SQL 不知道咋優化?吹一手 Join 語句的優化準沒錯

本文轉載自微信公眾號「飛天小牛肉」,作者小牛肉 。轉載本文請聯系飛天小牛肉公眾號。
面試最怕遇到的問題是什么,如何做優化一定當仁不讓,SQL 優化更是首當其沖,這里先跟大家分享一個比較容易理解的 join 語句的優化~
前文提到過,當能夠用上被驅動表的索引的時候,使用的是 Index Nested-Loop Join 算法,這時性能還是很好的;但是,用不上被驅動表的索引的時候,使用的 Block Nested-Loop Join 算法性能就差多了,非常消耗資源。
針對 join 語句的這兩種情況,其實都還是存在繼續優化的空間的
老規矩,背誦版在文末。點擊閱讀原文可以直達我收錄整理的各大廠面試真題
Multi-Range Read 優化
我們先來回顧一下 “回表” 這個概念。回表是指,InnoDB 在普通索引上查到主鍵 id 的值后,再根據主鍵 id 的值到主鍵索引樹上去查詢整行記錄的過程。
那么,思考一個問題,回表的過程是一行行地查數據,還是批量地查數據?
顯然是一行行地。
因為回表查詢的本質就是查詢 B+ 樹,在這棵樹上,每次只能根據一個主鍵 id 查到一行數據。
