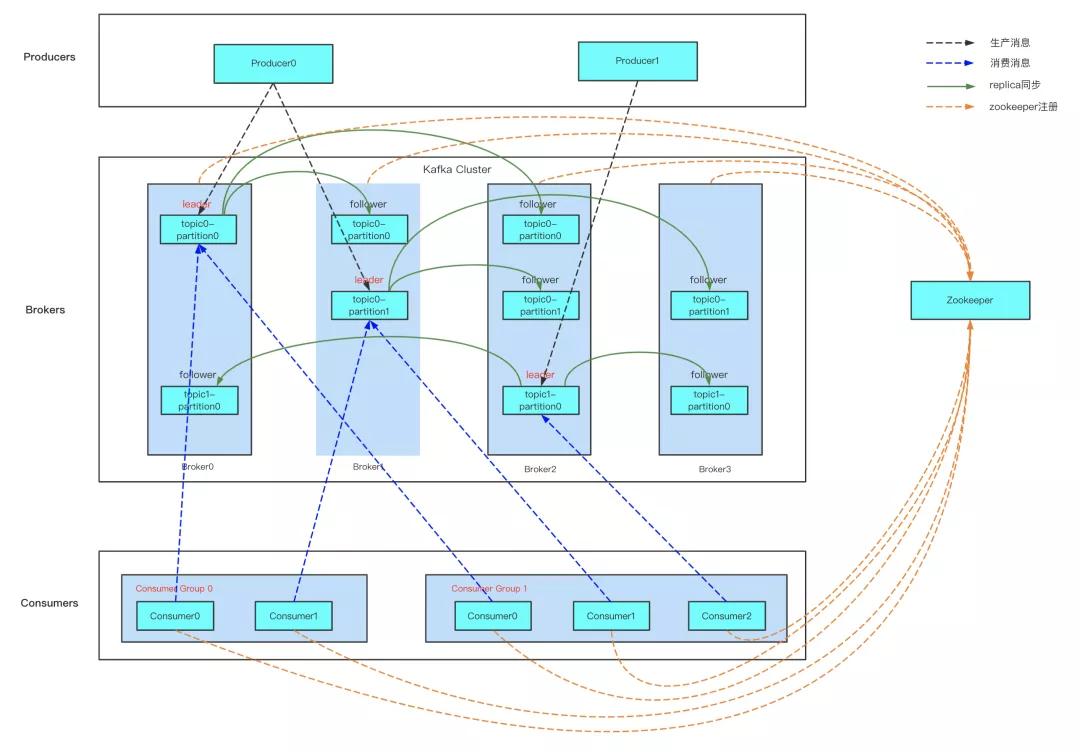
但有些讀者確實覺得還是有一定難度,別著急,先看下下面 Kafka 的拓撲結構,這個結構很清晰了吧,如果你對 Kafka 的拓撲結構還不了解,那我建議你先別往下看了,先把 Kafka 的拓撲結構搞清楚,或者先看老周前面的幾篇文章再來繼續閱讀,我覺得效果會更好。
這一篇主要從以下幾點來聊一聊 Rebalance 機制:
- 什么是 Rebalance 機制?
- 觸發 Rebalance 機制的時機
- Group 狀態變更
- 舊版消費者客戶端的問題
- Rebalance 機制的原理
- Broker 端重平衡場景
二、什么是 Rebalance 機制?
