現代 Web 開發困局

導讀
2021 年,Web 開發整體上仍然處于比較低效的狀態,各種開發,部署工具仍未很好的收斂,開發者仍然要面對選擇框架,選擇各種庫,選擇部署方式,溝通前后端接口等,一個完整的 Web 應用開發會牽扯很多不同的工種,而不同分工之間的協作卻是很低效的,本文旨在能夠很好的梳理當下 Web 開發的 "困局",以及我們通過何種方式,能夠走出這些困局,解放生產力,希望能給未來的工具發展給出一定的預測和啟發。
困境
設計/前端協作困境
在實際的 Web 開發中,UI/UX 的工作與前端的工作事實上是在兩個完全割裂的環境中進行的,比如,UI 會在 Figma 中完成頁面與組件的設計,而前端則是根據設計好的原型圖,在代碼環境中去復現原型圖,這其中就出現了幾個協作問題。我把它簡要總結成四個問題:
- 應該先設計再開發,還是先開發再設計?(Dev First or Design First?)
- 如果說設計的原型圖是前端開發的上游,那前端應該如何更高效地獲取設計的上游更新?
- 設計圖中藏有很多可復用的概念與元素,如何很好的傳達給前端?
- 前端工程師是否有義務參與純樣式的開發?既然 UI 已經完成了樣式的設計,為什么前端仍然需要重新實現一遍?
下面我們逐個討論這些問題,之后給出可能的解決方案。
Dev First Or Design First
先來討論第一個問題,這是一個困擾了我很久的問題,在之前的工作經驗中,我的處理方式往往是,以功能為主的組件,先開發,再設計(比如富文本編輯器),以展示為主的,先設計,再開發,但是實際的協作仍然會出現很多問題:
Dev First:先開發再設計,往往前端程序員需返工 (比如原來調的現成組件現在不能直接用了,需要自己重新寫一個),降低前端程序員工作體驗,而在設計圖不穩定的時候,前端會反復地 follow 設計圖的改動,降低前端程序員的工作體驗,有時甚至會引發員工間的矛盾。
Design First:設計對組件邏輯理解較為模糊,難以涵蓋組件所有狀態的樣式,而為了枚舉或描述組件的所有可能狀態,常常過于繁瑣,會有很多長得很像的重復原型圖,而缺斤短兩的原型圖,也容易影響前端工程師的工作體驗,甚至會提升責任推卸的可能性 (前端覺得有些組件狀態設計圖沒有給到,就停工了,將責任推卸給 UI)。
之后我們可以看到,如果不改變協作模式和工具,這個 dilemma 是無法消除的。
前端應該如何更高效地獲取設計的上游更新
設想這樣一個場景,公司有一個完整的設計團隊,它們有時會更新一些組件的圖標,當這些圖標得到更新后,設計團隊可能會手動通知前端工程師,前端工程師再下載到新的 icon 文件,將該文件放入倉庫的 src/assets 下,再 push 代碼,觸發流水線,部署完畢后,icon 得到更新。
上述的過程顯然是十分低效的,設想這樣一種情形,全公司有上百個網站,幾乎每個網站都用到了公司的 logo,但絕大多數網站都是將該 logo 放入 src/assets 這樣的形式來部署的,那么當公司更新 logo 的時候,就需要所有代碼倉庫都更新該 logo,浪費很多團隊,很多人的時間,并且更重要的是,公司 logo 的全量更新成為了一個漫長的過程。
除了上面這個例子外,還有很多例子,比如設計經常會給原型圖做一些修改,每次修改后,如果我們希望足夠敏捷,那 UI 就會當場通知前端,前端再打開 Figma 之類的軟件和 VSCode 等開發工具,完成了更改 (更多時候,前端還需要仔細檢查到底是哪里更改了,有時需要和 UI 進行同步溝通),在這個場景下,前端像是被 UI 牽著鼻子走的工種,長此以往,前端會覺得自己的工作沒有價值,引發更深層次的問題。
那為了防止這樣的現象,我們索性犧牲敏捷性,每個月迭代一版,前端統一更新 UI,但這樣又拋棄了 Web 的優勢之一:用戶使用的應用永遠都是最新的,在講究快速迭代的環境中,這種方式越來越少見,一個例子就是現在越來越多的 Web 應用忽略了 版本號 這個概念,因為只要能夠很好的追蹤 commit history,并規范好 commit message,版本號 這個概念其實也已經變得比較雞肋,它更多是桌面時代的產物。
設計圖中可復用的概念與元素,如何很好的傳達給前端
成熟的設計團隊,往往會給有自己的設計系統,會在團隊內部沉淀一些復用的概念與元素出來,比如,規定所有卡片組件的 box-shadow 都是同一種格式,規定調色板的基礎色號有哪幾種,字體大小有哪幾級,但這些信息往往并不能在原型圖層面很好的展現出來,而 UI 也很少會將這些概念很好的傳達給前端,前端也覺得自己沒有義務理解這些設計層面的概念,進一步加深了兩個工種的分裂。
