我們研究了特斯拉、毫末智行「自動駕駛算法」的秘密
目前,自動駕駛技術已經(jīng)走出實驗室,進入量產(chǎn)落地的階段,也成為了各大車企,零部件供應商,高科技公司爭相進入的領域,競爭空前激烈。
自動駕駛駕駛技術這一輪的爆發(fā),很大程度上取決于兩點:
- 大算力計算平臺在消費端取得的突破,為人工智能領域提供了基礎算力。
- 深度學習在計算機視覺領域取得的突破,這也是自動駕駛視覺感知的基礎。
目前,基于英偉達、高通、Mobileye、地平線、華為的自動駕駛芯片,做多芯片集成開發(fā)出來的計算平臺整體算力最高已經(jīng)達到上千 Tops,這為高階自動駕駛提供了算力保障。
但在算法和算力之間,技術既深度耦合又相互促進,安霸半導體中國區(qū)總經(jīng)理馮羽濤說過:
「自動駕駛所需要的算力不會無限擴展下去,算力要隨著算法和數(shù)據(jù)的能力增長而增長,以目前各家算法技術來說,市面上主流的大算力芯片已經(jīng)足夠,而算法才是接下來競爭的重點,除非算法和數(shù)據(jù)與算力之間的耦合達到一個瓶頸點,那再去做更大算力的平臺才有意義。」
在 1 月 27 日,中金發(fā)布了一份名為《人工智能十年展望(三):AI 視角下的自動駕駛行業(yè)全解析》的研究報告。報告指出,「深度學習是自動駕駛技術發(fā)展的分水嶺及底層推動力,算法是各廠商接下來應該重點布局的核心能力,同時,數(shù)據(jù)是決定自動駕駛量產(chǎn)能力的勝負手」。
也就是說,算力性能已經(jīng)到了階段性的平穩(wěn)發(fā)展期,「算法能力 + 數(shù)據(jù)能力」會成為自動駕駛領域里的各個公司之間競爭誰能勝出的關鍵。
01 多層神經(jīng)網(wǎng)絡的技術趨勢
視覺感知的技術突破,進一步推動了其他傳感器(比如激光雷達和毫米波雷達)的感知算法以及多傳感器融合算法的進步。另一方面,深度學習中的強化學習算法也在決策系統(tǒng)中起到了非常重要的作用。
對于深度學習算法來說,除了算法本身的能力以外,高質(zhì)量,大規(guī)模的訓練數(shù)據(jù)也是算法取得成功的關鍵因素。因此,如何高效地采集和標注數(shù)據(jù)對于每一家自動駕駛公司來說都是非常現(xiàn)實的課題。
在數(shù)據(jù)采集方面,面向量產(chǎn)的公司有著先天的優(yōu)勢。路面上行駛的數(shù)十萬,甚至上百萬的車輛,每一輛都可以源源不斷地提供豐富的路況數(shù)據(jù),加在一起就是一個海量的自動駕駛數(shù)據(jù)庫。
相比之下,面向 L4 級別的公司只能依靠有限的測試車輛來采集數(shù)據(jù)。目前路測規(guī)模最大的 Waymo 也只有幾百輛測試車,數(shù)據(jù)采集的規(guī)模自然不可同日而語。
