PolarDB 并行查詢的前世今生
本文轉載自微信公眾號「阿里技術」,作者遙凌。轉載本文請聯系阿里技術公眾號。
本文會深入介紹PolarDB MySQL在并行查詢這一企業級查詢加速特性上做的技術探索、形態演進和相關組件的實現原理,所涉及功能隨PolarDB MySQL 8.0.2版本上線。
一 背景
1 PolarDB
云的興起為古老而頑固的數據庫市場帶來了新的發展機遇,據Gartner預測,到 2022 年,所有數據庫中將有 75% 部署或遷移到云平臺,云原生數據庫的誕生為各個數據庫廠商、云服務供應商提供了彎道超車的絕好機遇,看一下AWS在Re:invent 2020發布的Babelfish,就能嗅到它在數據庫市場的野心有多大。
AWS在2017年發表的關于Aurora的這篇paper[1],引領了云原生關系型數據庫的發展趨勢,而作為國內最早布局云計算的廠商,阿里云也在2018年推出了自己的云原生關系數據庫PolarDB,和Aurora的理念一致,PolarDB深度融合了云上基礎設施,目標是在為客戶提供云上特有的擴展性、彈性、高可用性的同時,能夠具備更低的響應延遲和更高的并發吞吐,其基本架構如下:
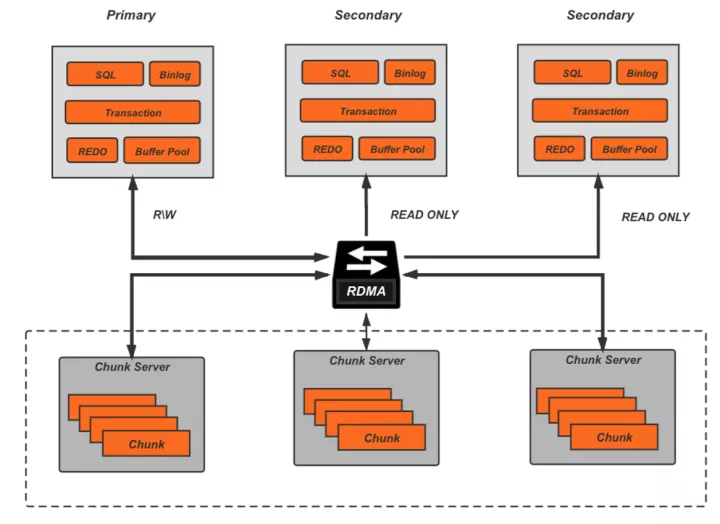
底層的分布式共享存儲突破了單機存儲容量的限制,而且可以隨用戶的數據量增長自動彈性擴容,計算層則是一寫多讀的典型拓撲,利用RDMA提供的高速遠程訪問能力來抵消計算存儲分離帶來的額外網絡開銷。
2 挑戰
從上圖可以看到,存儲層將允許遠大于單機的數據容量(目前是128T),甚至線上會出現一些用戶,單表容量達到xx T的級別,這在基于MySQL主從復制的傳統部署中是難以想象的。同時大量用戶會有對業務數據的實時分析訴求,如統計、報表等,但大家對MySQL的直觀印象就是:小事務處理快,并發能力強,分析能力弱,對于這些實時性分析查詢,該如何應對呢?
3 方案
首先要說的是,隨著互聯網的發展,數據量的爆炸,一定的數據分析能力、異構數據的處理能力開始成為事務型數據庫的標配,MySQL社區在8.0版本中也對自身的查詢處理能力做了補強,包括對子查詢的transformation、hash join、window function支持等,同時PolarDB MySQL優化器團隊也做了大量工作來提升對復雜查詢的處理能力,如統計信息增強、子查詢更多樣的transformation、query cache等。
并行查詢(Parallel Query)是PolarDB MySQL在推出伊始就配備的查詢加速功能,本質上它解決的就是一個最核心的問題:MySQL的查詢執行是單線程的,無法充分利用現代多核大內存的硬件資源。通過多線程并行執行來降低包括IO以及CPU計算在內的處理時間,來實現響應時間的大幅下降。畢竟,對于用戶來說,一條查詢如果可以1分鐘用10個核完成,總比10分鐘用1個核完成更有意義。此外所有成熟的商業型數據庫也都具備并行查詢的能力。
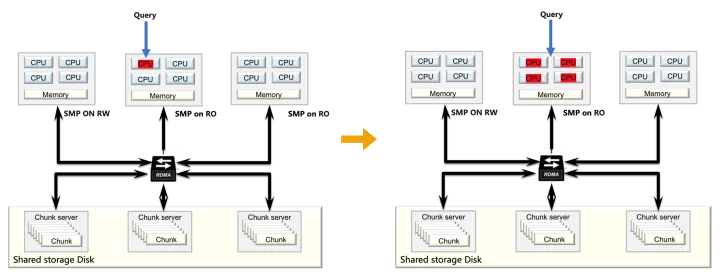
二 并行查詢介紹
1 特性
