OS近距離:mmap給你想要的快!
I/O問題一般不會被大多數人關注,因為大多數開發都是在做“業務”,也就是在搞計算節點的事情,通常遇到的I/O問題,也就是日志打的有點多了,磁盤寫起來有點吃力,所以iowait這個指標,關注的人也不多。
可惜的是,工作并不是只考慮怎么折騰CPU,數據總歸要落地的。一旦涉及到高性能的磁盤存儲,I/O問題就浮上水面。Redis這么流行,就是為了繞開磁盤性能問題而存在的。
換句話說,如果我的磁盤像內存一樣快,那還要內存干什么~
今天,我們就來簡單聊一下I/O。當然,更主要的還是傾向于和持久化打交道的磁盤I/O。如非特指,我們說的就都是它。

I/O都干了些啥?
I/O干的是啥?對我們使用者來說,簡單來講,就兩點。
- 和操作系統索要數據,并加載到緩沖區中。
- 填滿用戶進程緩沖區,并交給操作系統刷盤。
但也不是直接讀寫,因為操作系統有內核進程和用戶進程之分。為了保護內核的內存,用戶進程是不能隨便去讀內核所操作的數據的。想要數據,拷貝一份。
這一進一出,就涉及到用戶態和內核態的切換,也就是常說的系統調用,細節上肯定會比較復雜。

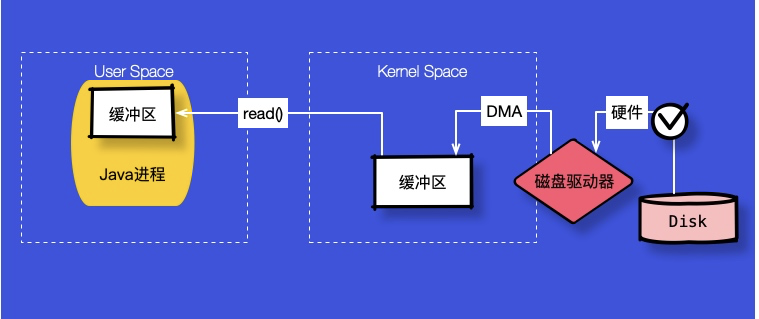
如上圖,就拿讀數據來說,我們可以把讀取過程分為以下幾個階段。
- Java進程發起讀取請求,調用最底層代碼發起read()系統調用。
- 操作系統通過DMA等從磁盤等硬件讀取數據。
- DMA讀取相關數據,存入到內核的緩沖區中。這部分操作是不需要CPU參與的。
- 接下來內核將會把自己緩沖區的內容,拷貝到Java進程的緩沖區中。
可以看到,由于一個讀取有操作系統的參與,它的交互過程就變的比較復雜。典型的,當Java進程讀取數據的時候,內核發現這部分數據已經存在于緩存中了,那么就直接拷貝出來;當內核緩存不存在這些數據的時候,那么Java進程將會阻塞在那里,直到所需的數據拷貝到用戶空間。
總結一下:內核進程所持有的內存,是不能直接訪問的,我們需要拷貝一份到用戶進程。
虛擬地址來幫忙
從上面的描述中可以看出,磁盤文件上的內容,要想被用戶進程所使用,就不得不經過kernel這個中轉站。既然這樣會影響效率,那么為什么不直接把這些磁盤上的文件直接發送到用戶進程呢?
這不是能不能做的問題,而是應不應該做的問題。既然用戶進程使用了特定的操作系統,就要按照操作系統的規矩辦事。在Linux操作系統上,把這些繁雜的事務交給操作系統,是最安全、最便捷的編程方式。
那么,我現在就是不想按照規矩來,把效率看的更重一些,怎么辦?
