聊聊流計算的兩個數據處理引擎:Spark 和 Flink

背景
談到大數據,流計算的重要性和它實時支持的強大分析是不可回避的。說到流計算,也離不開該領域最強大的兩個數據處理引擎:Spark 和 Flink。Spark和Flink都支持批處理和流處理,接下來讓我們對這兩種流行的數據處理框架在各方面進行對比。
- 批處理的特點是有界、持久、大量,非常適合需要訪問全套記錄才能完成的計算工作,一般用于離線統計。
- 流處理的特點是無界、實時, 無需針對整個數據集執行操作,而是對通過系統傳輸的每個數據項執行操作,一般用于實時統計。
Flink
介紹
Apache Flink是由Apache軟件基金會開發的開源流處理框架,其核心是用Java和Scala編寫的分布式流數據流引擎。Flink以數據并行和流水線方式執行任意流數據程序,Flink的流水線運行時系統可以執行批處理和流處理程序。此外,Flink的運行時本身也支持迭代算法的執行。Flink在實現流處理和批處理時,與傳統的一些方案完全不同,它從另一個視角看待流處理和批處理,將二者統一起來:Flink是完全支持流處理,也就是說作為流處理看待時輸入數據流是無界的;批處理被作為一種特殊的流處理,只是它的輸入數據流被定義為有界的。在Flink被apache提升為頂級項目之后,阿里實時計算團隊決定在阿里內部建立一個 Flink 分支 Blink,并對 Flink 進行大量的修改和完善,讓其適應阿里巴巴這種超大規模的業務場景。

特點
- 支持高吞吐、低延遲、高性能的流處理
- 有狀態計算的Exactly-once語義,對于一條message,receiver確保只收到一次
- 支持帶有事件時間(event time)的流處理和窗口處理。事件時間的語義使流計算的結果更加精確,尤其在事件到達無序或者延遲的情況下。
- 支持高度靈活的窗口(window)操作。支持基于time、count、session,以及data-driven的窗口操作,能很好的對現實環境中的創建的數據進行建模。
- 輕量的容錯處理( fault tolerance)。 它使得系統既能保持高的吞吐率又能保證exactly-once的一致性。通過輕量的state snapshots實現
- 支持機器學習(FlinkML)、圖分析(Gelly)、關系數據處理(Table)、復雜事件處理(CEP)
- 支持savepoints 機制(一般手動觸發)。即可以將應用的運行狀態保存下來;在升級應用或者處理歷史數據是能夠做到無狀態丟失和最小停機時間。
- 支持大規模的集群模式,支持yarn、Mesos。可運行在成千上萬的節點上
- Flink在JVM內部實現了自己的內存管理
- 支持迭代計算
- 支持程序自動優化:避免特定情況下Shuffle、排序等昂貴操作,中間結果進行緩存
- API支持,對Streaming數據類應用,提供DataStream API,對批處理類應用,提供DataSet API(支持Java/Scala)
- 支持Flink on YARN、HDFS、Kafka、HBase、Hadoop、ElasticSearch、Storm、S3等整合
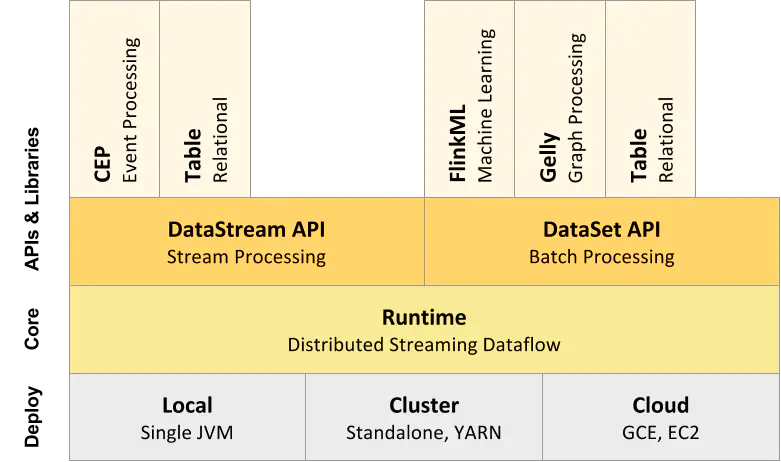
架構
系統組件
Flink的架構體系同樣也遵行分層架構設計的理念,基本上分為三層,API&Libraries層、Runtine核心層以及物理部署層。
- API&Libraries層:提供了支撐流計算和批計算的接口,同時在此基礎之上抽象出不同的應用類型的組件庫。
- Runtime 核心層:負責對上層不同接口提供基礎服務,支持分布式Stream作業的執行、JobGraph到ExecutionGraph 的映射轉換、任務調度等,將DataStream和DataSet轉成統一的可執行的Task Operator.