Rebalance 本質上是一種協議,規定了一個 Consumer Group 下的所有 Consumer 如何達成一致,來分配訂閱 Topic 的每個分區。
當集群中有新成員加入,或者某些主題增加了分區之后,消費者是怎么進行重新分配消費的?這里就涉及到重平衡(Rebalance)的概念,下面我就給大家講解一下什么是 Kafka 重平衡機制。
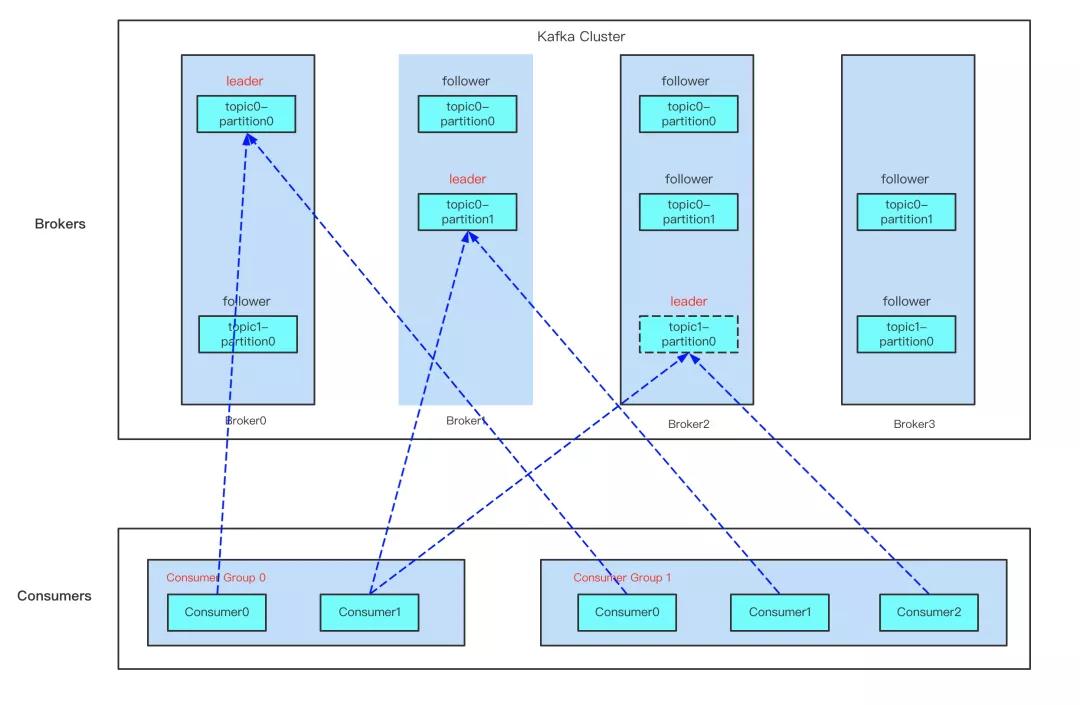
從圖中可以找到消費組模型的幾個概念:
- 同一個消費組,一個分區只能被一個消費者訂閱消費,但一個消費者可訂閱多個分區,也就是說每條消息只會被同一個消費組的某一個消費者消費,確保不會被重復消費;
- 一個分區可被不同消費組訂閱,這里有種特殊情況,假如每個消費組只有一個消費者,這樣分區就會廣播到所有消費者上,實現廣播模式消費。
要想實現以上消費組模型,那么就要實現當外部環境變化時,比如主題新增了分區,消費組有新成員加入等情況,實現動態調整以維持以上模型,那么這個工作就會交給 Kafka 重平衡(Rebalance)機制去處理。
從圖中可看出,Kafka 重平衡是外部觸發導致的,下面來看下觸發 Kafka 重平衡的時機有哪些。
三、觸發 Rebalance 機制的時機
- 有新的 Consumer 加入 Consumer Group