UI/UX 和 前端工程師之間的概念往往并不互通,而互相也覺得自己并沒有義務去了解對方專業中的知識,但日常的協作又有極多的的深度交織,UI/UX 是最了解設計里面的邏輯和復用的,但真正實現邏輯和復用的卻是前端工程師。這種職能的錯配和重疊是問題的根源所在
設想這樣一個情景:一個 Web 應用起初的設計,并未把主題色更換考慮在內,而 UI 團隊內部有基礎調色板,很多組件都共用一些基礎色號,但并未在原型圖中展示這些信息,事實上前端工程師也不關心這些,這就導致了幾乎所有前端代碼中,組件的顏色都是 hardcoded 的,并未體現出邏輯性和復用性,然后過了兩個月,UI 團隊決定支持主題色更換,于是前端團隊又面臨著巨量的體力活。
既然 UI 已經完成了樣式的設計,為什么前端仍然需要重新實現一遍
設計師給出原型圖,前端再實現一遍,這很契合我們往常的經驗,但是仔細思考會發現這是很荒誕的,這就像游戲行業的 建模師 建好了人物模型后,游戲開發者竟然還需要在游戲中重新實現一遍模型。
設備的尺寸布局,responsive 排版方式,這些層面的設計,按理來說應該由 UI/UX 來把控,可事實上卻是由前端工程師把控的,前端工程師似乎承擔了太多設計層面的 實現任務。
就像上文提到的,造成這四個 UI/前端 的協作困局,根本原因在于 職能的錯配和重疊,兩個工種深度耦合,互相牽制,用一個圖概括就是這樣:
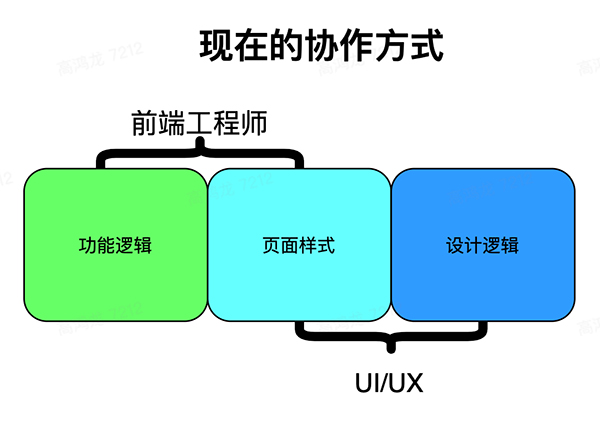
在頁面樣式這部分,工程師與設計師都參與了進來,這部分就是兩個工種的 職能重疊部分,重疊的部分帶來了大量的重復勞動與溝通成本。
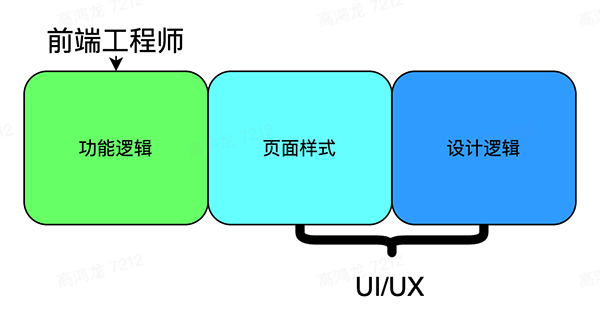
為了徹底解決上面的問題,我們首先將 職能重疊 的部分盡可能減少,從情理上講,頁面樣式 這塊工作應該歸屬于 UI,而前端工程師只需要負責 功能邏輯 即可,這樣兩個工種的工作就正交了:
接下來我們需要思考的問題是 為什么當下的工具和生態不允許這樣的分工方式?
從工具角度來說,目前 UI 用的工具以 Sketch,Figma 為主,它們都是比較好用的圖形化設計軟件,都支持組件設計,也支持一定的復用邏輯,原型圖也往往直接能夠看到元素的 css,這樣看起來似乎 前端工程師 只需要無腦復制粘貼 css,就可以復制出一個一模一樣的頁面了,
但真實情況并不是這么簡單,一方面就像上文提到的,直接復制粘貼 css 無法在前端代碼層面體現出設計的復用邏輯,而且原型圖的 css 往往采用絕對定位,實際的 css 要考慮 responsive,多設備適配等問題,并不能直接搬過來用,所以這條路事實上行不通。
根本原因在于 UI 工程師是在白板上進行設計,而不是在真實的組件上進行設計。
UI 工程師往往都在 Sketch 等軟件提供的白板上用各種按鈕,圖形去拼接出圖,這個東西和前端的環境完全分離,做的工作完全不能應用到實際的組件上,一方面我們沒有提供給 UI 工程師工具讓其將設計應用于某組件上 (你總不能期望 UI 工程師打開 VSCode,從 git 拉代碼吧),一方面前端工程師的組件也往往是作為一個 npm package 里面的一個 submodule 存在的,因此,我們事實上需要一種 UI 工程師和前端工程師互通共享的工作環境,在這個環境中,前端工程師可以實現組件的邏輯,UI 工程師可以直接給組件骨架添加設計樣式。
也就是說,次世代的前端開發工具,應該是同時面向 設計師 和 工程師 的,而同時也是 面向組件 的。它應該是一個對于設計師用戶友好的平臺,可以在這個平臺上看到工程師已經產出的,帶有邏輯骨架的組件,并且在平臺上為這些組件添加樣式,有了這樣的平臺,對于組件的開發,前端工程師只需要關心邏輯即可,剩下的樣式工作可以全部交由設計師來完成,這樣就實現了兩個工種職責的隔離,雙方都只需要負責好自己的事情,不需要互相替對方去實現一些想法。
所以概括一下,我認為未來的協作方式應該是這樣:
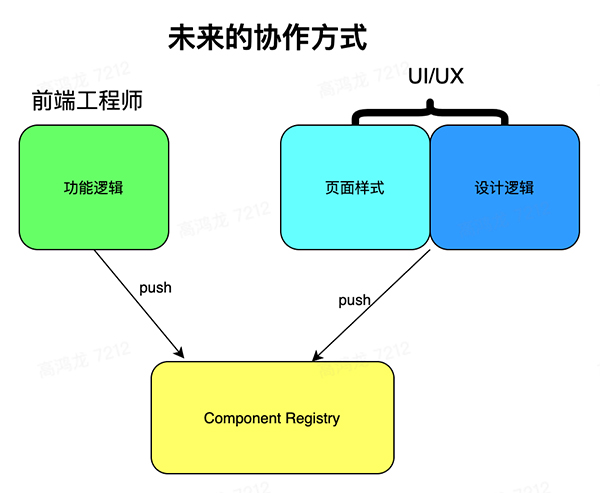
上面這張圖中,前端和 UI 都共享一個 Component Registry,也就是 組件注冊中心,它一方面向前端工程師暴露代碼接口,一方面又向設計師暴露設計面板,在這個 組件中心 里,一個 team 可以共享的看到所有組件,這是個統一的協作平臺。