并行查詢可以說是PolarDB MySQL在計算層最為重要復雜度也最高的功能組件,隨著PolarDB的推出已經線上穩定運行多年,而且一直在持續演進,它具備如下幾個特性:
- 完全基于MySQL codebase,原生的MySQL 100%兼容,這里包括
- 語法兼容
- 類型兼容
- 行為兼容
- 0 附加成本,隨產品發布就攜帶的功能
- 無需額外存儲資源
- 無需額外計算節點
- 0 維護成本,使用和普通查詢沒有任何差別,只是響應變快了
- 隨集群部署,開箱即用
- 對業務無侵入
- 單一配置參數(并行度)
- 實時性分析,PolarDB原生的一部分,受惠于REDO物理復制的低延遲
- 統一底層事務型數據
- 提交即可見
- 極致性能,隨著PQ的不斷完善,對于分析型算子、復雜查詢結構的支持能力不斷提升
- 全算子并行
- 高效流水線
- 復雜SQL結構支持
- 穩定可靠,作為企業級特性,這個毋庸置疑
- 擴展MySQL測試體系
- 線上多年積累
- 完備診斷體系
上面這些聽起來像是廣告宣傳詞,但也確實是并行查詢的核心競爭力。
2 演進
并行查詢的功能是持續積累起來的,從最初的PQ1.0到PQ2.0,目前進入了跨節點并行的研發階段并且很快會上線發布,這里我們先不介紹跨節點并行能力,只關注已上線的情況。
PQ1.0
最早發布的并行查詢能力,其基本的思路是計算的下推,將盡可能多的計算分發到多個worker上并行完成,這樣像IO這樣的重操作就可以同時進行,但和一般的share-nothing分布式數據庫不同,由于底層共享存儲,PolarDB并行中對于數據的分片是邏輯而非物理的,每個worker都可以看到全量的表數據,關于邏輯分片后面執行器部分會介紹。
并行拆分的計劃形態典型如下:
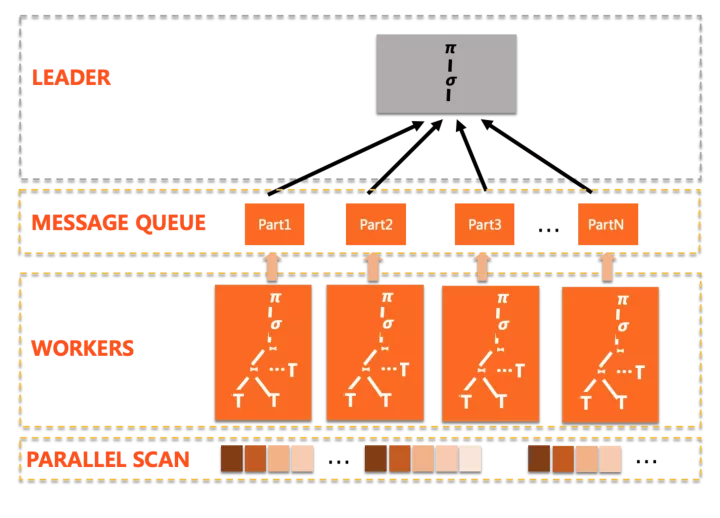
可以看到有這么幾個特點:
- 執行模式是簡單的scatter-gather,也就是只有一個plan slice,多個worker完成相同的功能,匯總到leader
- 盡可能的下推算子到worker上
- leader負責完成無法下推的計算
這個方案能夠解決很多線上的慢查詢問題,得到很好的加速效果,不過也存在著一定的局限性
- 計劃形態是單一的,導致算子的并行方式單一,比如group by + aggregation,只能通過二階段的聚集來完成:worker先做partial aggregation,leader上做final aggregation
- 一旦leader上完成聚集操作,后續如果有distinct / window function / order by等,都只能在leader上完成,形成單點瓶頸
- 如果存在數據傾斜,會使部分worker沒有工作可做,導致并行擴展性差
- 此外實現上還有一些待完善的地方,例如少量算子不支持并行、一些復雜的查詢嵌套結構不支持并行
總得來說,PQ1.0的并行形態和PostgreSQL社區的方案比較像,還有改進空間,畢竟所有商業數據庫的并行形態都要更靈活復雜。
PQ2.0
PQ2.0彌補了上面說到的那些局限性,從執行模式上對齊了Oracle/SQL Server,實現了更加強大的多階段并行。