- 有 Consumer 宕機下線。Consumer 并不一定需要真正下線,例如遇到長時間的 GC、網絡延遲導致消費者長時間未向 GroupCoordinator 發送 HeartbeatRequest 時,GroupCoordinator 會認為 Consumer 下線。
- 有 Consumer 主動退出 Consumer Group(發送 LeaveGroupRequest 請求)。比如客戶端調用了 unsubscribe() 方法取消對某些主題的訂閱。
- Consumer 消費超時,沒有在指定時間內提交 offset 偏移量。
- Consumer Group 所對應的 GroupCoordinator 節點發生了變更。
- Consumer Group 所訂閱的任一主題或者主題的分區數量發生變化。
四、Group 狀態變更
4.1 消費端
在 Consumer 側的門面 ConsumerCoordinator,它繼承了 AbstractCoordinator 抽象類。在協調器 AbstractCoordinator 中的內部類 MemberState 中我們可以看到協調器的四種狀態,分別是未注冊、重分配后沒收到響應、重分配后收到響應但還沒有收到分配、穩定狀態。
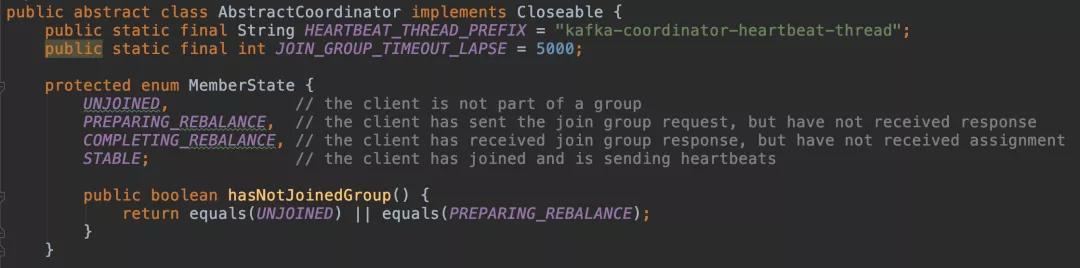
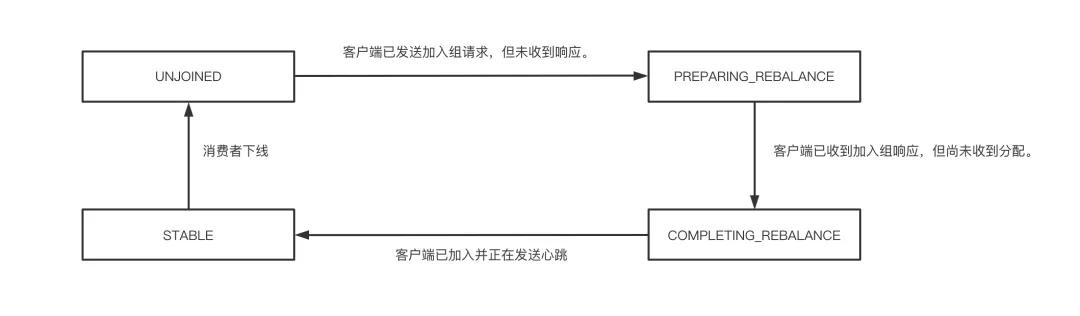
