阿里開源支持十萬億模型的自研分布式訓練框架EPL(EasyParallelLibrary)
原創一、導讀
最近阿里云機器學習PAI平臺和達摩院智能計算實驗室一起發布“低碳版”巨模型M6-10T,模型參數已經從萬億躍遷到10萬億,規模遠超業界此前發布的萬億級模型,成為當前全球最大的AI預訓練模型。同時,做到了業內極致的低碳高效,使用512 GPU在10天內即訓練出具有可用水平的10萬億模型。相比之前發布的大模型GPT-3,M6實現同等參數規模,能耗僅為其1%。
M6模型訓練使用的正是阿里云機器學習PAI平臺自研的分布式訓練框架EPL(Easy Parallel Library,原名whale)。EPL通過對不同并行化策略進行統一抽象、封裝,在一套分布式訓練框架中支持多種并行策略,并進行顯存、計算、通信等全方位優化來提供易用、高效的分布式訓練框架。
EPL背后的技術框架是如何設計的?開發者可以怎么使用EPL?EPL未來有哪些規劃?今天一起來深入了解。
二、EPL是什么
EPL(Easy Parallel Library)是阿里巴巴最近開源的,統一了多種并行策略、靈活易用的自研分布式深度學習訓練框架。
1.項目背景
近些年隨著深度學習的火爆,模型的參數規模也飛速增長,OpenAI數據顯示:
- 2012年以前,模型計算耗時每2年增長一倍,和摩爾定律保持一致;
- 2012年后,模型計算耗時每3.4個月翻一倍,遠超硬件發展速度;
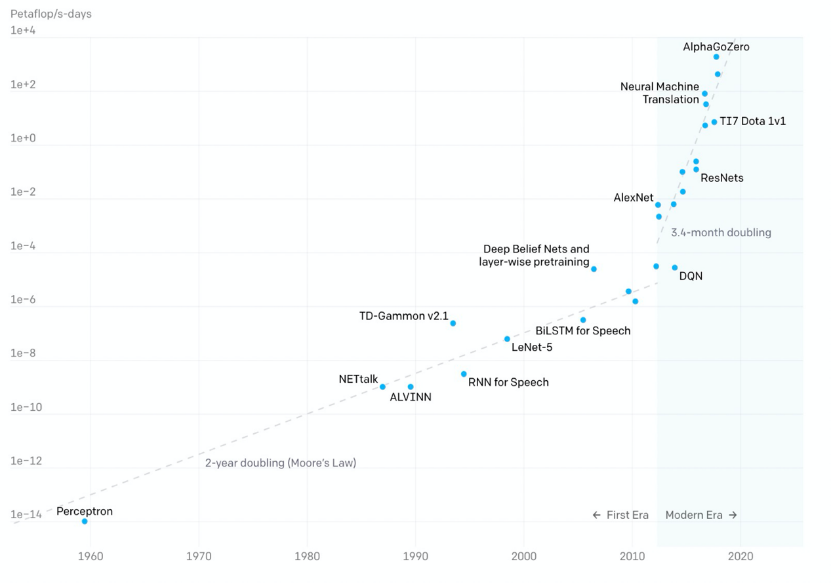
近一年來,百億、千億級的參數模型陸續面世,谷歌、英偉達、阿里、智源研究院更是發布了萬億參數模型。隨著模型參數規模的增大,模型效果逐步提高,但同時也為訓練框架帶來更大的挑戰。當前已經有一些分布式訓練框架Horovod、Tensorflow Estimator、PyTorch DDP等支持數據并行,Gpipe、PipeDream、PipeMare等支持流水并行,Mesh Tensorflow、FlexFlow、OneFlow、MindSpore等支持算子拆分,但當訓練一個超大規模的模型時還是會面臨一些挑戰:
- 如何簡潔易用:
接入門檻高:用戶實現模型分布式版本難度大、成本高,需要有領域專家經驗才能實現高效的分布式并行策略;
最優策略難:隨著研究人員設計出越來越靈活的模型以及越來越多的并行加速方法,如果沒有自動并行策略探索支持,用戶很難找到最適合自身的并行策略;
遷移代價大:不同模型適合不同的混合并行策略,但切換并行策略時可能需要切換不同的框架,遷移成本高;
- 如何提高性價比:
業界訓練萬億規模模型需要的資源:英偉達 3072 A100、谷歌 2048 TPU v3,資源成本非常高;
如何降本增效,組合使用各種技術和方法來減少需要的資源,提高訓練的速度;
為了應對當前分布式訓練的挑戰,阿里云機器學習PAI團隊自主研發了分布式訓練框架EPL,將不同并行化策略進行統一抽象、封裝,在一套分布式訓練框架中支持多種并行策略。同時,EPL提供簡潔易用的接口,用戶只需添加幾行annotation(注釋)即可完成并行策略的配置,不需要改動模型代碼。EPL也可以在用戶無感的情況下,通過進行顯存、計算、通信等全方位優化,打造高效的分布式訓練框架。
2.主要特性
- 多種并行策略統一:在一套分布式訓練框架中支持多種并行策略(數據/流水/算子/專家并行)和其各種組合嵌套使用;
- 接口靈活易用:用戶只需添加幾行代碼就可以使用EPL豐富的分布式并行策略,模型代碼無需修改;
- 自動并行策略探索:算子拆分時自動探索拆分策略,流水并行時自動探索模型切分策略;
- 分布式性能更優:提供了多維度的顯存優化、計算優化,同時結合模型結構和網絡拓撲進行調度和通信優化,提供高效的分布式訓練。
3.開源地址見文末
三、EPL主要技術特點
EPL通過豐富并行化策略、簡單易用的接口、多維度的顯存優化技術和優化的計算通信加速技術,讓每一位算法工程師都能輕松訓練分布式大模型任務。
- 豐富的并行化策略:EPL提供了多種并行化策略及其組合策略,包含數據并行、流水并行、算子拆分并行及并行策略的組合嵌套。豐富的策略選擇使得不同的模型結構都能找到最適合自己的分布式訓練方式。
- 易用性:用戶的模型編程接口和訓練接口均基于TensorFlow,用戶只需在已有的單機單卡模型上做簡單的標記,即可實現不同的分布式策略。EPL設計了兩種簡單的策略接口(replicate/split)來表達分布式策略及混合并行。分布式策略標記的方式讓用戶無需學習新的模型編程接口,僅需幾行代碼即可實現和轉換分布式策略,極大降低了分布式框架的使用門檻。