計劃形態典型如下:
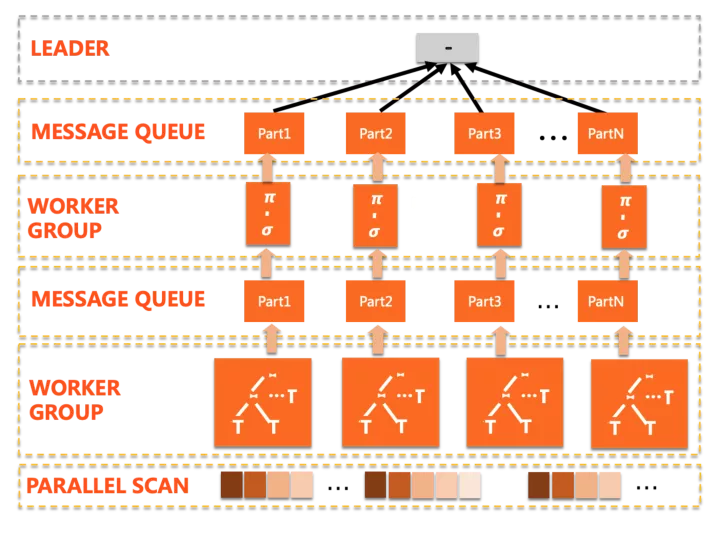
第一眼看到的變化是這里存在多個worker group,PQ2.0的執行計劃是多階段的,計劃會被拆分為若干片段(plan slice),每個slice由一組worker并行完成,在slice之間通過exchange數據通道傳遞中間結果,并觸發后續slice的流水線執行。其中一些補強的點包括:
- 全新的Cost-based并行優化器,基于統計信息和代價決定最優計劃形態
- 全算子的并行支持,包括上面提到的復雜的多層嵌套結構,也可以做到完全的并行
- 引入exchange算子,也就是支持shuffle/broadcast這樣的數據分發操作
- 引入一定自適應能力,即使并行優化完成了,也可以根據資源負載情況做動態調整,如回退串行或降低并行度
這些改變意味著什么呢?我們來看一個簡單且實際的例子:
SELECT t1.a, sum(t2.b)
FROM
t1 JOIN t2 ON t1.a = t2.a
JOIN t3 ON t2.c = t3.c
GROUP BY t1.a
ORDER BY t1.a
LIMIT 10;
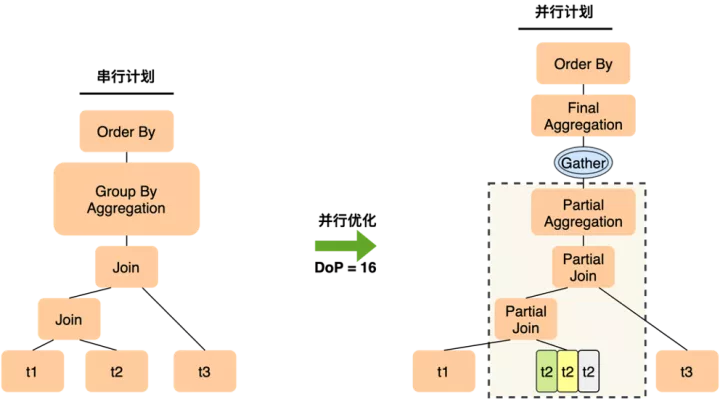
對上面的簡單查詢,在經過優化后,PQ1.0會生成圖中的執行計劃。
- 在join的表集合中,尋找一個可以做邏輯分片的表做拆分,如果3個表都不足以拆分足夠多的分片,那就選最多的那個,比如這里選擇了t2,它可能拆出12個分片,但仍然無法滿足并行度16的要求,導致有4個worker讀不到數據而idle。
- 聚集操作先在worker上做局部聚集,leader上做匯總聚集,如果各個worker上分組的聚攏不佳,導致leader仍然會收到來自下面的大量分組,leader上就會仍然有很重的聚集計算,leader算的慢了,會來不及收worker數據,從而反壓worker的執行速度,導致查詢整體變慢。
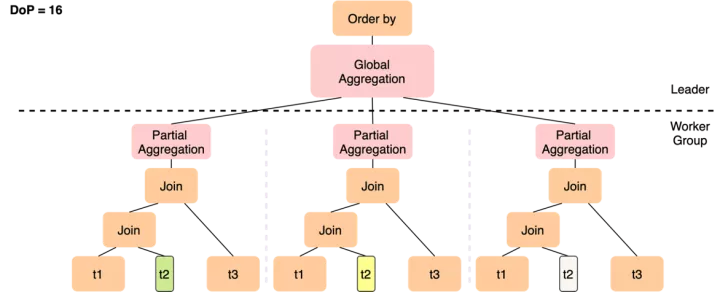
而PQ2.0的執行計劃如下
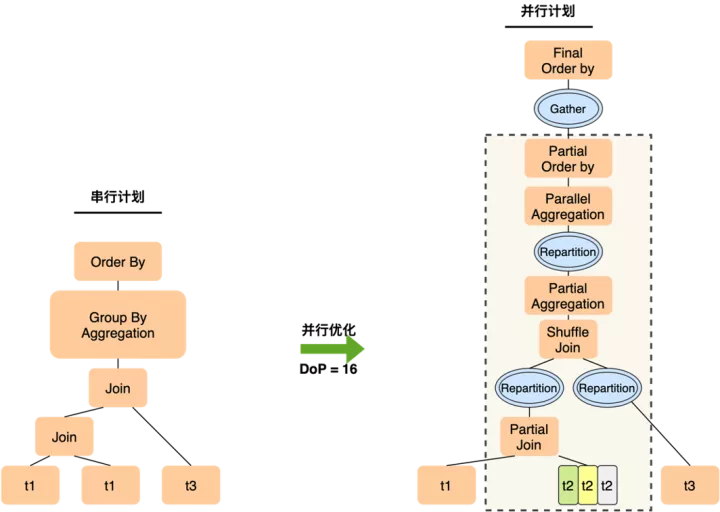
- 雖然仍然只能在t2上做數據分片,但12個worker只需要完成t1 join t2這個操作,在join完成后一般數據量會膨脹,通過Shuffle(Repartition)將更多的中間結果分發到后續的slice中,從而以更高的并行度完成與t3的join
- 各worker完成局部聚集后,如果分組仍很多,可以基于group by key做一次Shuffle來將數據打散到下一層slice,下一組worker會并行完成較重的聚集操作,以及隨后的order by局部排序,最終leader只需要做一次merge sort的匯總
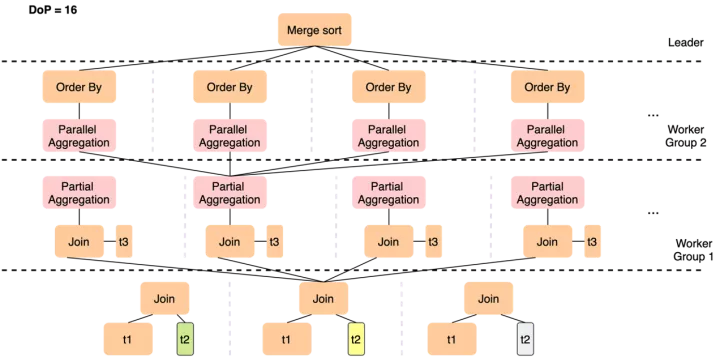
這樣就解決了單點瓶頸和數據量不足導致的擴展性問題,實現線性加速。
為什么線性擴展如此重要?
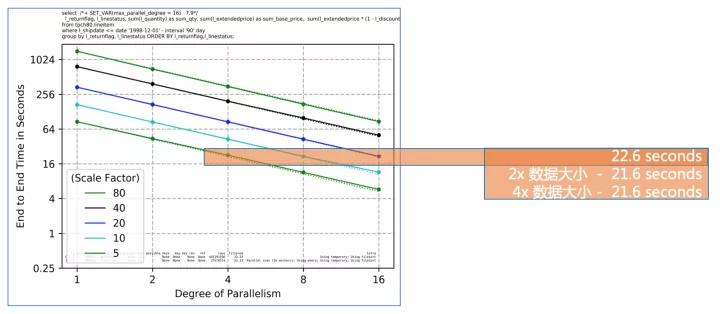
從上圖可以看到,隨著并行度的增長,E2E的響應時間是線性下降的,這對于客戶有兩個重要作用:
- 隨著業務增長數據不斷膨脹,通過相應提高并行度來使用匹配的計算資源,來持續得到穩定可預期的查詢性能
- 始終快速的分析時間可以驅動快速的業務決策,使企業在快速變化的市場環境中保持競爭力
完美的線性加速就是,Parallel RT = Serial RT / CPU cores,當然這并不現實
3 架構
并行查詢組件的整體架構如下
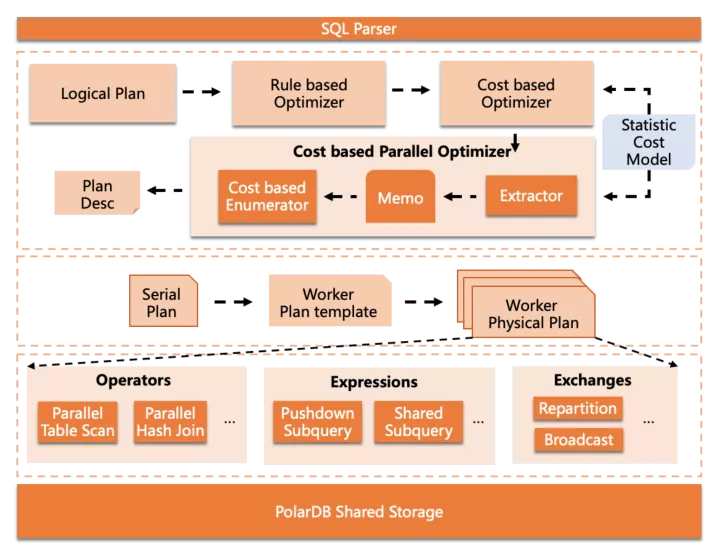
核心部分包括在3層中,從上到下依次是:
Cost-based Parallel Optimizer,嵌入在MySQL的優化器框架中,完成并行優化部分
Parallel Plan Generator,根據抽象的并行計劃描述,生成可供worker執行的物理執行計劃
Parallel Executor,并行執行器組件,包括一些算子內并行功能和數據分發功能等
具體每個組件的實現會在后面詳細介紹
4 性能
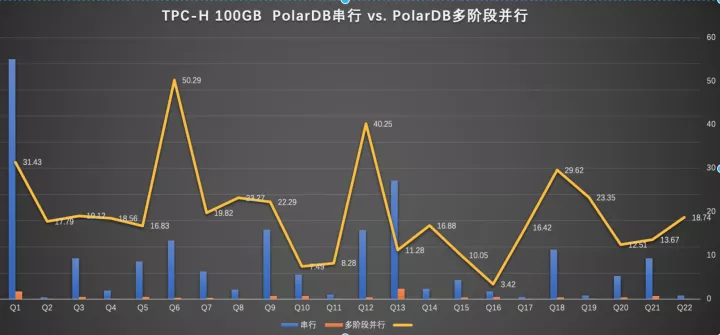
由于是個人文章這里隱去了具體執行時間(可以網上搜索下),主要看下PQ2.0的查詢加速能力,這里并行度是32(可能有同學會奇怪為什么Q6/Q12的加速比超過了32,后面會具體講到)
總的數字是:100%的SQL可以被加速,總和加速比是18.8倍。
5 使用方式
從易用性的角度,用戶開啟并行查詢只需要設置一個參數:
set max_parallel_degree = xxx;
如果想查看并行執行計劃,只需要和普通查詢一樣,執行EXPLAIN / EXPLAIN FORMAT=TREE 即可。
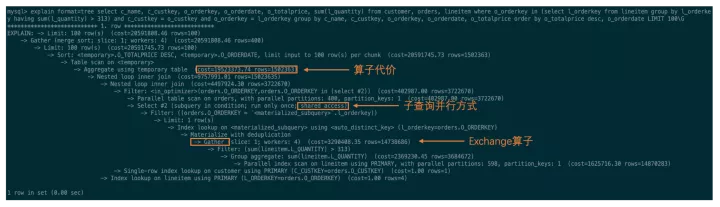
Explain 做了必要的增強來顯示并行相關的information,包括代價、并行模式、分發方式等。
三 并行查詢實現
上面是一些總體性的內容,沒有什么技術細節,后面的章節會依次dive到每個模塊中介紹下。
1 并行優化器
在PQ2.0中,由于計劃形態會變得更加多樣,如果拆分計劃只是依靠簡單規則和簡單統計是很難得到最優解的,因此我們重新實現了一套完全基于cost的并行優化器。
基本的流程是在MySQL串行優化后,進一步做并行拆分,這里可能有同學疑惑為什么不像Oracle或Greenplum那樣搞成一體化的,也就是在優化流程中統一考慮串/并行的執行策略。原因在于,MySQL的優化流程中,各個子步驟之間沒有清晰的邊界,而且深度遞歸的join ordering算法以及嵌入其中的semi-join優化策略選擇等,都使得代碼邏輯與結構更加復雜,很難在不大量侵入原生代碼的前提下實現一體化優化,而一旦對社區代碼破壞嚴重,就沒法follow社區后續的版本迭代,享受社區紅利。
因此采用了兩步走的優化流程,這也是業界常用的手法,如Spark、CockroachDB、SQL Server PDW、Oceanbase等都采用了類似的方案。
代價模型的增強
既然是基于cost的優化,在過程中就必然要能夠得到各個算子并行執行的代價信息。為此PolarDB也做了大量統計信息增強的工作:
- 統計信息自動更新
- 串行優化流程中做針對并行執行的補強,例如修正table掃描方式等,這也是上面性能數據中Q6/Q12會有超線性加速比的原因
- 全算子統計信息推導+代價計算,補充了一系列的cost formula和cardinality estimation推導機制
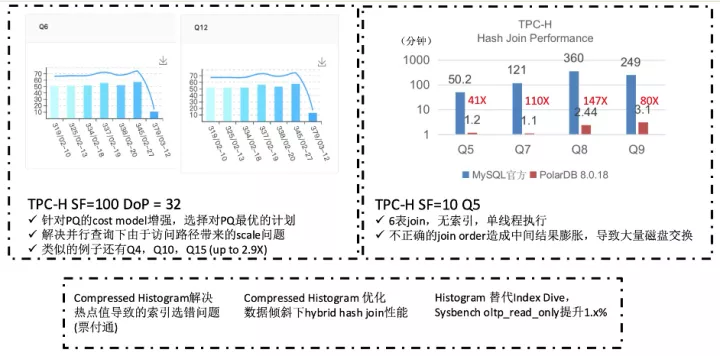
這里只能展示下統計信息增強帶來的效果,收益的不止是并行查詢,串行執行也會提升。
自適應執行策略
在早期版本中,串行優化和并行優化,并行優化和并行計劃生成之間存在一定的耦合性,導致的問題就是在開始并行優化后會無法退化回串行,如果系統中這樣的查詢并發較多,會同時占用很多worker線程導致CPU打爆。新的并行優化器解決了這個問題。
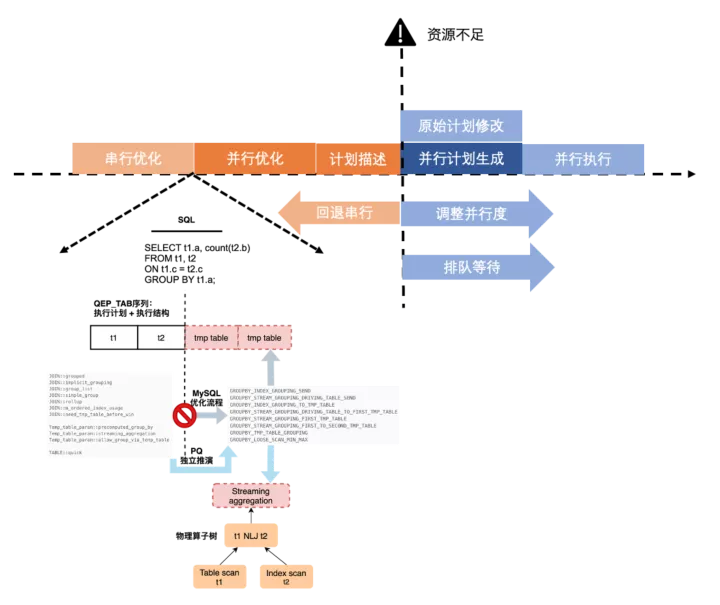
- 串行優化與并行優化解耦,并行優化會重新構建抽象算子樹,并以此為輸入開始enumeration
- 并行優化與并行計劃生成解耦,優化的結果是計劃子片段的抽象描述,作為輸出進行plan generation
這樣就使執行策略的靈活性成為可能,允許在資源不足情況下,要么退回串行,要么降低并行度,或者進入調度隊列排隊等資源。
基于代價的窮盡式枚舉
這是一個比較大的話題,概略來說,并行優化是一個自底向上,基于動態規劃的窮盡式枚舉過程,實現思路參考了SQL Server PDW paper[2],在過程中會針對每個算子,枚舉可能的并行執行方式和數據分發方式,并基于輸出數據的phsical property(distribution + order)構建物理等價類,從而做局部剪枝,獲取局部子問題的最優解并向上層傳遞,最終到root operator獲取全局最優解。
下圖是針對t1 NLJ t2這個算子,做枚舉過程的一個簡要示例:
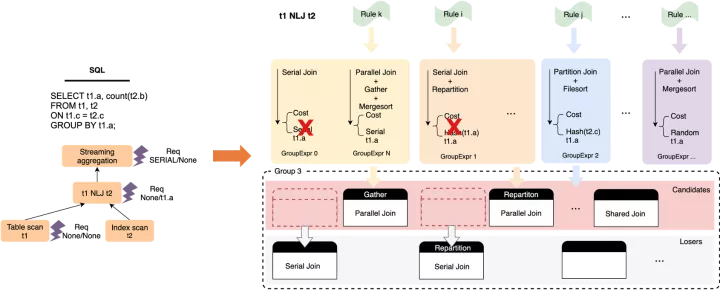
在整體枚舉完成后,計劃空間中會產生一系列帶有數據分發Exchange Enforcer的物理算子樹,基于代價選擇最優樹即可,然后以Enforcer作為子計劃的切分點,可以構建出一系列的執行計劃抽象描述,輸出到plan generator中。
2 并行計劃生成
從工程實現角度,并行計劃生成可以說是整個組件中復雜度最高,坑最多的部分。這里采用了physical plan clone的機制來實現,也就是說,根據優化器生成的并行計劃描述,從原始串行計劃clone出各個計劃片段的物理執行計劃。
為什么要用這種方式呢?還是和MySQL本身機制相關,MySQL的優化和執行是耦合在一起的,并沒有一個清晰的邊界,也就是在優化過程中構建了相關的執行結構。所以沒有辦法根據一個獨立的計劃描述,直接構建出各個物理執行結構,只能從串行計劃中“clone”出來,這可以說是一切復雜度的根源。
MySQL的執行結構非常復雜,expression(Item)和query block(SELECT_LEX)的交叉引用,內外層查詢的關聯(Item_ref)等等,都使得這項任務難度大增,但在這個不斷填坑不斷完善的過程中,團隊也對MySQL的優化執行結構有了很深入的理解,還發現了社區不少bug...
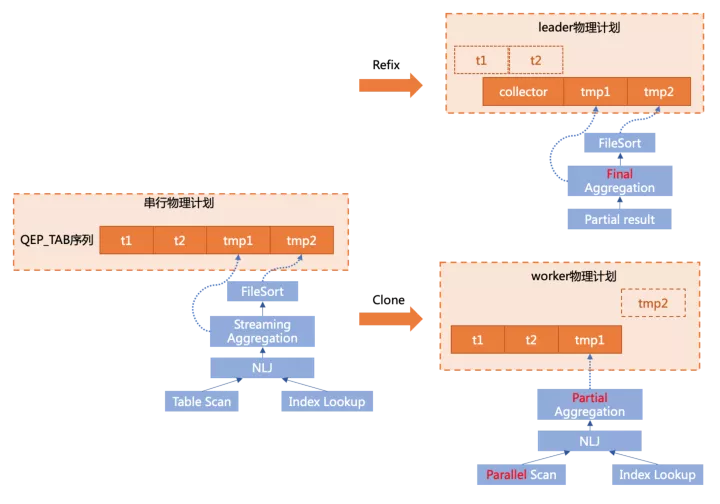
以上圖中簡單的查詢為例
SELECT t1.a, sum(t2.b) sumb
FROM t1 join t2
ON t1.c = t2.c
GROUP BY t1.a
ORDER BY sumb;
雖然社區對執行器做了基于Iterator model的重構,但本質上,物理執行計劃仍然是由QEP_TAB組成的序列,其中group by+aggr由一個tmp table1完成,order by由tmp table2完成。
在做plan generation時,有兩個核心的操作:
- clone
根據串行physical plan和子slice的描述,將相對應的結構clone到各個worker線程中,如上圖右下部分,將在worker上執行的t1 join t2和下推的聚集操作clone了下來。
- refix
原始的串行計劃需要轉換為leader計劃,因此要替掉不必要的執行結構并調整一些引用關系,如上圖右上部分,由于t1 join t2和部分聚集操作已經下推,leader上需要去掉不必要的結構,并替換為從一個collector table中讀取worker傳遞上來的數據,同時需要將后續步驟中引用的t1/t2表的結構轉為引用collector表的對應結構。
這里只是舉了最為簡單的例子,還沒有涉及子查詢和多階段plan,實際的工程實現成本要高很多。
3 并行執行器
PQ實現了一系列算子內并行的機制,如對表的邏輯分區和并行掃描,parallel hash join等,來使并行執行成為可能或進一步提升性能,還有多樣化的子查詢處理機制等,這里選一些具有代表性的來介紹。
parallel scan
PolarDB是共享存儲的,所有數據對所有節點均可見,這和sharding的分布式系統有所不同,不同worker處理哪一部分數據無法預先確定,因此采用了邏輯分區的方案:
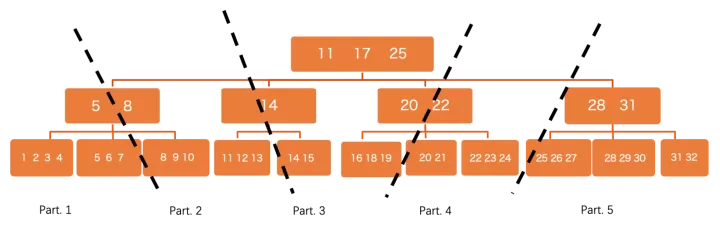
在btree這個level,會將數據切分成很多小分片,不同worker負責不同分片來觸發并行執行,這里有一些優化點:
盡量做細粒度的切分,使分片數 >> worker數,然后worker之間通過round robin的方式去“搶”分片來執行,這樣自然做到了能者多勞,避免由于數據分布skew導致的負載不均衡問題,這是shared storage系統的一個天然優勢。