有了海量數(shù)據(jù)是不是問題就解決了呢?
顯然沒有那么簡單。
雖然說深度神經(jīng)網(wǎng)絡依賴于大數(shù)據(jù),但是不同網(wǎng)絡結構學習海量數(shù)據(jù)的能力還是有很大差別的。最早出現(xiàn)的多層感知機結構網(wǎng)絡只有幾層,只需要很少的數(shù)據(jù)就可以使網(wǎng)絡的學習能力達到飽和。
近些年來提出的卷積神經(jīng)網(wǎng)絡(CNN),深度從十幾層增加到上百層,甚至上千層,這時就需要大規(guī)模的訓練數(shù)據(jù)來保證網(wǎng)絡訓練的質(zhì)量。
但是簡單的堆積層數(shù)也是行不通的,這時深度學習領域一個非常關鍵的技術 ResNet(深度殘差網(wǎng)絡)出現(xiàn)了,它提出通過增加額外的連接,使得信息可以從淺層直接傳輸?shù)缴顚樱瑴p少信息在網(wǎng)絡層之間傳輸時的損失。通過這個技術,卷積神經(jīng)網(wǎng)絡才能擁有更深的結構,從而更好地利用大規(guī)模數(shù)據(jù)。
雖然有了 ResNet 技術,深度卷積神經(jīng)網(wǎng)絡在數(shù)據(jù)規(guī)模增加到一定程度之后,其性能的提升也變得非常有限,也就是說存在飽和的趨勢,這說明神經(jīng)網(wǎng)絡的學習能力還是存在著一定的瓶頸。
大約從 2017 年開始,一種新型的神經(jīng)網(wǎng)絡結構開始引起研究人員的廣泛關注,那就是大名鼎鼎的基于注意力機制的 Transformer 網(wǎng)絡。
Transformer 首先被應用在自然語言處理領域(NLP),用來處理序列文本數(shù)據(jù)。
谷歌團隊提出的用于生成詞向量的 BERT 算法在 NLP 的 11 項任務中均取得了大幅的效果提升,而 BERT 算法中最重要的部分便是 Transformer。
在自然語言處理領域取得廣泛應用后,Transformer 也被成功移植到了很多視覺任務上,比如「圖像分類,物體檢測」等,并同樣取得了不錯的效果。Transformer 在海量數(shù)據(jù)上可以獲得更大的性能提升,也就是說學習能力的飽和區(qū)間更大。
有研究表明,當訓練數(shù)據(jù)集增大到包含 1 億張圖像時,Transformer 的性能開始超過 CNN。而當圖像數(shù)量增加到 10 億張時,兩者的性能差距變得更大。
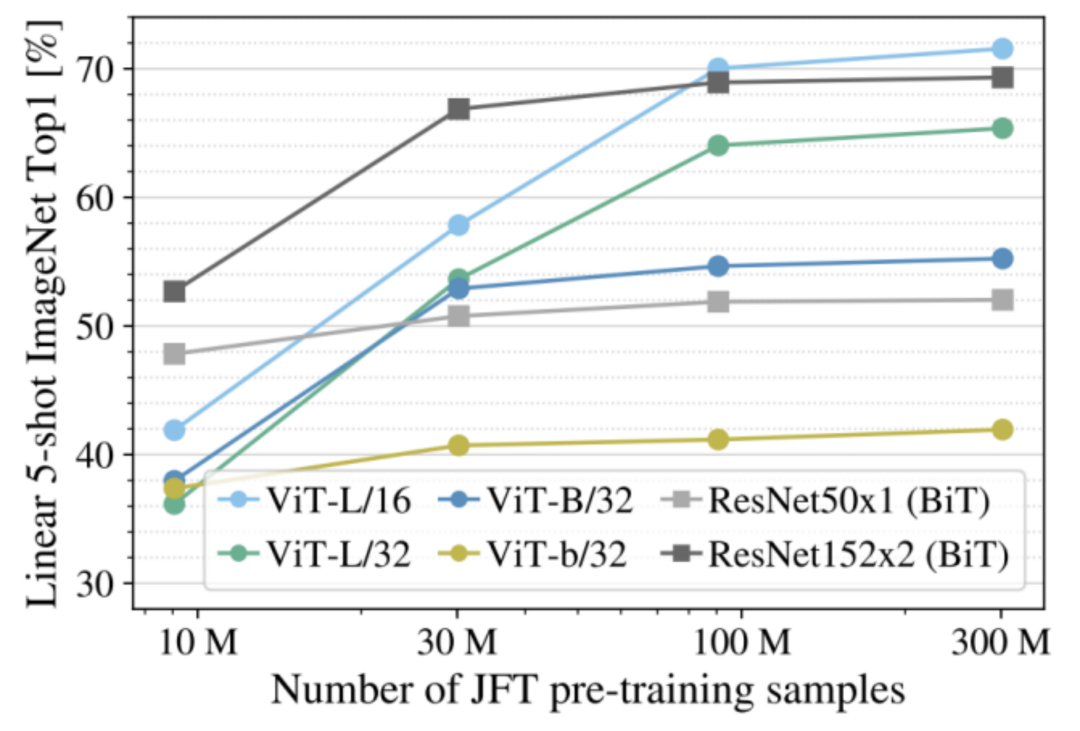
