2040張圖片訓(xùn)練出的ViT,準(zhǔn)確率96.7%,連遷移性能都令人驚訝
本文經(jīng)AI新媒體量子位(公眾號(hào)ID:QbitAI)授權(quán)轉(zhuǎn)載,轉(zhuǎn)載請(qǐng)聯(lián)系出處。
ViT在計(jì)算機(jī)視覺(jué)領(lǐng)域取得了巨大的成功,甚至大有取代CNN之勢(shì)。
但是相比CNN,訓(xùn)練ViT需要更多的數(shù)據(jù),通常要在大型數(shù)據(jù)集JFT-300M或至少在ImageNet上進(jìn)行預(yù)訓(xùn)練,很少有人研究少量數(shù)據(jù)訓(xùn)練ViT。
最近,南京大學(xué)吳建鑫團(tuán)隊(duì)提出了一種新方法,只需2040張圖片即可訓(xùn)練ViT。
他們?cè)?040張花(flowers)的圖像上從頭開(kāi)始訓(xùn)練,達(dá)到了96.7%的準(zhǔn)確率,表明用小數(shù)據(jù)訓(xùn)練ViT也是可行的。
另外在ViT主干下的 7 個(gè)小型數(shù)據(jù)集上從頭開(kāi)始訓(xùn)練時(shí),也獲得了SOTA的結(jié)果。
而且更重要的是,他們證明了,即使在小型數(shù)據(jù)集上進(jìn)行預(yù)訓(xùn)練,ViT也具有良好的遷移能力,甚至可以促進(jìn)對(duì)大規(guī)模數(shù)據(jù)集的訓(xùn)練。