- 顯存優化:EPL提供了多維度的顯存優化技術,包含自動重算技術(Gradient Checkpoint),ZeRO數據并行顯存優化技術,CPU Offload技術等,幫助用戶用更少的資源訓練更大的模型。
- 通信優化技術:EPL深度優化了分布式通信庫,包括硬件拓撲感知、通信線程池、梯度分組融合、混合精度通信、梯度壓縮等技術。
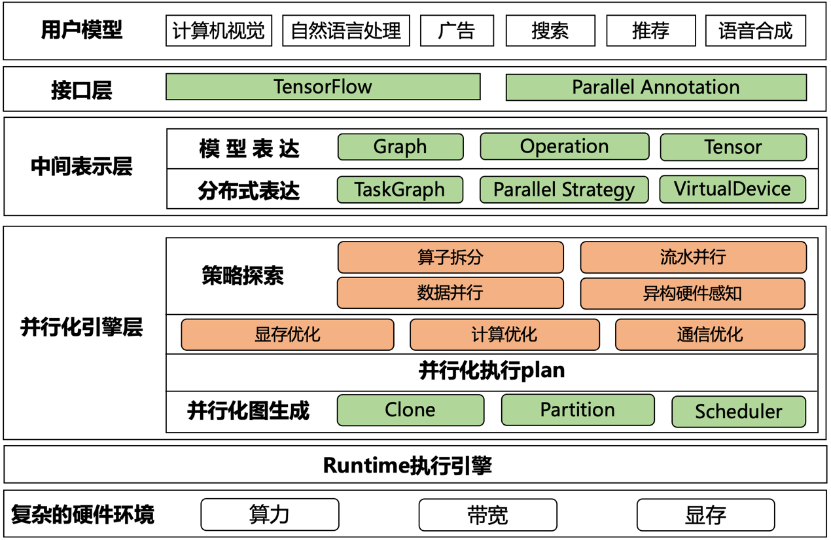
1.技術架構
EPL框架如下圖所示,主要分為以下幾個模塊:
- 接口層:用戶的模型編程接口基于TensorFlow,同時EPL提供了易用的并行化策略表達接口,讓用戶可以組合使用各種混合并行策略;
- 中間表達層:將用戶模型和并行策略轉化成內部表達,通過TaskGraph、VirtualDevices和策略抽象來表達各種并行策略;
- 并行化引擎層:基于中間表達,EPL會對計算圖做策略探索,進行顯存/計算/通信優化,并自動生成分布式計算圖;
- Runtime執行引擎:將分布式執行圖轉成TFGraph,再調用TF 的Runtime來執行;
2.并行化策略表達
EPL通過strategy annotation的方式將模型劃分為多個TaskGraph,并在此基礎上進行并行化。EPL有兩類strategy:replicate 和 split。通過這兩種并行化接口,可以表達出各種不同的并行化策略,例如:
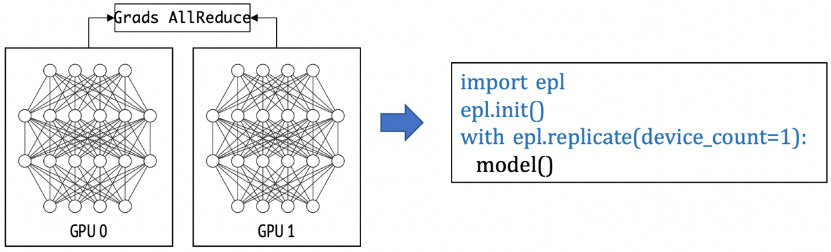
(1)數據并行: 下面這個例子是一個數據并行的例子,每個模型副本用一張卡來計算。如果用戶申請了8張卡,就是一個并行度為8的數據并行任務。
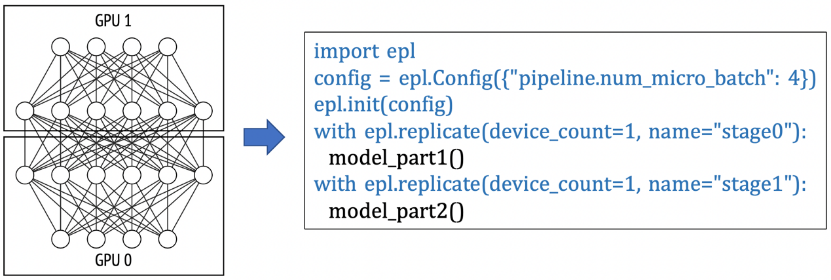
(2) 流水并行:在下面的例子里,模型被切分成2個 TaskGraph, "stage0"和"stage1",用戶可以通過配置pipeline.num_micro_batch參數來設定pipeline的micro batch數量。在這個例子里,"stage_0"和"stage_1"組成一個模型副本,共需要2張GPU卡。如果用戶申請了8張卡,EPL會自動在pipeline外嵌套一層并行度為4的數據并行(4個pipeline副本并行執行)。