一點小想法:目前 AI 已經可以幫我們設計 Logo 了,日后也可以幫我們設計組件的樣式,AI 可以學習一套組件的風格,并且將這種風格自動的應用到其它組件上,,日后這樣的方式或許可以幫我們快速地得到設計統一美觀的組件庫。
對于前端來講,代碼的 commit history,版本控制,它們的 scope 都應該是 組件,開發是針對組件的,而 UI 則可以打開一個組件,然后設計套件會自動將組件的一些基本元素提取出來,為 UI 提供圖形化的設計面板,完成設計后,轉化成 css in js 之類的東西,最終轉化成一條 commit history 提交到組件中。
從圖中看到,前端和 UI 都是在向 組件中心 push changes,而設計也可以在設計平臺中定義一些全局變量,一些復用的樣式,組件也會依賴于設計團隊的這些設計變量,于是設計團隊可以通過統一更改變量來達到全局組件樣式風格切換的效果,到這里為止,設計層面的復用和邏輯職能,甚至是 responsive design,多設備尺寸適配,都收斂到了設計師手里,因此設計師還需要學習流式布局,網格系統等概念,這從職能上看也更為合理,也更容易讓設計師來發揮更大的能力。
同時,因為組件在功能邏輯層面,前端已經做好了 composition,它們已經實現了組件之間的相互依賴關系,所以 UI 無需關心組件之間的依賴關系,當一個子組件的樣式更新后,在設計套件中,父組件也能看到更新后的子組件,組件邏輯的依賴關系,收斂到了前端手里。
這種協作模式,我稱為 面向組件的研發模式,而目前,像 https://bit.dev/ 之類的產品,已經在實踐這個想法,但是它們只是給工程師提供了一個面向組件的研發平臺,還未給設計師提供設計平臺,這是這類產品目前欠缺的地方,很可能也是它們未來的發展方向。
讀者可以回顧一下之前討論的四個問題,我們會發現在新的協作模式下,四個問題都得到了較好的解決。
組件這個層級的協作方式發生改變后,頁面級的組件 Composition 問題,也就是由這些組件組合成一個完整的頁面時,也可以同樣地在這套系統上完成協作,只需要把頁面當成一個復合程度很高的組件即可,實際的頁面內部會有很多數據 fetch 和處理邏輯,這塊的處理方式,在下文中會有提到。
數據交互困境
桌面應用誕生的最早期,客戶端是可以直接連接數據庫的,在當時,關于怎樣獲取數據,怎樣存數據的邏輯,是放在客戶端負責的,之后 Web 的發展,讓更多的邏輯放在了后端,后端負責連接數據庫,并且將更簡單規范的 HTTP (以 Restful 為代表) 請求轉換成對應的 SQL 等數據庫語句,在后端完成和數據庫的交互 (此處的數據庫指廣義的數據庫,可能包含各種中間件,各種形式的存儲等),前端只需要消費這些簡單的接口即可,看起來是降低了前端的負擔 (無需思考如何和后端的數據庫等服務交互,后端已經封裝好了)。
但在實際的業務場景下,以 Restful[1] 為主的這種后端 API 思路仍然出現了很多問題,我們發現實際的前端場景下,前端往往需要對數據有更精細的控制:
試想這樣一個情景:前端顯示一個評論列表,這里只用到了每個人的頭像和昵稱,但是后端提供的 profile 接口卻會連著其它的手機號,個性簽名等等一系列信息全部返回了,這個時候后端就返回了很多無用信息。
上面的場景說明,如果后端將用于操縱數據的接口封裝的抽象層級過高,會出現無法滿足前端的靈活使用的問題,除此之外還有處理一對多關系,比如一個班級里面包含很多學生,students 是 class 的一個屬性,那使用 GET 請求請求 class 的時候,是否應該返回它的子屬性 students 呢?如果前端希望能夠控制,那往往又需要引入新的 query parameter 來控制,這又增加了協商成本和文檔成本。
基于 Restful 的開發模式,實際體驗往往是前端仍然需要去看接口文檔,為了讓接口有靈活性,需要引入很多自定義的 query params,由于接口本身的靈活性差,導致前端程序員需要思考使用什么樣的順序和方式調用接口,才能實現一個功能,很多時候前端需要被迫拼接,堆積接口調用,甚至會出現在前端手動遞歸調用后端接口獲得一個樹狀文件夾數據這種現象,可見這種方式是有很大問題的。
除此之外,普通的后端 CRUD 接口,本身的實現很簡單,但是由于前后端分離,語言也可能不同,導致前端遇到接口問題時,必須要和后端協商,后端再做出改動,真實情況是 讓前端去學習后端 CRUD,并且直接對后端做出改動,比前端和后端協商來的效率高,根本原因第一在于 Restful 本身的靈活性問題,其次在于簡單的后端查詢業務由于和前端的業務深度耦合,這部分工作應該收斂到一個工種上,并且考慮到傳統的后端 CRUD 的代碼很大程度可以自動生成,所以我們接下來要做的事可以總結為:把常規的后端業務實現的任務收斂到前端工種,并且通過更好的 API + SDK + P/F/SaaS 讓常規的后端業務盡可能自動化+服務化,從而淘汰掉傳統的后端 CRUD 工種,提升整個系統的效率。