上面是 ResNet(CNN)和 ViT(Transformer)在不同大小訓練集上達到的圖像分類正確率。數(shù)據(jù)量為 1000 萬時,Transformer 的正確率遠低于 CNN,但是當數(shù)據(jù)量增加到 1 億時,Transformer 就開始超過 CNN。
此外,CNN 網(wǎng)絡在數(shù)據(jù)量超過 1 億以后呈現(xiàn)飽和趨勢,而 Transformer 的準確率還在繼續(xù)增加。
簡單理解就是,Transformer 在海量數(shù)據(jù)的處理能力上具有巨大冗余優(yōu)勢。
正是因為看到了這一點,面向量產(chǎn)的自動駕駛公司在擁有數(shù)據(jù)收集優(yōu)勢的情況下,自然就會傾向于選擇 Transformer 作為其感知算法的主體。
2021 年夏天,特斯拉的自動駕駛技術負責人 Andrej Karpathy 博士在 AI Day 上,公開了 FSD 自動駕駛系統(tǒng)中采用的算法,而 Transformer 則是其中最核心的模塊之一。在國內(nèi)方面,毫末智行也同樣提出將 Transformer 神經(jīng)網(wǎng)絡與海量數(shù)據(jù)進行有效的融合。
在 2021 年底,毫末智行 CEO 顧維灝在毫末 AI Day 上介紹了 MANA(雪湖)數(shù)據(jù)智能體系。除了視覺數(shù)據(jù)以外,MANA 系統(tǒng)還包含了激光雷達數(shù)據(jù)。
并基于 Transformer 神經(jīng)網(wǎng)絡模型來進行空間、時間、傳感器三個維度的融合,從而去提升感知算法的準確率。
了解了目前自動駕駛技術發(fā)展的趨勢以后,文章接下來的部分會首先簡單介紹一下 Transformer 的設計動機和工作機制,然后詳細解讀特斯拉和毫末智行的技術方案。
02 Transformer 神經(jīng)網(wǎng)絡
在說 Transformer 之前,要先理解一個概念:「機器翻譯、注意力機制」。
機器翻譯
機器翻譯可以粗暴理解成 「由現(xiàn)代化計算機模擬人類的智能活動,自動進行語言之間的翻譯」。
說起翻譯,不得不提自然語言處理(NLP)領域的機器翻譯應用,簡單說就是「輸入一句話,輸出另一句話」,后者可以是前者的其他語種表達,如「自行車翻譯為 Bicycle」;也可以是前者的同語種關鍵詞表達,如「騎行的兩輪車」。
而工程師把「翻譯」的過程,用數(shù)學函數(shù)設計了一套模型,這個模型就是大家通常意義上理解的「神經(jīng)網(wǎng)絡」。
在 Transformer 到來之前,大家一般都是使用基于循環(huán)神經(jīng)網(wǎng)絡 RNN 的「編碼器-解碼器」結構來完成序列翻譯。
所謂序列翻譯,「就是輸入一個序列,輸出另一個序列」。例如,漢英翻譯即輸入的序列是漢語表示的一句話,而輸出的序列即為對應的英語表達。
