前端開發(fā)者也可以懂的基礎(chǔ) System Design
大家好,我是小智,今天帶來 Kyle Mo 大佬的一篇關(guān)于 System Design 好文,希望對大家有所幫助,早期成為大神。PS:文文已經(jīng)過授權(quán)。
前陣子在與朋友一起籌劃的后端開發(fā)線上分享會 BESG 有成員分享了 TinyURL 的系統(tǒng)設(shè)計 (System Design),剛好也看到了知名 YouTuber Terry 關(guān)于 Google 系統(tǒng)設(shè)計面試的影片,了解到在美國的資訊業(yè),不論你是前端、后端、資料工程師還是 DevOps,System Design 系統(tǒng)設(shè)計幾乎都是面試時的必考題。
有人可能會覺得,反正那是國外的狀況,我在國內(nèi)找前端的工作,不需要會系統(tǒng)設(shè)計也可以錄取吧?是沒錯,以目前國內(nèi)的前端業(yè)界來看,面試大多是不會考系統(tǒng)設(shè)計的,但是其實學習系統(tǒng)設(shè)計并不僅是為了應付面試,更是學習如何應付復雜系統(tǒng)的能力,也是從 Junior 開發(fā)者過渡到 Senior 開發(fā)者的關(guān)鍵。就算身為前端開發(fā)者,也會需要面對越來越復雜的系統(tǒng),學會基本的系統(tǒng)設(shè)計思維除了能讓你更了解系統(tǒng)的整體架構(gòu)外,同時也加強在開發(fā)時和其他角色溝通與協(xié)作的能力。
我是一個剛要進入社會,準備開始自己第一份正職的菜鳥工程師,主要 focus 在 Web 前端技術(shù),但也熱衷于學習后端開發(fā)與云端技術(shù)。我想透過這篇文章,以自己是前端開發(fā)者的角度出發(fā),去介紹我認為前端開發(fā)者也該擁有的基本系統(tǒng)設(shè)計思維,也就是說主要會介紹系統(tǒng)設(shè)計最表層的元素,而不會去深入探討每一個技術(shù)的深入實作,目標在廣而不在深。
要知道系統(tǒng)設(shè)計是一門非常非常非常複雜的技術(shù)(說了三次,應該了解到底多複雜了??),絕對不是我這樣的菜雞可以精通的,因此這篇文應該會蠻入門也蠻淺的,主要目的是希望和我一樣剛?cè)胄械那岸碎_發(fā)者在看完文章后,也能擁有最基本的系統(tǒng)設(shè)計思維,除了處理 UI 畫面與瀏覽器相關(guān)的眉眉角角外,應該也要理解一個合格的系統(tǒng)在背后是怎麼運作的。
本篇文章的流程會是這樣的,首先我會把我認為系統(tǒng)設(shè)計的重要元素列出來,并對每個元素進行更近一步的介紹,等讀者有了大概的認知后,再分享我認為在面對系統(tǒng)設(shè)計時可以採用的思維走向,最后再以一個實際的系統(tǒng)設(shè)計范例按照先前介紹的思維走向來解決問題。
以分散式系統(tǒng)為設(shè)計目標
雖然我們知道分散式相對于單機來說復雜許多,在單機都處理不好的狀況下去碰分散式系統(tǒng)幾乎是死路一條,不過單機的 Vertical Scaling 是有侷限性的,并且 Single Point Of Failure 的問題也讓系統(tǒng)充滿風險,要建立一個“可靠的大型系統(tǒng)”,採用分散式架構(gòu)似乎是無法避免了。況且在遇到系統(tǒng)設(shè)計面試問題時,通常都會預設(shè)要設(shè)計的系統(tǒng)是高流量的,畢竟設(shè)計一個只能承受低流量的系統(tǒng)是毫無意義的,因此本篇文章討論的系統(tǒng)設(shè)計都會以分散式系統(tǒng)為出發(fā)點。
我們希望設(shè)計出來的系統(tǒng)能擁有哪些特性?
