從數據庫獲取數據,必須要了解Python生成器
介紹
作為數據工程師,我們經常面臨這樣的情況:我們必須從運營數據庫中獲取一個特別大的數據集,對其進行一些轉換,然后將其寫回分析數據庫或云對象存儲(例如S3桶)。
如果數據集太大無法裝入內存,但同時使用分布式計算不值得或不可行,該怎么辦呢?
在這種情況下,我們需要找到一種方法,在不影響數據團隊其他同事(例如通過使用Airflow實例中可用內存的大部分)的情況下完成工作。這就是Python生成器可能會派上用場的時候,通過避免內存峰值來高效地從數據庫獲取數據。
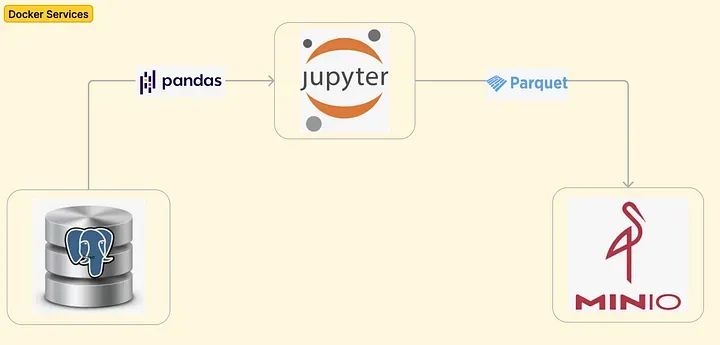
事實上,在本教程中,我們將通過旋轉運行三個服務(PostgresDB、Jupyter Notebook和MinIO)的Docker容器來模擬一個真實的端到端數據工作流程,探討在數據工程師中使用生成器的兩個實際用例。

Python中使用生成器的優點
在Python中,標準函數計算并返回單個值然后終止,而生成器可以隨時間產生一系列值,根據需要暫停和恢復。生成器是一種特殊的函數,它使用`yield`子句而不是`return`來產生一系列的值。值逐個創建,無需將整個序列存儲在內存中。
當調用生成器函數時,它返回一個迭代器對象,可以用于迭代生成器產生的值的序列。例如,讓我們創建一個squares_generator(n)函數,該函數生成介于零和輸入變量n之間的數字的平方:
def squares_generator(n):
num = 0
while num < n:
yield num * num
num += 1當調用該函數時,它只返回一個迭代器:
squares_generator(n)
#Output:
# <generator object squares_generator at 0x10653bdd0>為了觸發整個值序列,我們必須在循環中調用生成器函數:
for num in squares_generator(5):
print(num)
#Output:
0
1
4
9
16另一種更優雅的選擇是創建一個生成器表達式,它執行與上述函數相同的操作,但作為一行代碼:
n = 5
generator_exp = (num * num for num in range(n))現在,可以直接使用`next()`方法訪問值:
print(next(generator_exp)) # 0
print(next(generator_exp)) # 1
print(next(generator_exp)) # 4
print(next(generator_exp)) # 9
print(next(generator_exp)) # 16正如我們所看到的,生成器函數返回值的方式并不像常規Python函數那樣直觀,這可能是為什么許多數據工程師沒有像他們應該的那樣經常使用生成器的原因。
目標與設置
本教程的目標是:
- 從Postgres數據庫中獲取數據并將其存儲為pandas數據框。
- 將pandas數據框以parquet格式寫入S3桶。
每個目標都將使用常規函數和生成器函數兩種方法實現。為了模擬這樣的工作流程,我們將使用三個服務旋轉一個Docker容器:
- Postgres數據庫(這個服務將是我們的源操作數據庫,從中獲取數據。Docker-compose還涉及創建一個mainDB,以及在名為transactions的表中插入500萬個模擬記錄。請注意:可以插入任意數量的行來模擬一個更大的數據集(在準備本教程的材料時,嘗試過5000萬和1億行),但Docker服務的性能會受到嚴重影響。)
- MinIO(這個服務將用于模擬AWS S3桶,然后使用awswrangler包幫助將pandas數據框以parquet格式寫入其中。)
- Jupyter Notebook(這個服務將用于通過熟悉的編譯器以交互方式運行Python片段。)
下面的圖表是對到目前為止所描述的內容的可視化表示:
第一步,我們項目的GitHub存儲庫并切換到相關文件夾:
git clone git@github.com:anbento0490/projects.git &&
cd fetch_data_with_python_generators然后,我們可以運行docker-compose來啟動這三個服務:
docker compose up -d
[+] Running 5/5
? Network shared-network Created 0.0s
? Container jupyter-notebooks Started 1.0s
? Container minio Started 0.7s
? Container postgres-db Started 0.9s
? Container mc Started最終,我們可以驗證:
(1) 在Postgres數據庫中存在一個名為transactions的表,其中包含5百萬條記錄。
docker exec -it postgres-db /bin/bash
root@9632469c70e0:/# psql -U postgres
psql (13.13 (Debian 13.13-1.pgdg120+1))
Type "help" for help.