基于 RNN 的架構有一個明顯弊端就是,RNN 屬于序列模型,需要以一個接一個的序列化方式進行信息處理,注意力權重需要等待序列全部輸入模型之后才能確定,簡單理解就是,需要 RNN 對序列「從頭看到尾」。
例如:
面對翻譯問題「A magazine is stuck in the gun」,其中的「Magazine」到底應該翻譯為「雜志」還是「彈匣」?
當看到「gun」一詞時,將「Magazine」翻譯為「彈匣」才確認無疑。在基于RNN的機器翻譯模型中,需要一步步的順序處理從 Magazine 到 gun 的所有詞語,而當它們相距較遠時 RNN 中存儲的信息將不斷被稀釋,翻譯效果常常難以盡人意,而且效率非常很低。
這種架構無論是在訓練環(huán)節(jié)還是推理環(huán)節(jié),都具有大量的時間開銷,并且難以實現(xiàn)并行處理。而這個時候,工程師又想到了一個方案,就是在標準的 RNN 模型中加入一個「注意力機制」。
什么是注意力機制?
「深度學習中的注意力機制,源自于人腦的注意力機制,當人的大腦接受外部信息時,如視覺信息,聽覺信息時,往往不會對全部信息處理和理解,而只會將注意力集中在部分顯著或者感興趣的信息上,這樣有利于濾除不重要的信息,而提升的信息處理效率。」
加入注意力機制的模型會一次性的「看見」所有輸入的詞匯,利用注意力機制將距離不同的單詞進行結合,為序列中每個元素提供全局的上下文。
谷歌團隊賦予新模型一個大名鼎鼎的名字:「Transformer」。
Transformer 與處理序列數(shù)據(jù)常用的循環(huán)神經(jīng)網(wǎng)絡(RNN)不同,Transformer 中的注意力機制并不會按照順序來處理數(shù)據(jù),也就是說,每個元素和序列中的所有元素都會產(chǎn)生聯(lián)系,這樣就保證了不管在時序上相距多遠,元素之間的相關性都可以被很好地保留。
而這種長時相關性對于自然語言處理的任務來說通常都是非常重要。比如下圖中,句子中的「it」所指的是「The animal」,但是這兩個元素之間相距較遠,如果用 RNN 來順序處理的話很難建立起兩者之間的聯(lián)系。
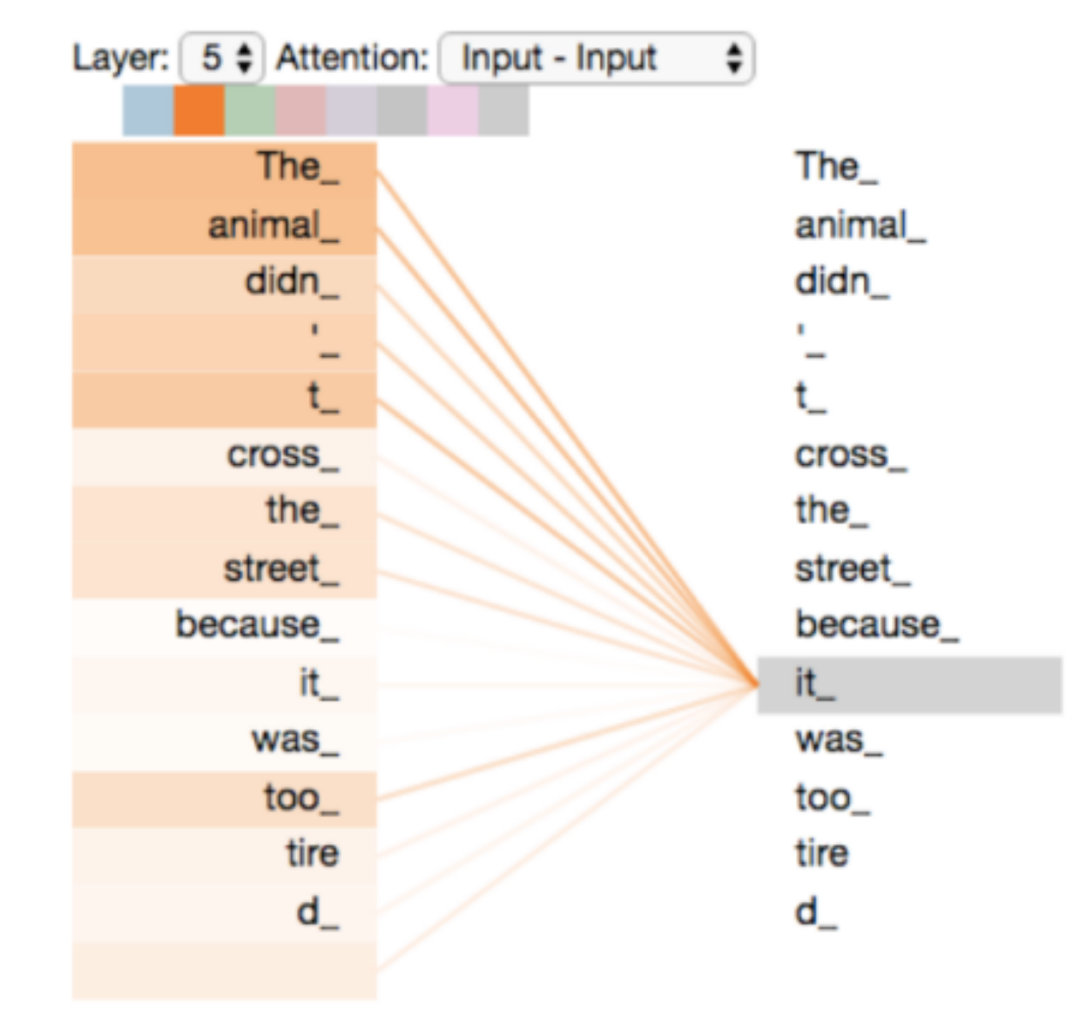
一個句子中各個單詞之間的相關性
Transformer 并不關心順序,在計算相關性時,每個元素的重要性是根據(jù)數(shù)據(jù)本身的語義信息計算出來的。因此,可以輕松地提取任意距離元素之間的相關性。
為什么要說這些?
因為在視覺任務圖像分類和物體檢測上,通過帶有注意力機制的 Transformer 模型其結果出乎意料的好。
為什么源自自然語言領域的算法,在視覺上同樣適用呢?