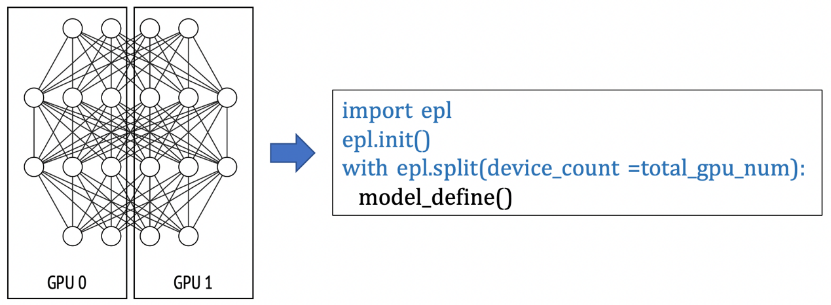
(3) 算子拆分并行:在以下例子中,EPL會對split scope下的模型定義做拆分,并放置在不同的GPU卡上做并行計算。
(4)同時,EPL支持對上述并行策略進行組合和嵌套,組成各種混合并行策略,更多示例可以參考開源代碼的文檔和示例。
3.顯存優化
當模型增長,GPU的顯存常常成為訓練大模型的瓶頸。EPL提供了多維度的顯存優化技術,極大優化了訓練顯存消化。
- 重算 Recomputation (Gradient Checkpoint):正常的DNN前向過程中會生成activation,這部分activation會在后向過程中用于梯度計算。因此,在梯度生成之前,前向的activation會一直存留在顯存中。activation大小和模型結構以及batch size相關,通常占比都非常高。Gradient Checkpoint (GC) 通過保留前向傳播過程中的部分activation,在反向傳播中重算被釋放的activation,用時間換空間。GC中比較重要的一部分是如何選擇合適的checkpoint點,在節省顯存、保證性能的同時,又不影響收斂性。EPL提供了自動GC功能,用戶可以一鍵開啟GC優化功能。
- ZeRO:在數據并行的場景下,每個卡上會存放一個模型副本,optimizer state等,這些信息在每張卡上都是一樣,存在很大的冗余量。當模型變大,很容易超出單卡的顯存限制。在分布式場景下,可以通過類似DeepSpeed ZeRO的思路,將optimizer state和gradient分片存在不同的卡上,從而減少單卡的persistent memory占用。
- 顯存優化的AMP(Auto Mixed Precision):在常規的AMP里,需要維護一個FP16的weight buffer,對于參數量比較大的模型,也是不小的開銷。EPL提供了一個顯存優化的AMP版本,FP16只有在用的時候才cast,從而節約顯存。