回過頭來想一下,如果后端希望暴露給前端一個安全的操縱數據的接口,使用 HTTP Path + Method 的這種方式顯然不夠強,關于數據關系模型是一個關于集合的數學理論,它在數學中一開始的描述方式是使用 關系代數[2] 這樣的語言描述的,基于樹狀關系(HTTP Path 是一種樹狀的命名空間) + 方法(Get Post Delete Put 等) 的描述方式過弱,遠遠無法支撐實際的數據操作。
但直接使用 SQL 語言,一方面是安全性的問題(可以通過代理+一些權限驗證方式解決,不是問題的關鍵),一方面是 SQL 語言這種模式和前端的語言環境太過割裂,前端被迫進行字符串拼接,與之相對的是 MongoDB 的查詢語言,其和 javascript 語言的貼合度較之 SQL 要好很多,前端程序員可以用很自然的方式寫出一個查詢語句。
與此同時,基于 Restful 這樣的模式,讓很多的后端代碼變成了非常簡單的 CRUD 代碼,很多代碼就是為了將 restful 接口轉化成 SQL 語句,大量的時間被耗費在了這些無聊的事情上,降低了開發效率,這些簡單的操作應該被自動化。
在這樣的困境下,GraphQL[3] 應運而生,它用一種更優雅的方式實現了聲明式數據請求格式,相較于 Restful,它更像是 SQL 這種聲明式的語言,從 Restful 到 GraphQL 的轉變,對于前端來講則是命令式到聲明式的轉變,從思考 "what do I need to get I want" 到直接思考 "what I want"。
但是僅僅依靠 GraphQL 還是沒解決這兩個問題:
- Restful 時代的 CRUD 代碼轉變成了 GraphQL 的 resolver 代碼,后端還是需要手動寫,或者使用 codegen 工具來生成代碼,仍然沒擺脫樣板代碼的桎梏。
- 前端對數據的請求的狀態管理:重復請求問題,數據依賴更新問題。
先討論第二個問題,在前端的業務場景下,數據依賴可以分為兩類:一類是純前端的數據綁定,一類則是涉及到后端數據的綁定,狀態的綁定也是前端這種響應式系統和轉換式系統的最顯要的差別,這是 Web 要處理的最核心的問題之一。
響應式系統(reactive system) 和 轉化式系統 (transformational system) 的最大區別在于,前者更像一個狀態機,輸入與當前的狀態才能決定輸出,而轉化式系統(典型例子如編譯器) 則更著重的是輸入和輸出。Statecharts:a visual formalism for complex systems - ScienceDirect[4]
我們可以看到幾乎所有前端框架,無論基于模板的,還是 jsx 的,都解決了一個核心問題就是狀態之間的綁定,UI 狀態和內部 js 變量的綁定等,數據之間是有一個依賴關系的,它們可以用一個依賴圖表示。
鑒于 Web 的特殊性,我將狀態的綁定分為 純前端綁定 和 前后端綁定,前者的綁定只發生在前端,比如一個 js 內部的變量和 <input> 的 value 的綁定,而后者則涉及到前端狀態與后端狀態的綁定,比如,一個評論列表與后端的評論數據做綁定。
(更多的時候,程序員并沒有把后者理解成一種綁定,因為目前的工具還是將這個過程作為一種主動 fetch 的命令式做法,沒有像前端框架一樣提供了簡單的聲明式綁定,這也是目前發展的不足之處,我認為未來前后端的綁定,也應該是像純前端綁定一樣簡單,命令式,消除顯式的 http 請求代碼)
試想這樣一個場景:一篇文章下面有評論列表,你在評論框中添加了一條評論,這時按道理來說,前端的 UI 列表與后端的評論數據應該是雙向綁定的關系,評論列表應該立即得到更新,但這時前端程序員的做法很可能是顯式的寫一個邏輯,當新建評論后,手動重新請求評論 api,然后得到更新,這種做法像極了使用原生 DOM 和 js 處理前端 UI 和數據的綁定關系,手動維護狀態,手動調用 DOM 接口,從這個角度看,兩種綁定的發展路線是類似的,只不過 前后端綁定 的相關工具是最近兩三年出現的。
