2022年必須要了解的20個開源NLP 庫
在本文中,我列出了當今最常用的 NLP 庫,并對其進行簡要說明。 它們在不同的用例中都有特定的優勢和劣勢,因此它們都可以作為專門從事 NLP 的優秀數據科學家備選方案。每個庫的描述都是從它們的 GitHub 中提取的。
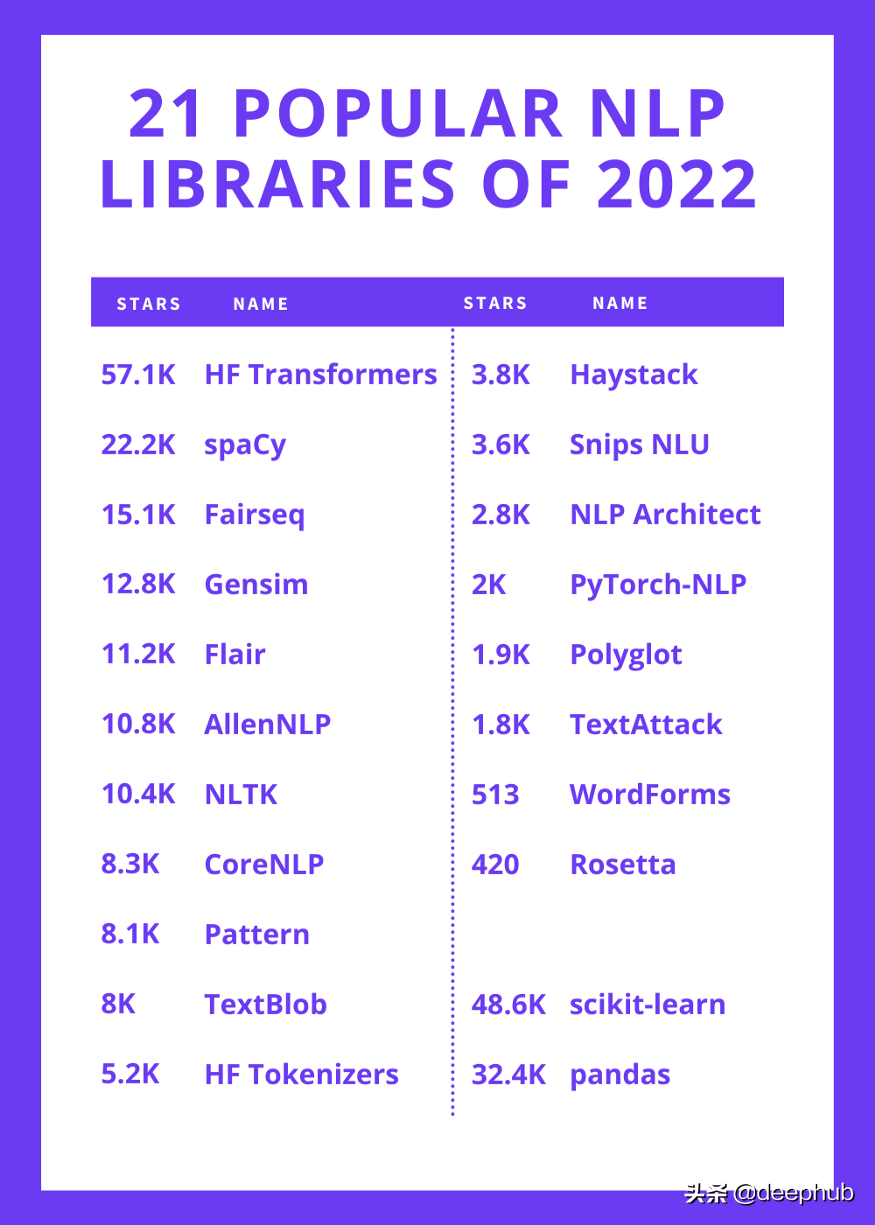
NLP庫
以下是頂級庫的列表,排序方式是在GitHub上的星數倒序。
1、Hugging Face Transformers
57.1k GitHub stars.
