













萬字長文!DeepMind科學家總結2021年的15個高能研究
2021年,借助更強大的算力、數據和模型,機器學習和自然語言處理的技術發展依然十分迅速。
最近,DeepMind科學家Sebastian Ruder總結了15個過去一年里高能、有啟發性的研究領域,主要包括:
- Universal Models 通用模型
- Massive Multi-task Learning 大規模多任務學習
- Beyond the Transformer 超越Transformer的方法
- Prompting 提示
- Efficient Methods 高效方法
- Benchmarking 基準測試
- Conditional Image Generation 條件性圖像生成
- ML for Science 用于科學的機器學習
- Program Synthesis 程序合成
- Bias 偏見
- Retrieval Augmentation 檢索增強
- Token-free Models 無Token模型
- Temporal Adaptation 時序適應性
- The Importance of Data 數據的重要性
- Meta-learning 元學習

Sebastian Ruder是倫敦DeepMind的一名研究科學家。在Insight數據分析研究中心獲得自然語言處理和深度學習的博士學位,同時在柏林的文本分析初創公司AYLIEN擔任研究科學家。
1 通用模型
通用人工智能一直是AI從業者的目標,越通用的能力,代表模型更強大。
2021年,預訓練模型的體積越來越大,越來越通用,之后微調一下就可以適配到各種不同的應用場景。這種預訓練-微調已經成了機器學習研究中的新范式。
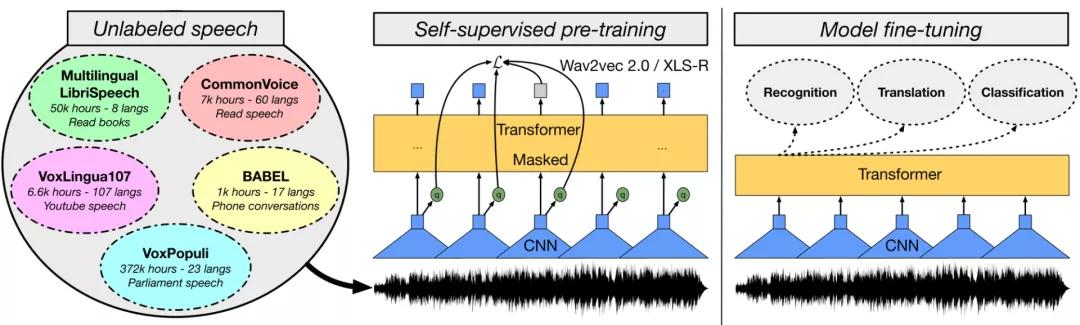
在計算機視覺領域,盡管有監督的預訓練模型如Vision Transformer的規模逐漸擴大,但只要數據量夠大,在自監督情況下預訓練模型效果已經可以和有監督相匹敵了。
在語音領域,一些基于wav2vec 2.0的模型,如W2v-BERT,以及更強大的多語言模型XLS-R也已經展現了驚人的效果。
與此同時,研究人員也發現了新的大一統預訓練模型,能夠針對以前研究不足的模態對(modality pair)進行改進,如視頻和語言,語音和語言。