- 物理部署層:Flink 支持多種部署模式,本機,集群(Standalone/YARN)、云(GCE/EC2)、Kubenetes。
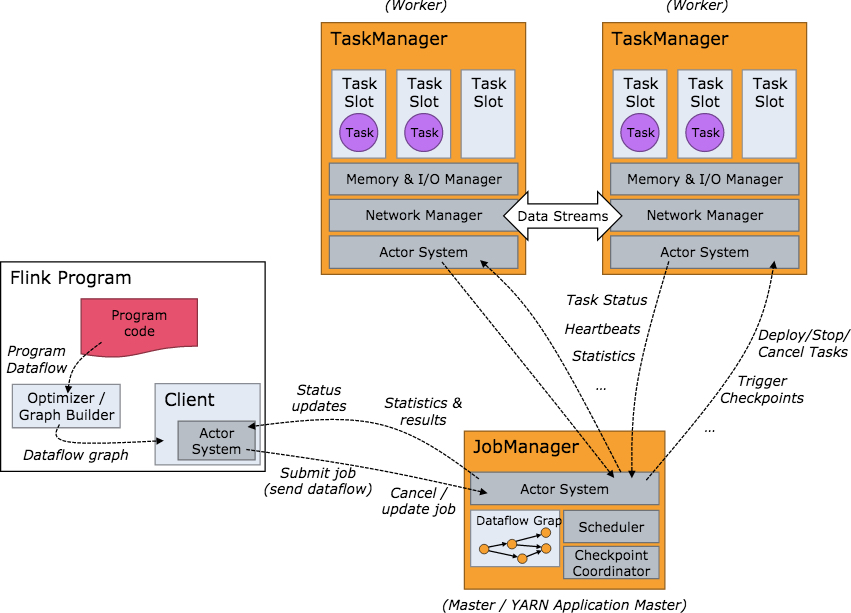
系統架構
當 Flink 集群啟動后,首先會啟動一個 JobManger 和一個或多個的 TaskManager。由 Client 提交任務給 JobManager,JobManager 再調度任務到各個 TaskManager 去執行,然后 TaskManager 將心跳和統計信息匯報給 JobManager。TaskManager 之間以流的形式進行數據的傳輸。上述三者均為獨立的 JVM 進程。
- Client 為提交 Job 的客戶端,可以是運行在任何機器上(與 JobManager 環境連通即可)。提交 Job 后,Client 可以結束進程(Streaming的任務),也可以不結束并等待結果返回。
- JobManager 主要負責調度 Job 并協調 Task 做 checkpoint,職責上很像 Storm 的 Nimbus。從 Client 處接收到 Job 和 JAR 包等資源后,會生成優化后的執行計劃,并以 Task 的單元調度到各個 TaskManager 去執行。
- TaskManager 在啟動的時候就設置好了槽位數(Slot),每個 slot 能啟動一個 Task,Task 為線程。從 JobManager 接收需要部署的 Task,部署啟動后,與自己的上游建立 Netty 連接,接收數據并處理。
Spark
介紹
Spark是一種快速、通用、可擴展的大數據分析引擎,2009年誕生于加州大學伯克利分校AMPLab,2010年開源,2013年6月成為Apache孵化項目,2014年2月成為Apache頂級項目。項目是用Scala進行編寫。目前,Spark生態系統已經發展成為一個包含多個子項目的集合,其中包含SparkSQL、Spark Streaming、GraphX、MLib、SparkR等子項目,Spark是基于內存計算的大數據并行計算框架。