切分時可以不用dive到葉子節點,也就是以page作為最小分區單位,來加速初始分區速度。
parallel hash join
hash join是社區8.0為加速分析型查詢所引入的功能,并隨著版本演進對semi hash/anti hash/left hash join均做了支持,PolarDB也引入了這些patch來實現完整的hash join功能,并實現了多種并行執行策略。
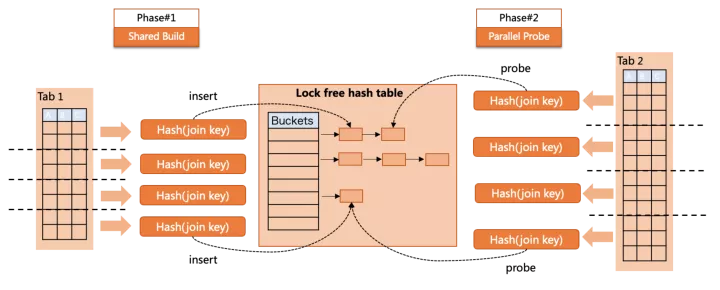
parallel hash join在build/probe兩個階段均做了并行支持
build階段,多個worker向同一個共享的lock-free hash table中插入數據。
probe階段,多個worker并行到hash table做搜索。
兩個階段沒有重疊,這樣就實現了全階段的并行,但parallel hash join也有自身的問題,例如共享hash table過大導致spill to disk問題,并行插入雖然無鎖,但仍有“同步”原語帶來的cache invalidation。
partition hash join
partition hash join則可以避免以上問題,但代價則是引入數據shuffle的開銷:
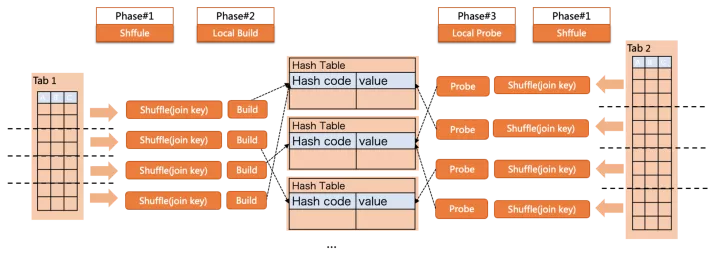
如圖所示,查詢的執行過程分為了3個階段
- build/probe兩側都根據join key做shuffle,將數據分發到目標partition;
- 在每個partition內,build側各自構建小hash table;
- 在每個partition內,probe側各自查找對應的hash table;
這樣就在各個partition內,完成了co-located join,每個hash table都更小來避免落盤,此外也沒有了build中的并發問題。
以上兩個方案哪個更優?由并行優化器基于Cost決定。
子查詢并行 - pushdown exec
這里子查詢是表達式中的一部分,可以存在于select list / where / having等子句中。對于相關子查詢,唯一的并行方式是隨外層依賴的數據(表)下推到worker中,在每個worker內完整執行,但由于外層并行了,每個worker中子查詢執行次數還是可以等比例減少。
例如如下查詢:
SELECT c1 FROM t1
WHERE EXISTS (
SELECT c1 FROM t2 WHERE t2.a = t1.a <= EXISTS subquery
)
ORDER BY c1
LIMIT 10;
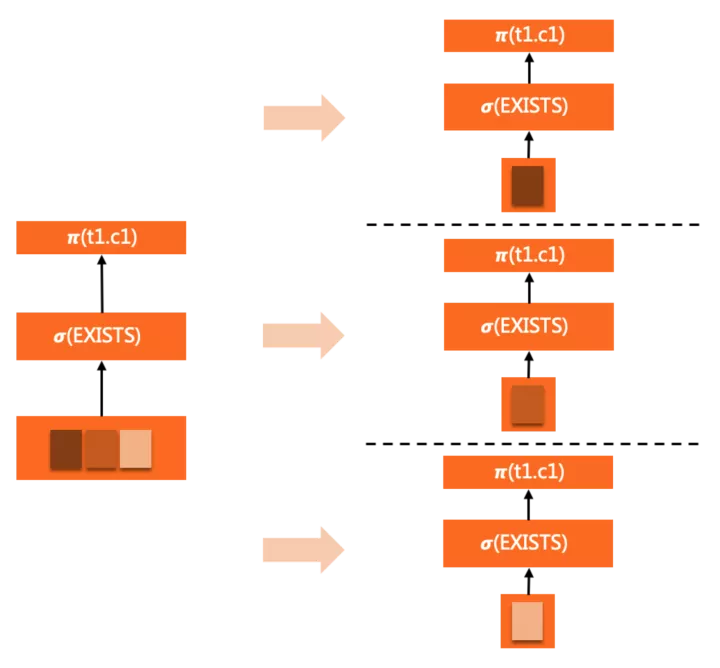
EXISTS子查詢完整的clone到各個worker中,隨著WHERE條件的evaluation反復觸發執行。
子查詢并行 - pushdown shared
這種并行方式的子查詢可以是表達式的一部分,也可以是派生表(derived table)。
概略的來說,這種并行方式適用于非相關子查詢,因此可以提前并行物化掉,形成一個臨時結果表,后續外層在并行中,各worker引用該子查詢時可以直接從表中并行讀取結果數據。
例如如下查詢
SELECT c1 FROM t1
WHERE t1.c2 IN (
SELECT c2 FROM t2 WHERE t2.c1 < 15 <= IN subquery
)
ORDER BY c1
LIMIT 10;
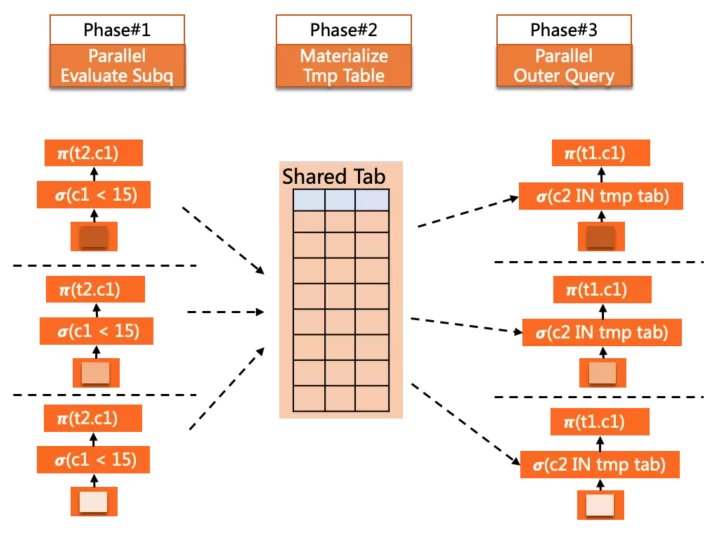
另外線上用戶的報表類查詢中,一種非常常見的Query模式就是derived table的多層嵌套,對于這類SQL,pushdown shared策略可以很好的提升并行執行的性能,例如如下示例:

上圖中每個顏色的方塊,代表了一層query block,這里就構成了多層derived table的嵌套邏輯,有些層中通過UNION ALL做了匯總,有些層則是多個表(包括derived table)的join,對于這樣的查詢,MySQL會對每個derived table做必要的物化,在外層形成一個臨時結果表參與后續計算,而PQ2.0對這種常見的查詢模式做了更普遍的支持,現在每一層查詢的執行都是并行完成的,力爭達到線性的加速效果。
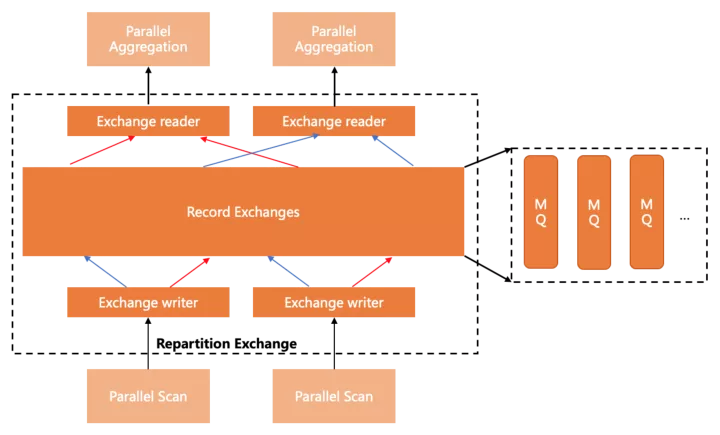
Exchanges
要生成高效靈活的執行計劃,數據分發組件是必不可少的,目前PolarDB支持了Shuffle/Broadcast/Gather三種分發方式,實現上利用lock-free shared ring buffer,做到流水線模式的高效數據傳輸。
下圖展示了Shuffle(Repartition)的基本形態
到這里,并行查詢的線上版本功能及實現已經大體介紹完了。
作為一款成熟的企業級功能特性,團隊還實現了一整套完善的輔助工具集,來配合提升產品的易用性,實現功能的可監控、可干預、可反饋,但這里篇幅已經很大了,就先不介紹了。
四 未來規劃
這里說是未來規劃并不確切因為團隊已經在跨節點并行上做了大量的工作并進入了開發周期的尾端,跨節點的并行會把針對海量數據的復雜查詢能力提升到另一個水平:
- 打通節點間計算資源,實現更高的計算并行度
- 突破單節點在IO / CPU上的瓶頸,充分利用分布式存儲的高吞吐能力
- 結合全局節點管理與資源視圖,平衡調度全局計算資源,實現負載均衡的同時保證查詢性能
- 結合全局一致性視圖,保證對事務性數據的正確讀取
[1]https://www.allthingsdistributed.com/files/p1041-verbitski.pdf
[2]https://www.scinapse.io/papers/2160963784#fullText