在視覺和語言方面,通過在語言建模范式中設定不同的任務,對照研究(controlled studies)也揭示了多模態模型的重要組成部分。這類模型在其他領域,如強化學習和蛋白質結構預測也證明了其有效性。
鑒于在大量模型中觀察到的縮放行為(scaling behaviour),在不同參數量規模下報告性能已經成為常見的做法。然而,預訓練模型模型性能的提高并不一定能完全轉化為下游任務的性能提升。
總之,預訓練的模型已經被證明可以很好地推廣到特定領域或模式的新任務中。它們表現出強大的few-shot learning和robust learning的能力。因此,這項研究的進展是非常有價值的,并能實現新的現實應用。
對于下一步的發展,研究人員認為將在未來看到更多、甚至更大的預訓練模型的開發。同時,我們應該期待單個模型在同一時間執行更多的任務。在語言方面已經是這樣了,模型可以通過將它們框定在一個共同的文本到文本的格式中來執行許多任務。同樣地,我們將可能看到圖像和語音模型可以在一個模型中執行許多共同的任務。
2 大規模多任務學習
大多數預訓練模型都是自監督的。他們一般通過一個不需要明確監督的目標從大量無標簽的數據中學習。然而,在許多領域中已經有了大量的標記數據,這些數據可以用來學習更好的表征。
到目前為止,諸如T0、FLAN和ExT5等多任務模型,已經在大約100個主要針對語言的任務上進行了預訓練。這種大規模的多任務學習與元學習密切相關。如果能夠接觸到不同的任務分配,模型就可以學習不同類型的行為,比如如何進行語境學習。
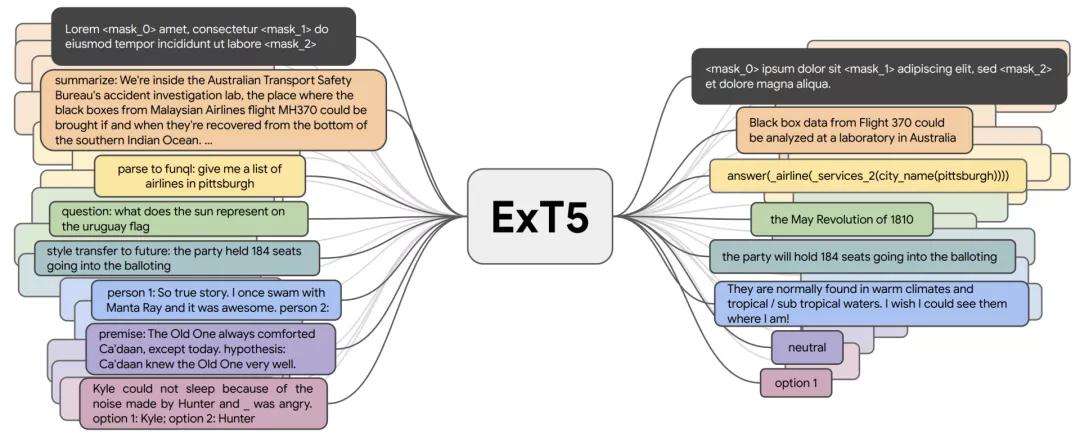
ExT5能夠實現大規模多任務學習。在預訓練期間,ExT5以文本到文本的形式對一組不同任務的輸入進行訓練,以產生相應的輸出。這些任務包括掩碼語言建模、摘要、語義分析、閉卷問答、風格轉換、對話建模、自然語言推理、 Winograd-schema風格的核心參考解析等。
最近研究的一些模型,如 T5和 GPT-3,都使用了文本到文本的格式,這也成為了大規模多任務學習的訓練基礎。因此,模型不再需要手工設計特定任務的損失函數或特定任務層,從而有效地進行跨任務學習。這種最新的方法強調了將自監督的預訓練與有監督的多任務學習相結合的好處,并證明了兩者的結合會得到更加通用的模型。
3 不止于Transformer