特點
- 輕量級快速處理 :Spark允許傳統Hadoop集群中的應用程序在內存中以100倍的速度運行,即使在磁盤上運行也能快10倍。Spark通過減少磁盤IO來達到性能的提升,提供 Cache 機制來支持需要反復迭代計算或者多次數據共享,減少數據讀取的 IO 開銷;
- 易于使用 :Spark支持多語言。Spark允許Java、Scala、Python及R
- 支持復雜查詢 :除了簡單的map及reduce操作之外,Spark還支持filter、foreach、reduceByKey、aggregate以及SQL查詢、流式查詢等復雜查詢
- 實時的流處理 :對比MapReduce只能處理離線數據,Spark還能支持實時流計算。SparkStreaming主要用來對數據進行實時處理,當然在YARN之后Hadoop也可以借助其他的工具進行流式計算
- 通用解決方案:Spark提供了統一的解決方案。Spark可以用于批處理、交互式查詢(Spark SQL)、實時流處理(Spark Streaming)、機器學習(Spark MLlib)和圖計算(GraphX)
- 與其他開源產品集成:Spark可以使用Hadoop的YARN、Apache Mesos(已經啟用)、Kubernetes作為它的資源管理和調度器,并且可以處理所有Hadoop支持的數據,包括HDFS、HBase和Cassandra等
架構
生態組件
Spark 生態系統以Spark Core 為核心,能夠讀取傳統文件(如文本文件)、HDFS、Amazon S3、Alluxio 和NoSQL 等數據源,利用Standalone、YARN 和Mesos 等資源調度管理,完成應用程序分析與處理,這些應用程序來自Spark 的不同組件,如Spark Shell 或Spark Submit 交互式批處理方式、Spark Streaming 的實時流處理應用、Spark SQL 的即席查詢、采樣近似查詢引擎BlinkDB 的權衡查詢、MLbase/MLlib 的機器學習、GraphX 的圖處理和SparkR 的數學計算等