postgres=# \c mainDB
You are now connected to database "mainDB" as user "postgres".
mainDB=# select count(*) from transactions;
count
---------
5000000
(1 row)(2) 可以通過端口localhost:9001訪問MinIO UI(在要求憑據時插入管理員和密碼),并且已經創建了一個名為generators-test-bucket的空桶:
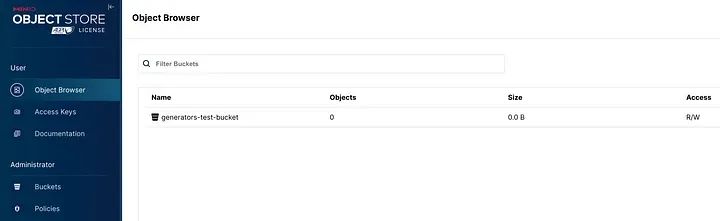
MinIO UI端口9001處的用戶界面
(3) 可以通過localhost:8889訪問Jupyter Notebook用戶界面,并通過以下方法檢索令牌:
docker exec -it jupyter-notebooks /bin/bash
root@eae08d1f4bf6:~# jupyter server list
Currently running servers:
http://eae08d1f4bf6:8888/?token=8a45d846d03cf0c0e4584c3b73af86ba5dk9e83c8ac47ee7 :: /home/jovyan
很好!我們已經準備好在Jupyter上運行一些代碼了。但在我們這樣做之前,我們需要創建一個新的access_key和secret_access_key,以便能夠與MinIO桶進行交互:
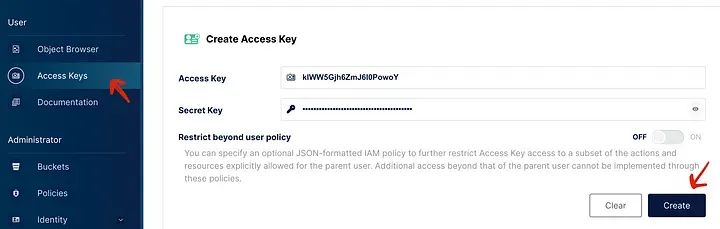
如何在MinIO中生成新的密鑰對
注意:MinIO桶的最酷的功能之一是,我們可以與它們交互,就像它們是AWS S3桶一樣(例如使用boto3、awswrangler等),但它們是免費的,而且無需擔心暴露密鑰,因為它們僅存在于我們的本地環境中,并且除非持久保存,否則將在容器停止時被刪除。
現在,在生成器筆記本中,讓我們運行以下代碼(確保替換secrets):
import psycopg2
import pandas as pd
import boto3
import awswrangler as wr
#######################################################
######## CONNECTING TO PG DB + CREATING CURSORS #######
connection = psycopg2.connect(user="postgres",
password="postgres",
port="5432",
database="mainDB")
cursor = connection.cursor()
query = "select * from transactions;"
#######################################################
######## CONNECTING TO MINIO BUCKET ###################
boto3.setup_default_session(aws_access_key_id = 'your_access_key',
aws_secret_access_key = 'your_secret_key')
bucket = 'generators-test-bucket'
folder_gen = 'data_gen'
folder_batch = 'data_batch'
parquet_file_name = 'transactions'
batch_size = 1000000
wr.config.s3_endpoint_url = 'http://minio:9000'這將創建一個連接到mainDB的連接以及用于執行查詢的游標。還將設置一個default_session,以與generators-test-bucket進行交互。
用例 #1:從數據庫讀取數據
作為數據工程師,在將大型數據集從數據庫或外部服務抓取到Python管道中時,我們經常需要在以下方面找到合適的平衡:
- 內存:一次性拉取整個數據集可能導致OOM錯誤或影響整個實例/集群的性能。
- 速度:逐行獲取數據也會導致昂貴的I/O網絡操作。
方法 #1:使用批處理
一個合理的折衷方案(在實踐中經常使用)是以批處理方式獲取數據,其中批處理的大小取決于可用內存以及數據管道的速度要求。
# 1.1. CREATE DF USING BATCHES
def create_df_batch(cursor, batch_size):
print('Creating pandas DF using generator...')