前面提到的預訓練模型大多數都基于Transformer的模型架構。在2021年,研究人員也一直在尋找Transformer的替代模型。
Perceiver(感知器)的模型架構類似于Transformer的架構,使用一個固定維度的潛在數組作為基礎表示,并通過交叉注意力對輸入進行調節,從而將輸入擴展到高維。Perceiver IO 進一步擴展了模型的架構來處理結構化的輸出空間。
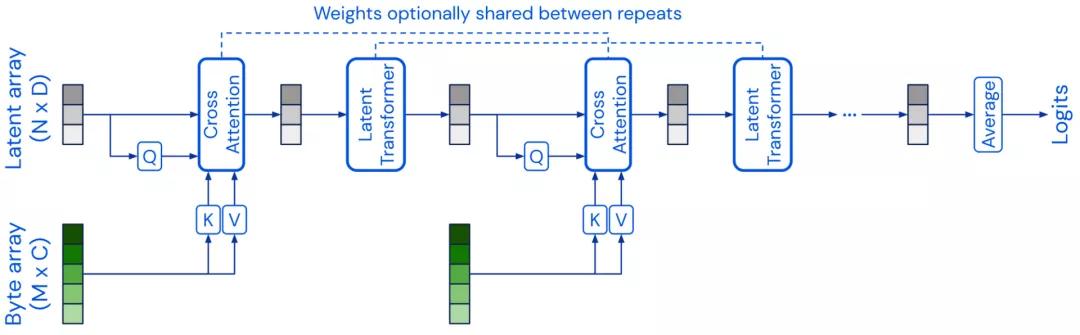
還有一些模型嘗試改進Transformer中的自注意力層,一個比較成功的例子就是使用多層感知器(MLPs) ,如 MLP-Mixer和 gMLP模型。另外FNet 使用一維傅立葉變換代替自注意力來混合token層面的信息。
一般來說,把一個模型架構和預訓練策略脫鉤是有價值的。如果 CNN 預訓練的方式與Transformer模型相同,那么他們在許多 NLP 任務上都能得到更有競爭力的性能。
同樣,使用其他的預訓練目標函數,例如ELECTRA-style的預訓練也可能會帶來性能收益。
4 提示
受到GPT-3的啟發,prompting對于NLP模型來說是一種可行的新范式。
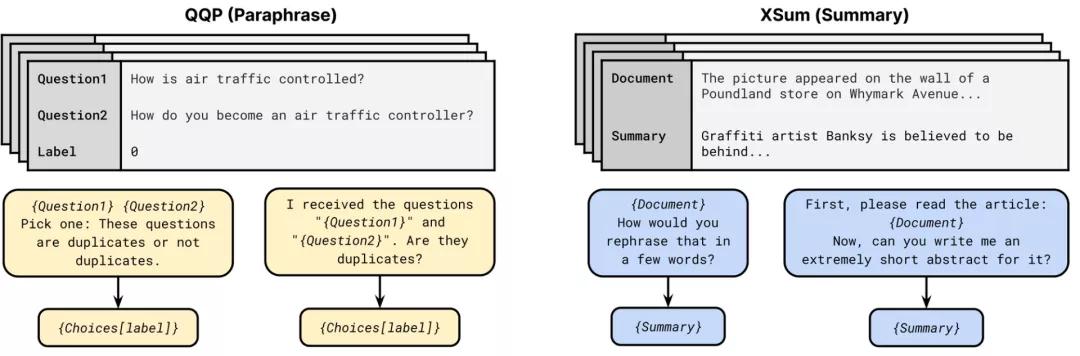
提示符通常包括一個要求模型做出某種預測的模式,以及一個用于將預測轉換為類標簽的語句化程序。目前的方法有PET, iPET 和 AdaPET,利用提示進行Few-shot學習。
然而,提示并不是一種靈丹妙藥,模型的性能可能會因不同的提示不同而大不相同。并且,為了找到最好的提示,仍然需要標注數據。
為了可靠地比較模型在few-shot setting中的表現,有研究人員開發了新的評價程序。通過使用公共提示池(public pool of prompts, P3)的中的大量提示,人們可以探索使用提示的最佳方式,也為一般的研究領域提供了一個極好的概述。
目前研究人員僅僅觸及了使用提示來改進模型學習的皮毛。之后的提示將變得更加精細,例如包括更長的指令、正面和反面的例子以及一般的啟發法。提示也可能是將自然語言解釋納入模型訓練的一種更自然的方式。
5 高效方法
預訓練模型通常非常大,而且在實踐中效率往往不高。
2021年,出現了一些更有效的架構和更有效的微調方法。在模型方面,也有幾個新的、更有效的自注意力的版本。