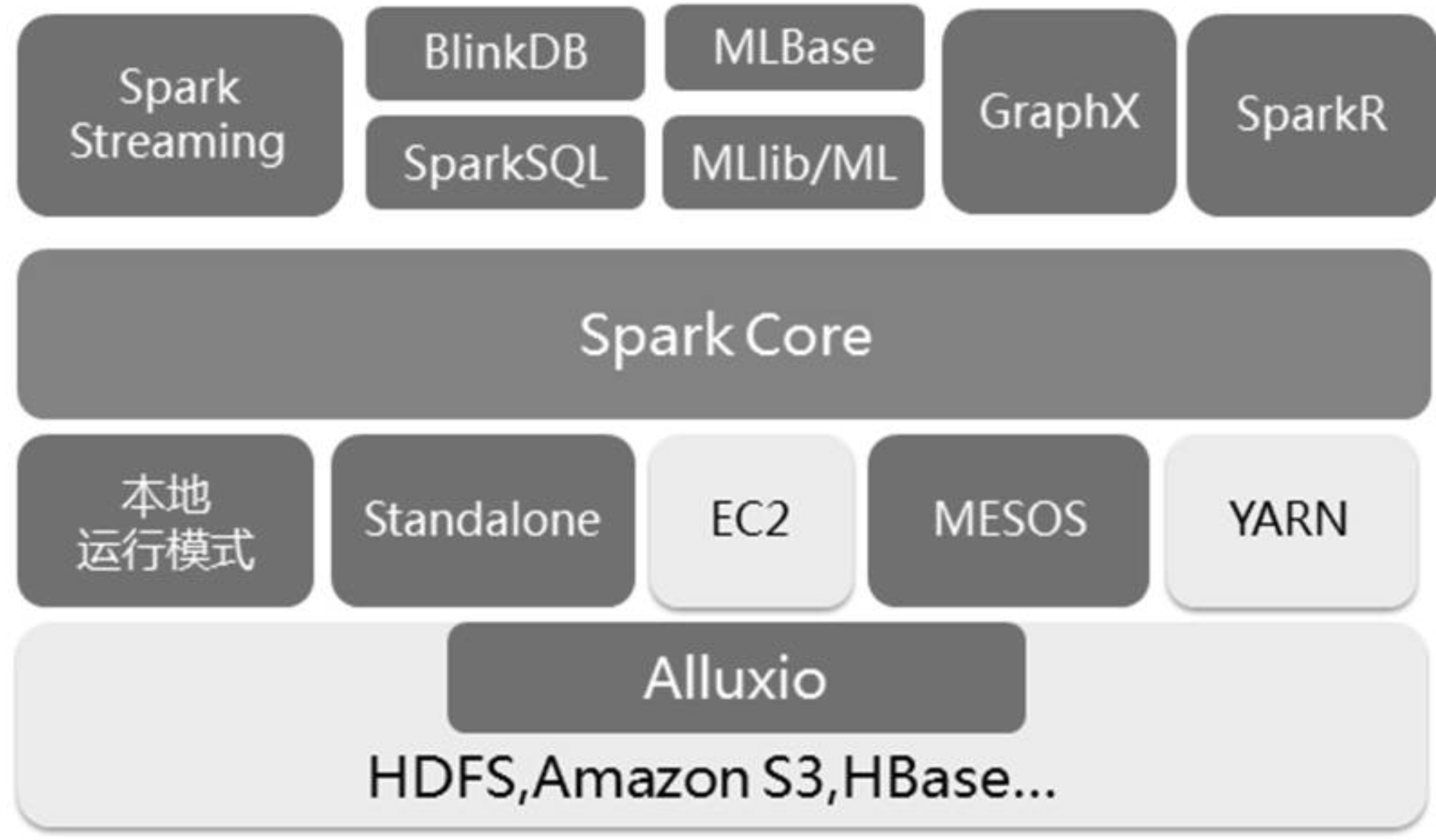
系統組件
整個 Spark 集群中,分為 Master 節點與 worker 節點,,其中 Master 節點上常駐 Master 守護進程和 Driver 進程, Master 負責將串行任務變成可并行執行的任務集Tasks, 同時還負責出錯問題處理等,而 Worker 節點上常駐 Worker 守護進程, Master 節點與 Worker 節點分工不同, Master 負載管理全部的 Worker 節點,而 Worker 節點負責執行任務。
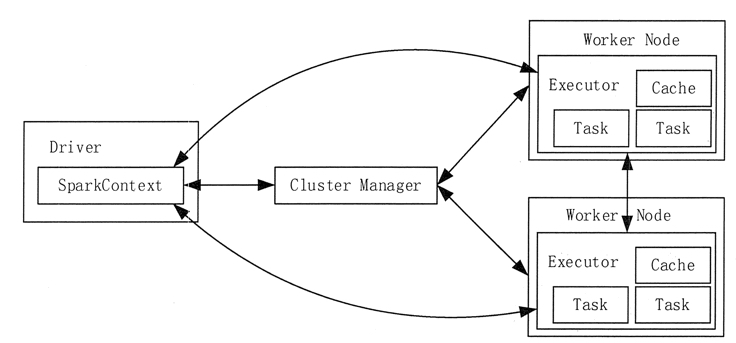
Spark的架構中的基本組件:
Cluster Manager:在standalone模式中即為Master主節點,控制整個集群,監控worker。在YARN模式中為資源管理器
Worker:從節點,負責控制計算節點,啟動Executor或者Driver。在YARN模式中為NodeManager,負責計算節點的控制。
Driver:運行Application的main()函數并創建SparkContext。
Executor:執行器,在worker node上執行任務的組件、用于啟動線程池運行任務。每個Application擁有獨立的一組Executor。
SparkContext:整個應用的上下文,控制應用的生命周期。
- RDD:Spark的基礎計算單元,一組RDD可形成執行的有向無環圖RDD Graph。
- DAG Scheduler:根據作業(task)構建基于Stage的DAG,并提交Stage給TaskScheduler。
- TaskScheduler:將任務(task)分發給Executor執行。