上述消費端的四種狀態的轉換如下圖所示:
4.2 服務端
對于 Kafka 服務端的 GroupCoordinator 則有五種狀態 Empty、PreparingRebalance、CompletingRebalance、Stable、Dead。他們的狀態轉換如下圖所示:


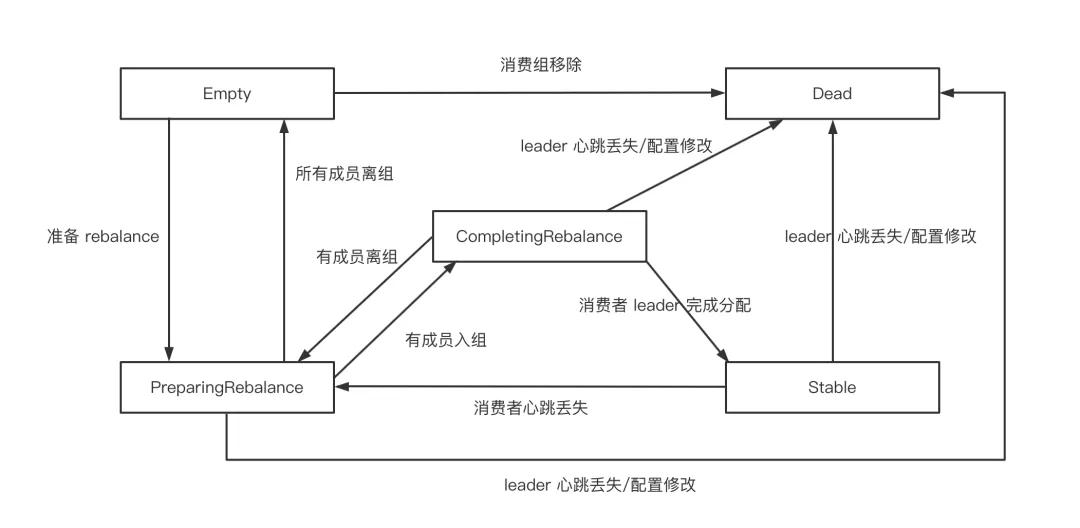
- 一個消費者組最開始是 Empty
- 重平衡開啟后,會置于 PreparingRebalance 等待成員加入。
- 之后變更到 CompletingRebalance 等待分配方案
- 最后流轉到 Stable 完成 Rebalance
- 當有成員變動時,消費者組狀態從 Stable 變為 PreparingRebalance。
- 此時所有現存成員需要重新申請加入組
- 當所有組成員都退出組后,消費者組狀態為 Empty。
- 消費者組處于 Empty 狀態,Kafka 會定期自動刪除過期 offset。
五、舊版消費者客戶端的問題
ConsumerCoordinator 與 GroupCoordinator 的概念是針對 Kafka 0.9.0 版本后的消費者客戶端而言的,我們 暫且把 Kafka 0.9.0 版本之前的消費者客戶端稱為舊版消費者客戶端。舊版消費者客戶端是使用 Zookeeper 的監聽器(Watcher)來實現這些功能的。