colnames = ['transaction_id',
'user_id',
'product_name',
'transaction_date',
'amount_gbp']
df = pd.DataFrame(columns=colnames)
cursor.execute(query)
while True:
rows = cursor.fetchmany(batch_size)
if not rows:
break
# some tramsformation
batch_df = pd.DataFrame(data = rows, columns=colnames)
df = pd.concat([df, batch_df], ignore_index=True)
print('DF successfully created!\n')
return df上面的代碼執行以下操作:
- 創建一個空的df(數據框);
- 執行查詢,將整個結果緩存到游標對象中;
- 初始化一個while循環,每次迭代都獲取等于指定batch_size的行數(在此示例中為1百萬行),并使用這些數據創建一個batch_df(批數據框)。
- 最終將batch_df附加到主df。該過程重復進行,直到整個數據集被遍歷。
讓我們明確一下:這只是一個基本示例,我們可以在while循環的一部分執行許多其他操作(過濾、排序、聚合、將數據寫入其他位置等),而不僅僅是一次一個批次地創建df。當在筆記本中執行該函數時,我們得到:
%%time
df_batch = create_df_batch(cursor, batch_size)
df_batch.head()
Output:
Creating pandas DF using generator...
DF successfully created!
CPU times: user 9.97 s, sys: 13.7 s, total: 23.7 s
Wall time: 25 s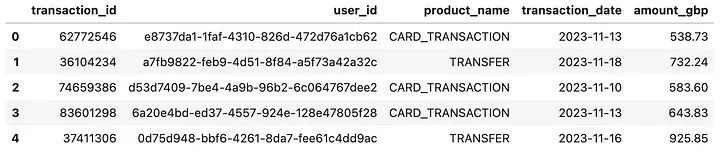
df_batch數據框的前5行
方法 #2:使用生成器
一種不太常見但強大的數據工程師策略是使用生成器以流的形式獲取數據:
# AUXILIARY FUNCTION
def generate_dataset(cursor):
cursor.execute(query)
for row in cursor.fetchall():
# some tramsformation
yield row
# 2.1. CREATE DF USING GENERATORS
def create_df_gen(cursor):
print('Creating pandas DF using generator...')
colnames = ['transaction_id',
'user_id',
'product_name',
'transaction_date',
'amount_gbp']
df = pd.DataFrame(data = generate_dataset(cursor), columns=colnames)
print('DF successfully created!\n')
return df在上面的代碼片段中,我們創建了`generate_dataset` 輔助函數,該函數執行查詢,然后將行作為序列生成。該函數直接傳遞給`pd.DataFrame()` 子句的`data`參數,該子句在背后遍歷所有獲取的記錄,直到行被耗盡。
同樣,這個例子非常基礎(主要是為了演示目的),但我們可以在輔助函數中執行任何類型的過濾或轉換。當執行該函數時,我們得到df_gen數據框的前5行
%%time
df_gen = create_df_gen(cursor)
df_gen.head()
Creating pandas DF using generator...
DF successfully created!
CPU times: user 9.04 s, sys: 2.1 s, total: 11.1 s
Wall time: 14.4 s
看起來似乎兩種方法最終都使用了同樣的內存量(因為df都是以不同方式返回的),但事實并非如此,因為數據在生成df本身時的處理方式是不同的:
- 對于方法 #1,是急切地獲取數據,通過網絡進行數據交換有點低效,導致內存占用峰值較高;
- 對于方法 #2,是懶惰地獲取數據,只有在需要時才計算,并且逐個計算,從而降低內存占用。
用例 #2:寫入云對象存儲
有時,數據工程師需要獲取存儲在數據庫中的大量數據,并將這些記錄外部共享(例如與監管機構、審計員、合作伙伴共享)。
一種常見的解決方案是創建一個云對象存儲,數據將被傳遞到該存儲中,以便第三方(具有適當訪問權限的人)能夠讀取并將數據復制到其系統中。
實際上,我們創建了一個名為`generators-test-bucket`的桶,數據將以parquet格式寫入其中,利用了`awswrangler`包。
`awswrangler`的優勢在于它與pandas數據框非常有效地配合,并允許以保留數據集結構的方式將它們轉換為parquet格式。
方法 #1:使用批處理
與第一個用例一樣,一個常見的解決方案是以批處理方式獲取數據,然后寫入數據,直到整個數據集被遍歷:
# 1.2 WRITING DF TO MINIO BUCKET IN PARQUET FORMAT USING BATCHES
def write_df_to_s3_batch(cursor, bucket, folder, parquet_file_name, batch_size):
colnames = ['transaction_id',
'user_id',
'product_name',
'transaction_date',
'amount_gbp']
cursor.execute(query)
batch_num = 1
while True:
rows = cursor.fetchmany(batch_size)
if not rows:
break
print(f"Writing DF batch #{batch_num} to S3 bucket...")