論文內(nèi)容
在這篇論文中,作者提出了用于自我監(jiān)督 ViT訓(xùn)練的IDMM(Instance Discrimination with Multi-crop and CutMix)。
我們先來(lái)看一下ViT圖像分類網(wǎng)絡(luò)的基本架構(gòu):
將圖像樣本x?(i = 1, 2, …, N; N為圖片數(shù)量)送入ViT中,得到一組輸出表征z?。w?為第j個(gè)分類的權(quán)重。
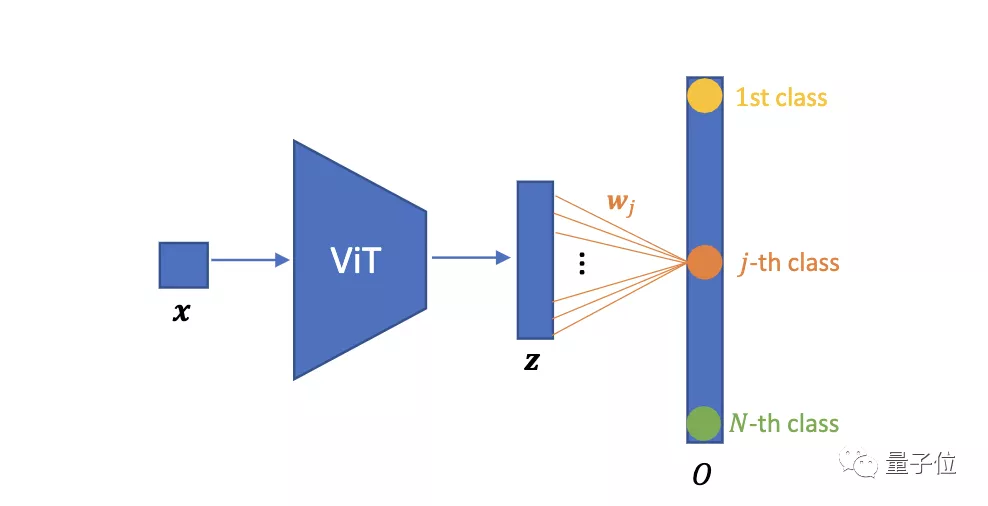
然后,使用全連接層W進(jìn)行分類,當(dāng)類的數(shù)量等于訓(xùn)練圖像的總數(shù)N時(shí),即參數(shù)化實(shí)例判別。
第j類的輸出為:
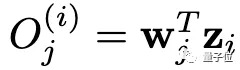
我們把O送入Softmax層,就得到一個(gè)概率分布P???。對(duì)于實(shí)例判別,損失函數(shù)為:
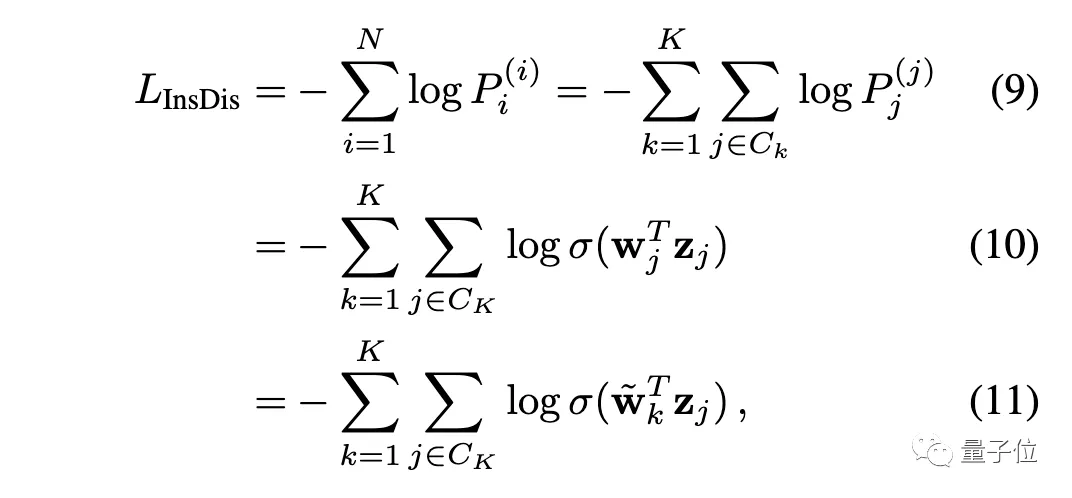
對(duì)于深度聚類,其損失函數(shù)為:
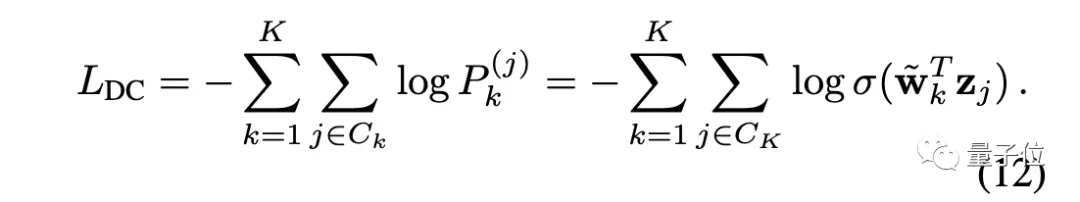
可以看出,只要適當(dāng)設(shè)置權(quán)重(讓w? = ~w? ),就可以讓實(shí)例判別等價(jià)于深度聚類。