- SparkEnv:線程級別的上下文, 存儲運行時的重要組件的引用。
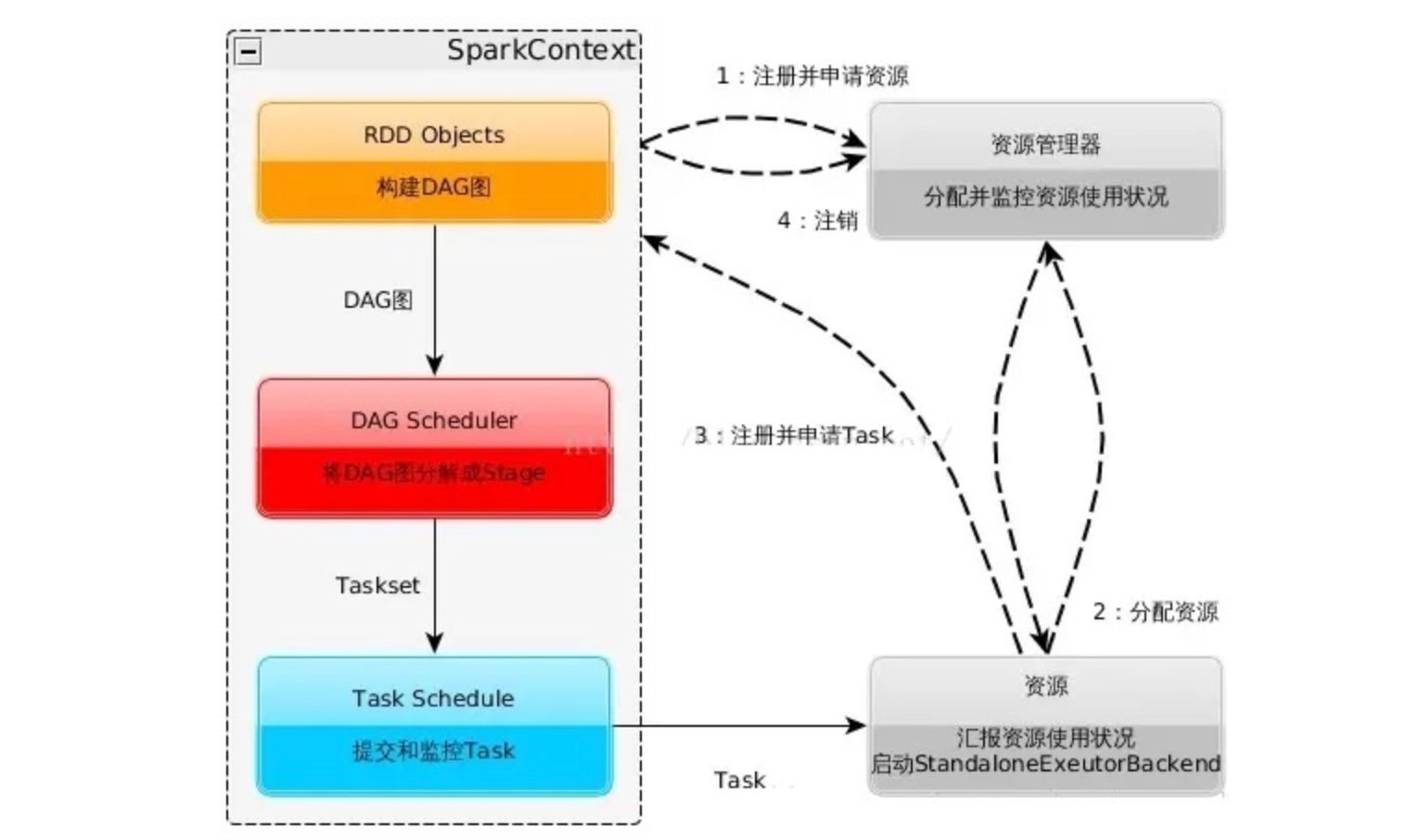
執行流程
- 構建 Spark Application 的運行環境(啟動 SparkContext),SparkContext 向 Cluster Manager 注冊,并申請運行 Executor 資源。
- Cluster Manager 為 Executor 分配資源并啟動 Executor 進程,Executor 運行情況將隨著“心跳”發送到 Cluster Manager 上。
- SparkContext 構建 DAG 圖,將 DAG 圖分解成多個 Stage,并把每個 Stage 的 TaskSet(任務集)發送給 Task Scheduler (任務調度器)。Executor 向 SparkContext 申請 Task, Task Scheduler 將 Task 發放給 Executor,同時,SparkContext 將應用程序代碼發放給 Executor。
- Task 在 Executor 上運行,把執行結果反饋給 Task Scheduler,然后再反饋給 DAG Scheduler。運行完畢后寫入數據,SparkContext 向 ClusterManager 注銷并釋放所有資源。
總結
Spark 和 Flink 都是通用的能夠支持超大規模數據處理,支持各種處理類型的計算引擎。在spark的世界觀中,一切都是由批次組成的,離線數據是一個大批次,而實時數據是由一個一個無限的小批次組成的。而在flink的世界觀中,一切都是由流組成的,離線數據是有界限的流,實時數據是一個沒有界限的流,這就是所謂的有界流和無界流。Apache Spark 和 Flink 都是備受業界關注的大數據工具。兩者都提供與 Hadoop 和 NoSQL 數據庫的集成,并且可以處理 HDFS 數據。