看下面這條語句,從 user 表中獲取 80 歲以上用戶的信息:
- select * from user where age >= 80;
假設,age 對應的 id 是連續自增的,這樣,我們對于主鍵索引樹的查詢,就是連續的:
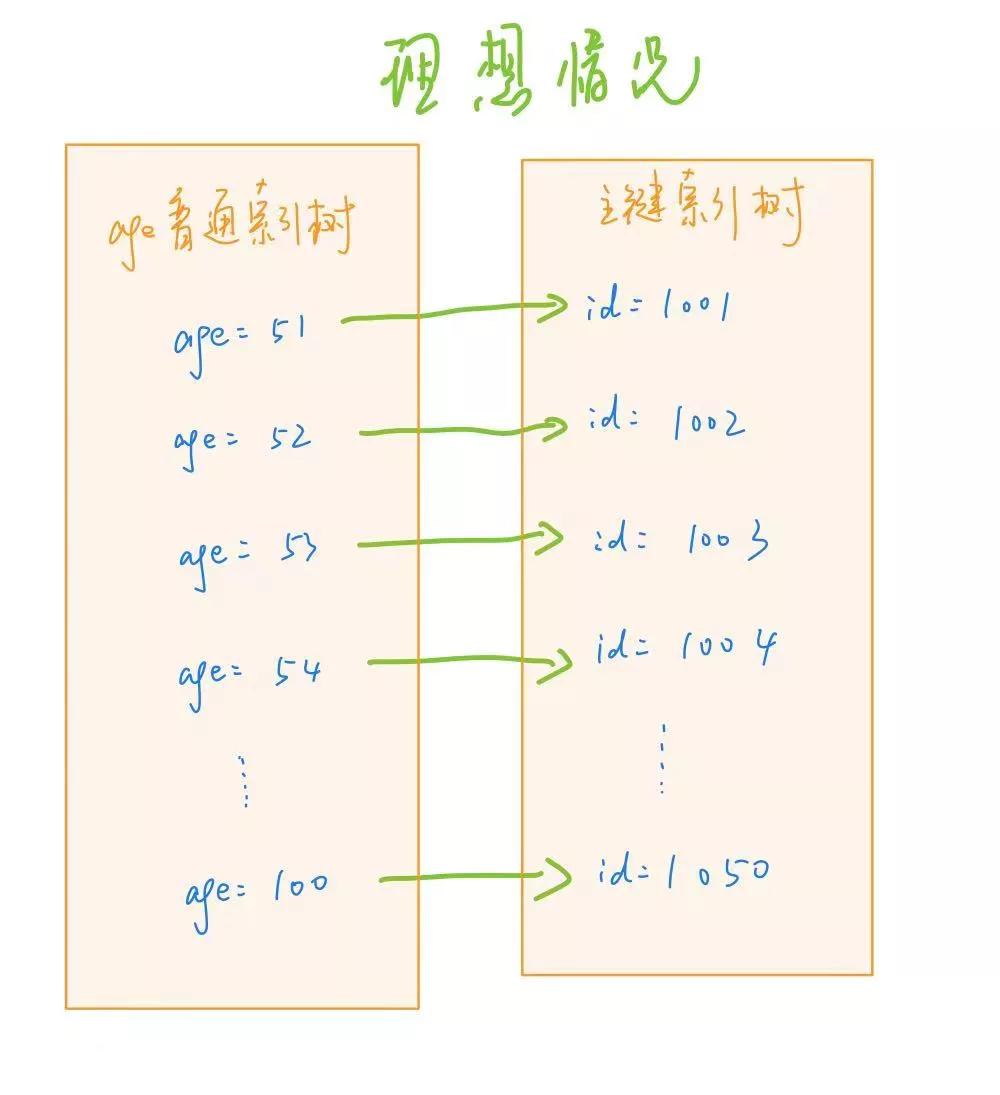
當然,這是理想情況,如果 age 對應的 id 值不是順序的話,那當我們順序取 age 的時候,id 的獲取就是亂序隨機的了,性能就會比較差。解釋下為什么這里亂序查詢的性能就比較差:
首先,我們都知道,索引文件其實就是一個磁盤文件,盡管有內存中 Buffer Pool 的存在可以減少訪問磁盤的次數,但是并不能完全避開對磁盤的訪問。而對于磁盤來說,一個磁盤從內到外有許多磁道,一個磁道又被劃分成多個相同的扇區,隨機讀取性能較差的原因就是每次都需要花費時間去尋找磁道,找到磁道之后又要去尋找合適的扇區,從而耗費大量時間。所以順序讀取比隨機讀取快很多。
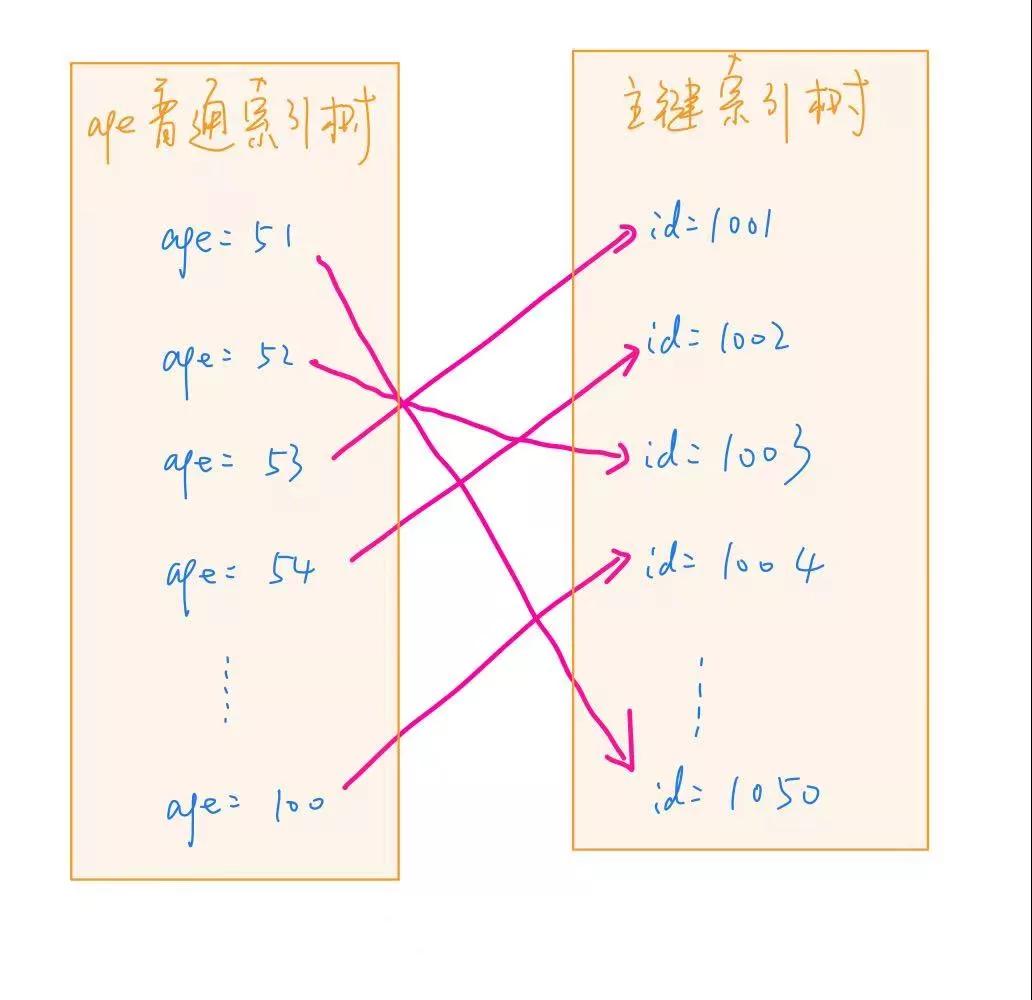
所以,一個很自然的想法,就是調整主鍵 id 查詢的順序,使其接近順序讀取,從而達到加速的目的。
那么,具體該如何調整主鍵 id 查詢的順序呢?