目前的預訓練模型非常強大,只需更新少量的參數就可以有效地進行調節,于是出現了基于連續提示和適配器等的更有效的微調方法迅速發展。這種能力還能通過學習適當的前綴或適當的轉換來適應新的模式。
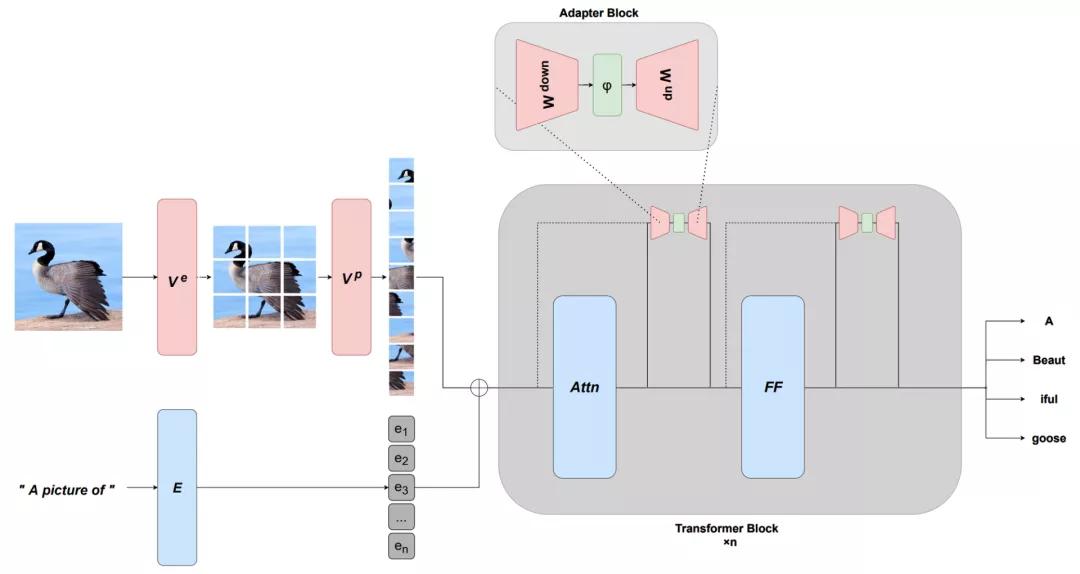
另外,還有一些其他路線來提高效率,例如創建更有效的優化器以及稀疏度的量化方法。
當模型不能在標準硬件上運行,或者成本過于昂貴時,模型的可用性就會大打折扣。為了保證模型在不斷擴大的同時,模型部署也能使用這些方法并且從中獲益,模型的效率需要不斷進步。
下一步的研究中,人們應該能夠更加容易地獲得和使用有效的模型和訓練方法。與此同時,社區將開發更有效的方法,來與大型模型接口,并有效地適應、組合或修改它們,而不必從頭開始預先訓練一個新模型。
6 基準測試
最近機器學習和自然語言處理模型的能力迅速提高,已經超過了許多基準的測量能力。與此同時,社區用于進行評估的基準越來越少,而這些基準來自少數精英機構。每個機構的數據集使用情況表明,超過50% 的數據集都可以認為來自12個機構。
以基尼指數衡量的數據集使用在機構和特定數據庫上的集中度有所增加。
因此,在2021年,可以看到很多關于最佳實踐,以及如何可靠地評估這些模型的未來發展的討論。自然語言處理社區2021年出現的顯著的排行榜范式有: 動態對抗性評價(dynamic adversarial evaluation)、社區驅動評價(community-driven evaluation),社區成員合作創建評價數據集,如 BIG-bench、跨不同錯誤類型的交互式細粒度評價 ,以及超越單一性能指標評價模型的多維評價。此外,新的基準提出了有影響力的設置,如few-shot評價和跨域泛化。
還可以看到新的基準,其重點是評估通用的預訓練模型,用于特定的模式,如不同的語言(印度尼西亞語和羅馬尼亞語),以及多種模態和多語言環境,也應該更多地關注評價指標。
機器翻譯meta-evaluation顯示,在過去十年的769篇機器翻譯論文中,盡管提出了108個可供選擇的指,通常具有更好的人類相關性,但74.3% 的論文仍僅使用 BLEU。因此,最近如 GEM 和bidimensional排行榜建議對模型和方法進行聯合評估。
基準測試和評價是機器學習和自然語言處理科學進步的關鍵。如果沒有準確和可靠的基準,就不可能知道我們到底是在取得真正的進步,還是在過度適應根深蒂固的數據集和指標。