沒別的辦法,只有開啟一條綠色通道。
如果我能夠在用戶進程里,和操作系統內核里,讀到的是同一份數據,操作的是同一份緩沖區,那么目的就算達到了。
如果讓用戶進程直接去訪問內核所擁有的物理內存地址,是非常危險的。如何共享這些物理內存,這需要借助 虛擬內存。這就是所謂的綠色通道。
虛擬內存,肯定是相對于物理內存來說的。如果你反編譯一個二進制文件的話,可以看到它的引用地址是固定的。虛擬內存區域是進程的虛擬地址空間中的一個同質區間,即具有同樣特性的連續地址范圍。如下圖,MMU組件就專門負責虛擬內存到物理內存到翻譯,這都是《計算機組成結構》的東西,已經是現代操作系統的默認操作。

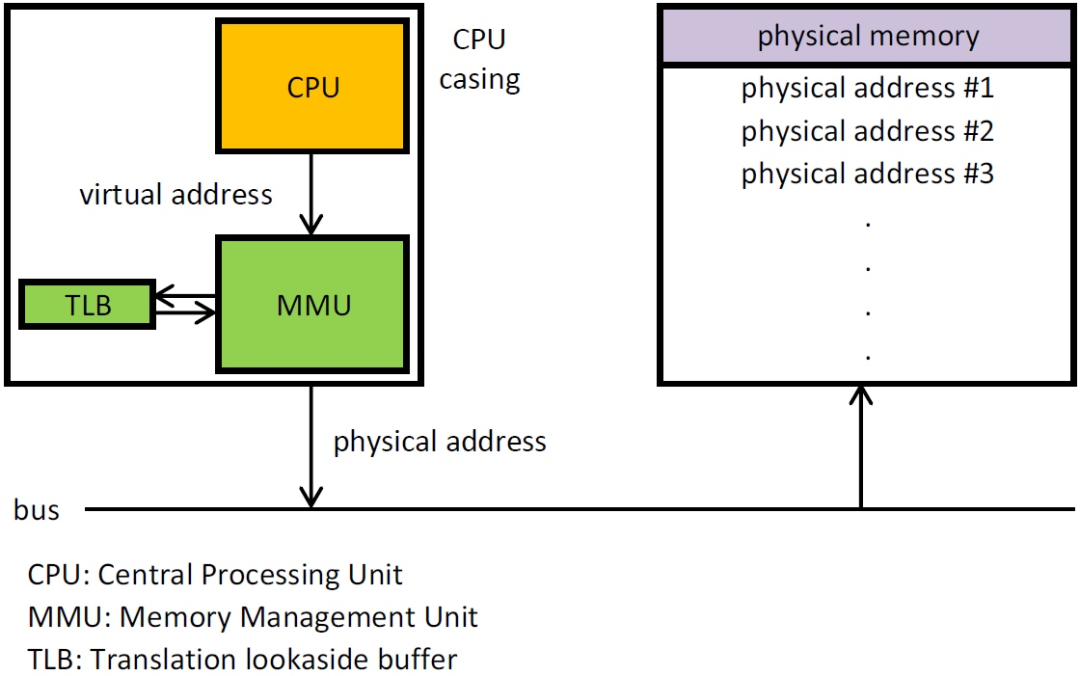
借助于虛擬內存,我們就可以使用不同的虛擬內存地址指向同一塊物理內存地址,變相的實現了內存數據的共享,避免了kernel和user進程之間的數據拷貝。
如果我們同時mapping一個內核空間的虛擬地址和用戶空間的虛擬地址,到同一塊內核實際的物理內存地址上,那么我們就能夠同時操作這一塊內存區域。
典型應用mmap
mmap (Memory Mapped Files) 就是這樣處理映射的一種特殊通道。它可以將一個文件,或者其他對象,映射到進程的虛擬地址空間。
當我們操作這一段內存的時候,就可以直接影響到最終操作系統上的文件。雖然文件的讀寫仍然由操作系統去做,但明顯的,我們不必再調用read、write等函數,從操作系統的內存中拷貝數據,這肯定能夠增加文件讀寫的效率。
MMAP也使得進程間共享編程型內存,進程通信成為了可能,也可以和內核進程進行協同式交互。當我們的物理內存空間不足的時候,甚至可以使用磁盤來模擬內存。
這就是抽象的魔力。
mmap的映射區域必須時候 物理頁大小(page_size)的整數倍,這也是操作系統為了增加處理效率所采取的批量處理模式(內存管理的最小粒度就是頁)。同時,mmap不能映射超過文件大小的區域,所以當文件大小發生變化時,就需要重新映射。
Java中有專門處理mmap的類MappedByteBuffer,我們可以通過FileChannel的map函數來獲取這個變量。
MappedByteBuffer mb = new RandomAccessFile("test", "rw")
.getChannel()
.map(FileChannel.MapMode.READ_WRITE, 0, 256);
//...
public abstract MappedByteBuffer map(MapMode mode,
long position, long size)
可以看到,通過position和size兩個參數,就可以直接將文件的內容映射到mb變量中。假如我們不同的進程做了同樣的映射,內存的使用量也不會翻倍,因為它們都是虛擬的地址。
假如你的內存非常大40GB,但操作系統的內存只有2GB,通過這種方式,依然能夠快速的讀取和修改文件。
在使用top命令的時候,我們經常看到swap區域,也就是使用文件去模擬內存的區域。當你使用2GB內存去操作40GB的文件時,通常會引起swap out,內存的數據要寫入到磁盤中。在mmap模式下,就不必再使用額外的swap去保證這個操作。當需要swap的時候,操作系統會直接使用原始文件,這些映射也會在要操作的目標文件上生效。
這整個過程中,除了操作系統缺頁引起文件讀寫,沒有其他任何的緩沖區參與,所以是非常高效的。
怎么用?
如果你仔細翻一下mmap相關的代碼,可以發現默認提供的函數非常非常非常的稀少,要拿它來搞事情的話,使用起來各種限制。
所以我們需要配合索引文件,來配合mmap完成高效的操作。
在一些數據庫和中間件中,我們經常看到mmap的身影,尤其是那些涉及到大文件讀寫的場景。
在kafka和rocketmq中,commitlog需要根據偏移量讀取數據,mmap無疑是非常好的加速方式。就拿kafka的索引文件來說,就大量使用了mmap;消費時Kafka 直接把文件發送給消費者,配合mmap 作為文件讀寫方式,直接把它傳給 sendfile。
包括主流的ES,也大量使用了mmap。這是一種作弊的行為。
不要高興的太早。
經過很多benchmark的測試,mmap在不同的Linux平臺上,并不總是有這么好的表現。當文件大小不被內存所容下的時候,頻繁的文件交換和缺頁依然會發生,這需要經過實際驗證才能確認服務真正的表現。
所以,在內嵌數據庫rocksdb中,mmap相關的優化參數是默認關閉的。mmap應該作為一種魔法存在,而不能作為一種通用的優化方法。
allow_mmap_reads=false
allow_mmap_writes=false
另外,mmap在作為寫入時,也并不是十分可靠。因為寫入到mmap中的數據,并沒有被真正的寫到硬盤,它需要操作系統在調用flush函數的時候才真正的刷到硬盤上。所以,作為數據恢復用的wal日志或者translog、redolog等,并沒有采用mmap這種方式。
mmap另外一個比較嚴重的問題,就是不可預料的I/O停頓。有了操作系統這一環,加上應用中的各種Buffer的參與,再加上預讀這種操作,應用在操作文件的時候,會比較平滑。但一旦使用了mmap,你可能在不可預料的情況下被阻塞,或者被不合理的預讀干擾,發生頻繁的I/O。
End
性能優化從來都是一把雙刃劍。這把劍,到底是能殺掉敵人,還是手殘傷了隊友,那就要看掌劍人的水平了。mmap也不例外,它有好處,也有缺點,多一點敬畏,結論從實踐中來,才是正確的態度。