原因主要有兩點:
- 雖然圖像本身不是時間序列數(shù)據(jù),但可以看作空間上的序列,視覺任務一個關鍵的步驟就是要提取像素之間的相關性,普通的 CNN 是通過卷積核來提取局部的相關性(也稱為:局部感受野)。與 CNN 的局部感受野不同,Transformer 可以提供全局的感受野。因此,特征學習能力相比 CNN 要高很多。
- 如果進一步考慮視頻輸入數(shù)據(jù)的話,那么這本身就是時序數(shù)據(jù),因此,更加適合Transformer 的處理。
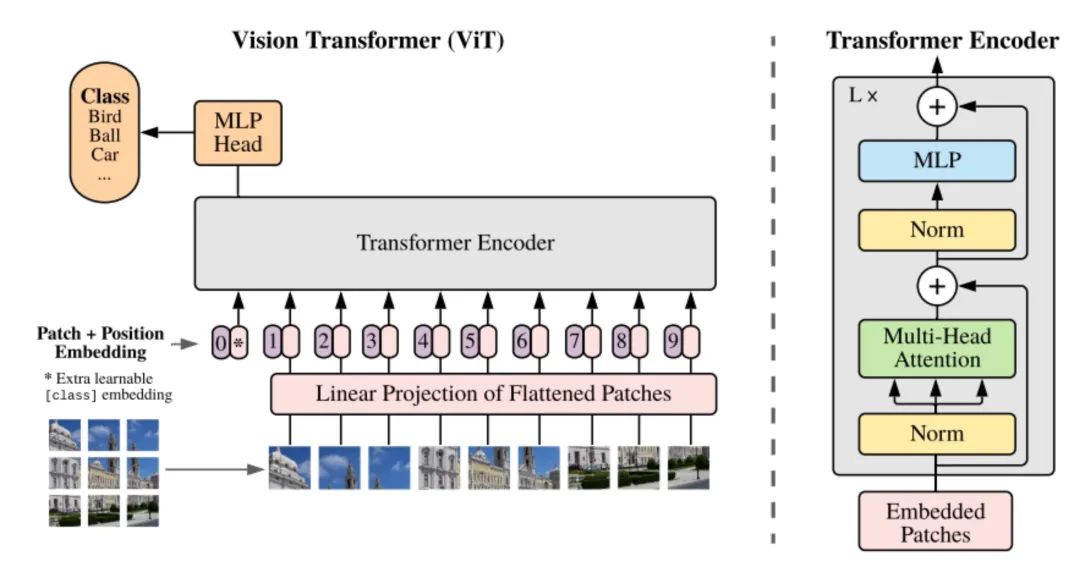 Transformer 在圖像分類中的應用
Transformer 在圖像分類中的應用
在圖 3 的例子中,Transformer 被用來進行圖像分類的任務。圖像被均勻地分成若干小塊,按照空間排列的順序組成了一個圖像塊的序列。每個圖像塊的像素值(或者其他特征)組成了該圖像塊的特征向量,經(jīng)過 Transformer 編碼在進行拼接后就得到整幅圖像的特征。
上圖的右側,給出了編碼器的具體結構,其關鍵部分是一個 「多頭注意力模塊」。
簡單來說,多頭注意力其實就是多個注意力機制模塊的集成,這些模塊各自獨立的進行編碼,提取不同方面的特征,在增加編碼能力的同時,也可以非常高效的在計算芯片上實現(xiàn)并行處理。
綜上所述,這也就是中金《人工智能十年展望(三):AI 視角下的自動駕駛行業(yè)全解析》這份報告里說的:
由于 Transformer 可以很好地在 「空間-時序」 維度上進行建模,目前特斯拉和毫末智行等行業(yè)龍頭通過 Transformer 在感知端提升模型效果。
特斯拉從安裝在汽車周圍的八個攝像頭的視頻中用傳統(tǒng)的 ResNet 提取圖像特征,并使用 Transformer CNN、3D 卷積中的一種或者多種組合完成跨時間的圖像融合,實現(xiàn)基于 2D 圖像形成具有 3D 信息輸出。
毫末智行的 AI 團隊正在逐步將基于 Transformer 的感知算法應用到實際的道路感知問題,如車道線檢測、障礙物檢測、可行駛區(qū)域分割、紅綠燈檢測&識別、道路交通標志檢測、點云檢測&分割等。
03 特斯拉的 FSD 系統(tǒng)解讀
Andrej 博士在特斯拉 AI Day 上首先提到,五年前 Tesla 的視覺系統(tǒng)是先獲得單張圖像上的檢測結果,然后將其映射到向量空間(Vector Space)。
這個「向量空間」則是 AI Day 中的核心概念之一。其實,它就是環(huán)境中的各種目標,在世界坐標系中的表示空間。
比如,「對于物體檢測任務,目標在 3D 空間中的位置、大小、朝向、速度等描述特性組成了一個向量,所有目標的描述向量組成的空間就是向量空間。」
視覺感知系統(tǒng)的任務就是,將圖像空間中的信息轉化為向量空間中的信息。
一般可以通過兩種方法來實現(xiàn):
- 先在圖像空間中完成所有的感知任務,然后將結果映射到向量空間,最后融合多攝像頭的結果;
- 先將圖像特征轉換到向量空間,然后融合來自多個攝像頭的特征,最后在向量空間中完成所有的感知任務。