從下圖中可以看出,與其他方法相比,實(shí)例判別可以學(xué)習(xí)到更多的分布式表征,并能更好地捕捉到類內(nèi)的相似性。
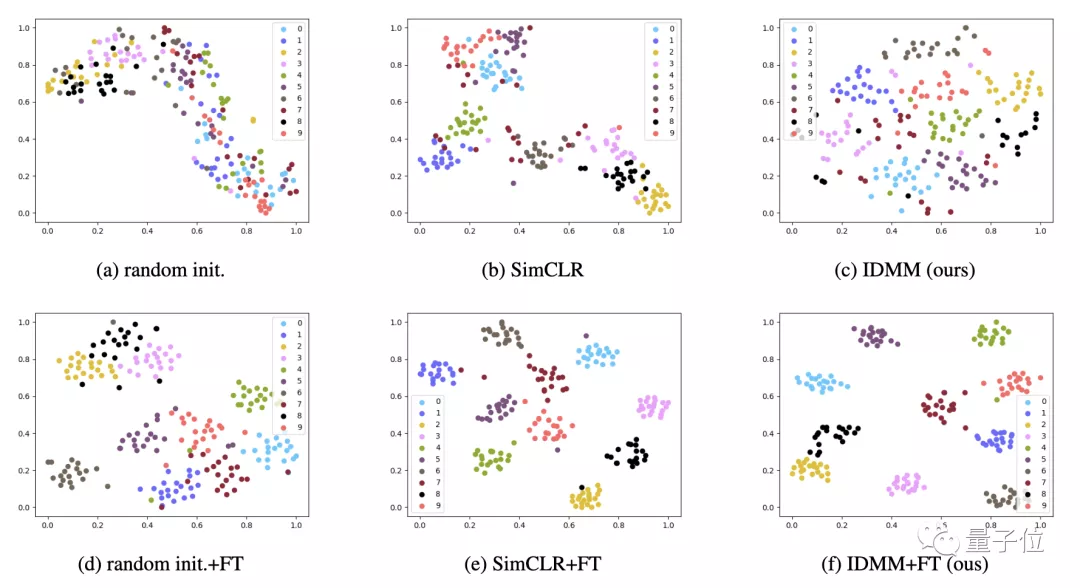
作者之所以選擇參數(shù)化的實(shí)例判別,還有一個(gè)重要的原因:簡(jiǎn)單性和穩(wěn)定性。
不穩(wěn)定性是影響自監(jiān)督ViT訓(xùn)練的一個(gè)主要問(wèn)題。實(shí)例判別(交叉熵)的形式更穩(wěn)定,更容易優(yōu)化。
接下來(lái)開(kāi)始梯度分析,損失函數(shù)對(duì)權(quán)重求導(dǎo):
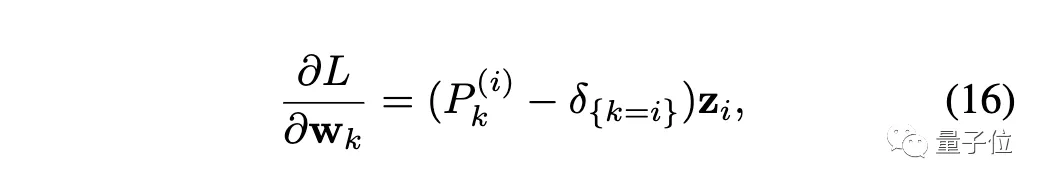
其中δ是指示函數(shù),當(dāng)k=i時(shí)值為1,否則為0。
需要注意的是,對(duì)于實(shí)例判別,類的數(shù)量N通常很大,而且存在對(duì)實(shí)例樣本訪問(wèn)極稀少的問(wèn)題。
對(duì)于稀少的實(shí)例k≠i,可以預(yù)計(jì)P????≈0,因此?L/?w?≈0,這意味著w?的更新頻率極低。
在小數(shù)據(jù)集問(wèn)題上,作者使用CutMix和標(biāo)簽平滑,來(lái)緩解此問(wèn)題。
CutMix:
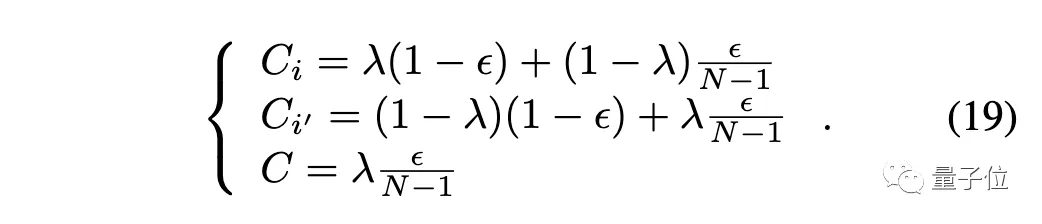
標(biāo)簽平滑:
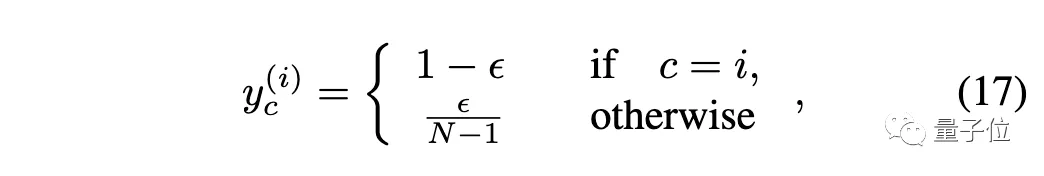
最后梯度變?yōu)椋?/p>
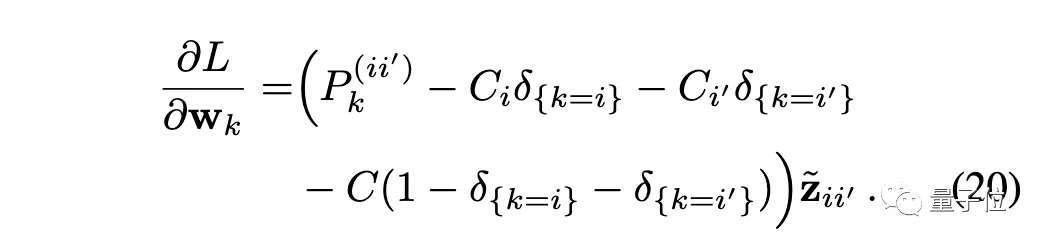
這樣通過(guò)直接修改單次標(biāo)簽,來(lái)更頻繁地更新權(quán)重矩陣,也是ViT監(jiān)督訓(xùn)練中常用的方法。
總之,作者使用了以下策略來(lái)加強(qiáng)小數(shù)據(jù)集上的實(shí)例判別。
- ?小分辨率:預(yù)訓(xùn)練中的小分辨率對(duì)小數(shù)據(jù)集很有用。
- 多次裁剪:實(shí)例判別概括了對(duì)比損失,保證了在使用多種實(shí)例時(shí)獲取特征的對(duì)齊和統(tǒng)一性。
- CutMix和標(biāo)簽平滑:有助于緩解使用實(shí)例判別時(shí)的過(guò)擬合和不經(jīng)常訪問(wèn)的問(wèn)題。
至于為什么需要直接在目標(biāo)數(shù)據(jù)集上從頭開(kāi)始訓(xùn)練,作者給出了3點(diǎn)原因:
1、數(shù)據(jù)
目前的ViT模型通常在一個(gè)大規(guī)模的數(shù)據(jù)集上進(jìn)行預(yù)訓(xùn)練,然后在各種下游任務(wù)中進(jìn)行微調(diào)。由于缺乏典型的卷積歸納偏向,這些模型比普通的CNN更耗費(fèi)數(shù)據(jù)。
因此從頭開(kāi)始訓(xùn)練ViT,能夠用圖像總量有限的任務(wù)是至關(guān)重要的。