wr.s3.to_parquet(df= pd.DataFrame(data = rows, columns=colnames),
path=f's3://{bucket}/{folder}/{parquet_file_name}',
compression='gzip',
mode = 'append',
dataset=True)
print('Batch successfully written to S3 bucket!\n')
batch_num += 1執行`write_df_to_s3_batch()` 函數會在桶中創建五個parquet文件,每個文件包含1百萬條記錄:
write_df_to_s3_batch(cursor, bucket, folder_batch, parquet_file_name, batch_size)
Writing DF batch #1 to S3 bucket...
Batch successfully written to S3 bucket!
Writing DF batch #2 to S3 bucket...
Batch successfully written to S3 bucket!
Writing DF batch #3 to S3 bucket...
Batch successfully written to S3 bucket!
Writing DF batch #4 to S3 bucket...
Batch successfully written to S3 bucket!
Writing DF batch #5 to S3 bucket...
Batch successfully written to S3 bucket!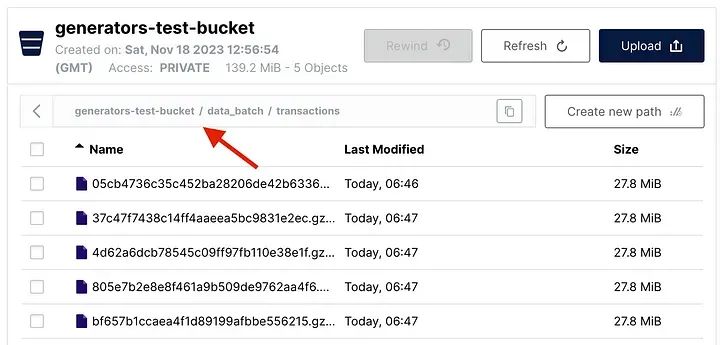
在MinIO中以批處理方式寫入的數據
方法 #2:使用生成器
或者,可以通過利用生成器提取數據并將其寫入桶中。由于生成器在提取和移動數據時不會導致內存效率問題,我們甚至可以決定一次性寫入整個df:
# 2.2 WRITING DF TO MINIO BUCKET IN PARQUET FORMAT USING GENERATORS
def write_df_to_s3_gen(cursor, bucket, folder, parquet_file_name):
print('Writing DF to S3 bucket...')
colnames = ['transaction_id',
'user_id',
'product_name',
'transaction_date',
'amount_gbp']
wr.s3.to_parquet(df= pd.DataFrame(data = generate_dataset(cursor), columns=colnames),
path=f's3://{bucket}/{folder}/{parquet_file_name}',
compression='gzip',
mode = 'append',
dataset=True)
print('Data successfully written to S3 bucket!\n')當執行`write_df_to_s3_gen()` 函數時,將一個包含所有5百萬行的唯一較大parquet文件保存到桶中:
write_df_to_s3_gen(cursor, bucket, folder_gen, parquet_file_name)
Writing DF to S3 bucket...
Data successfully written to S3 bucket!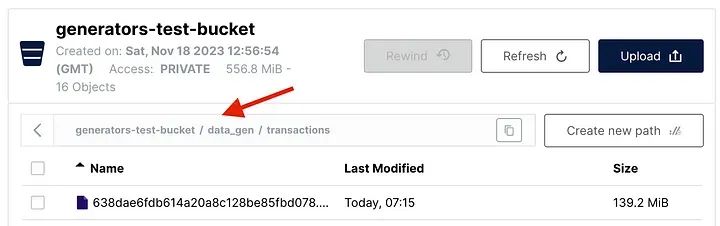
利用生成器寫入MinIO的數據