Andrej 舉了兩個例子,說明為什么第一種方法是不合適的。
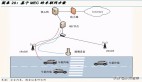
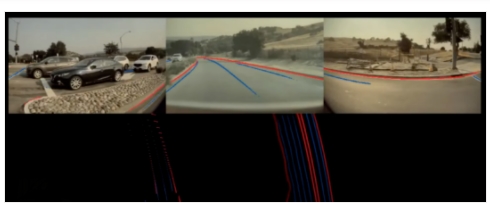
一,由于透視投影,圖像中看起來不錯的感知結果在向量空間中精度很差,尤其是遠距離的區(qū)域。如下圖所示,車道線(藍色)和道路邊緣(紅色)在投影到向量空間后位置非常不準,無法用支持自動駕駛的應用。

圖像空間的感知結果(上)及其在向量空間中的投影(下)
二,在多目系統(tǒng)中,由于視野的限制,單個攝像頭可能無法看到完整的目標。比如,在下圖的例子中,一輛大貨車出現(xiàn)在了一些攝像頭的視野中,但是很多攝像頭都只看到了目標的一部分,因此無法根據(jù)殘缺的信息做出正確的檢測,后續(xù)的融合效果也就無法保證。這其實是多傳感器決策層融合的一個一般性問題。

單攝像頭受限的視野
綜合以上分析,圖像空間感知 + 決策層融合并不是一個很好的方案。
進而直接在向量空間中完成融合和感知可以有效地解決以上問題,這也是 FSD 感知系統(tǒng)的核心思路。
為了實現(xiàn)這個思路,需要解決兩個重要的問題:一,如何將特征從圖像空間變換到向量空間;二,如何得到向量空間中的標注數(shù)據(jù)。
特征的空間變換
對于特征的空間變換問題,一般性的做法就是:「利用攝像頭的標定信息將圖像像素映射到世界坐標系」。
但這有一些條件上的問題,需要有一定的約束,自動駕駛應用中通常采用的是地平面約束,也就是目標位于地面,而且地面是水平的,這個約束太強了,在很多場景下無法滿足。
Tesla 的解決方案,核心有三點:
一,通過 Transformer 和自注意力的方式建立圖像空間到向量空間的對應關系。簡單說就是,向量空間中每一個位置的特征都可以看作圖像所有位置特征的加權組合。
當然對應位置的權重肯定大一些,但這個加權組合的過程通過自注意力和空間編碼來自動的實現(xiàn),不需要手工設計,完全根據(jù)需要完成的任務來進行端對端的學習。
二,在量產(chǎn)車中,每一輛車上攝像頭的標定信息都不盡相同,導致輸入數(shù)據(jù)與預訓練的模型不一致。因此,這些標定信息需要作為額外的輸入提供給神經(jīng)網(wǎng)絡。
簡單的做法是,將每個攝像頭的標定信息拼接起來,通過神經(jīng)網(wǎng)絡編碼后再輸入給神經(jīng)網(wǎng)絡;但更好的做法是將來自不同攝像頭的圖像通過標定信息進行校正,使不同車輛上對應的攝像頭都輸出一致的圖像。
三,視頻(多幀)輸入被用來提取時序信息,以增加輸出結果的穩(wěn)定性,更好地處理遮擋場景,并且預測目標的運動。
這部分還有一個額外的輸入就是車輛自身的運動信息(可以通過 IMU 獲得),以支持神經(jīng)網(wǎng)絡對齊不同時間點的特征圖,時序信息的處理可以采用 3D 卷積,Transformer 或者 RNN。
圖像空間感知(左下) vs. 向量空間感知(右下)
通過以上這些算法上的改進,F(xiàn)SD 在向量空間中的輸出質(zhì)量有了很大的提升。在下面的對比圖中,下方左側是來自圖像空間感知+決策層融合方案的輸出,而下方右側上述特征空間變換 + 向量空間感知融合的方案。