處理前后端綁定的框架,代表性的有 React Query[5] (2019 年建倉) 和 Apollo GraphQL Client[6] (2016 年建倉)。它們解決的問題都是使用聲明式的語法,處理前后端綁定的場景,都基于 GraphQL,它們往往被人稱作數據層的狀態管理工具,為了更好的理解本文意圖,我將其稱為 前后端數據綁定工具。
在上文的 設計/前端協作困境 中提到的基于組件的協作流,只是對單組件的協作,而一個復合型應用需要將這些組件組合起來,填充到頁面中,這個場景下多了兩個要解決的問題:
- 組件和后端數據的綁定問題。
- 純前端綁定。
前后端綁定方式
拿一個最簡單的例子,一個填寫個人信息的表單,在傳統的 Web 思路中,如果使用框架的話,會將一個組件內部的 r 和表單的 <input> 的 value 屬性做綁定,當用戶點擊 "提交" 按鈕時,執行一個 onSubmit 方法,方法內部將數據作為 body,一個 POST 請求將數據傳給后端。
這樣做沒問題,但它會阻擾我們理解問題。使用"面向綁定"的方式理解這個問題的時候,這個問題其實變得很簡單,我們將后端的個人信息數據與組件內部的狀態做綁定,當用戶點擊提交前,綁定處于 out of sync 的狀態,點擊 "提交" 進行同步,進入 sync 狀態。這樣理解問題,前后端的數據交互問題就變得清晰明朗了起來。
那么與此同時,因為頁面的右上角可能有你的頭像,那個頭像的組件也和你的個人信息的子屬性 avatar 綁定,這時,當表單進行 sync 后,由于頭像組件也綁定了有依賴關系的數據源,所以數據層會自動更新頭像:
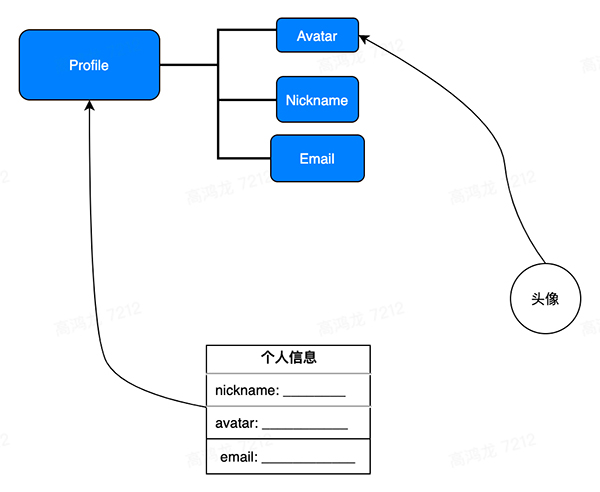
上圖中,表單和 Profile 做了綁定,頭像和 Avatar 做了綁定,當個人信息點擊提交后,數據狀態管理層會自動檢測到 Avatar 組件所依賴的數據的父節點發生了 Mutation,從而自動觸發 refetch,獲得更新后的 Avatar。
如果我們能夠保證所有的數據源的請求都是以 GraphQL 的話,那么我們可以使用 GraphQL Query 作為前后端數據綁定的聲明式語法,而根據對 GraphQL + Endpoint 構成的實時數據圖依賴分析,可以實時地解決數據的依賴變化問題,這個過程可以直接在前端完成。在 React Query 中,由于其本身的設計是后端無關的,數據間的依賴關系是通過手動維護 query 的命名數組進行的,尚未達成自動解決依賴的問題。
為了更好地在下面討論組件,我們先將組件從復用性的高低可以分為兩類,一類是 通用型組件,一類是 自治型組件。 前者盡可能地讓自己的能力通用化,自己內部不維護網絡請求等信息,而是根據傳入的 props 來動態地決定與后端數據的依賴,以及數據源和組件內部狀態的綁定關系,而自治型組件通常可以獨立使用,其自己內部實現了網絡請求等邏輯,但是通用型較差,通常只能實現特定功能,類似于 iframe。
舉個例子,繼續拿表單組件為例,通用型表單組件從外界接受數據源,以及請求后的數據的屬性與組件內部的對應關系,除此之外,往往還需要提供一個數組用來生成相應的表單列表,數據從哪來,數據和表單怎么對應,表單的 validation 函數,都從外界傳入,組件本身只實現邏輯框架和設計樣式。
而對于自治型表單組件,很可能是一個飛書投票組件,從飛書小程序中生成一個組件實例,就可以直接使用,它內部實現了相應的數據邏輯,用戶可以直接填寫,就可以在飛書投票后臺看到該組件收集的投票信息。
對于純前端的綁定來說,本質上還是組件的樹狀結構組合,很多頁面可以通過代碼的方式寫成一個大組件,不管是單一功能型組件還是頁面,都可以統一的視為組件,使用統一的方式看待和處理。
再來討論上面的第一個問題,如何解決后端程序員仍然要寫很多 GraphQL Resovler 代碼浪費很多時間,顯然,從數據庫的 schema 出發,是可以生成一些默認的 Rosovler 代碼的,但是需要程序員手寫的原因在于,默認生成的 Resolver 代碼往往缺一些和具體業務相關的東西,基于此可以使用約定大于配置的思路,為用戶提供默認的 Resolver 能力,并給用戶提供自定義的 Custom Resolver 的接口,在這個方向上,Hasura[7] 已經做了一些工作,它們也是從數據庫出發,搭配權限驗證策略,自動生成統一的 GraphQL API 網關,供各種形式的前端來調用,大幅簡化傳統的 CRUD 代碼:
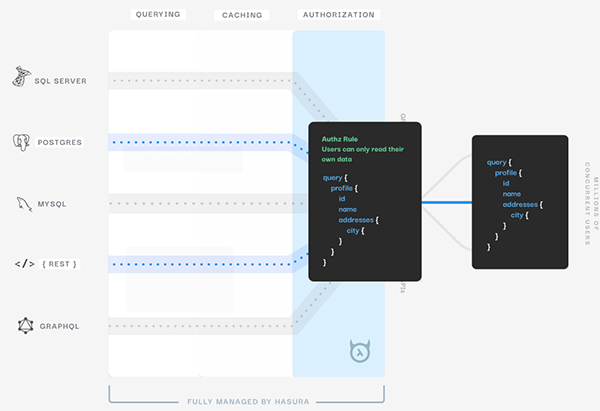
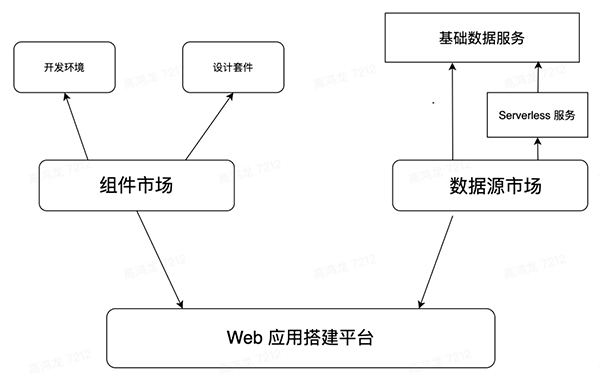