Scalability 可擴展性
當系統(tǒng)遇到的流量漸漸變大時,我們會希望系統(tǒng)的服務器或儲存空間也能夠跟著擴展,來避免無法負荷的狀況。
用白話一點的方式來比喻的話,想像今天你跟 4 個朋友約好要出去玩,你們租了 Toyota 的四人座 Vios,不過另外 2 個人看到你們要出去玩,就堅持要你們帶上他們,當然現(xiàn)在 6 個人是塞不下小小的 Vios 的,你們只好換租可以載 6 人的 Luxgen U6。
這就很像是系統(tǒng)設(shè)計垂直擴展(Vertical Scaling) 的概念,藉由提升單機 CPU 或內(nèi)存來提升效能。然而這樣的提升是有限制的,想像越來越多朋友想跟你們一起出去玩,你說到了 30 個人,你還可以換包游覽車,那 300 個呢?(別跟我說包火車)這時可能就得放棄全部人都擠一臺車的方式,改為租用多臺游覽車來載運所有人。這在系統(tǒng)設(shè)計上稱作水平擴展(Horizontal Scaling),用多臺機器來分流處理單機可能無法負荷的流量,達到系統(tǒng)的可擴展性。
Reliability 可靠性
可靠性代表一個系統(tǒng)在它開始執(zhí)行之后到某個時間點,系統(tǒng)正常執(zhí)行的機率,也就是系統(tǒng)無故障執(zhí)行的概率。
Availability 可用性
可用性是一個容易跟可靠性搞混的指標,它的定義為系統(tǒng)在面對各種異常時可以正確提供服務的能力,更嚴謹?shù)亩x為“系統(tǒng)服務不中斷運行時間占實際運行時間的比例。””如果以公式來看:
Availability % = (available time / total time) *100
因此可用性跟容錯性是相關(guān)聯(lián)的,在單機架構(gòu)下,機器炸了,使用者也 access 不到服務了,而分散式的狀況下即使有機器 shutdown,也會由其他機器馬上遞補上,對用戶來說服務一直是可用的,這也是為什麼說分散式系統(tǒng)可以提升可用性的原因。
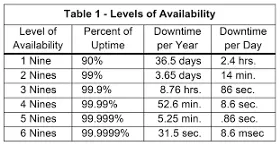
Reliability 與 Availability 這兩個指標常常讓人搞混,一個 reliable 的系統(tǒng)通常也會是一個 available 的系統(tǒng),Availability 雖然可以透過分散式系統(tǒng)的冗馀電腦 (redundant) 來達成,但卻不能保證這個系統(tǒng)是 reliable 的。
Efficiency 高效率
代表這個系統(tǒng)的效率如何,一般常見的指標有系統(tǒng)的延遲(Latency)與吞吐量(Throughput).
Latency 延遲:執(zhí)行一個操作要花費的“時間長度”。以我自己較熟悉的 web 領(lǐng)域來說,Latency 指的是使用者發(fā)出請求后,等待 server 接收請求,進行處理后回傳給使用者的總花費時間。
Throughput 吞吐量:以一個時間區(qū)間作為單位,單位時間內(nèi)可以執(zhí)行“幾次”操作,或運算的“次數(shù)”。同樣以 web 來舉例,Throughput 指的是單位時間內(nèi)服務器可以接收的請求量。
要建構(gòu)一個高效率的系統(tǒng),我們會希望系統(tǒng)可以達到 **Low Latency **與 High Throughput。
Manageability 可管理性
故名思義,代表一個系統(tǒng)是不是方便管理,是不是能快速迭代新功能?是不是能夠快速追蹤 bug?或是能不能把 infrastructure 抽象化,讓應用工程師可以專注在程式邏輯的開發(fā)。
System Design Common Components & Topics
無論是面對系統(tǒng)設(shè)計的題目或是自己在思考系統(tǒng)的架構(gòu),有些技術(shù)是建構(gòu)分散式系統(tǒng)時非常重要的元素,了解這些元素將會使我們對于分散式系統(tǒng)更加了解,在系統(tǒng)設(shè)計時也更得心應手,這些常見的元素有:
Load Balancer Web Server Database (SQL vs NoSQL) Schema Design Caching Replication Partitions Sharding Read/Write Splitting Algorithm Queue Consistent Hashing Proxy CAP Theorem
如果要每個技術(shù)或概念都介紹的話應該得花不少篇幅,因此這邊如果讀者對某些概念不熟悉,就麻煩自行研究囉!
面對系統(tǒng)設(shè)計時的思維走向
系統(tǒng)設(shè)計是一個開放式的問題,沒有所謂一定正確且標準的解法,不管哪種方法幾乎都會帶來 trade off,所以我接下來提供的思維走向也許不是最好最標準的,也不一定適用于所有的情形,但我認為它可以幫助我們快速建構(gòu)出系統(tǒng)的基本雛形與軟硬體需求,如果你對系統(tǒng)設(shè)計毫無想法,不妨試試看參考這個思維走向,再根據(jù)自己的需求去做細部的調(diào)整。
Step.1 弄清系統(tǒng)需求
這是最基本卻也是最重要的一步,弄清系統(tǒng)的需求后,你才知道自己到底要設(shè)計什麼,如果是在系統(tǒng)設(shè)計的面試,這也是應該要盡早跟面試官確定的事。系統(tǒng)需求一般來說可以分為兩種類型:
- Functional Requirements
- Non-Functional Requirements
Functional Requirements 代表系統(tǒng)該要有的功能,以 YouTube 系統(tǒng)舉例,使用者可以創(chuàng)建自己的頻道,也可以去訂閱別人的頻道,在訂閱頻道發(fā)布新影片時會收到通知…等等你想得到的各種功能,都算在 Functional Requirements 的范疇裡。
Non-Functional Requirements 顧名思義是一些跟系統(tǒng)功能較無直接關(guān)連的需求,例如系統(tǒng)需要有高可用性、系統(tǒng)延遲需要非常低、需要嚴格的資料一致性…等等。
Step.2 關(guān)于系統(tǒng)流量、容量、網(wǎng)絡(luò)帶寬等指標的粗略計算
對系統(tǒng)的流量、儲存空間、網(wǎng)絡(luò)做初步的估算,對于后面要考慮 scaling、caching、load balancing 時是有幫助的,再者對這些指標進行評估,也讓我們可以更好的掌握系統(tǒng)的資源成本。
同樣以設(shè)計 YouTube 來舉例, 我們可以先估算系統(tǒng)大約會有多少使用者,其中又有多少 DAU (Daily Activated User),估算一天大約會有幾部影片上傳,影片建立跟讀取的比例是多少…等等,這是比較偏向系統(tǒng)流量的考量。
下一步可以估算系統(tǒng)的儲存容量,例如每年儲存影片的總?cè)萘看蠹s是多少?儲存的資料會存活多久?如果系統(tǒng)有實作 Caching,Memory 的用量又大概是多少?
而最后網(wǎng)絡(luò)貸款也是我們可以事先預估的指標。
如果讀者不知道怎麼計算這些指標也不要擔心,在下一個章節(jié)會以設(shè)計 Instagram 為范例跑一次系統(tǒng)設(shè)計流程,到時候會示范估算這些指標的方式。
Step.3 定義 System Interface
當我們釐清系統(tǒng)的需求后,就可以按照需求來粗略規(guī)劃系統(tǒng)的 API,這也可以讓我們確認先前訂出的系統(tǒng)需求并沒有定義錯誤。這時可以先思考系統(tǒng)要採用哪種 API 架構(gòu),例如 REST APIs、SOAP、GraphQL,再來可以簡單定義出有哪些 API endpoints,以 YouTube 來舉例:
uploadVideo(user_id, video_content, video_location, user_location, ……) addVideoToFavorite(user_id, video_id, timestamp, …….)
Step.4 定義 Data Model | DB Schema
在 System Design 的前段及早定義出 DB Schema 將幫助我們更清楚系統(tǒng)的資料流,我們應該清楚不同 Entities 之間是怎麼互動與溝通的,以 YouTube 為例,Data Model 可能是這樣子:
User: UserID, Name, Email, DoB, CreationDate, LastLogin, …. Video: VideoID,VideoLink, VideoLocation, NumberOfLikes, TimeStamp, … .….
在這個階段也可以先思考究竟系統(tǒng)適合哪種資料庫?RDBMS 還是 NoSQL ? 還有使用者上傳的影片與圖片,又適合儲存在哪呢?