- Offload: Offload將訓練的存儲空間從顯存擴展到內存甚至磁盤,可以用有限的資源訓練大模型。
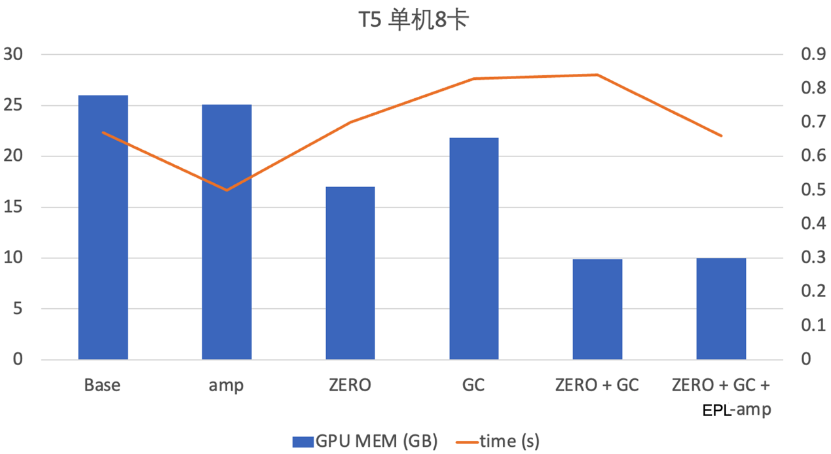
同時,EPL支持各種顯存優化技術的組合使用,達到顯存的極致優化。阿里云機器學習PAI團隊在T5模型上開啟了GC+ZeRO+顯存優化的AMP技術,在性能保持不變的情況下,顯存降低2.6倍。
四、應用場景
EPL適合不同場景的模型,在阿里巴巴內部已經支持圖像、推薦、語音、視頻、自然語言、多模態等業務場景。同時,EPL也支持不同規模的模型,最大完成了10萬億規模的M6模型訓練,下面以M6和Bert模型為例進行介紹。
1.萬億/10萬億 M6模型預訓練
訓練一個萬億/10萬億參數模型,算力需求非常大。為了降低算力需求,EPL中實現了MoE(Mixture-of-Experts)結構,MoE的主要特點是稀疏激活,使用Gating(Router)來為輸入選擇Top-k的expert進行計算(k常用取值1、2),從而大大減少算力需求。
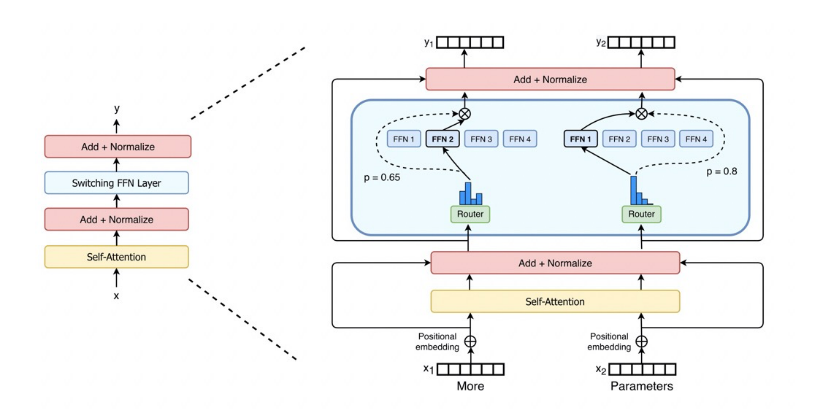
EPL支持專家并行(Expert Parallelism, EP),將experts拆分到多個devices上,降低單個device的顯存和算力需求。同時,數據并行有利于提升訓練的并發度,因此,采用數據并行+專家并行的混合并行策略來訓練M6模型:MoE layer采用專家并行,其他layer采用數據并行。
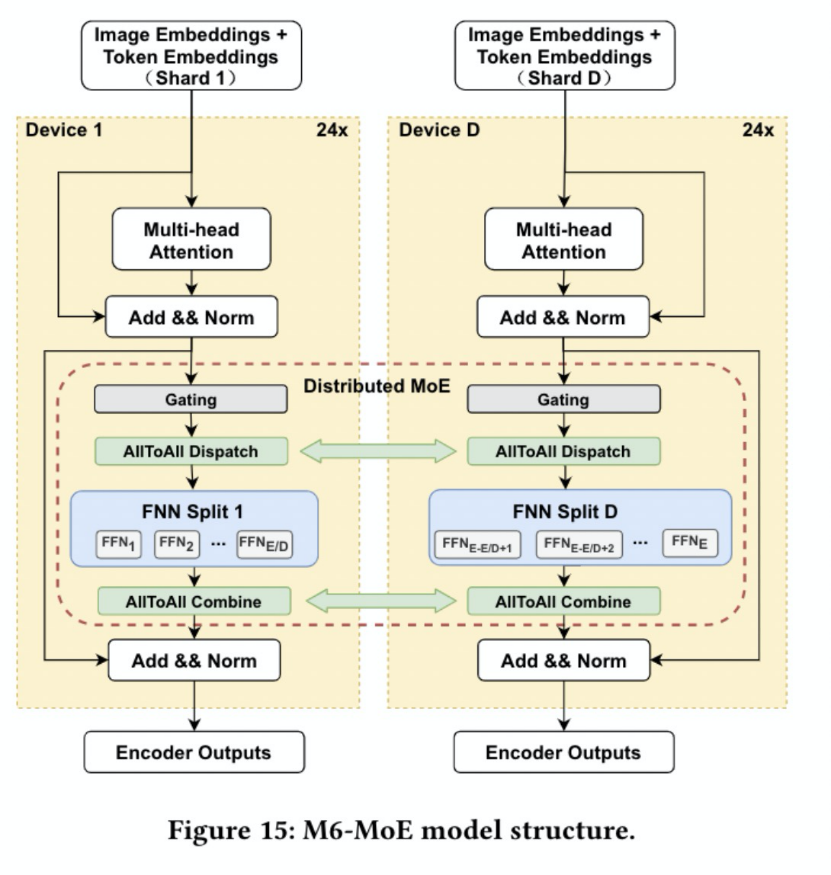
EPL中提供簡潔易用的接口來進行模型的混合并行訓練,只需要增加幾行annotation(注釋)來配置并行策略,不需要對模型本身做任何修改。例如,M6模型采用數據并行+專家并行的策略,只需要增加如下圖的annotation:

同時,為了節約訓練資源、提高訓練效率,我們采用了EPL的顯存優化技術和計算通信加速技術,包含自動 Gradient Checkpointing節省activation顯存占用,CPU Offload技術用于優化optimizer states和weight的顯存占用,采用DP+EP混合并行策略降低算力需求,結合混合精度、編譯優化等技術提高訓練效率等。 借助EPL框架,首次在480 V100 上,3天內完成萬億M6模型的預訓練。相比此前業界訓練同等規模的模型,此次僅使用480張V100 32G GPU就成功訓練出萬億模型M6,節省算力資源超80%,且訓練效率提升近11倍。進一步使用512 GPU在10天內即訓練出具有可用水平的10萬億模型。
2.流水并行加速Bert Large模型訓練
對于Bert Large模型,結構圖如下圖所示:
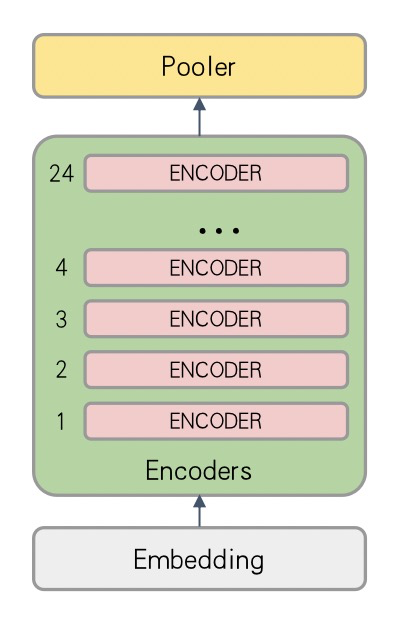
由于Bert Large模型對顯存消耗較大,Nvidia V100 16G顯卡上batch size常常只有2-8左右(具體值和Embedding大小、Sequence Length等有關)。Batch size太小會導致算法收斂波動大、收斂效果差的問題。同時,通過數據并行模式訓練,通信占比較高,分布式加速效果不理想。
分析Bert Large模型,由24層重復結構的encoder組成,可以使用流水并行進行加速。這里,我們將Bert Large中的Encoder Layer 1~8層、Encoder Layer 9~16層,Encoder Layer 17~24層分別放在不同的卡上進行訓練,并行化后的計算圖如下圖所示:
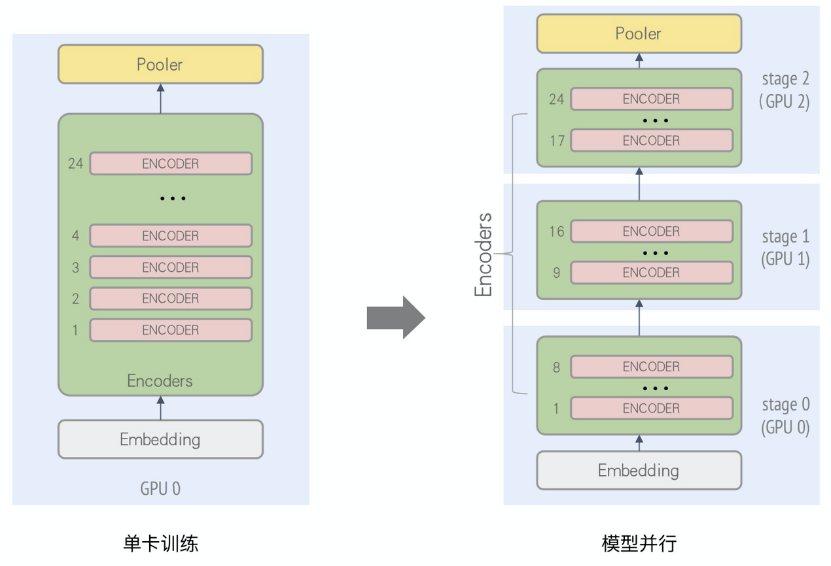
如此,每張卡訓練時的顯存開銷會減少,從而可以增大batch size以提升收斂加速。另外,針對因模型過大、單卡顯存無法放下所導致的無法訓練的場景,通過Layer間拆分的模型并行方式來進行分布式訓練。通過epl.replicate接口可以實現模型的stage劃分,同時通過流水并行的執行調度來提升并行化性能,如下圖所示:

上述例子是一個流水micro batch mumber為5的情況。通過流水并行優化后的時間軸可以看出,在同一個時間上,多張卡可以并行計算。當5個micro batch結束后,每張卡會將梯度進行本地的累計之后再進行update。與單純的模型并行相比,通過流水的交替執行,提高了GPU的利用率。EPL還通過采用Backward-Preferred調度優化策略來提升流水并行性能,降低GPU空閑時間和顯存開銷。