基于此,我設想未來的 Web App 的開發,可能會有很多的數據源提供提供商,比如像 OneGraph - Build Integrations 100x Faster[8] 中,將常用的公開 API 轉化成統一的 GraphQL API 網關供調用,這些數據源會像是一個 Market,組件有組件市場 (Component Market),而數據源也有數據源市場 (Datasources Market)。
對于數據源市場來講,每個人都能在其上發布數據源,可以像 Github 一樣做私有付費(Pay For Privacy) 的策略,和組件一樣可以供其它人消費,然后很多程序員可以快速借助統一的數據源和組件市場搭建出一個功能完整的現代 web app:
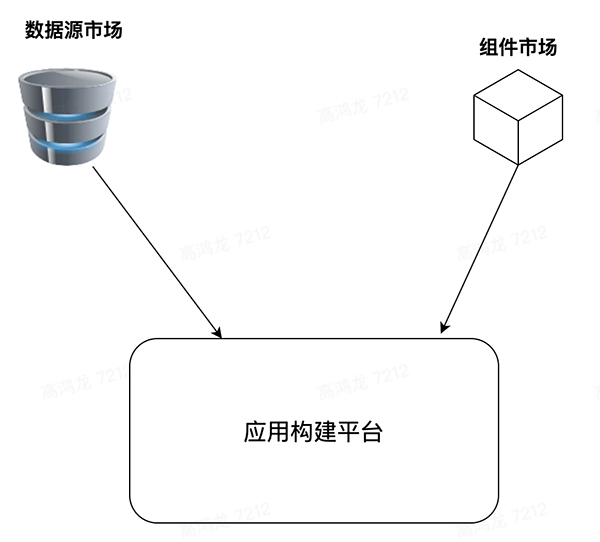
數據源平臺將會依托于 Serverless 提供的基礎能力,為泛開發者提供一個類似于 AWS Lambda 的函數注冊中心,提供幾種基本的數據交互場景的定制能力,開發者可以直接使用云 IDE 完成一些輕量的函數開發和更新,去填補單純根據 Schema 生成的 GraphQL Endpoint 能力的不足,架構設想圖如下:
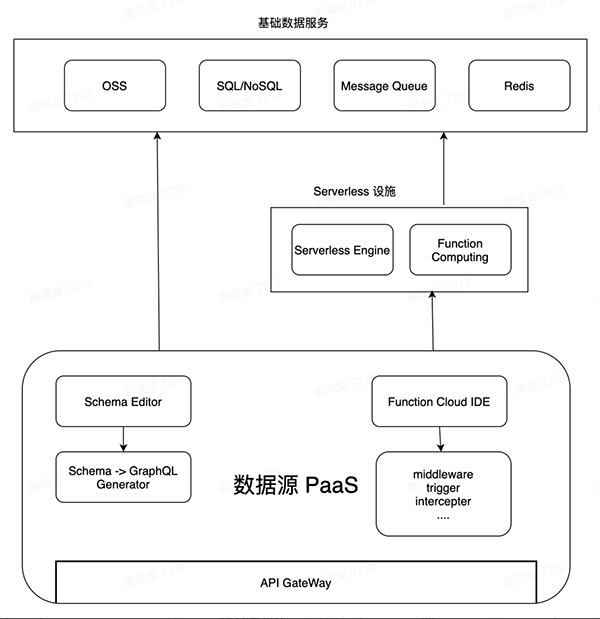
數據源平臺會依托于基礎存儲服務和 Serverless 服務,借助在線的 Schema Editor 來編輯關系型數據 Schema,借由 Schema -> GraphQL Generator 自動生成 GraphQL Endpoint,再由平臺提供的函數計算接口,在在線 IDE 中完成函數的邏輯的開發,這些函數可以在數據源中扮演 middleware,trigger,intercepter 等的角色,為數據源能力提供一些補全和增強。
數據源平臺會作為現代 web 開發的后臺的最高層次抽象,現代的業務側開發者往往只需要在數據源平臺上進行簡單的操作即可配置出數據源供前端消費。
有數據源 PaaS 的支持,傳統的 CRUD 工作可以很大程度消除,并且將一些剩余的任務收斂到前端(事實上相當于前端與 CRUD 后端工種合并了,但由于 CRUD 的工作大部分被自動化了,所以我們姑且仍然稱這種具有全棧 Web App 開發能力的工種叫做"前端")
上面這是一種思路,除此之外,還有將服務端與客戶端代碼放在一起的開發模式,典型例子如 Blitz[9],它也遵循同樣的思路,代碼中沒有顯式的 http 調用,直接通過函數調用的方式直接對數據庫做 Query,這樣的優勢是前后端合并,但是缺點還是有些明顯:由于沒有 GraphQL 這一層的轉換,可能會聲明過多的 Query 函數,它將處理 Query 復用的責任遷移給了程序員,并且一個數據源 對接 多終端的場景不太合適,后端和前端的綁定過深,不易抽取出數據源,如果移動端 App 和網頁都依賴這個數據源,使用這種方式不太好處理前后端的解耦,個人認為這種方式在前后端聚合程度較高,且只有單一客戶端(比如只有 Web,沒有移動端 app)的情形下比較適合,適用場景較窄。
構建困境
DevOps 平臺是一個資源消耗大戶:每當應用倉庫的 release 分支發生 commit 的時候,往往就會觸發流水線的測試,構建,部署等一系列運維操作,而目前的生態,前端的構建涉及到依賴的拉取,依賴圖分析,打包依賴,打包產物優化等步驟,一次完整的構建花費的時間可能是分鐘級的:

上圖給出了目前 Web 應用構建所要經歷的步驟,在敏捷開發的場景下,如果 release 分支經常得到更新的話,流水線將經常阻塞,而且如果是僅僅是更新了某個包的版本,或者更新了 readme,或者是修改了源碼中的變量命名,就需要全量的進行上圖中繁重的工作的話,這無疑是存在很大的算力和 I/O 浪費的。
我們上文曾提到以組件為中心的協作方式,在那種協作方式下,我們注重組件的快速迭代,而一個 web app 則會重度依賴上游的各種組件,總結一下,目前上圖的這種構建/發布模式存在這幾個重大問題:
- 修改一個文件中的一行代碼,觸發全量構建,大量算力,I/O 浪費。
- 上游的更新無法觸發下游流水線更新,或者說下游無法 "觀察" 上游的更新。
對于第一個問題剛才已經解釋過,第二個問題可能更為嚴重,下面解釋一下:
包和包之間的依賴,是一個 有向無環圖,在 npm package 這種管理模式下,一個包得到更新,往往依靠迭代新的版本號來解決,示意圖:
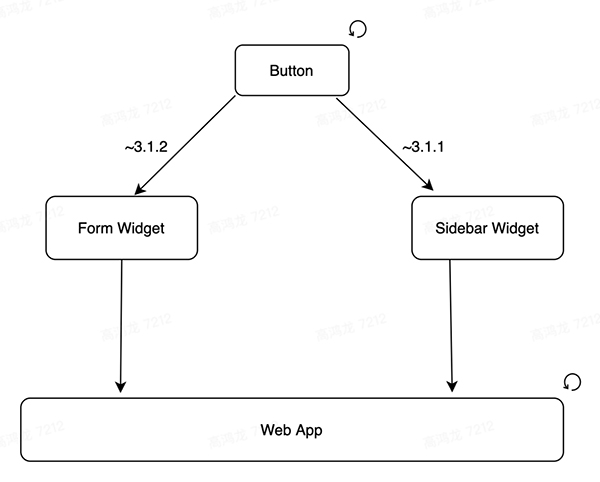
上圖中,Web App 依賴于 Form Widget 和 Sidebar Widget ,而這兩個組件又依賴于更基礎的 Button 組件,而當 Button 組件得到更新之后,比如版本從 3.2.1 遷移到了 3.2.2,這時候 Web App 應用本身是不會收到這個通知的,它必須手動重新運行一次流水線,才能將更新的依賴 3.2.2 打包進構建產物中。
在上面的 Button 更新的場景中,我們自然希望所有依賴 Button 的 Web App,在 Button 得到更新后,立即能夠使用新的 Button。
npm 這種基于版本的發布更新方式,雖然 semantic version 本身能夠起到對包的兼容性等的基本管控,但它本質上是一種君子協定,包不遵守也沒辦法,其實,我在上文中曾提到現代的 Web App 傾向于 "無版本號化",只要源碼改動能夠以極低的成本,極快的速度觸發產品更新,那版本號這種方案就可以廢棄,如果我們能夠很容易的追溯過去任何一個組件在任何一個時間點的狀態,那所謂的版本號的意義只是用來聲明 break changes 的發生節點。
前端開發在很多場景下被迫使用 monorepo,也是使用 semver (semantic version) 作為迭代的方式的失敗證明。若快速迭代一個包,則版本數爆炸增長,若想讓版本號慢速增長,則需要累計更新,又失去了敏捷性,這看起來是一個無法調和的矛盾 (關于 monorepo 和其它的替代方案的討論,會在下面一個 section 深入討論)。
造成這種構建困境的源頭,其實和歷史包袱有關,那就是純瀏覽器端的 module load 一直在過去都被認為是一個還沒有得到良好覆蓋的 es6 特性,但是截至目前,es module 在除了 IE 之外的其它主流瀏覽器中,已經得到了良好的覆蓋:
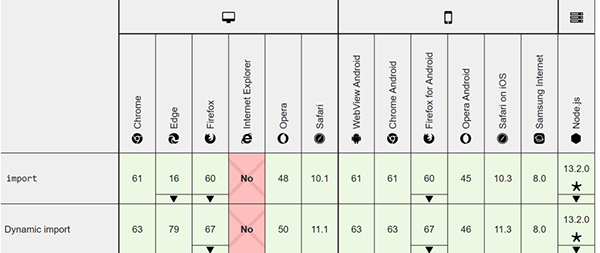
之前基于 webpack,rollup 等工具的生態,是為了既能讓開發側可以享受 module 帶來的好處,又能在瀏覽器側加載單文件提升加載速度和兼容性,如果我們不再考慮 es module 帶來的兼容性問題,那么我們就可以開始進行對 esm 的使用和驗證,相關的工具已經不斷涌現,典型的例子如 Vite[10] ,Snowpack[11] 等,這類構建工具可以簡稱為 bundless build tool。
但是目前,拿 Vite 來說,它們僅僅是在開發模式下啟用無打包模式,生產環境仍然使用打包,原因在于目前關于生產環境中使用 esm,一些測試結果表明仍然會影響性能,可汗學院曾嘗試進行 esm 的全量遷移,即便是在 HTTP2 的加持下,加載速度仍然變慢了:Forgo JS packaging?Not so fast (khanacademy.org)[12]
但是同樣也有一些數據表明,在應用本身的體量較小的情況下,全量使用 esm 是完全 OK 的:ES modules in production:my experience so far | Bryan Braun - Designer/Developer[13]
在可汗學院的博客中提到,全量 esm 的性能下降原因主要來源于 HTTP2 的一些加載 issue 和 多個小文件的解壓縮開銷增大,最后的結果是使用 esm 使得資源下載時間從 0.6s 漲到了 1.7s,最后得出的結論是目前仍然推薦使用 bundle 用于生產。
但是其測試并未考慮 esm 能帶來的更多的優勢,在這些新的優勢和網絡協議的發展下,esm 之后做到基本和 bundle 持平或者接近,個人認為是完全有可能的。
esm 能帶來的潛在優勢如下:
- 全局依賴緩存。
- 大幅降低流水線構建的計算和 I/O 負擔,甚至可以跳過構建這個步驟。
- 上游更新后,用戶加載頁面時,可以直接加載更新后的組件的代碼,達到了真正的敏捷更新。
可以看到后兩個問題是我們上面提到過的,如果使用了 esm,由于代碼的加載是直接通過 import 的方式,那么當上游的一個組件更新后,瀏覽器側就可以直接加載到更新后的組件的代碼,完全不需要觸發任何依賴了該組件的項目的流水線,而且當應用更新的時候,如果是打包模式,用戶需要全量加載新的 js 資源,但是在 esm 場景下,用戶只需要重新加載更新后的那一小部分即可。
很多 Bug 的發生都是局部的,比如 Bug 發生在組件內部,當修復了這些 Bug 后,工程師只需要將更新 push 到組件注冊中心,即可完成 Bug 修復,無需觸發下游無數的 app 的流水線。