Step.5 High-level design
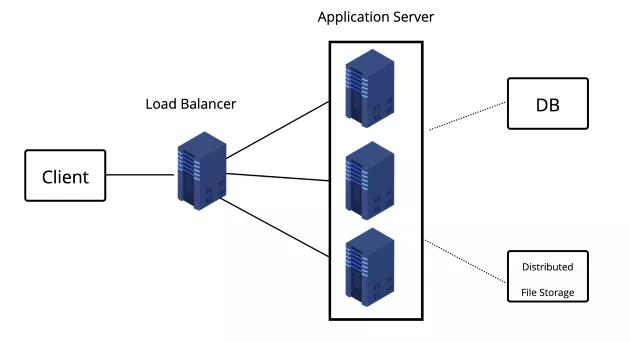
這步驟是系統(tǒng)的 High-level 設(shè)計,可以在一張圖表畫出系統(tǒng)大概由哪些 Components 組成,因為先前步驟已經(jīng)確定了系統(tǒng)需求,也對流量做了初步估算,所以在這個步驟我們可以設(shè)計系統(tǒng)需不需要做分流、讀寫分離,以 YouTube 的例子來說,我們可能還需要一個分散式的檔案儲存系統(tǒng)來存放影片。
Step.6 System Detailed design
先完成 high-level 的系統(tǒng)設(shè)計,接下來才進入系統(tǒng)的 detailed design,如果是面對系統(tǒng)面試,在時間有限的狀況下,可以針對前面 high-level design 畫出的架構(gòu)圖裡挑出兩三個 components 來說明就好,而這邊建議可以跟著面試官的引導走。(如果不是在面試,當然你就有大把時間可以好好對每個環(huán)節(jié)做 detailed 的設(shè)計了)
針對特定的 component 或 topic,我們可以提供兩三種可行的方法,并思考它們各自的優(yōu)缺點,這也是個開放性的問題,重要的是你要能清楚每種方式的 trade off,并找出最“適合”自己系統(tǒng)的做法。
- 在需要存取大量資料的情況下,我們該怎麼把資料做 partition 并且存到不同資料庫伺服器裡 ?
- 我們應該在系統(tǒng)的哪些 layer 加入快取服務 ?
- 系統(tǒng)中哪些部分比較需要做 load balancing ?
Step.7 找到系統(tǒng)可能瓶頸或 trade off 并嘗試給出解決方案
如果是在系統(tǒng)設(shè)計的面試中,在做完系統(tǒng)架構(gòu)設(shè)計之后,可以針對自己設(shè)計的系統(tǒng)提出一些可能的瓶頸,畢竟沒有所謂完美的系統(tǒng)架構(gòu),能夠講出自己所設(shè)計的系統(tǒng)有哪些缺陷或瓶頸,代表你對系統(tǒng)整體的掌握度是高的,也許在面試官的眼中是加分的行為(不過這邊可能得注意挖坑給自己跳的狀況)。
嘗試設(shè)計一個 Instagram 吧!
雖然知道了面對系統(tǒng)設(shè)計可以採取的思路,但我相信各位讀者看到這裡還是覺得十分抽象吧?那不如我們就按照前面的思考步驟實際設(shè)計一個 IG 系統(tǒng)體會看看吧!(下面代稱這個系統(tǒng)為“Fake IG”好了??)
(大家應該都知道 IG 是什麼吧!???)
Step.1 理清系統(tǒng)需求
前面有提到可以針對“Functional Requirements”與 “Non-Functional Requirements”來區(qū)分系統(tǒng)需求
Functional Requirements:
- 使用者可以上傳照片、影片,另外也可以讀取與下載
- 使用者可以追蹤其他使用者以觀看最新貼文
- 使用者可以根據(jù) tags 來搜尋文章
- 當使用者刷新頁面后,系統(tǒng)會根據(jù)使用者追蹤的人顯示該些用戶的最新貼文
Non-Functional Requirements:
- Fake IG 系統(tǒng)需要具有高可用性(high availability)
- 刷新頁面看最新貼文時可以允許短暫的延遲
- 在某些狀況下,系統(tǒng)的一致性可以犧牲,例如使用者貼文的愛心數(shù)量(每個使用者看到的數(shù)量即使不一樣,也不會造成什麼影響)
- 系統(tǒng)希望可以擁有高可靠性(high reliability),使用者上傳的照片、影片不能夠遺失
我們都知道實際上 IG 的功能絕對比上面列出來的還要多,例如在照片上標記其他使用者、限時動態(tài)…等等,這些較進階的功能可以自己思考要不要列出。(設(shè)計出基本功能比較重要)
Step.2 關(guān)于系統(tǒng)流量、容量、網(wǎng)絡(luò)帶寬等指標的粗略計算
關(guān)于系統(tǒng)的流量,我們可以先假設(shè)高一點,畢竟設(shè)計能面對高流量的系統(tǒng)才有意思。假設(shè)我們的 Fake IG 系統(tǒng)的使用者總?cè)藬?shù)有 5000 萬人,當然裡面不乏許多早就沒在使用的幽靈用戶,所以這邊假設(shè)每天仍然活躍的用戶(daily active users, DAU)有 100 萬人。
接下來我們先忽略使用者可以上傳影片這個行為,先限定使用者只能夠上傳照片,不然要考慮的因素實在太多了。假設(shè)一天大約有 150 萬張照片會被上傳,平均一張照片的檔案大小為 250 KB,那麼儲存一天中新上傳的照片總共需要的容量為
1.5M * 250KB ~= 375GB
如果將時間拉遠來看,10 年下來存放照片需要的容量為
375GB * 365(days) * 10 ~= 1368.75TB
當你在后面的步驟定義好 DB Schema 后,也可以再回過頭來用同樣的方式估算資料庫要儲存的資料總大小,例如我們的系統(tǒng)一定會有儲存用戶資訊的 User Table ,而它的欄位與空間如下
UserID (4 bytes) + Name (20 bytes) + Email (32 bytes) + Birthday (4 bytes) + CreationDate (4 bytes) = 64 bytes
先前有假設(shè) Fake IG 的使用者總?cè)藬?shù)有 5000 萬人,因此儲存用戶資訊的 total storage 約為:
50M 64 ~=3.2GB*
其他的 DB Schema 與上傳圖片使用的 Network Bandwidth 也可以採用類似的方法估算需要的容量。
Step.3 定義 System Interface
規(guī)劃系統(tǒng) API 的步驟,因為是一個十分開放式的問題,答案也不太會影響接下來的步驟因此這邊就不多花篇幅說明。
Step.4 定義 Data Model | DB Schema
定義出 Data Model 可以讓我們清楚數(shù)據(jù)的關(guān)聯(lián)與數(shù)據(jù)的流動,在未來要做 data sharding 或 partitioning 時也會比較容易。在 Fake IG 系統(tǒng)中,我們先假設(shè)只需要先考慮使用者與用戶上傳的照片就好(不然我這邊會寫不完,還請高抬貴手),在學生時期十分認真修資料庫課程的你可能會馬上畫出以下的數(shù)據(jù)庫關(guān)聯(lián)圖
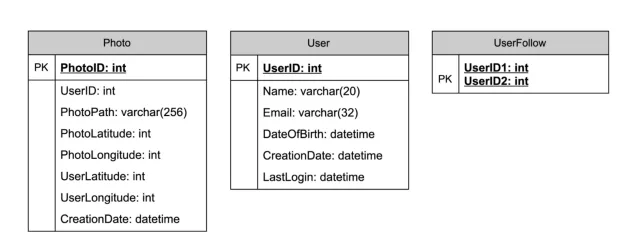
畫完圖后你可能會覺得這個 use case 還蠻適合使用如 MySQL 的 RDBMS 的,畢竟數(shù)據(jù)是有 join 的需求的。不過 RDBMS 在 Scaling 上是非常非常複雜且困難的,例如數(shù)據(jù)一致性的處理方式也與單機時大不相同。而使用 NoSQL 其實也是可行的,雖然可能需要一些額外的 table 來儲存數(shù)據(jù)的關(guān)聯(lián) (例如 UserPhoto),不過在 Scaling 上卻較為簡單。我也沒辦法告訴你,使用 RDBMS 還是 NoSQL 好,它們各有各的優(yōu)缺點也有各自適用的時機,因此這個問題也算是開放式的,應該在多深入了解后再做出選擇。
另外像照片影片這種資源,一般會需要像是 AWS S3 這樣的 Distributed File Storage,而在我們的數(shù)據(jù)庫中則只存圖片或影片在 file storage 的 link 還有其他的 meatdata。
Step.5 High-level design
當然我們也不一定要畫出整個系統(tǒng)的架構(gòu)圖,尤其是在面試的話,我們得在有限的時間內(nèi)盡量 focus 在系統(tǒng)的重點部分,以 Fake IG 來說我們先試著設(shè)計使用者上傳照片與讀取照片的功能。
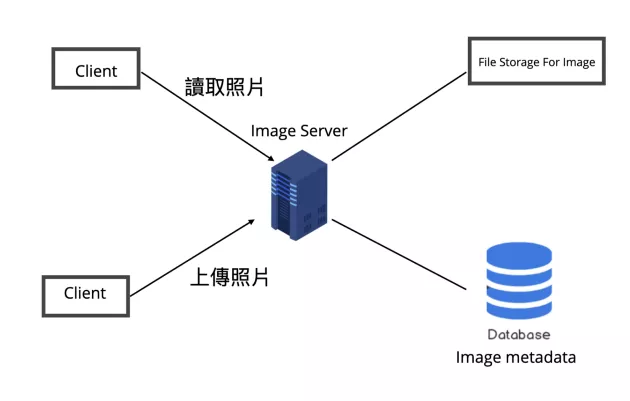
以 high-level 的角度來看 Fake IG 的照片系統(tǒng),大致上會有兩種情境,也就是用戶上傳照片與讀取照片,所以我們會需要一臺 application server 來處理使用者的讀寫 requests,另外會需要一個如 AWS S3 一樣的分散式 file Storage 來儲存照片,另外也會再開一個 database 來儲存照片相關(guān)的 metadata。
Step.6 System Detailed design
不過仔細思考就會知道上傳照片相比讀取照片所耗費的時間會多出更多,因為上傳照片可能涉及了硬盤的寫入,也不像讀取一樣可以加一層快照層。通常 web server 是有連線數(shù)量的限制的,如果上傳照片的過程太耗時,可能會占用 web server 的連線請求,導致要讀取照片的 request 被卡住,造成響應的延遲。要處理這個 bottleneck 的其中一種方式就是將讀取與上傳拆成兩個獨立的 server 來分別處理請求,而負責上傳照片的 server 還能搭配 message queue 來消化請求。這樣的做法還有一個好處就是兩個服務可以依照需求各自 Scale 與 Opimize。
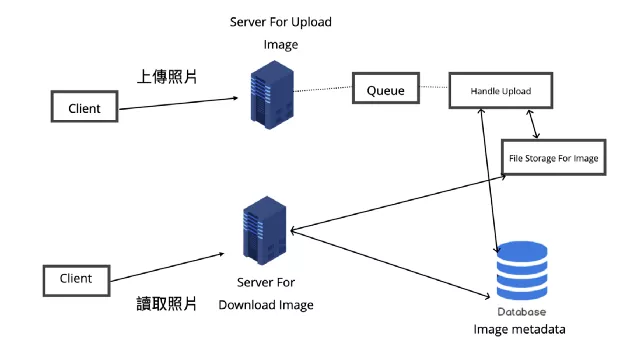
對于 Availability 與 Reliability,也可以考慮為系統(tǒng)的各個 component 加入 replica service,這樣 horizontal scaling 的結(jié)果是可以避免 single point of failure,在其中一個服務節(jié)點掛掉時仍能保持系統(tǒng)可用性,搭配 Load Balancer 也可以做到流量的分流,降低系統(tǒng)的延遲。
提到 Load Balancer,它的目的是達成 horizontal scaling,不過它也可能會有 single point of failure 的風險,因此 replica 也可以應用在它上面。就算是只需要一個 instance 來運作的服務,也可以為其建立 redundant secondary copy,這個 copy 不會 serve 任何的流量,卻可以當作備胎,在主服務掛掉時立即取代它的工作成為 master node。
同樣的 Scaling 思維也適用于儲存服務例如 Fake IG 使用的 File Storage 與 Database,畢竟我們不希望系統(tǒng)出現(xiàn)檔案或資料遺失的狀況,因此可以為 Database 與 File Storage 加 backup server,讓數(shù)據(jù)也可以避免單點失效后遺失的問題。
不過還是得呼吁一下,加 replica services 未必能改善所有性能或其他的瓶頸,再來成本也是需要考量的一個元素,因此還是得依照需求謹慎評估是否需要 scaling,需要的話也要謹慎評估 scaling 的程度。