Transformers 提供了數千個預訓練模型來執行不同形式的任務,例如文本、視覺和音頻。 這些模型可應用于文本(文本分類、信息提取、問答、摘要、翻譯、文本生成,支持超過 100 種語言)、圖像(圖像分類、對象檢測和分割)和音頻(語音識別和音頻分類 )。 Transformer 模型還可以結合多種模式執行任務,例如表格問答、OCR、從掃描文檔中提取信息、視頻分類和視覺問答。
2、spaCy
22.2k GitHub stars.
spaCy是 Python 和 Cython 中用于自然語言處理的免費開源庫。 它從一開始就設計用于生產環境。 spaCy 帶有預訓練的管道,目前支持 60 多種語言的標記化和訓練。 它具有最先進的神經網絡模型,可以用于標記、解析、命名實體識別、文本分類、并且使用 BERT 等預訓練Transformers進行多任務學習,可以對模型進行 打包、部署和工作,方便生產環境的部署。 spaCy 是商業開源軟件,在 MIT 許可下發布。
3、Fairseq
15.1k GitHub stars.
Fairseq 是一個序列建模工具包,允許研究人員和開發人員為翻譯、摘要、語言建模和其他文本生成任務訓練自定義模型。 它提供了各種序列建模論文的參考實現。
4、Gensim
12.8k GitHub stars.
Gensim 是一個 Python 庫,用于主題建模、文檔索引和大型語料庫的相似性檢索。 目標受眾是 NLP 和信息檢索 (IR) 社區。 Gensim 具有流行算法的高效多核實現,包括但不限于Latent Semantic Analysis (LSA/LSI/SVD)、Latent Dirichlet Allocation (LDA)、Random Projections (RP)、Hierarchical Dirichlet Process(HDP) 或 word2vec 深度學習等。
5、Flair
11.2k GitHub stars.
Flair 是一個強大的 NLP 庫。 Flair 的目標是將最先進的 NLP 模型應用于文本中,例如命名實體識別 (NER)、詞性標注 (PoS)、對生物醫學數據的特殊支持、語義消歧和分類。 Flair 具有簡單的界面,允許使用和組合不同的單詞和文檔嵌入,包括 Flair 嵌入、BERT 嵌入和 ELMo 嵌入。 該框架直接構建在 PyTorch 上,可以輕松地訓練自己的模型并使用 Flair 嵌入和類庫來試驗新方法。
6、AllenNLP
10.8k GitHub stars.
AllenNLP是基于 PyTorch 構建的 NLP 研究庫,使用開源協議為Apache 2.0 ,它包含用于在各種語言任務上開發最先進的深度學習模型并提供了廣泛的現有模型實現集合,這些實現都是按照高標準設計,為進一步研究奠定了良好的基礎。 AllenNLP 提供了一種高級配置語言來實現 NLP 中的許多常見方法,例如transformer、多任務訓練、視覺+語言任務、公平性和可解釋性。 這允許純粹通過配置對廣泛的任務進行實驗,因此使用者可以專注于解決研究中的重要問題。
7、NLTK
10.4k GitHub stars.
NLTK — Natural Language Toolkit — 是一套支持自然語言處理研究和開發的開源 Python 包、數據集和教程的集合。 它為超過 50 個語料庫和詞匯資源(如 WordNet)提供易于使用的接口,以及一套用于分類、標記化、詞干提取、標記、解析和語義推理的文本處理庫。
8、CoreNLP
8.3k GitHub stars.
斯坦福 CoreNLP 提供了一組用 Java 編寫的自然語言分析工具。 它可以接收原始的人類語言文本輸入,并給出單詞的基本形式、詞性、公司名稱、人名等,規范化和解釋日期、時間和數字量,標記句子的結構 在短語或單詞依賴方面,并指出哪些名詞短語指的是相同的實體。
9、Pattern
8.1k GitHub stars.
注意:該庫已經2年沒有更新了
Pattern 是 Python 的web的挖掘工具包,它包含了:網絡服務(谷歌、推特、維基百科)、網絡爬蟲和 HTML DOM 解析器。 它有幾個自然語言處理模型:詞性標注器、n-gram 搜索、情感分析和 WordNet。 它實現了機器學習模型:向量空間模型、聚類、分類(KNN、SVM、感知器)。 模式也可用于網絡分析:圖形中心性和可視化。
10、TextBlob
8k GitHub stars.
