













Meta「世界模型」遭質疑:10年前就有了!LeCun:關鍵在于構建和訓練
?2月24日,Meta在「春晚」上介紹了首席科學家Yann LeCun在構建人類級別的AI勾勒出的另一種愿景。 LeCun表示,AI學習「世界模型」(世界如何運作的內部模型)的能力可能是關鍵。 然而,文章一出,便遭到了很多業內人士的質疑,這不是老早就有了的東西么?
始于20世紀60年代?
多倫多大學的副教授Dan Roy指出,「我好像記得Josh Tenenbaum確實提過世界模型。當然也可能我記錯了。」
卡內基梅隆大學計算機科學教授、前蘋果人工智能研究主任Russ Salakhutdinov隨即跟帖表示:「我十年前從事博士后研究時,Josh Tenenbaum和很多人就已經在搞世界模型了。所以今天Facebook說他們要描繪一個以AI為基礎的世界模型,我聽著就覺得挺逗的。」

甚至有網友搬出了Jürgen Schmidhuber在1990年發表的論文,其中就有關于世界模型的介紹。

論文地址:?https://mediatum.ub.tum.de/doc/814960/file.pdf? 另有熱心網友在下面附上了他2018年在NIPS上發表的一篇有關世界模型的
論文的鏈接。

論文地址:?https://arxiv.org/abs/1809.01999?項目地址:https://worldmodels.github.io/? 當然還有更過分的網友直接表示,「大概率成不了。」

被推上風口浪尖的LeCun,不得不親自下場:這和Facebook沒啥關系,是我自己提出的,況且應該是Meta。 他表示,「確實有很多人聊世界模型聊了幾十年了,自打上個世紀60年代的控制論開始。但提出這個概念不是關鍵,關鍵在于到底怎樣構建和訓練世界模型。」