而下游如果想鎖定上游的版本,也可以直接用 commit hash 鎖定,這樣就不會加載到更新的組件版本,保證了下游的一致性。
第一條:全局依賴緩存 是指,不同的域名,應用之間,有很多的包都是公用的,比如 react,這些包加載了一次之后,就不需要再次加載了,隨著用戶使用瀏覽器的增多,本地的緩存就會變得更多,用戶訪問新網站后,需要加載的新依賴就會變得更少,而這的前提是這些網站都使用同樣的 CDN,這種 CDN 應該專為瀏覽器側的 esm 做了優化,支持 HTTP2/3 等新的協議, 這種全局依賴緩存的建立,會進一步縮小 esm 和 bundle 之間的性能差距。
第一個將這個思路 built in mind 的,應該是 deno,它原生支持 http import,為服務側基于 cdn 的 import 的開發做了準備,與之配套的就是相關的開發套件,比如 VSCode 相關插件的支持,以及 CDN for module,對于這種 CDN,已經有了類似的產品:Skypack: search millions of open source JavaScript packages[14]。
個人大膽預測一下,五年之后的 web 開發,不管在 dev 還是 prod,不管是 server 還是 client,都會采用 CDN for module + http import 這種模式,帶來前端的新一輪敏捷革命。(現在已經開始了 ??)
代碼管理困境
沒有包管理的時代,人們的應用都包含了全部代碼,有了包管理后,人們傾向于每個包都有自己獨立的 git 倉庫來管理,但是有時候又想將一些包放在一起來開發,于是又有了 monorepo:

這樣搞來搞去其實沒什么意思,都沒有根本解決問題,我們引入 Monorepo 是因為我們想要同時對一些包做改動,然后統一發布更新,如果分開,程序員需要每天在不同的倉庫中輾轉,并且需要不斷地 publish&update 才能在另外的包用到更新的包,但是引入了 Monorepo 后,commit history 就混入了各種包的 commit,不方便追蹤某個模塊的改動,與之相對應的一種代碼管理方式是以 Git - Submodules (git-scm.com)[15] 為代表的子倉庫模式,父倉庫可以依賴于其它的子 git 倉庫,在父倉庫做的 commit 不會進入到子倉庫中,同時在開發父倉庫的時候,又可以修改子倉庫的代碼,甚至進行 commit,它很好的平衡了 作為依賴引入 和 想要隨時修改 的兩個需求,實測好用。
可惜的是在 npm 這樣的生態下,發布的東西和源碼可以不是一種東西,發布的包也不再是一個 Git 倉庫,其它包引用某包的時候,先不談有沒有 push 某包的權限,本身就無法當作 git submodule 來使用,即便把代碼 push 到源 repo 了,也不會觸發 package 的更新,還需要手動發布,這個和 Go 語言的基于 git 倉庫 + git registry 的依賴管理方式形成了鮮明的對比,個人認為這也是 npm 設計的一大敗筆。
我認為新的包管理模式,應該是和 Git 倉庫綁定的,參考 Go 語言,我們使用 Git 來進行代碼的管理,發布到注冊中心的包,仍然是一個 Git 倉庫,只不過是一個 remote history,當它作為依賴拉取的時候,會連并構建產物一并拉取,(git clone --depth 1 拉取最新的 snapshot) 而如果想要即時修改該包并且 push 更新,則可以使用提供的新的命令行工具進行 dependency 到 git submodule 模式的轉化,轉化后,會變成 git submodule,你就可以即時的修改這個包了。
而構建步驟和 semver 相關的東西,可以深度集成流水線和一些 tag,下游使用上游依賴也仍然可以鎖定版本,這些都可以解決。
所以我認為未來的包管理中心可能是:
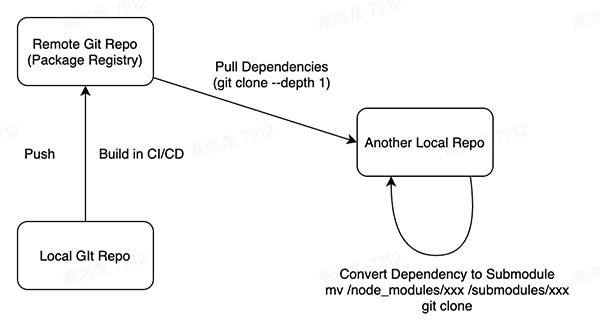
所有的包在 registry 中都是作為一個 git 倉庫存在的,而本地開發的時候,既可以將其作為依賴,也可以將其一個命令轉化為 git submodule,這樣就可以靈活的協調依賴和快速修改反饋之間的矛盾了。
而這個包注冊中心,應該和上面所說的組件注冊中心其實是一個東西,每個組件也都是一個 package,后者是前者的子集。
總結
把上面提到的技術設想畫成一張大圖: