全鏈路觀測平臺設計點歸納

引言
全鏈路觀測平臺設計離不開基礎數據的采集、提煉和呈現。本文就基礎數據日志、指標、鏈路的采集原理進行梳理,如何將其關聯最終提供輔助決策價值提點歸納。
一、數據采集
1.日志架構簡圖
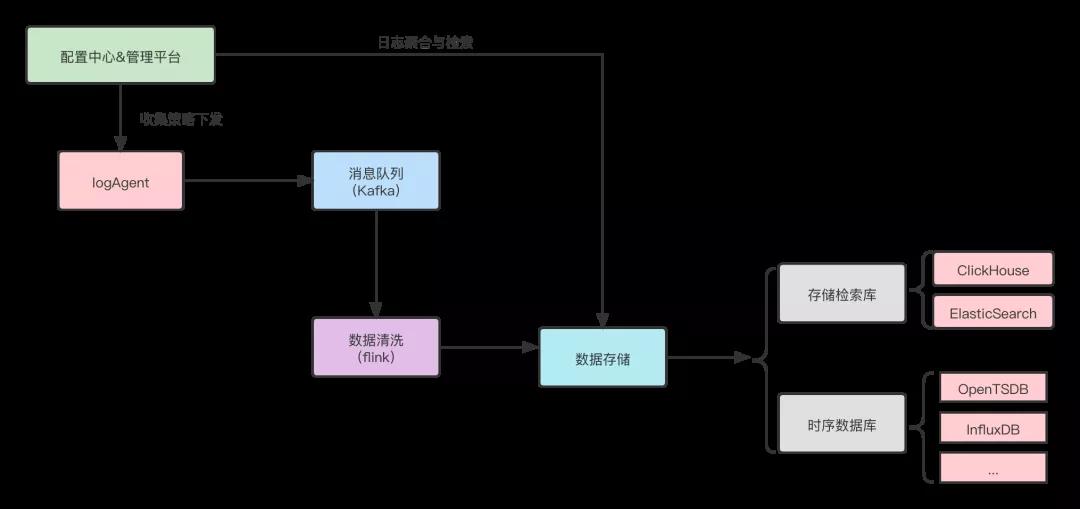
統一日志: 標準化日志格式、鏈路ID透傳、自定義檢索標識
日志類型: 應用日志、中間件日志(RPC框架、消息、緩存、存儲等)、網關日志、終端日志
收集策略: 例如根據IP、APP、文件等靈活管控,不同日志分類管理
數據清洗: 清洗重復非標準數據、重復數據、聚合高質量數據
存儲數據: 區分哪些數據適合ES、哪些數據適合ClickHouse、哪些數據適合時序庫
性能成本: 延遲問題、查詢性能、存儲成本
小結: 通過標準化的日志格式,多樣化的收集策略,清洗成高質量數據為根因定位提供基礎保障。
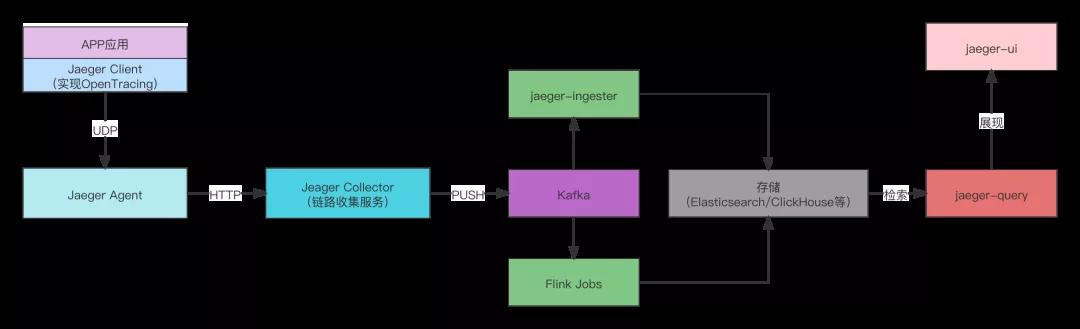
2.鏈路架構簡圖
采樣策略
- 固定采樣率:保持固定采樣的頻率
- 最低采樣率:過低流量保證最低的采樣率
- 自適應采樣率:根據流量自動適應采樣率
- 全部采樣率:對應特高優先流量100%采樣
- 染色采樣:對于染色打標的請求100%采樣
- 應急采樣:請求傳遞過程中檢測到錯誤或者異常,強制將該請求采樣
動態設置
- 采樣率采樣策略動態調整
- 自殺熔斷保護 不允許過度占用資源影響業務
小結: 鏈路采集和分析關鍵的點在于如何提供靈活的采樣策略,將核心鏈路、異常鏈路能實現高質量采集。
二、數據關聯
1.橫向關聯
橫向關聯:應用為維度通過調用關系將上下游關聯,包括經過的網關、緩存(Redis等)、消息(RocketMQ、Kafka等)、存儲資源(MySQL、Hbase、Mongo、ES等)。
指標(metrics):監控變化趨勢以及基于趨勢變化告警 如Micrometer,Prometheus格式指標數據的錯誤率變化
鏈路(Tracing): 微服務記錄上下游服務調用與耗時,基于OpenTracing 和 OpenTelemetry 規范,例如 Jaeger
日志(Logging):日志采集,通過日志詳細問題溯源

小結: 通過Tracing將Metrics和Logging進行關聯,當指標波動觸發告警能否智能關聯的tracing,尋根通過Logging錯誤日志找出根因,為業務提供輔助決策。
2.縱向關聯
垂直關聯:應用維度包含依賴的容器、機器、CPU、帶寬、磁盤、內存、消息資源(主題和消費組、集群)、緩存資源、數據庫資源(表與實例等)、搜索資源(索引等)指標關聯一站式展現。
三、輔助決策
1.數據質量
指標埋點覆蓋度
鏈路采樣策略的多樣性
日志清洗與提煉
2.告警質量
告警信息能包含從指標到鏈路以及日志的清晰關聯與日志信息,提高決策能力
3.分析能力
沉淀問題分析的最佳實踐庫,將其自動化分析提升定位能力
4.自愈能力
基于分析能力,沉淀自愈策略
自愈策略的靈活配置
5.性能與穩定性
采集延遲、計算能力、查詢性能
可視化觀測平臺自身的穩定性建設
6.可視化能力
可觀測一站式
豐富圖表與報表
7.預測能力
基于歷史數據沉淀算法模型預測未來可能發生的問題