也就是如何讓世界模型學習分級表示法,并且實現分級規劃。我認為這里創新的點就在于使用聯合嵌入型預測架構(JEPA)在表征空間中進行預測。

JEPA有這么幾個特點:
- 非生成性——輸出是被加密的,細節都被省掉。
- 非概率性——是基于能量的,不是可規范化的。
- 非對比訓練(用VICR)
我認為第一個和第二個特點大概率會有悖于Josh的貝葉斯定理。
不過,也有網友贊成LeCun的看法。 他表示,「確實,訓練是個問題。對于一個離開自己原來的工作,去搞世界模型的人來說,他們可能會從物理學家、控制理論專家和人工智能的角度去構思,這樣的話這些視角很難幫他們做什么...哪怕你搭建了一個機器,也學了一些特定領域的世界模型,你還是很難做出一款現象級的軟件。」
「世界模型」是什么?
人類會根據自己有限的感官所能感知到的事物,去建立了一個關于世界的模型。 在此之后,人類做出的所有決定和行動都將基于這個內部模型的。 而這個模型并不只是泛泛地預測未來,而是根據我們當前的運動和行動對未來的感官數據進行預測。 當面臨危險時,人類能夠本能地根據這個預測模型采取行動,并進行快速的反射性行為,而不需要有意識地計劃出行動方案。

人類所看到的是基于大腦對未來的預測 LeCun指出:「人類學習在世界如何運作的背景知識時,是通過觀察,以及用獨立于任務和無監督方式進行的。可以假定,這種積累的知識可能構成了通常被稱為常識的基礎。」 常識可以被視為世界模型的集合,可以指導智能體何種行為可能、何種行為合理、何種行為不可能。 這使人類能夠在不熟悉的情況中有效地預先計劃。例如,一名少年司機以前可能從未在雪地上駕駛,但他預知雪地會很滑、如果車開得太猛將會失控打滑。 