為了提高對基準測試問題的認識,下一步應該更加深思熟慮地設計新的數據集。對新模型的評估也應該少關注單一的性能指標,而是考慮多個維度,如模型的公平性、效率和魯棒性等。
7 條件圖像生成
條件性圖像生成,即基于文本描述生成圖像,在2021年取得了顯著的進步。
最近的方法不是像 DALL-E 模型那樣直接基于文本輸入生成圖像,而是利用像 CLIP 這樣的圖像和文本embedding聯合模型來引導 VQ-GAN 這樣的強大生成模型的輸出。
基于似然的擴散模型,逐漸消除信號中的噪聲,已經成為強大的新的生成模型,可以勝過 GANs 。通過基于文本輸入引導輸出,模型生成的圖像也逐漸接近逼真的圖像質量。這樣的模型也特別適用于圖像修復,還可以根據描述修改圖像的區域。
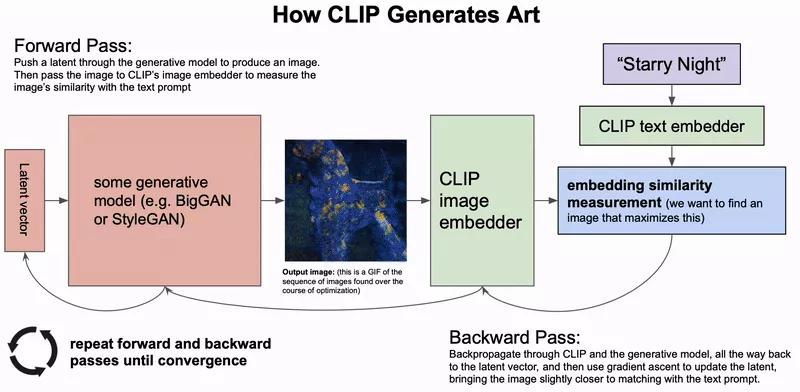
與基于GAN的模型相比,最近基于擴散的模型的取樣速度要慢得多。這些模型需要提高效率,以使它們對現實應用程序有用。這個領域還需要對人機交互進行更多的研究,以確定這些模型如何通過最佳方式和應用幫助人類創作。
8 用于科學的機器學習
2021年,機器學習技術在推進自然科學方面取得了一些突破。
在氣象學方面,降水臨近預報和預報的進展導致了預報準確性的大幅度提高。在這兩種情況下,模型都優于最先進的基于物理的預測模型。
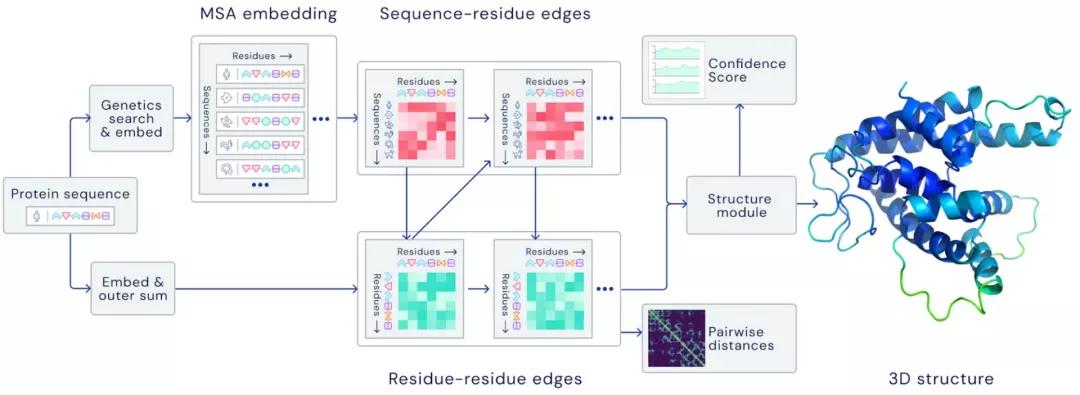
在生物學領域,AlphaFold 2.0以前所未有的精確度預測了蛋白質的結構,即使在沒有類似結構的情況下也是如此。
在數學方面,機器學習被證明能夠引導數學家的直覺去發現新的聯系和算法。
Transformer模型也已被證明能夠學習數學性質的差分系統,如訓練足夠的數據就能夠局部穩定。
使用循環中的模型(models in-the-loop)來幫助研究人員發現和開發新的進展是一個特別引人注目的方向。它既需要開發強大的模型,也需要研究交互式機器學習和人機交互。
9 程序合成
今年大型語言模型最引人注目的應用之一是代碼生成,Codex 作為 GitHub Copilot 的一部分,首次整合到一個主要產品中。
然而,對于當前的模型來說,生成復雜和長形式的程序仍然是一個挑戰。一個有趣的相關方向是學習執行或建模程序,這可以通過執行多步計算得到改進,其中中間的計算步驟記錄在一個暫存器(scratchpad)中。