向量空間中的標注
既然是深度學習算法,那么數(shù)據(jù)和標注自然就是關鍵環(huán)節(jié),圖像空間中的標注非常直觀,但是系統(tǒng)最終需要的是在向量空間中的標注。
Tesla 的做法是利用來自多個攝像頭的圖像重建 3D 場景,并在 3D 場景下進行標注,標注者只需要在 3D 場景中進行一次標注,就可以實時地看到標注結果在各個圖像中的映射,從而進行相應的調(diào)整。
 3D 空間中的標注
3D 空間中的標注
人工標注只是整個標注系統(tǒng)的一部分,為了更快更好地獲得標注,還需要借助自動標注和模擬器。
自動標注系統(tǒng)首先基于單攝像頭的圖像生成標注結果,然后通過各種空間和時間的線索將這些結果整合起來。形象點說就是 「各個攝像頭湊在一起討論出一個一致的標注結果」。
除了多個攝像頭的配合,在路上行駛的多臺 Tesla 車輛也可以對同一個場景的標注進行融合改進。當然這里還需要 GPS 和 IMU 傳感器來獲得車輛的位置和姿態(tài),從而將不同車輛的輸出結果進行空間對齊。
自動標注可以解決標注的效率問題,但是對于一些罕見的場景,比如,中金《人工智能十年展望(三):AI 視角下的自動駕駛行業(yè)全解析》報告中所演示的在高速公路上奔跑的行人,還需要借助模擬器來生成虛擬數(shù)據(jù)。
以上所有這些技術組合起來,才構成了 Tesla 完整的深度學習網(wǎng)絡、數(shù)據(jù)收集和標注系統(tǒng)。
04 毫末智行的 MANA 系統(tǒng)解讀

依托長城汽車,毫末智行可以獲得海量的真實路測數(shù)據(jù),對于數(shù)據(jù)的處理問題,毫末智行也提出將 Transformer 引入到其數(shù)據(jù)智能體系 MANA 中,并逐步應用到實際的道路感知問題,比如障礙物檢測、車道線檢測、可行駛區(qū)域分割、交通標志檢測等等。
從這一點上就可以看出,量產(chǎn)車企在有了超大數(shù)據(jù)集作為支撐以后,其技術路線正在走向趨同。
在自動駕駛技術百花齊放的時代,選擇一條正確的賽道,確立自身技術的優(yōu)勢,無論對于特斯拉還是毫末智行來說,都是極其重要的。
在自動駕駛技術的發(fā)展中,一直就對采用何種傳感器存在爭論。目前爭論的焦點在于是走純視覺路線還是激光雷達路線。
特斯拉采用純視覺方案,這也是基于其百萬量級的車隊和百億公里級別的真實路況數(shù)據(jù)做出的選擇。
而采用激光雷達,主要有兩方面的考慮:
- 數(shù)據(jù)規(guī)模方面的差距其他自動駕駛公司很難填補,要獲得競爭優(yōu)勢就必須增加傳感器的感知能力。目前,半固態(tài)的激光雷達成本已經(jīng)降低到幾百美元的級別,基本可以滿足量產(chǎn)車型的需求。
- 從目前的技術發(fā)展來看,基于純視覺的技術可以滿足 L2/L2+ 級別的應用,但是對L3/4級的應用(比如RoboTaxi)來說,激光雷達還是必不可少的。
在這種背景下,誰能夠既擁有海量數(shù)據(jù),又能同時支持視覺和激光雷達兩種傳感器,那么無疑會在競爭中占據(jù)先發(fā)的優(yōu)勢。顯然,毫末智行在這個方向上已經(jīng)占據(jù)了先機。