2、算力
大規(guī)模的數(shù)據(jù)集、大量的耗時(shí)和復(fù)雜的骨干網(wǎng)絡(luò)的,讓ViT訓(xùn)練的算力成本非常昂貴。這種現(xiàn)象使ViT成為少數(shù)機(jī)構(gòu)研究人員的特權(quán)。
3、靈活性
預(yù)訓(xùn)練后再進(jìn)行下游微調(diào)的模式有時(shí)會(huì)很麻煩。
例如,我們可能需要為同一任務(wù)訓(xùn)練10個(gè)不同的模型,并將它們部署在不同的硬件平臺(tái)上,但在一個(gè)大規(guī)模的數(shù)據(jù)集上預(yù)訓(xùn)練10個(gè)模型是不現(xiàn)實(shí)的。
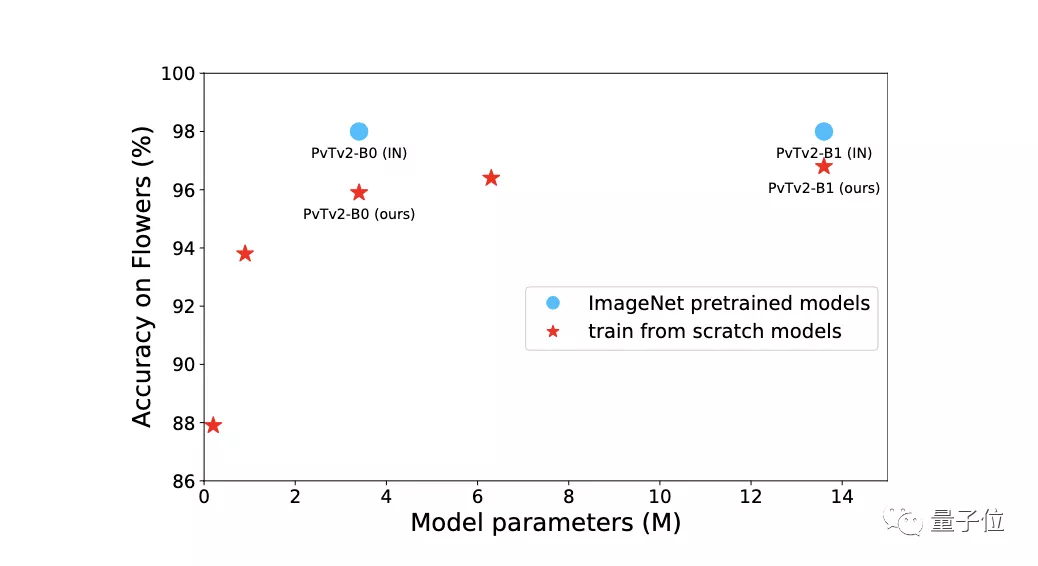
在上圖中,很明顯與從頭開(kāi)始訓(xùn)練相比,ImageNet預(yù)訓(xùn)練的模型需要更多的參數(shù)和計(jì)算成本。
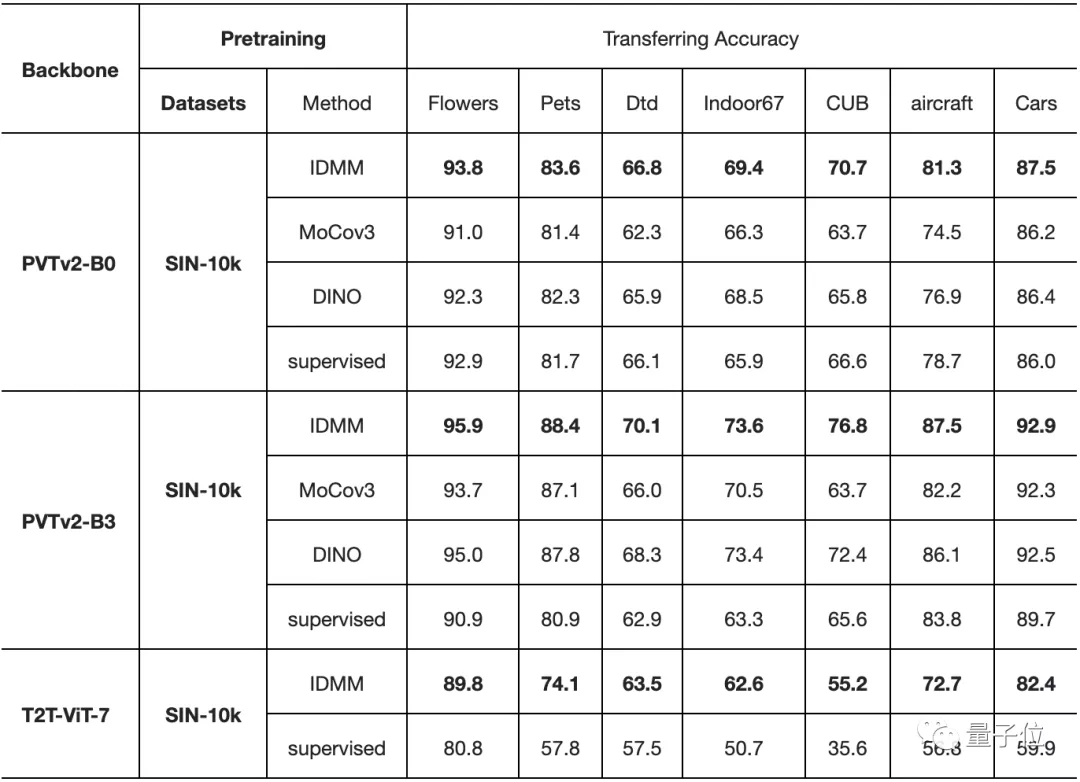
在小數(shù)據(jù)集上進(jìn)行預(yù)訓(xùn)練時(shí)的遷移能力。每個(gè)單元格和列中精度最高的元素分別用下劃線和粗體表示
最后,在下表中,作者評(píng)估了在不同數(shù)據(jù)集上預(yù)訓(xùn)練模型的遷移精度。