更進一步可以思考 database 數(shù)據(jù)是不是需要 Partitioning 或 Sharding,前者是在同一個數(shù)據(jù)庫中將 table 拆成數(shù)個小 table,后者則是將 table 放到數(shù)個數(shù)據(jù)庫中。
Partitioning 的 table 與 schema 可能會改變,Sharding 的 schema 則是相同,但分散在不同數(shù)據(jù)庫中,Partitioning 是為了分散單表的壓力,Sharding 則是分散單庫的壓力,實際上還是要依照需求找出適合當前系統(tǒng)的方式。
以 Fake IG 來說,如果真要選擇我可能會選擇比較容易擴展的 Sharding,不過 Sharding 也帶來相當多的問題例如橫跨不同 shards 的 transaction、rollback、schema change、join、每個 shard db 還要另外去做 backup……等等。
如果選擇了 Sharding 的方式,那麼 Shard 時依賴的 key 就很重要了,一般來說可以分為 Range-based 與 Hash 兩種方式(如果完全不知道 Sharding 的讀者可以參考我之前的筆記文章),假設(shè)我們以 userId 來作為 shard 的 key,那可能會出現(xiàn) hot user 造成某一個數(shù)據(jù)庫 loading 過重的問題(想想那些在 IG 上追蹤人數(shù)破億的全球巨星,一天不知道會有多少使用者去瀏覽他們的文章呢,那麼存取這些明星數(shù)據(jù)的數(shù)據(jù)庫可能流量就會比其他 instance 還要大很多)。
總之我覺得 Sharding 的複雜度還有坑真的是挺多的,也許在一開始得先考慮清楚系統(tǒng)是不是真的需要 Sharding,如果在面試提出要做 Sharding 或 Partitioning,也要做好萬全準備,以免只是挖更多坑給自己跳。
當然 Caching 也是一個必定要考慮的機制,因為 Fake IG 會產(chǎn)生許多圖片,而這些資源非常適合暫存在離 end users 更接近的 CDN 裡。除了 CDN Cache,也可以在數(shù)據(jù)庫前加一個例如 Memcache 的快照服務器,用來暫存一些較常被抓取的資料。
關(guān)于到底要存哪些數(shù)據(jù)到快照這個問題,我們不可能把所數(shù)據(jù)都放到快照裡,根據(jù)“80–20 Rule”,80% 的流量可能都來自于 20% 的 hot data,因此我們可以找出較常被 user 存取的 20% photo 與 metadata 數(shù)據(jù)存到緩存中。
而快照是需要一些清除策略(cache eviction policy)的,不然無限增長的狀況下很容易就沒有快照空間了。在 Fake IG 系統(tǒng)中,我覺得 LRU Cache (Least Recently Used Cache)就還蠻適合的,當要清除快取空間時,可以先從近期最少被存取的數(shù)據(jù)開始移除。
總結(jié)
雖然說身為前端開發(fā)者,在求職過程甚至是整個職涯都有可能不會碰到系統(tǒng)設(shè)計相關(guān)的問題,不過因為我將自己定義為雜食性的軟體工程師,遇到有興趣、有挑戰(zhàn)性的技術(shù)我都想學,再加上自己一直有個不切實際的硅谷夢,所以依然深信自己未來某一天也會遇到系統(tǒng)設(shè)計的挑戰(zhàn)。而自己也的確在接觸這些內(nèi)容后對整個系統(tǒng)應用架構(gòu)有了更進一步的了解,所以我非常推薦前端開發(fā)者也可以嘗試了解最基礎(chǔ)的系統(tǒng)設(shè)計。
作者:HannahLin 來源:medium
原文:https://medium.com/starbugs/%E5%89%8D%E7%AB%AF%E9%96%8B%E7%99%BC%E8%80%85%E4%B9%9F%E5%8F%AF%E4%BB%A5%E6%87%82%E7%9A%84%E5%9F%BA%E7%A4%8E-system-design-5468e0f43033