但由于其底層架構,Flink 比 Spark 更快。Spark流處理的實時性還不夠,所以無法用在一些對實時性要求很高的流處理場景中。這是因為 Spark的流處理是基于所謂微批處理( Micro- batch processing)的思想,即它把流處理看作是批處理的一種特殊形式,每次接收到一個時間間隔的數據才會去處理,所以天生很難在實時性上有所提升。采用了基于操作符(Operator)的連續流模型,可以做到微秒級別的延遲。
從流處理的角度來講,Spark基于微批量處理,把流數據看成是一個個小的批處理數據塊分別處理,所以延遲性只能做到秒級。而Flink基于每個事件處理,每當有新的數據輸入都會立刻處理,是真正的流式計算,支持毫秒級計算。由于相同的原因,Spark只支持基于時間的窗口操作(處理時間或者事件時間),而Flink支持的窗口操作則非常靈活,不僅支持時間窗口,還支持基于數據本身的窗口(另外還支持基于time、count、session,以及data-driven的窗口操作),開發者可以自由定義想要的窗口操作。
從SQL 功能的角度來講,Spark和Flink分別提供SparkSQL和Table APl提供SQL交互支持。兩者相比較,Spark對SQL支持更好,相應的優化、擴展和性能更好,而Flink在SQL支持方面還有很大提升空間。
從迭代計算的角度來講,Spark對機器學習的支持很好,因為可以在內存中緩存中間計算結果來加速機器學習算法的運行。但是大部分機器學習算法其實是一個有環的數據流,在Spark中,卻是用無環圖來表示。而Flink支持在運行時間中的有環數據流,從而可以更有效的對機器學習算法進行運算。
從相應的生態系統角度來講,Spark 的社區無疑更加活躍。Spark可以說有著Apache旗下最多的開源貢獻者,而且有很多不同的庫來用在不同場景。而Flink由于較新,現階段的開源社區不如Spark活躍,各種庫的功能也不如Spark全面。但是Flink還在不斷發展,各種功能也在逐漸完善。