TextBlob 是一個用于處理文本數據的 Python 庫。 它提供了一個簡單的 API,用于深入研究常見的自然語言處理任務,例如詞性標注、名詞短語提取、情感分析、分類、翻譯等。 TextBlob 站在 NLTK 和 Pattern 的基礎上制作,并且可以很好地與兩者配合使用。
11、Hugging Face Tokenizers
5.2k GitHub stars.
該庫提供了當今最常用的標記器的實現,重點是性能和通用性。
12、Haystack
3.8k GitHub stars.
Haystack 是一個端到端框架,能夠為不同的搜索用例構建功能強大且可用于生產的管道。 無論要執行問答還是語義文檔搜索,都可以使用 Haystack 中最先進的 NLP 模型來提供獨特的搜索體驗并為用戶提供使用自然語言進行查詢的功能。 Haystack 以模塊化方式構建,因此可以結合其他開源項目(如 Huggingface 的 Transformers、Elasticsearch 或 Milvus)。
13、Snips NLU
3.6k GitHub stars.
注意:該庫已經2年沒有更新了
Snips NLU 是一個可以從用自然語言編寫的句子中提取結構化信息的 Python 庫。 每當用戶使用自然語言與人工智能交互時,他們的文字都需要被翻譯成機器可讀的形式(向量)。 Snips NLU 的 NLU(自然語言理解)引擎首先檢測用戶的意圖是什么(也就是意圖),然后提取查詢的參數(稱為slots)。
14、NLP Architect
2.8k GitHub stars.
NLP Architect 是一個用于探索用于優化自然語言處理和自然語言理解神經網絡的最先進的深度學習拓撲和技術的Python 庫。 它允許在應用程序中輕松快速地集成 NLP 模型,并展示優化的模型。
15、PyTorch-NLP
2k GitHub stars.
PyTorch-NLP 擴展了 PyTorch并提供基本的文本數據處理功能。
16、Polyglot
1.9k GitHub stars.
Polyglot 是一個支持大量多語言應用程序的自然語言管道:標記化(165 種語言)、語言檢測(196 種語言)、命名實體識別(40 種語言)、部分語音標記(16 種語言)、情感分析(136 種語言)、Word 嵌入(137 種語言)、形態分析(135 種語言)和音譯(69 種語言)。
但是該庫的最新更新時間是3年前。
17、TextAttack
1.8k GitHub stars.
TextAttack 是一個用于 NLP 中的對抗性攻擊、數據增強和模型訓練 的Python 框架。
18、Word Forms
513 GitHub stars.
Word forms可以準確地生成一個英語單詞的所有可能形式。 它可以連接不同的詞性,例如名詞與形容詞、形容詞與副詞、名詞與動詞等。
19、Rosetta
420 GitHub stars.
Rosetta 是一個基于 TensorFlow 的隱私保護框架。 它集成了主流的隱私保護計算技術,包括密碼學、聯邦學習和可信執行環境。 Rosetta 重用了 TensorFlow 的 API,只需極少的代碼更改,就可以將傳統的 TensorFlow 代碼轉換為隱私保護的方式運行。
必備基礎庫
這里列出了一些并非特定于 NLP 但仍然經常用于 NLP 項目的數據科學庫。
20、scikit-learn
48.6k GitHub stars.
Scikit-learn(也稱為 sklearn)是 Python 編程語言的免費軟件機器學習庫。 它具有各種分類、回歸和聚類算法,包括支持向量機、隨機森林、梯度提升、k-means 和 DBSCAN,是建立在 Python 數值和科學庫 NumPy 和 SciPy 之上的。
21、Pandas
32.4 GitHub stars.
Pandas 是一個提供了操作表格數據的Python 包。 它已經成為在 Python 中進行實際的、真實的數據分析的基礎模塊。 它可以被稱作最強大、最靈活的開源數據分析/操作工具。