一文帶你了解Elasticsearch vs. Solr
背景
當前是云計算和數據快速增長的時代,今天的應用程序正以PB級和ZB級的速度生產數據,但人們依然在不停的追求更高更快的性能需求。隨著數據的堆積,如何快速有效地搜索這些數據,成為對后端服務的挑戰。本文,我們將比較業界兩個最流行的開源搜索引擎,Solr和ElasticSearch。兩者都建立在Apache Lucene開源平臺之上,它們的主要功能非常相似,但是在部署的易用性,可擴展性和其他功能方面也存在巨大差異。
Elastcisearch
介紹
Elasticsearch 是一個分布式、RESTful 風格的搜索和數據分析引擎。Elasticsearch是用Java語言開發的,并作為Apache許可條款下的開放源碼發布,是一種流行的企業級搜索引擎。Elasticsearch 以其易用性迅速贏得了許多用戶,被用在網站搜索、日志分析等諸多方面。由于 ES 強大的橫向擴展能力,甚至很多人也會直接把 ES 當做 NoSQL 來用。

特性
- 搜索引擎:通過 Elasticsearch,您能夠執行及合并多種類型的搜索(結構化數據、非結構化數據、地理位置、指標),搜索方式隨心而變
- 分析引擎:對的是十億行日志,Elasticsearch 聚合讓您能夠從大處著眼,探索數據的趨勢和規律
- 檢索性能:通過有限狀態轉換器實現了用于全文檢索的倒排索引,實現了用于存儲數值數據和地理位置數據的 BKD 樹,以及用于分析的列存儲
- 可擴展性:能夠水平擴展,每秒鐘可處理海量事件,同時能夠自動管理索引和查詢在集群中的分布方式,以實現極其流暢的操作
- 檢索能力:基于各項元素(從詞頻或新近度到熱門度等)對搜索結果進行排序。將這些內容與功能進行混搭,以優化向用戶顯示結果的方式
- 數據容錯:通過跨集群復制功能,輔助集群可以作為熱備份隨時投入使用。
- 實時互動:在 Kibana 中通過炫酷的可視化來探索您的數據,從華夫餅圖到熱點圖,再到時序數據分析,應有盡有

數據結構
- index(索引):索引是文檔(Document)的容器,是一類文檔的集合,類比傳統的關系型數據庫來說,索引相當于SQL中的一個數據庫(Database)
- Type(類型):從 6.0.0開始單個索引只能有一個類型,7.0.0以后將不建議使用,8.0.0以后完全不支持
- Document(文檔):Document Index 里面單條的記錄成為Document(文檔)。等同于關系型數據庫表中的行
- Field(字段):屬性Fieldl類似于關系型數據庫的字段的概念,一樣的,每個屬性有自己不同的類型,類型包括核心類型、復雜類型(對象類型[object]和嵌套類型[nested])、地理類型以及特殊類型
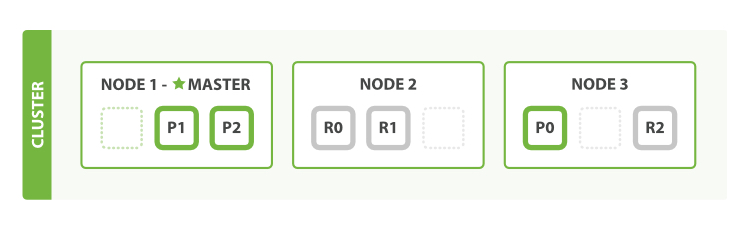
集群
Elasticsearch 可以橫向擴展至數百(甚至數千)的服務器節點,同時可以處理PB級數據。ElasticSearch 的主旨是隨時可用和按需擴容。 而擴容可以通過購買性能更強大( 垂直擴容 ,或 縱向擴容 ) 或者數量更多的服務器( 水平擴容 ,或 橫向擴容 )來實現。雖然 Elasticsearch 可以獲益于更強大的硬件設備,但是垂直擴容是有極限的。 真正的擴容能力是來自于水平擴容—為集群添加更多的節點,并且將負載壓力和穩定性分散到這些節點中。對于大多數的數據庫而言,通常需要對應用程序進行非常大的改動,才能利用上橫向擴容的新增資源。與之相反的是,ElastiSearch天生就是 分布式的 ,它知道如何通過管理多節點來提高擴容性和可用性。 這也意味著你的應用無需關注這個問題 。
集群支持如下功能:
- 集群健康
- 故障轉移
- 水平擴容
- 應對故障
Solr
介紹
Solr是一個高性能,采用Java開發,基于Lucene的全文搜索服務器。同時對其進行了擴展,提供了比Lucene更為豐富的查詢語言,同時實現了可配置、可擴展并對查詢性能進行了優化,并且提供了一個完善的功能管理界面,是一款非常優秀的全文搜索引擎。Apache Solr 是一個成熟的項目,于 2006 年首次發布到開源,Solr 在搜索領域占據了多年的主導地位。然后,在 2010 年左右,Elasticsearch 成為市場上的另一種選擇。

特點
- RESTful API: 要與Solr通信,可以使用RESTful服務與Solr通信,可以使用XML,JSON,CSV等格式的文件作為輸入文檔,并以相同的文件格式獲取結果
- 全文搜索: Solr提供了全文搜索所需的所有功能:令牌,短語,拼寫檢查,通配符,自動完成
- 企業準備: 根據企業或組織的需要,Solr可以部署在任何類型的系統:獨立,分布式,云
- 靈活可擴展: 通過擴展Java類并進行相關配置,可以定制Solr組件
- NoSQL數據庫: Solr可以用作大數量級的NoSQL數據庫,可以沿著集群分布搜索任務
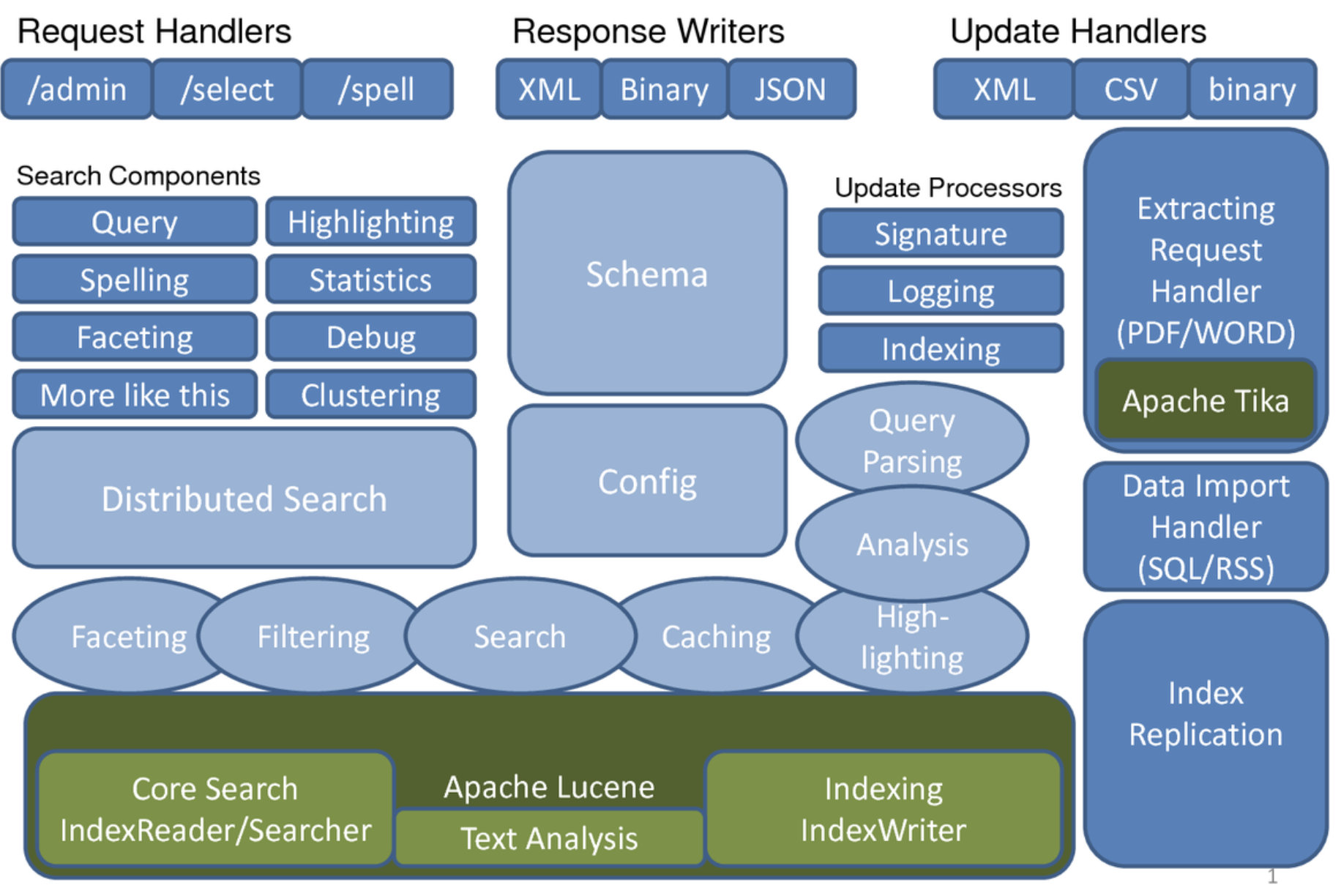
架構
Apache Solr的主要構建塊(組件)
- 請求處理程序 - 發送到Apache Solr的請求由這些請求處理程序處理。請求可以是查詢請求或索引更新請求。根據這些請示的要求來選擇請求處理程序。為了將請求傳遞給Solr,通常將處理器映射到某個URI端點,并且它將為指定的請求提供服務。
- 搜索組件 - 搜索組件是Apache Solr中提供的搜索類型(功能)。它可能是拼寫檢查,查詢,構面,命中突出顯示等。這些搜索組件被注冊為搜索處理程序。多個組件可以注冊到搜索處理程序。
- 查詢解析器 ? Apache Solr查詢解析器解析傳遞給Solr的查詢,并驗證查詢的語法是否有錯誤。解析查詢后,將它們轉換為Lucene理解的格式。
- 響應寫入器 - Apache Solr中的響應寫入器是為用戶查詢生成格式化輸出的組件。 Solr支持XML,JSON,CSV等響應格式。對每種類型的響應都有不同的響應寫入。
- 分析器/分詞器 - Lucene以令牌的形式識別數據。 Apache Solr分析內容,將其分成令牌,并將這些令牌傳遞給Lucene。 Apache Solr中的分析器檢查字段的文本并生成令牌流。分詞器將分析器準備的令牌流分解成令牌。
- 更新請求處理器 - 每當向Apache Solr發送更新請求時,請求都通過一組稱為更新請求處理器的插件(簽名,日志記錄,索引)運行。這個處理器負責修改,例如刪除字段,添加字段等。
總結
Solr專注于文本搜索,而Elasticsearch則常用于查詢、過濾和分組分析統計。那么,到底是選擇 Solr 還是 Elasticsearch?有時很難找到明確的答案。無論選擇 Solr 還是 Elasticsearch,首先需要了解正確的用例和未來需求,總結它們的每個屬性。
- 如果需要分布式索引,則需要選擇 Elasticsearch。對于需要良好可伸縮性和性能的云和分布式環境,Elasticsearch 是更好的選擇。
- 在Solr中,索引間進行join必須是單個分片和其他節點上的副本集進行關聯來搜索文檔間關系(例如SQL連接)。而Elasticsearch提供更高效的has_children和top_children查詢來檢索這樣的相關文檔。
- 兩者都有很好的操作工具,盡管 Elasticsearch 因其易于使用的 API 而更多地吸引了 DevOps 人群,因此可以圍繞它創建一個更加生動的工具生態系統。
- Elasticsearch 在開源日志管理用例中占據主導地位,許多組織在 Elasticsearch 中索引它們的日志以使其可搜索。雖然 Solr 現在也可以用于此目的,但它只是錯過了這一想法。
- Solr 仍然更加面向文本搜索。另一方面,Elasticsearch 通常用于過濾和分組,分析查詢工作負載,而不一定是文本搜索。
- Elasticsearch 開發人員在 Lucene 和 Elasticsearch 級別上投入了大量精力使此類查詢更高效(降低內存占用和 CPU 使用)。因此,對于不僅需要進行文本搜索,而且需要復雜的搜索時間聚合的應用程序,Elasticsearch 是一個更好的選擇。
- Elasticsearch 更容易上手,一個下載和一個命令就可以啟動一切。Solr 傳統上需要更多的工作和知識,但 Solr 最近在消除這一點上取得了巨大的進步,現在只需努力改變它的聲譽。
- 從操作上講,Elasticsearch 使用起來比較簡單,它只有一個進程。Solr 在其類似 Elasticsearch 的完全分布式部署模式 SolrCloud 中依賴于 Apache ZooKeeper,ZooKeeper 是超級成熟,超級廣泛使用等等,但它仍然是另一個活躍的部分。雖然 Elasticsearch 內置了類似 ZooKeeper 的組件 Xen,但 ZooKeeper 可以更好地防止有時在 Elasticsearch 集群中出現的可怕的裂腦問題。
- Solr接受來自不同來源的數據,包括XML文件,逗號分隔符(CSV)文件和從數據庫中的表提取的數據以及常見的文件格式(如Microsoft Word和PDF)。Elasticsearch還支持其他來源的數據,例如Git,JDBC,JMS,Kafka,LDAP,MongoDB等。還有各種插件可用。