對(duì)角線上的單元(灰色)是在同一數(shù)據(jù)集上進(jìn)行預(yù)訓(xùn)練和微調(diào)。對(duì)角線外的單元格評(píng)估了這些小數(shù)據(jù)集的遷移性能。
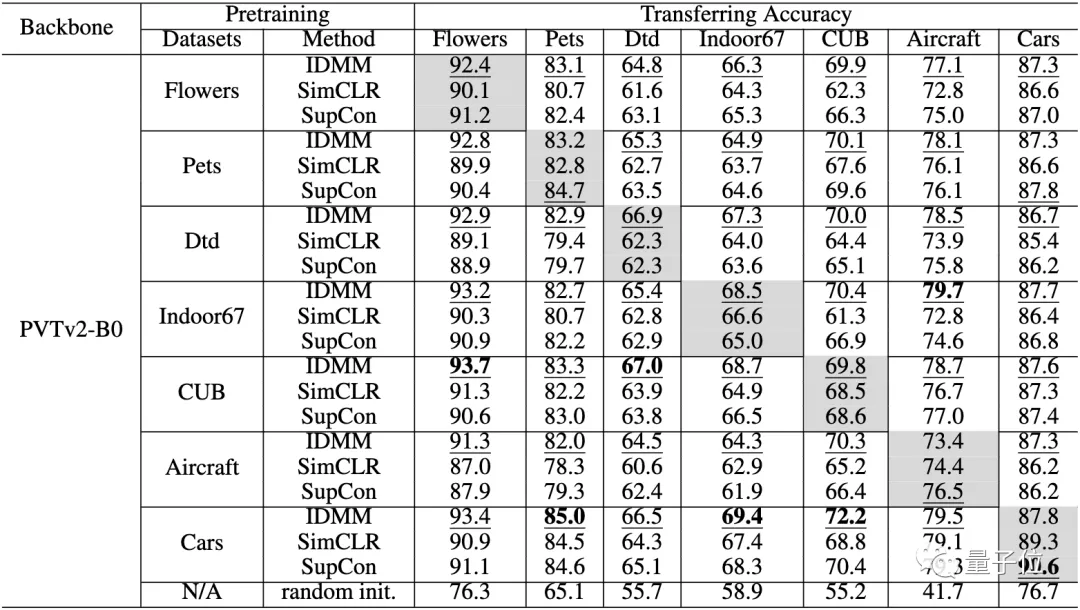
從這張表中,我們可以看到以下幾點(diǎn):
- 即使在小數(shù)據(jù)集上進(jìn)行預(yù)訓(xùn)練,ViT也有良好的遷移能力。
- 與SimCLR和SupCon相比,該方法在所有這些數(shù)據(jù)集上也有更高的遷移精度。
- 即使預(yù)訓(xùn)練的數(shù)據(jù)集和目標(biāo)數(shù)據(jù)集不在同一領(lǐng)域,也能獲得令人驚訝的好結(jié)果。例如,在Indoor67上預(yù)訓(xùn)練的模型在轉(zhuǎn)移到Aircraft上時(shí)獲得了最高的準(zhǔn)確性。
作者簡(jiǎn)介
本文第一作者是南京大學(xué)在讀博士曹云浩,通訊作者是南京大學(xué)人工智能學(xué)院吳建鑫教授。

吳建鑫本科和碩士畢業(yè)于南京大學(xué)計(jì)算機(jī)專業(yè),博士畢業(yè)于佐治亞理工。2013年,他加入南京大學(xué)科學(xué)與技術(shù)系,任教授、博士生導(dǎo)師,曾擔(dān)任ICCV 2015領(lǐng)域主席、CVPR 2017領(lǐng)域主席,現(xiàn)為Pattern Recognition期刊編委。