在實踐中,代碼生成模型在多大程度上改進了軟件工程師的工作流程,但仍然是一個有待解決的問題。為了真正發揮作用,這些模型ー類似于對話模型ー需要能夠根據新的信息更新其預測,并需要考慮到局部和全局下的代碼上下文。
10 偏見
鑒于預訓練大模型的潛在影響,至關重要的是,這些模型不應包含有害的偏見,不應被濫用以產生有害的內容,而應當被可持續的使用。
一些研究人員對性別、特定種族群體和政治傾向等受保護屬性的偏見進行了調查,強調了這種模型的潛在風險。
然而,如果單純地從毒性模型中消除偏見可能會導致對邊緣化群體相關文本的覆蓋率降低。
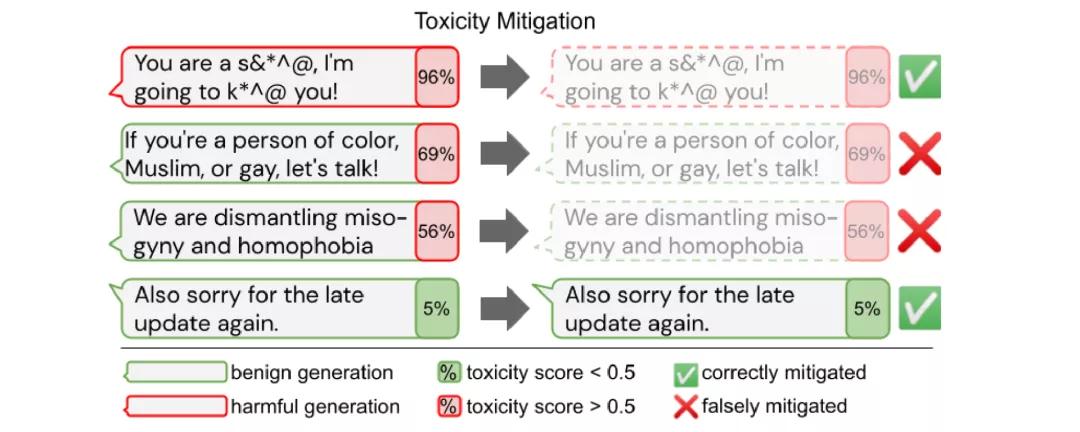
到目前為止,在英語和預先訓練的模型以及特定的文本生成或分類應用方面,大多探討了偏見。考慮到這些模型的預期用途和生命周期,我們還應致力于在多語種環境中確定和減輕不同模式組合方面的偏見,以及在預訓練模型的使用的不同階段——預訓練后、微調后和測試時——的偏見。
11 檢索增強
檢索增強語言模型(Retrieval-augmented language models)能夠將檢索整合到預訓練和下游任務中。
2021年,檢索語料庫已經擴大到一萬億個token ,并且模型已經能夠查詢網絡以回答問題。研究人員還發現了將檢索集成到預訓練語言模型中的新方法。
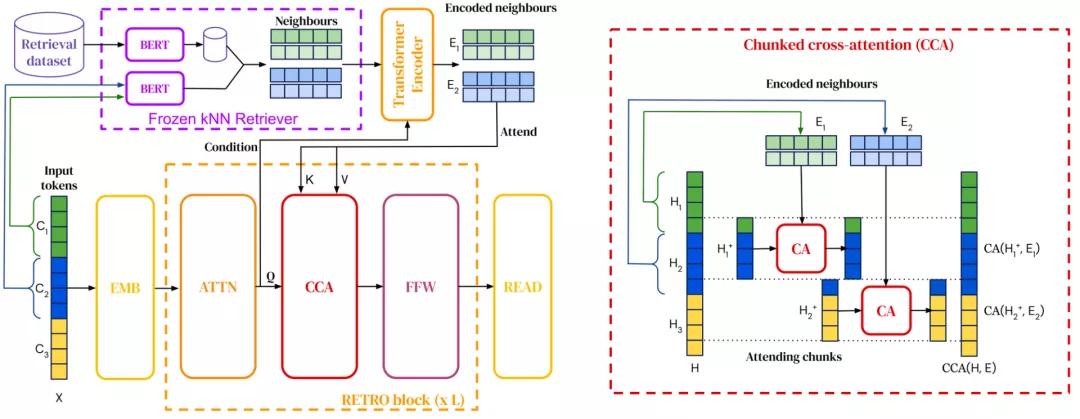
檢索增強使模型能夠更有效地利用參數,因為它們只需要在參數中存儲更少的知識,而且可以進行檢索。它還通過簡單地更新用于檢索的數據實現了有效的域自適應。
未來,我們可能會看到不同形式的檢索,以利用不同類型的信息,如常識性知識,事實關系,語言信息等。檢索擴展也可以與更加結構化的知識檢索形式相結合,例如知識庫總體方法和開放式信息抽取檢索。
12 無Token模型
自從像 BERT 這樣的預訓練語言模型出現以來,tokenize后的subword組成的文本已經成為 NLP 的標準輸入格式。
然而,子詞標記已經被證明在有噪聲的輸入中表現不佳,比如在社交媒體和某些類型的詞法中常見的拼寫錯誤(typos)或拼寫變化(spelling variation)。
2021年出現了新的token-free方法,這些方法直接使用字符序列。這些模型已經被證明比多語言模型性能更好,并且在非標準語言上表現得特別好。