為能夠獲得更高的水平擴展,EPL還支持在流水并行外嵌套數據并行來提升訓練吞吐。EPL會自動推導嵌套的數據并行的并行度。最新測試結果顯示,在32卡GPU規模下,使用EPL的流水+數據并行對Bert Large模型進行優化,相比于數據并行,訓練速度提升了66%。
五、Roadmap
我們決定建設開源生態主要有如下的考慮:
- EPL發源于阿里云內部的業務需求,很好地支持了大規模、多樣性的業務場景,在服務內部業務的過程中也積累了大量的經驗,在EPL自身隨著業務需求的迭代逐漸完善的同時,我們也希望能夠開源給社區,將自身積累的經驗和理解回饋給社區,希望和深度學習訓練框架的開發者或深度學習從業者之間有更多更好的交流和共建,為這個行業貢獻我們的技術力量。
- 我們希望能夠借助開源的工作,收到更多真實業務場景下的用戶反饋,以幫助我們持續完善和迭代,并為后續的工作投入方向提供輸入。
- 同時,我們希望借助開源的工作,能吸引一些志同道合的同學、公司或組織來參與共建,持續完善深度學習生態。
后續,我們計劃以兩個月為單位發布Release版本。EPL近期的Roadmap如下:
- 持續的性能優化和穩定性改進;
- 通用算子拆分功能;
- 自動拆分策略探索的基礎版;
- 自動流水并行策略探索;
此外,在中長期,我們將在軟硬件一體優化、全自動策略探索等幾個探索性的方向上持續投入精力,也歡迎各種維度的反饋和改進建議以及技術討論,同時我們十分歡迎和期待對開源社區建設感興趣的同行一起參與共建。
- 全自動的模型并行策略探索;
- 高效的策略探索算法和精準的CostModel評估;
- eager model下的并行策略探索;
- 更多新硬件的支持、適配和協同優化;
- 高效的算子優化和集成、極致的顯存優化、軟硬一體的通信優化;
EPL(Easy Parallel Library)的開源地址:https://github.com/alibaba/EasyParallelLibrary
我們同時提供了model zoo,歡迎大家試用:https://github.com/alibaba/FastNN