常識性知識讓智能動物不僅可以預測未來事件的結果,還可以在時間或空間上填補缺失的信息。當司機聽到附近有金屬撞擊聲時,即使沒有看到撞車現場,他也能立即知道車禍發生。 就像首次接觸左側駕駛的人,不用再重復學習方向盤該怎么打一樣,物理法則是不會改變的,而這就是個「世界模型」的例子。
早期工作
早在1990年,就有研究人員開始嘗試建立一個完全依靠自己來學習世界表征的智能體。 Schmidhuber的模型指出,智能體可以從世界接收獎勵R和輸入IN。輸入在經過網絡處理后,模型會分別對世界和未來的獎勵進行預測——PREDIN,PREDR。最后,動作通過OUT輸出。 也就是說,這個智能體對于未來的獎勵和輸入是使用世界模型預測的。
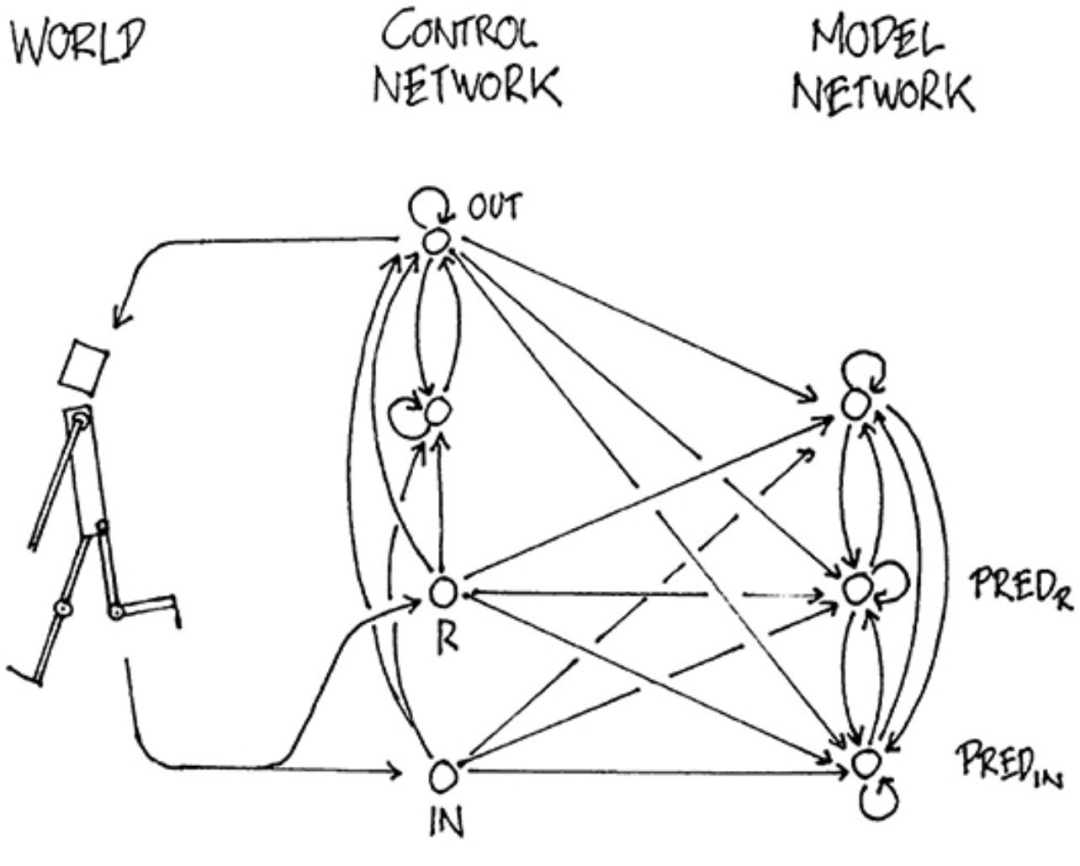
Schmidhuber的模型遵循的是壓縮神經表征的思想,而壓縮也是歸納推理的關鍵,即從少數例子中學習,這通常被認為是智能才有的行為。 然而,Schmidhuber在這個方法中缺少一個關于如何分析智力和意識的理論。 在2018年的論文中,Schmidhuber再次提出了一個受人類認知系統啟發的簡單模型。 在這個模型中,智能體有一個視覺感覺組件,將它看到的東西壓縮成一個小的代表代碼。還有一個記憶組件,根據歷史信息對未來的代碼進行預測。最后是一個決策組件,只根據其視覺和記憶組件所創建的表征來決定采取什么行動。
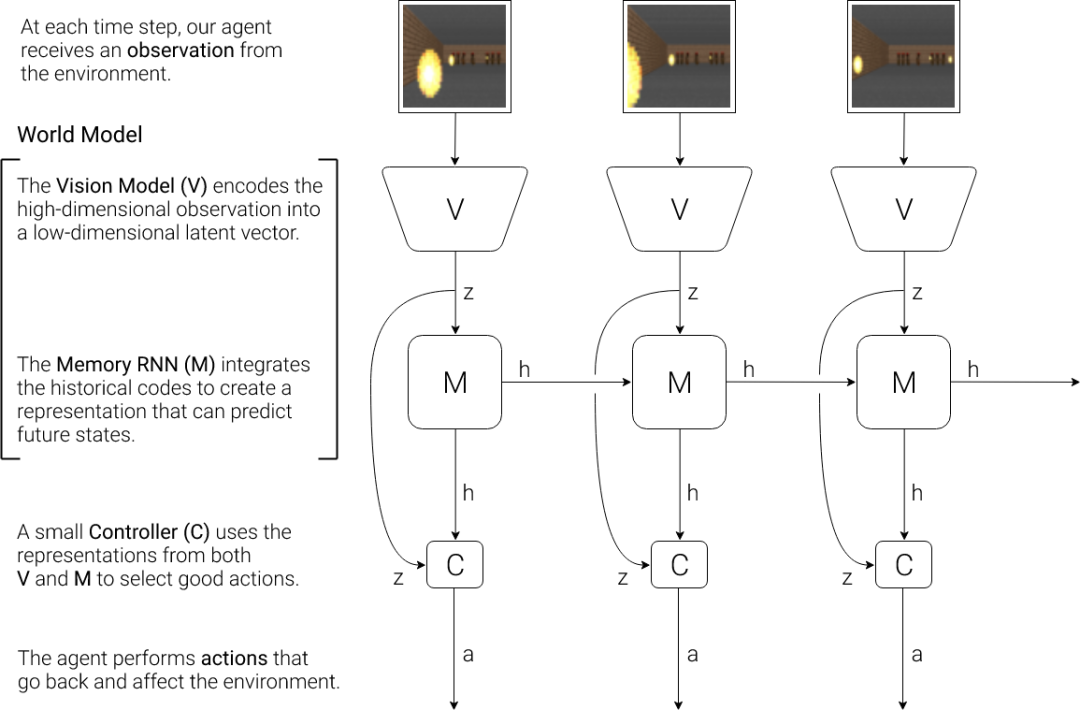
智能體由三個組件組成:視覺(V),記憶(M),和控制器(C) 在這項工作中,Schmidhuber首先訓練一個大型神經網絡,以無監督的方式學習智能體的世界模型,然后訓練較小的控制器模型,學習使用這個世界模型來執行任務。 其中,控制器讓訓練算法專注于小的搜索空間上的信用分配問題,同時不犧牲通過大的世界模型的能力和表現力。 在通過世界模型的視角進行訓練之后,Schmidhuber證明,智能體可以學習一個高度緊湊的策略來執行其任務。
自主智能架構
LeCun在自己的「世界模型」中提出了一個由六個獨立模塊組成的架構。 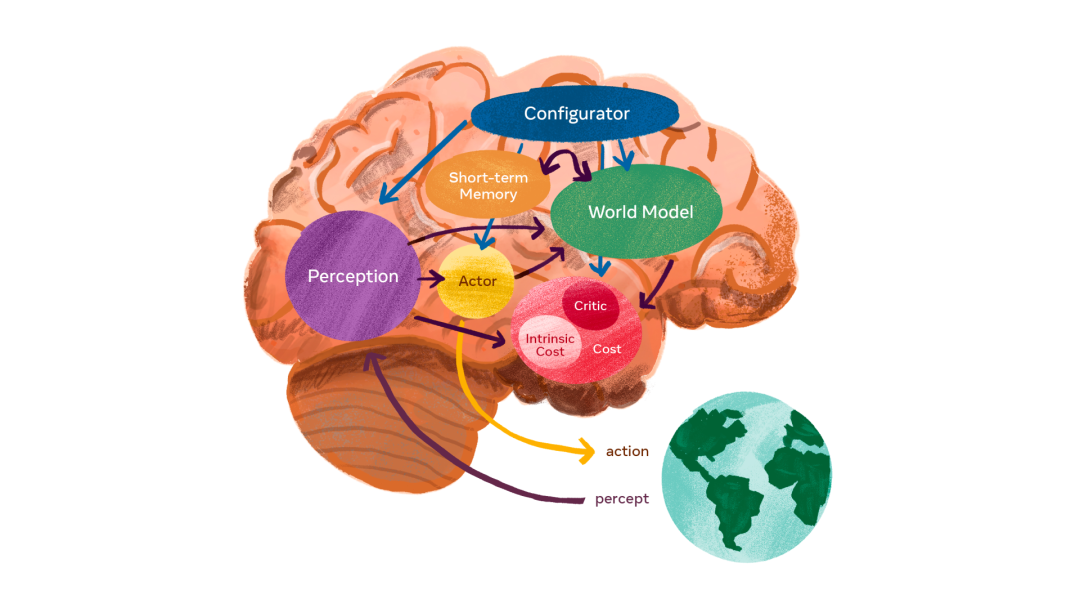
- 配置器模塊負責控制任務的分配和調參。
- 感知模塊負責接收來自傳感器的信號并估計世界的當前狀態。
- 世界模型模塊的作用有兩點:(1)補全感知模塊沒有提供的信息;(2)預測合理的未來狀態。
- 代價模塊負責計算和預測智能體的不合適程度。由兩個部分組成:(1)內在代價,直接計算「不適」:對智能體的損害、違反硬編碼的行為等;(2)評價者,預測內在代價的未來值。
- 行為者模塊負責提供動作序列的建議。
- 短期記憶模塊負責跟蹤當前和預測的世界狀態,以及相關代價。
自監督訓練
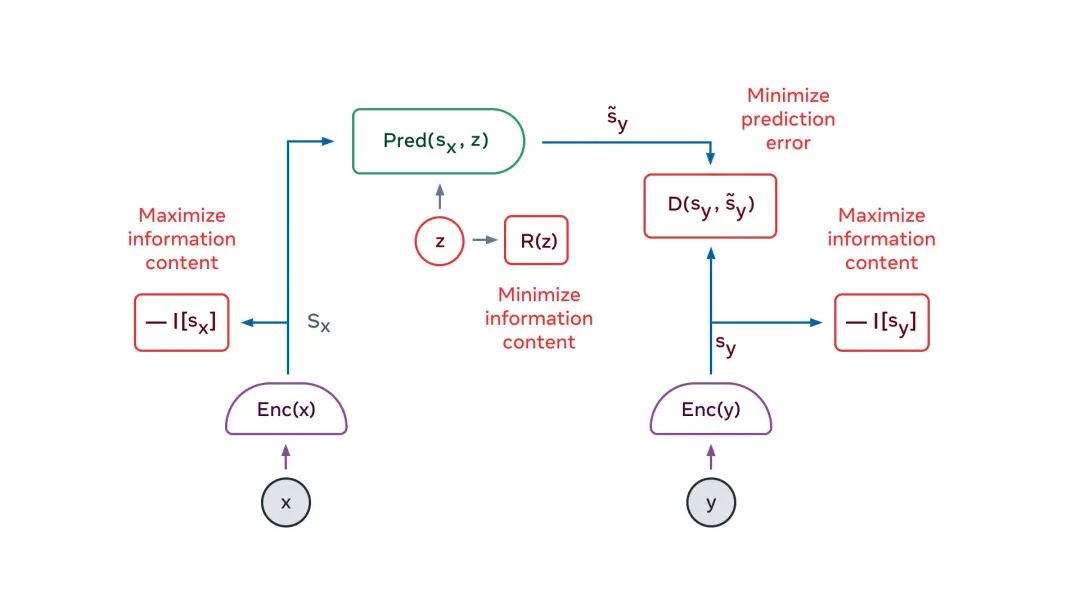
自主智能架構的核心是預測世界模型。而建構它的關鍵挑戰,是如何能使其呈現多種可能性的預測。 現實世界并不是完全可以單一預測的,特定情況的演變有多種可能途徑,并且狀況的許多細節與當下任務無關。 人類司機可能需要預測駕駛時自己周圍的汽車會做什么,但不需要預測道路附近樹木中單個葉子的詳細位置。 世界模型如何學習現實世界的抽象表示,從而保留關鍵細節、忽略不相關細節,且能在抽象表示的空間中進行預測? 解決方案的關鍵要素是「聯合嵌入式可預測架構」 (JEPA)。 JEPA能捕獲兩個輸入數據x和y之間的依賴關系。例如,x可以是一段視頻,y可以是視頻的下一段。輸入數據x和y被饋送到可訓練的編碼器,這些編碼器提取它們的抽象表示,即sx和sy。 JEPA以兩種方式處理預測中的不確定性:(1)編碼器可能會拋棄關于y的難以預測信息,(2)當潛在變量z在一個集合上有變化時,將導致在另一個可能性集合上的預測結果有變化。 那么,JEPA如何訓練? 直到晚近,唯一的途徑是使用對比方法,即提供足夠多的兼容x和y的示例、兼容x但不兼容y的示例、不兼容x但兼容y的示例。 但是當抽象表示達到高維時,此方法不切實際。 過去兩年出現了另一種訓練策略:正則化方法。當應用于JEPA時,該方法使用四個準則:
- 使關于x的表示,最大程度地提供關于x的信息
- 使關于y的表示,最大程度地提供關于y的信息
- 從關于x的表示中,最大程度地預測關于y的呈現
- 使預測器調用來自潛在變量的盡可能少的信息,來表示預測中的不確定性。
這些準則可以通過VICReg,也就是「方差、不變性、協方差正則化」(Variance, Invariance, Covariance Regularization)方法,轉化為可微的代價函數。 其中,x和y表示的信息內容最大化方式,是將其分量的方差保持在閾值之上,并使這些分量盡可能地相互獨立。 同時,此方法試圖讓y的表征可以從x的表示中預測,而潛變量的信息內容,則被使其離散、低維、稀疏或噪聲化的方式最小化。
JEPA的妙處,在于它自然地產生了關于輸入信息的抽象表示,這些抽象表示消除了不相關的細節,基于其可以執行預測。 這使得JEPA可以相互堆疊,用來學習具有更高層次的、能藉以執行更長期預測的抽象表示。 例如,一個場景可以在高層次上抽象描述為「廚師正在制作法式薄餅」。 因此,人類智能可以預測:廚師會去取面粉、牛奶和雞蛋;混合原料;把面糊舀進鍋里;讓面糊油炸;翻轉薄餅;重復以上流程。 在低一級的層次上,人類智能可以預測:舀面糊動作,包括勺子舀面糊、倒進鍋里、將面糊鋪在鍋面上。 這種層級的攤低可以一直持續到以毫秒為單位的廚師手部的精確運動軌跡。 在手部軌跡的低層次上,「世界模型」只能在短期內做出準確的預測。但在更高的抽象層次上,它可以做出長期的預測。
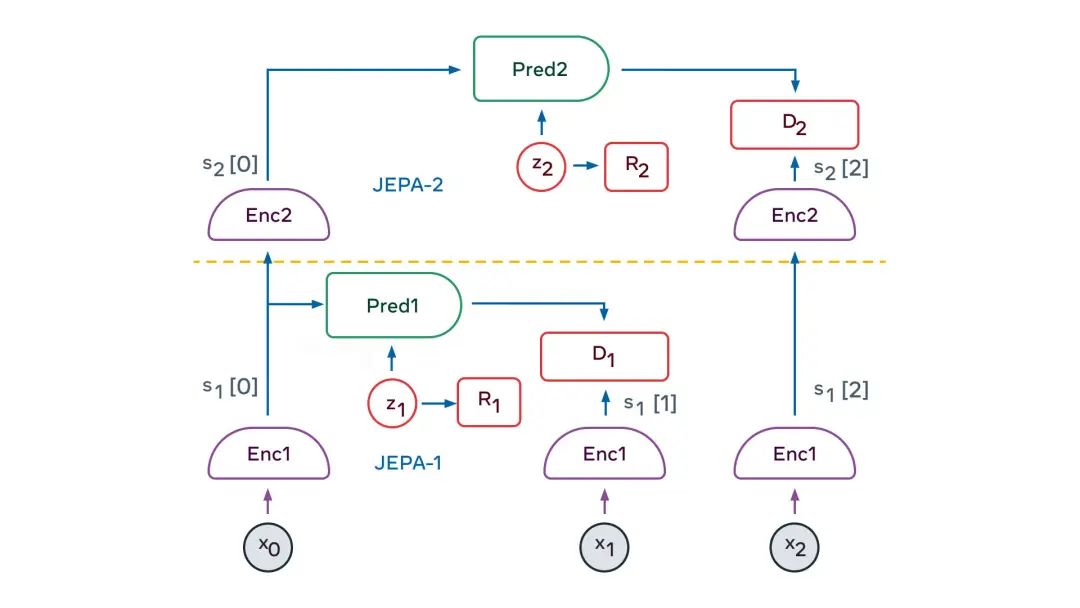
多層JEPA可用于在多個抽象級別和多個時間尺度上執行預測。訓練的主要途徑是被動觀察,輔助途徑是與環境互動。 正如嬰兒在出生后頭幾個月,主要通過觀察來了解世界是如何運作的。她了解到世界是三維的、有些物體排在其他物體的前面、當一個物體被遮擋時它仍然存在。 最終,在大約9個月大的時候,嬰兒學會了直觀的物理學——例如,不受支撐的物體會因重力而落下。 多層JEPA有望通過類似的觀看視頻、與環境交互等方式,來了解世界是如何運作的。 通過自訓練來預測視頻中會發生什么,它將產生世界的分層級表示。通過在現實世界上采取行動并觀察結果,「世界模型」將學會預測其行動的后果,這將使其能夠進行推理和計劃。
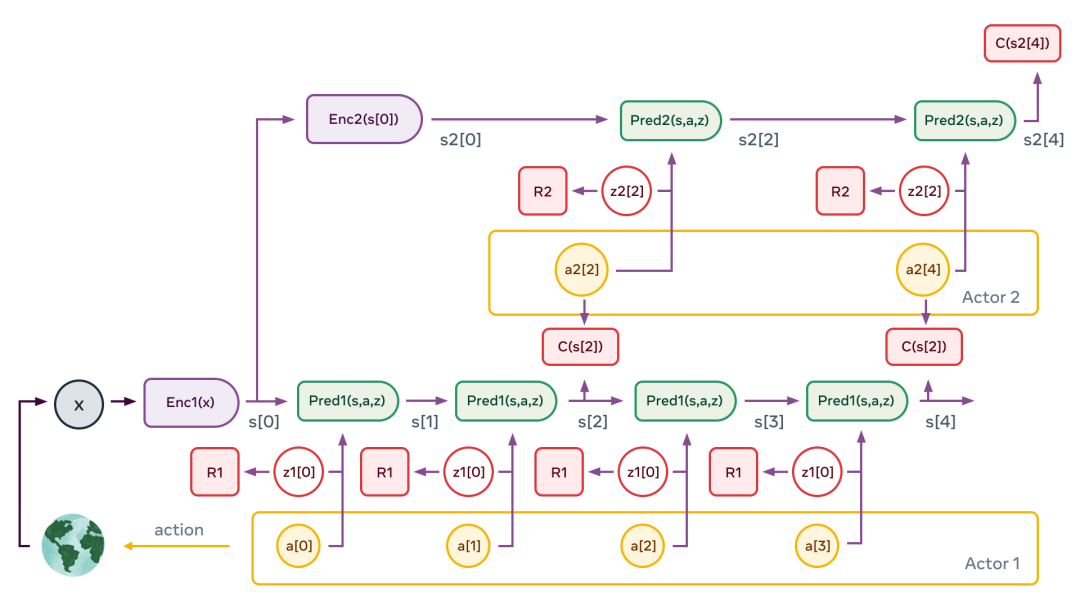
在LeCun看來,我們應該讓機器通過觀察來學會現實世界中的最基礎定律,這是讓機器學習世界模型的最主要途徑。 而對于現在的人工智能來說,最重要的挑戰之一就是設計學習范式和架構,使起能夠以自監督的方式學習世界模型,然后用這些模型進行預測、推理和計劃。 或許,這個概念并沒有想象中的那么「新」,但如何真正應用于實踐,可能還有很長的一條路要走。

