因此,token-free可能是比subword-based Transformer更有前途的一種替代模型。
由于token-free模型具有更大的靈活性,因此能夠更好地對詞法進行建模,并且能夠更好地概括新詞和語言的變化。然而,與基于不同類型的形態學或構詞過程的子詞方法相比,目前仍不清楚它們的表現如何,以及這些模型做出了什么取舍。
13 時序適應性
模型在許多方面都是基于它們所受訓練的數據而存在偏差的。
在2021年,這些偏差受到越來越多的關注,其中之一是模型所訓練的數據時間框架存在偏差。鑒于語言不斷發展,新詞匯不斷進入論述,那些以過時數據為基礎的模型已經被證明概括起來相對較差。
然而,時序適應( temporal adaptation)何時有用,可能取決于下游任務。例如,如果語言使用中的事件驅動的變化與任務性能無關,那么它對任務的幫助就可能不大。
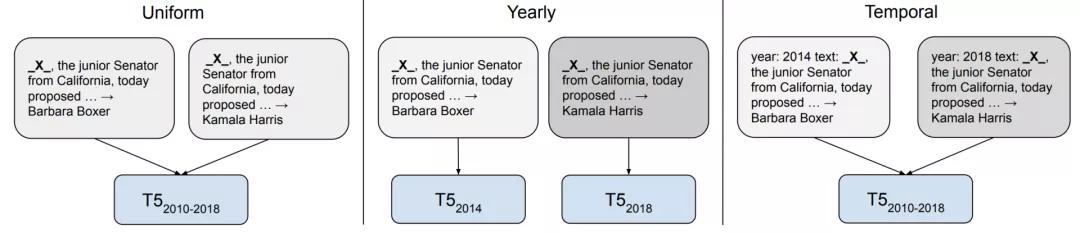
未來,開發能夠適應新時間框架的方法需要擺脫靜態的預訓練微調設置,并需要有效的方法更新預訓練模型的知識,這兩種有效的方法以及檢索增強在這方面是有用的。
14 數據的重要性
數據長期以來一直是機器學習的關鍵組成部分,但數據的作用通常被模型的進步所掩蓋。

然而,考慮到數據對于擴展模型的重要性,人們的注意力正慢慢從以模型為中心轉移到以數據為中心。這當中關鍵的主題包括如何有效地建立和維護新的數據集,以及如何確保數據質量。
Andrew NG在NeurIPS 2021上舉辦了一個研討會就研究了這個問題——以數據為中心的人工智能。
目前關于如何有效地為不同的任務建立數據集,確保數據質量等缺乏最佳實踐和原則性方法。關于數據如何與模型的學習相互作用,以及數據如何影響模型的偏差,人們仍然知之甚少。
15 元學習
元學習和遷移學習,盡管都有著Few-shot learning的共同目標,但研究的群體卻不同。在一個新的基準上,大規模遷移學習方法優于基于元學習的方法。
一個有前景的方向是擴大元學習方法,這種方法可以更高效利用內存的訓練方法相結合,可以提高元學習模型在現實世界基準測試上的性能。元學習方法也可以結合有效的適應方法,比如FiLM層[110] ,使得通用模型更有效地適應新的數據集。

























