













聊聊無鎖編程設計
本文轉載自微信公眾號「Code視角」,作者Code視角。轉載本文請聯(lián)系Code視角公眾號。
什么是無鎖編程
LOCK-FREE,字面解釋就是不通過鎖來解決多線程、多進程之間的數(shù)據(jù)同步和訪問的程序設計方案。相對來說就是通過數(shù)據(jù)結構和算法來解決數(shù)據(jù)并發(fā)沖突的實現(xiàn)方案。
無鎖編程的實現(xiàn)
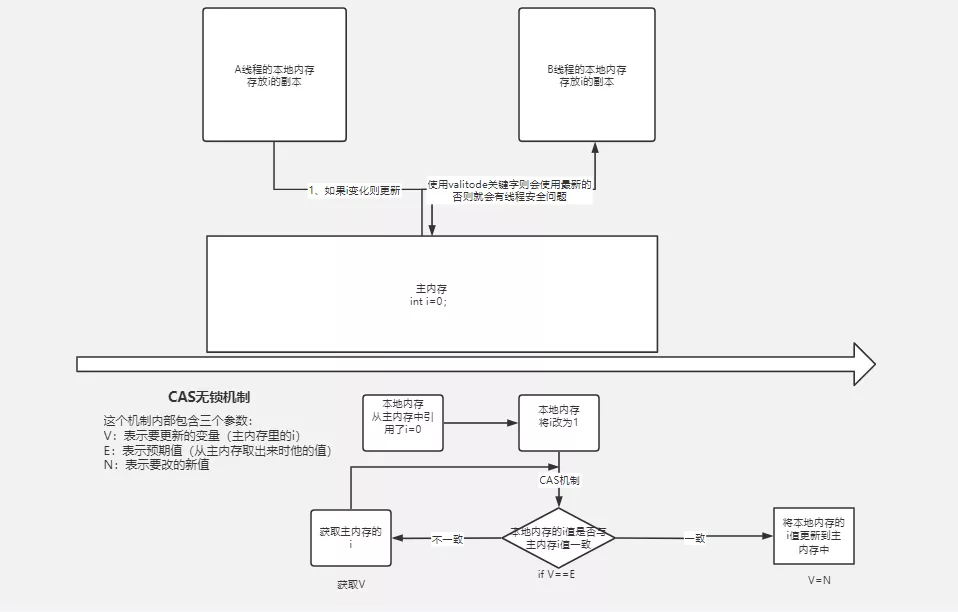
「比較并交換 Compare-and-swap」
compare and swap,解決多線程并行情況下使用鎖造成性能損耗的一種機制,CAS操作包含三個操作數(shù)——內(nèi)存位置(V)、預期原值(A)和新值(B)。如果內(nèi)存位置的值與預期原值相匹配,那么處理器會自動將該位置值更新為新值。否則,處理器不做任何操作。無論哪種情況,它都會在CAS指令之前返回該位置的值。CAS有效地說明了“我認為位置V應該包含值A;如果包含該值,則將B放到這個位置;否則,不要更改該位置,只告訴我這個位置現(xiàn)在的值即可。(百度百科)
參考圖
使用場景
(1) 樂觀鎖的實現(xiàn)方案:不加鎖,假設沒有沖突去完成某項操作,如果因為沖突失敗就重試,直到成功為止。
缺點
(1)循環(huán)開銷問題。長時間更改不成功,會來帶大量的CPU消耗。解決方法:需要在修改失敗后執(zhí)行其它邏輯, 且CAS并不適合資源大量競爭的情況。
(2)ABA問題:線程1準備用CAS將變量的值由A替換為B,在此之前,線程2將變量的值由A替換為C,又由C替換為A,然后線程1執(zhí)行CAS時發(fā)現(xiàn)變量的值仍然為A,所以CAS成功。但實際上這時的現(xiàn)場已經(jīng)和最初不同了。
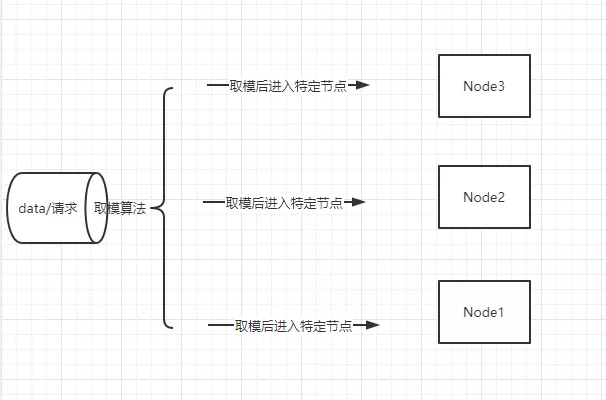
「數(shù)據(jù)Hash」
數(shù)據(jù)Hash其實就是通過Hash算法把數(shù)據(jù)提前來確定由哪個節(jié)點進行處理或者存儲,解決數(shù)據(jù)并發(fā)的思想是通過算法解決不同的數(shù)據(jù)到不同的節(jié)點。算法:數(shù)據(jù).hashCode() % 節(jié)點數(shù)量。
參考圖
使用場景
(1)定時任務處理數(shù)據(jù)時。例如:一個定時任務數(shù)據(jù)量較多,需要集群處理。那么就可以同時啟動任務讀取數(shù)據(jù),然后根據(jù)idHash來決定當前節(jié)點是否要處理這條數(shù)據(jù)。
(2)請求到指定服務器進行處理。例如:Nginx ipHash轉發(fā)策略,Kafka hash分區(qū)保證分區(qū)有序性。
缺點
(1) 擴容相對復雜,需要進行數(shù)據(jù)遷移。例如一致性hash算法,Kafka分區(qū)再均衡策略。但是某些場景不一定支持擴容。
(2) hash算法是否散列,如果算法不夠散列會出現(xiàn)數(shù)據(jù)傾斜問題。
「單線程」
某些場景下單線程的設計要比多線程更加優(yōu)秀, 單線程下不存在資源競爭、線程切換,當然也取決于你當前的服務器配置。
例如:
(1)Redis的設計上,由于內(nèi)存級別的K/V數(shù)據(jù)庫,在處理核心讀寫時如果頻繁的CPU切換、線程等待喚醒和鎖資源獲取,反倒會造成性能瓶頸。
(2)在生成分布式id的場景下, 某臺id服務器批量生成id 這個時候也可以進行單線程處理,內(nèi)存計算非常高效。
什么時候使用單線程?
(1)單核服務器。
(2)業(yè)務場景大量CPU計算且數(shù)據(jù)沖突較多的情況下(非絕對)。
無鎖編程的優(yōu)缺點
「優(yōu)點」
不會有優(yōu)先級倒置。
不會出現(xiàn)死鎖、饑餓、餓死等問題。
減少資源競爭,CPU資源消耗少,更高效。
「缺點」
具有一定的復雜性,需要一定的算法思想。
不適合所以的場景,非全局最優(yōu)解。
總結
在設計程序時, 應該考慮程序的使用場景來進行最優(yōu)的數(shù)據(jù)結構和算法來進行方案設計。無鎖編程也只是解決某些場景的一種方案,并不一定代表著最優(yōu)解。
結語
優(yōu)秀的設計模式結合優(yōu)秀的數(shù)據(jù)結構相才能帶來優(yōu)秀的代碼。編程人的內(nèi)功心法:數(shù)據(jù)結構+算法。