因為大多數的數據都是按照主鍵 id 遞增順序插入的,對吧,所以我們可以簡單的認為,如果按照主鍵 id 的遞增順序查詢的話,對磁盤的讀取會比較接近順序讀取,從而提升讀性能。這就是 Multi-Range Read (MRR) 優化的思想。
而將主鍵 id 進行升序排序的過程,是在內存中的隨機讀取緩沖區 read_rnd_buffer 中進行的。
我們可以設置 set optimizer_switch="mrr_cost_based=off" 來開啟 MRR 優化,這樣,語句的執行流程就是下面這個樣子:
- 根據普通索引 age,找到滿足條件的主鍵 id,然后將 id 值放入 read_rnd_buffer 中
- 將 read_rnd_buffer 中的 id 進行遞增排序;
- 根據排序后的 id 數組,進行回表查詢
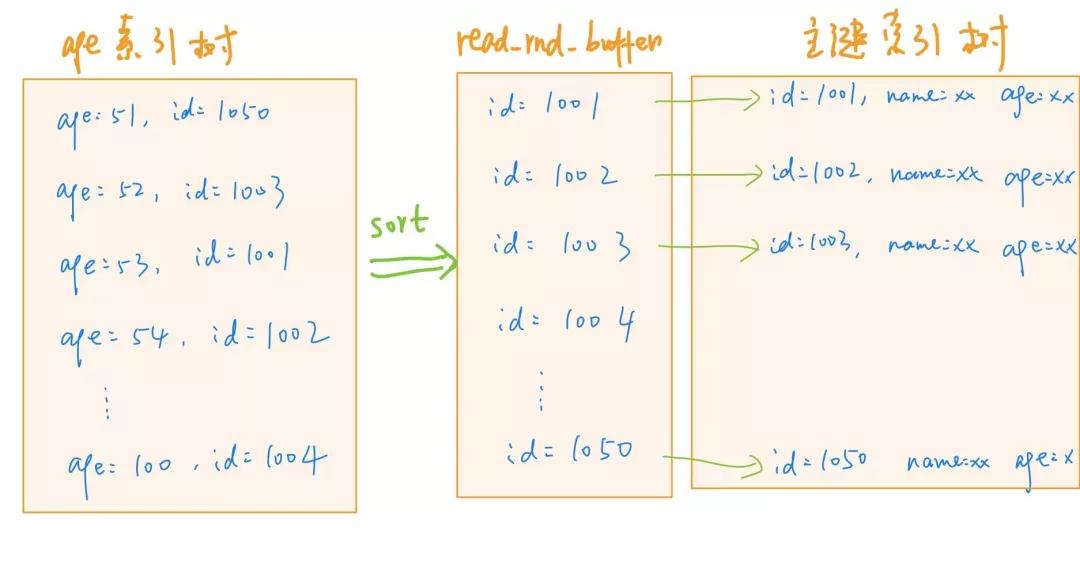
需要注意的是,read_rnd_buffer 的大小是由 read_rnd_buffer_size 參數控制的。如果發現 read_rnd_buffer 放滿了,那么 MySQL 就會先執行完步驟 2 和 3,然后清空 read_rnd_buffer,之后再繼續循環。
可以看出來,使用 MRR 提升性能主要適用于范圍查詢,這樣可以得到足夠多的主鍵 id,通過排序以后,再去主鍵索引查數據,從而體現出順序讀取的優勢。
MRR 這種開辟一個內存空間對主鍵 id 進行排序的思想呢,應用到 join 語句的優化層面上來,就是 MySQL 在 5.6 版本后引入的 Batched Key Access 算法(BKA),下面我們來解析下這個算法以及如何使用這個算法對 Index Nested-Loop Join 和 Block Nested-Loop Join 兩種情況進行優化。
優化 Index Nested-Loop Join
假設我們已經在 age 字段上建立了索引,那么下面這條 sql 語句用到的就是 Index Nested-Loop Join 算法,回顧下具體的執行邏輯:
- select * from table1 join table2 on table1.age = table2.age where table2.age >= 80;
從 table1 表中讀入一行數據 R
從數據行 R 中,取出 age 字段到表 table2 的 age 索引樹上去找并取得對應的主鍵
根據主鍵回表查詢,取出 table2 表中滿足條件的行,然后跟 R 組成一行,作為結果集的一部分
也就是說,對于表 table2 來說,每次都是只匹配一個值。這時,MRR 的優勢就用不上了。
所以,如果想要享受到 MRR 帶來的優化,就必須在被驅動表 table2 上使用范圍匹配,換句話說,我們需要一次性地多傳些值給表 table2。那么具體該怎么做呢?
方法就是,從表 table1 中一次性地多拿些行出來,先放到一個臨時內存中,然后再一起傳給表 table2。而這個臨時內存不是別人,就是 join_buffer!