每個消費組
下圖與 /consumers/
- /consumers//owners 路徑下記錄了分區和消費者的對應關系
- /consumers//offsets 路徑下記錄了此消費組在分區中對應的消費位移
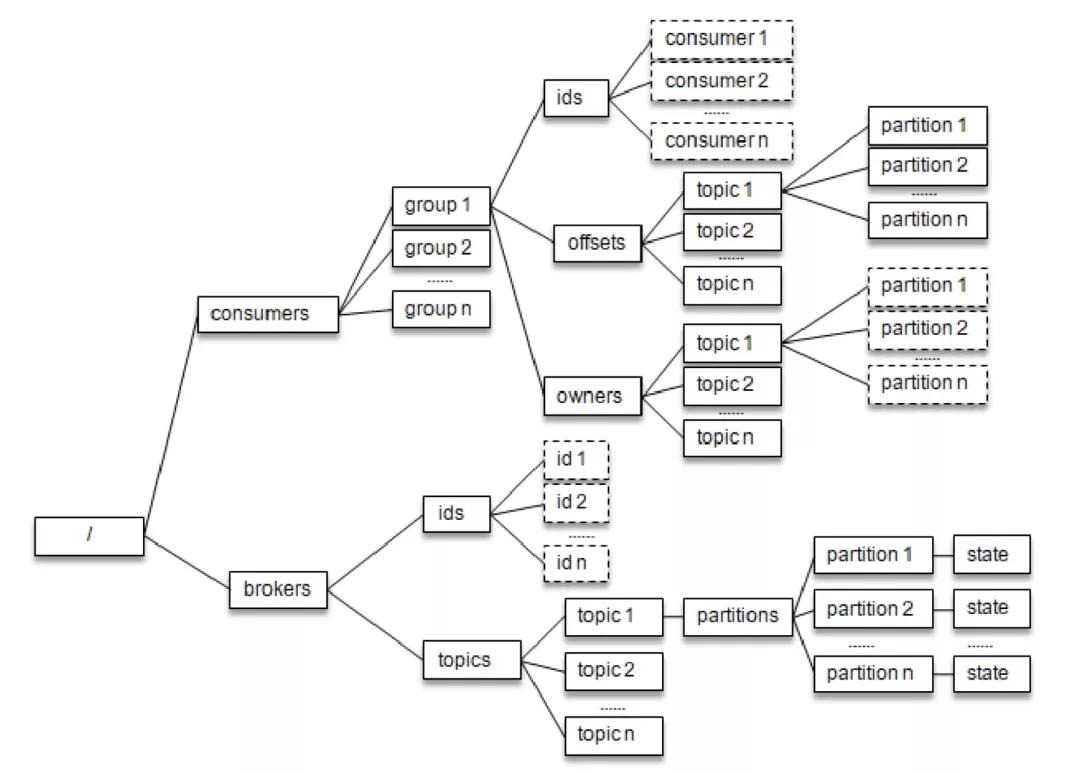
每個 broker、主題和分區在 Zookeeper 中也都對應一個路徑:
- /brokers/ids/記錄了 host、port 及分配在此 broker 上的主題分區列表;
- /brokers/topics/ 記錄了每個分區的 leader 副本、ISR 集合等信息。
- /brokers/topics//partitions//state 記錄了當前 leader 副本、leader epoch 等信息。
每個消費者在啟動時都會在 /consumers/
這種方式下每個消費者對 Zookeeper 的相關路徑分別進行監聽,當觸發再均衡操作時,一個消費組下的所有消費者會同時進行再均衡操作,而消費者之間并不知道彼此操作的結果,這樣可能導致 Kafka 工作在一個不正確的狀態。與此同時,這種嚴重依賴于 Zookeeper 集群的做法還有兩個比較嚴重的問題。
- 羊群效應(Herd Effect):所謂的羊群效應是指 Zookeeper 中一個被監聽的節點變化,大量的 Watcher 通知被發送到客戶端,導致在通知期間的其他操作延遲,也有可能發生類似死鎖的情況。
- 腦裂問題(Split Brain):消費者進行再均衡操作時每個消費者都與 Zookeeper 進行通信以判斷消費者或 broker 變化的情況,由于 Zookeeper 本身的特性,可能導致在同一時刻各個消費者獲取的狀態不一致,這樣會導致異常問題發生。
六、Rebalance 機制的原理
Kafka 0.9.0 版本后的消費者客戶端對此進行了重新設計,將全部消費組分成多個子集,每個消費組的子集在服務端對應一個 GroupCoordinator 對其進行管理,GroupCoordinator 是 Kafka 服務端中用于管理消費組的組件。而消費者客戶端中的 ConsumerCoordinator 組件負責與 GroupCoordinator 進行交互。
- Rebalance 完整流程需要 Consumer & Coordinator 共同完成
- Consumer 端 Rebalance 步驟
- 加入組:對應 JoinGroup 請求
- 等待 Leader Consumer 分配方案:對應 SyncGroup 請求
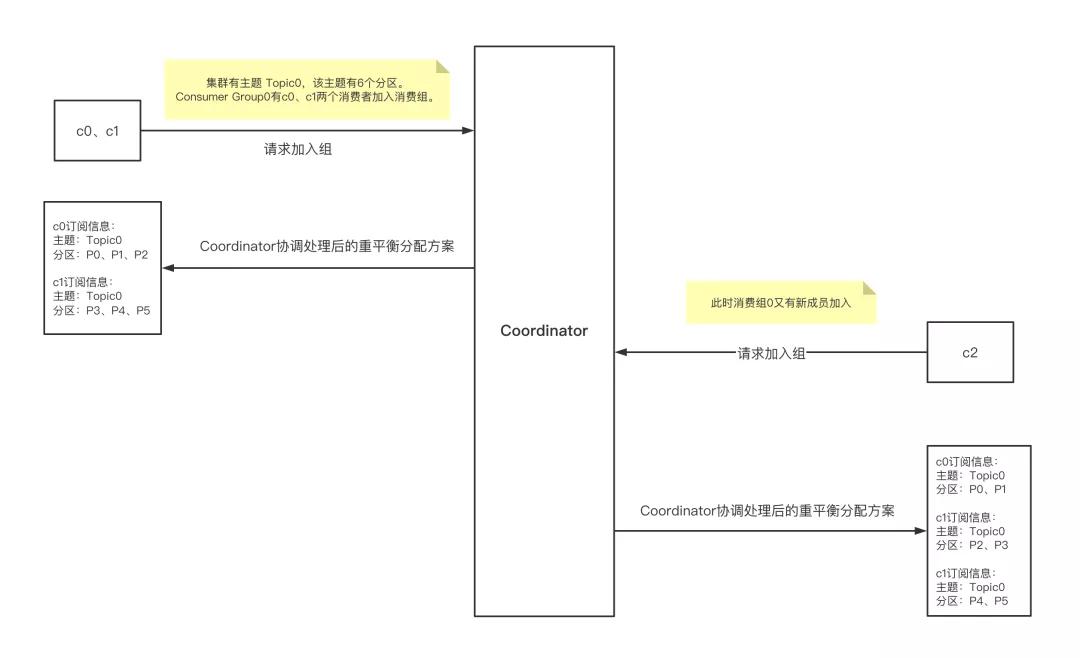
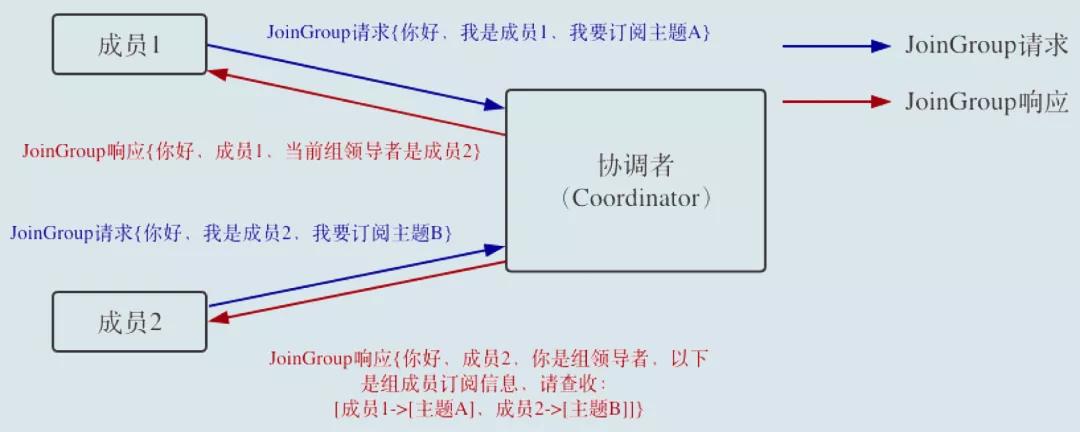
- 當組內成員加入組時,Consumer 向協調者發送 JoinGroup 請求。
- 每個 Consumer 會上報自己訂閱的 topic
- Coordinator 收集到所有 JoinGroup 請求后,從這些成員中選擇一個擔任消費者組的 Leader
- 通常第一個發送 JoinGroup 請求的自動成為 Leader
- Leader Consumer 的任務是收集所有成員的 topic,根據信息制定具體的 partition consumer 分配方案。
- 選出 Leader 后,協調者把所有 topic 信息封裝到 JoinGroup Response 中,發送給 Leader。
- Leader Consumer 做出統一分配方案,進入到 SyncGroup 請求。
- Leader Consumer 向協調者發送 SyncGroup,將分配方案發給協調者。
- 其他成員也會發出 SyncGroup 請求
- 協調者以 SyncGroup Response 的方式將方案下發給所有成員
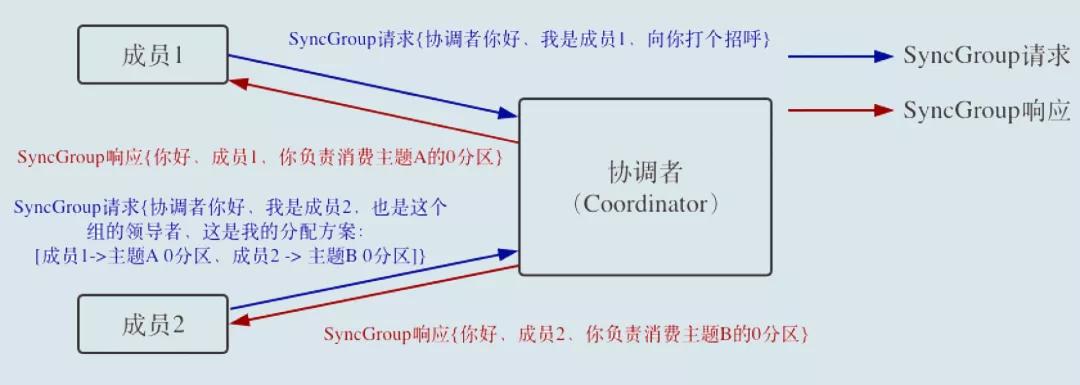
- 所有成員成功接收到分配方案,消費者組進入 Stable 狀態,開始正常消費。
具體的源碼分析,可以看我上一篇分析的 Consumer 如何加入 Consumer Group 文章。
七、Broker 端重平衡場景
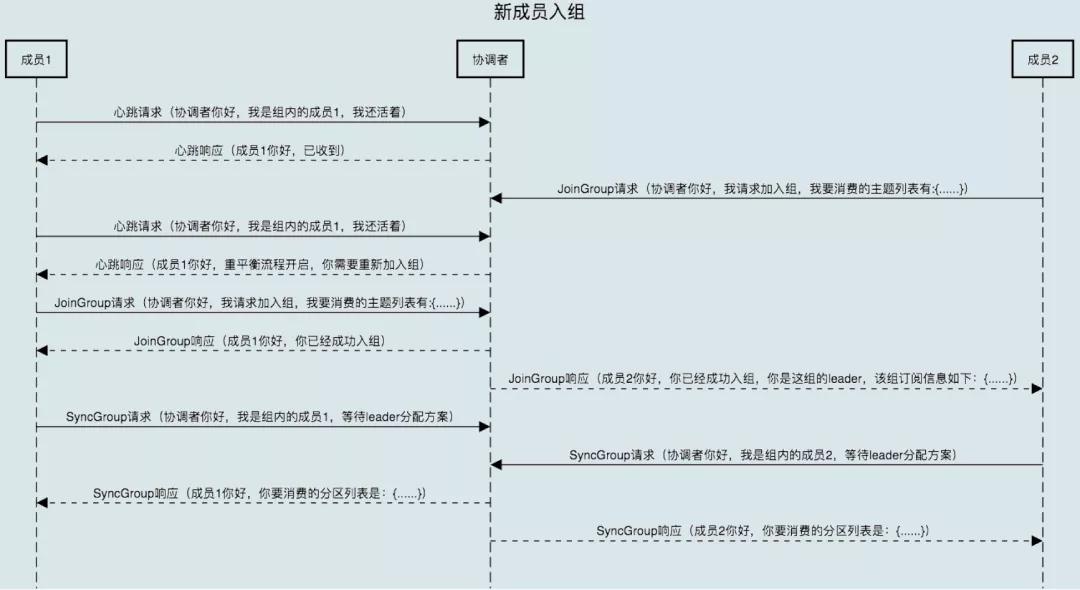
7.1 新成員加入
消費者組處于 Stable 之后有新成員加入
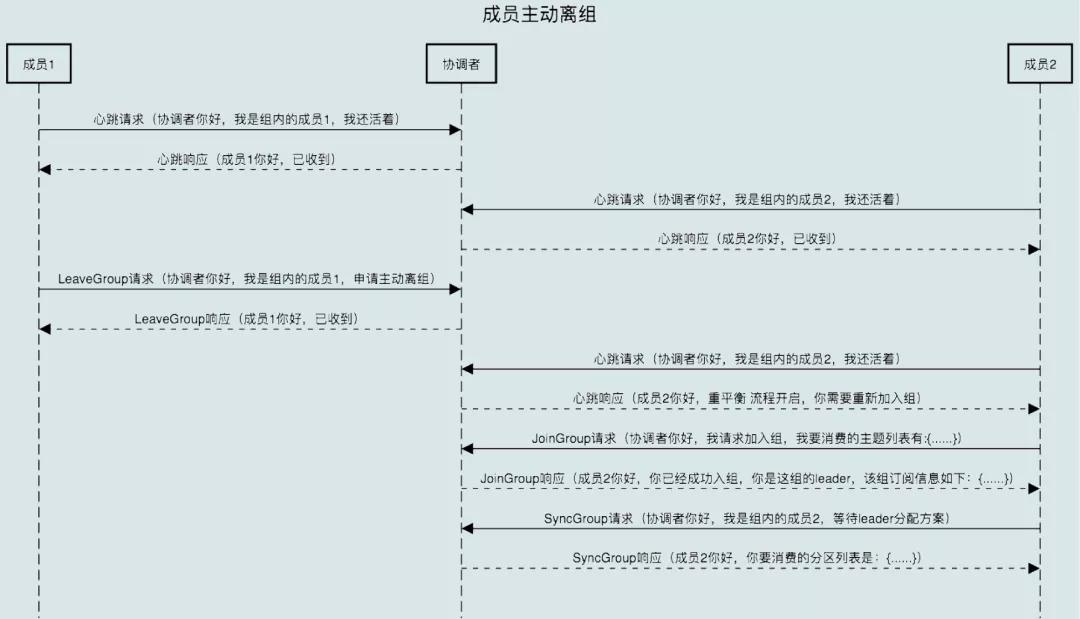
7.2 組成員主動離開
- 主動離開:Consumer Instance 通過調用 close() 方法通知協調者退出
- 該場景涉及第三個請求:LeaveGroup 請求
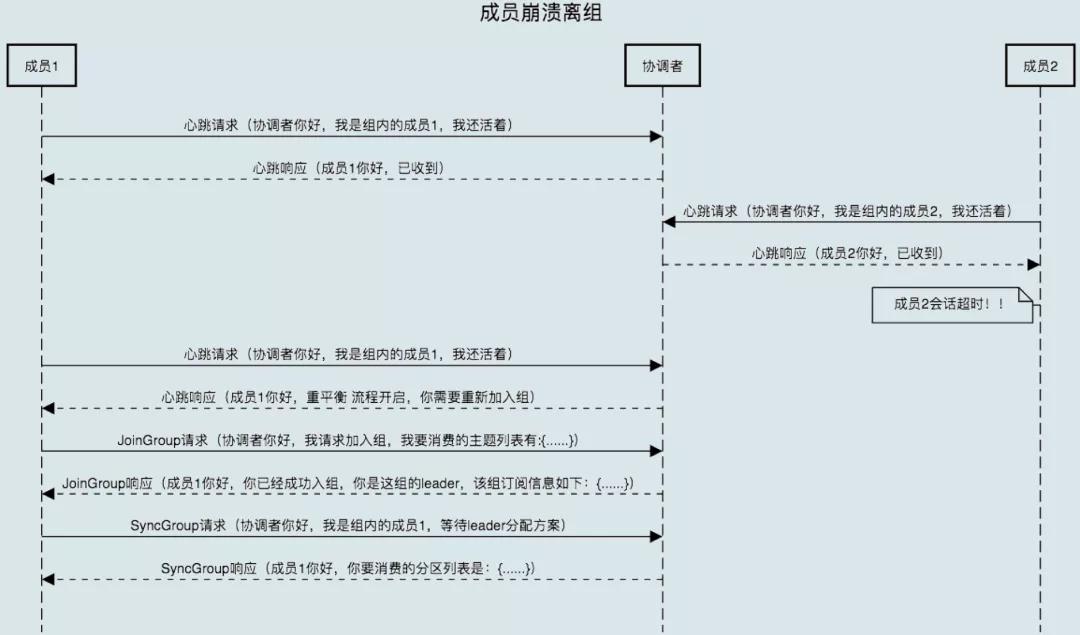
7.3 組成員崩潰離開
- 協調者需要等待一段時間才能感知
- 這個時間段由 Consumer 端參數 sessionn.timeout.ms 控制
- Kafka 不會超過上述參數時間感知崩潰
- 處理流程相同
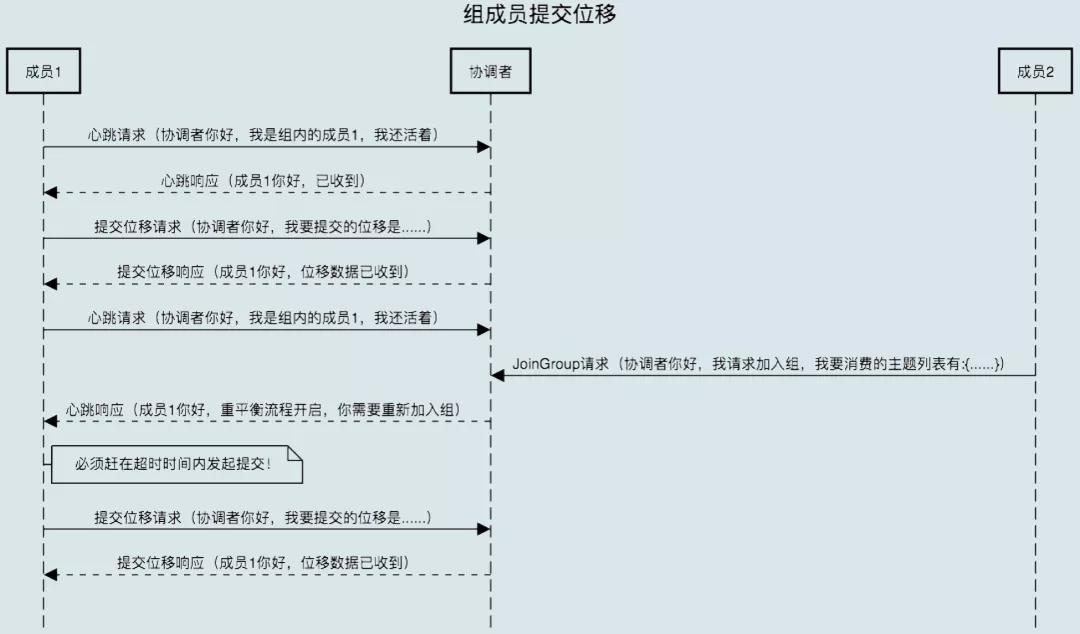
7.4 Rebalance 時組成員提交 offset
- Rebalance 開啟時,協調者會給予成員一段緩沖時間,要求每個成員在這段時間內快速上報自己的 offset。
- 再開啟正常的 JoinGroup/SyncGroup 請求
好了,Rebalance 機制就先說這么多了,下一篇會來聊一聊如何避免重平衡。
本文轉載自微信公眾號「老周聊架構」,可以通過以下二維碼關注。轉載本文請聯系老周聊架構公眾號。