之前我們分析過 Block Nested-Loop Join 算法中用到了 join_buffer,而 Index Nested-Loop Join 并沒有用到,這不,在優化這里派上用場了。
這就是 BKA 算法對 Index Nested-Loop Join 的優化,可以通過下面這行命令啟用 BKA 優化算法
- set optimizer_switch='mrr=on,mrr_cost_based=off,batched_key_access=on';
前兩個參數的作用是啟用 MRR,因為 BKA 算法的優化依賴于 MRR。
優化 Block Nested-Loop Join
那如果用不上被驅動表索引的話,使用的 BNL 算法性能是比較低的,所以常見的優化方法就是給被驅動表的 join 字段加上索引。
但是,如果這條 SQL 語句的使用頻率比較低并且數據量不大的話,建立索引其實就比較浪費資源了。
所以,有沒有一種兩全其美的辦法呢?
這時候,我們可以考慮使用臨時表。使用臨時表的大致思路是:
把表 table2 中滿足條件的數據放在臨時表 temp_table2 中
給臨時表 temp_table2 的字段 age 加上索引
讓表 table1 和 temp_table2 做 join 操作
這樣,一個 BNL 算法的優化問題,就被我們轉換成了 Index-Nested Loop Join 的優化問題了,按照上述所說的,可以使用 BKA 進行優化。
具體的 SQL 語句如下:
- # select * from table1 join table2 on table1.age = table2.age where table2.age >= 80;
- create temporary table temp_table2 (id int primary key, name varchar, age int, index(age)) engine=innodb;
- insert into temp_table2 select * from table1 where age >= 80;
- select * from table1 join temp_table2 on (table1.b=temp_table2 .b);
總的來說,優化 Block Nested-Loop Join 的思路就是使用有索引的臨時表,讓 join 語句能夠用上被驅動表上的索引,從而轉換為 Index Nested-Loop Join 然后觸發 BKA 算法,提升查詢性能。
最后放上這道題的背誦版:
面試官:SQL 優化了解過嗎?
小牛肉:先說 join 語句的優化
join 語句分為兩種情況,一種是能夠用上被驅動表的索引,這個時候使用的算法是 Index Nested-Loop,另一種是用不上,這個時候使用的算法是 Block Nested-Loop
- 對于 Index Nested-Loop 來說,具體步驟其實就是一個嵌套查詢,首先,遍歷驅動表,然后,對這每一行都去被驅動表中根據 on 條件字段進行搜索,由于被驅動表上建立了條件字段的索引,所以每次搜索只需要在輔助索引樹上掃描一行就行了,性能比較高
- 對于 Block Nested-Loop 來說,MySQL 首先把驅動表中的數據讀入線程內存 join_buffer 中;然后掃描被驅動表,把被驅動表中的每一行依次取出來,跟 join_buffer 中的數據做對比,滿足 on 條件的,就作為結果集的一部分返回。BNL 算法的性能比較差,因為我們需要多次遍歷被驅動表。那么對于 BNL 算法來說,一個很常見的優化思路就是對被驅動表的條件字段建立索引,從而轉換成 Index Nested-Loop 算法。
對于上面這兩種 join 情況來說,如果繼續添加一個范圍查詢的 where 條件的話,其實還存在優化空間。
其核心做法其實就是針對范圍查詢的優化,也稱為 Multi-Range Read 算法
具體來說,因為大多數的數據都是按照主鍵 id 遞增順序插入的嘛,所以我們可以簡單的認為,如果按照主鍵 id 的遞增順序進行查詢的話,對磁盤的讀取會比較接近順序讀取,這樣相比于亂序讀取的話減少了尋道時間,從而提升讀性能。
而將主鍵 id 進行升序排序的過程,是在內存中的隨機讀取緩沖區 read_rnd_buffer 中進行的。就是先把在輔助索引樹上查找的滿足條件的主鍵 id 存到 read_rnd_buffer 中,然后對這些 id 進行遞增排序,根據排序后的 id 數組,進行回表查詢。
MRR 的思想應用到 join 語句的優化層面上來,就是 MySQL 在 5.6 版本后引入的 Batched Key Access,BKA 算法
- 對于 Index Nested-Loop 來說,就是一次性地從驅動表中取出很多個行記錄出來,先放到臨時內存 join_buffer 中,然后再一起傳給被驅動表
- 對于 Block Nested-Loop 來說,就是對被驅動表建立一個臨時表,并且對條件字段建立索引,然后把之前兩張表的 join 操作轉換成驅動表和臨時表的 join 操作,從而轉換成對 Index Nested-Loop 的優化問題
balabala.......(后續其他 SQL 優化會慢慢更新的~)