根據(jù)毫末智行 CEO 顧維灝的在 AI Day 上的介紹,MANA 系統(tǒng)采用 Transformer 在底層融合視覺和激光雷達數(shù)據(jù),進而實現(xiàn)空間、時間、傳感器三位一體的深層次感知。
下面我就來詳細解讀一下 MANA 系統(tǒng),尤其是與特斯拉 FSD 的差異之處。
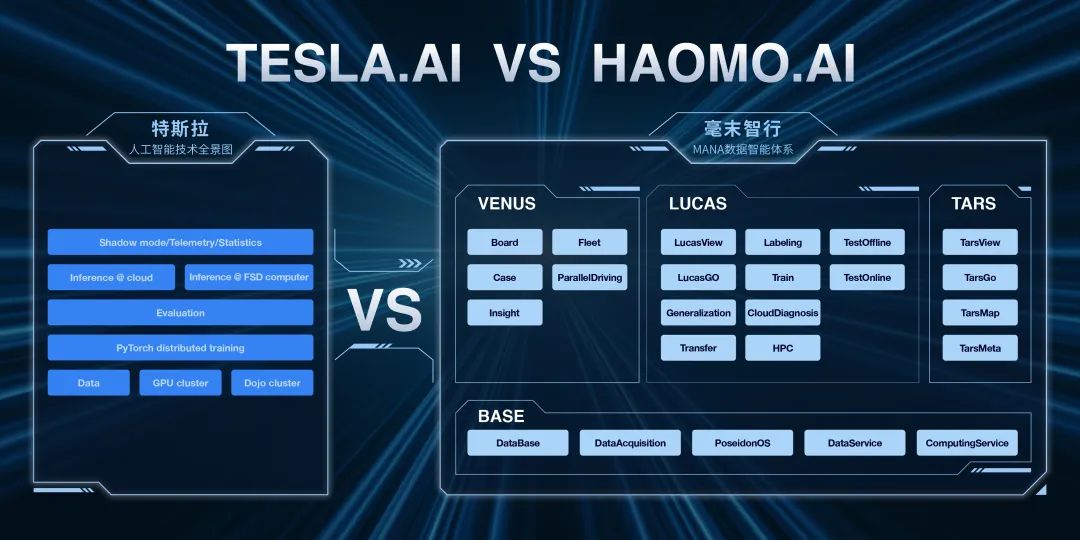
視覺感知模塊
相機獲取原始數(shù)據(jù)之后,要經(jīng)過 ISP(Image Signal Process)數(shù)字處理過程后,才能提供給后端的神經(jīng)網(wǎng)絡使用。
ISP 的功能一般來說是為了獲得更好的視覺效果,但是神經(jīng)網(wǎng)絡其實并不需要真正的「看到」數(shù)據(jù),視覺效果只是為人類設計的。
因此,將 ISP 作為神經(jīng)網(wǎng)絡的一層,讓神經(jīng)網(wǎng)絡根據(jù)后端的任務來決定 ISP 的參數(shù)并對相機進行校準,這有利于最大程度上保留原始的圖像信息,也保證采集到的圖像與神經(jīng)網(wǎng)絡的訓練圖像在參數(shù)上盡可能的一致。
處理過后的圖像數(shù)據(jù)被送入主干網(wǎng)絡 Backbone,毫末采用的 DarkNet 類似于多層的卷積殘差網(wǎng)絡(ResNet),這也是業(yè)界最常用的主干網(wǎng)絡結構。
主干網(wǎng)絡輸出的特征再送到不同的頭(Head)來完成不同的任務。
這里的任務分為三大類:全局任務(Global Task)、道路任務(Road Tasks)和目標任務(Object Tasks)。
不同的任務共用主干網(wǎng)絡的特征,每個任務自己擁有獨立的 Neck 網(wǎng)絡,用來提取針對不同任務的特征。這與特斯拉 HydraNet 的思路是基本一致的。
但是 MANA 感知系統(tǒng)的特點在于 「為全局任務設計了一個提取全局信息的 Neck 網(wǎng)絡」。
這一點其實是非常重要的,因為全局任務(比如可行駛道路的檢測)非常依賴于對場景的理解,而對場景的理解又依賴于全局信息的提取。
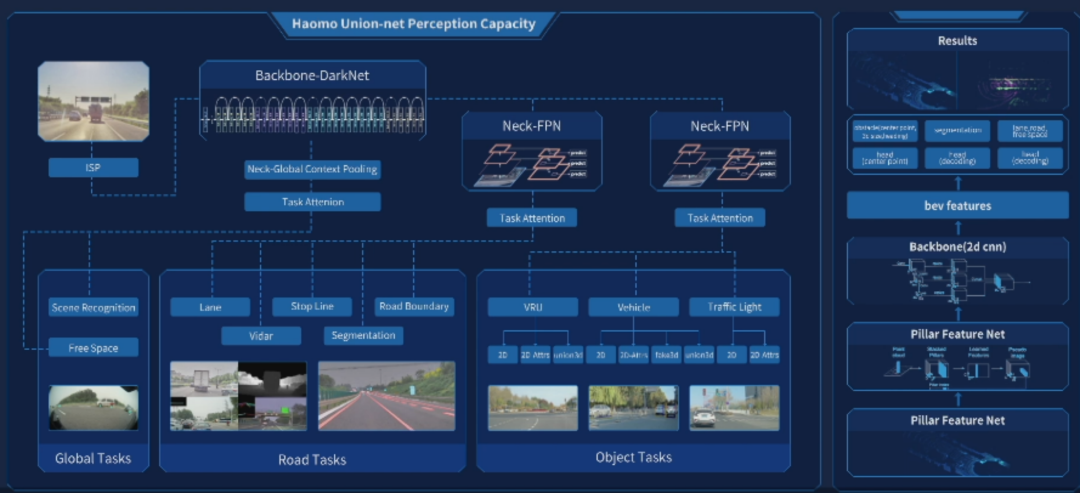 MANA 系統(tǒng)的視覺和激光雷達感知模塊
MANA 系統(tǒng)的視覺和激光雷達感知模塊
激光雷達感知模塊
激光雷達感知采用的是 PointPillar 算法,這也是業(yè)界常用的一個基于點云的三維物體檢測算法。這個算法的特點在于:「將三維信息投影到二維(俯視視圖),在二維數(shù)據(jù)上進行類似于視覺任務中的特征提取和物體檢測」。
這種做法的優(yōu)點在于避免了計算量非常大的三維卷積操作,因此,算法的整體速度非常快。PointPillar 也是在點云物體檢測領域第一個能夠達到實時處理要求的算法。
在 MANA 之前的版本中,視覺數(shù)據(jù)和激光雷達數(shù)據(jù)是分別處理的,融合過程在各自輸出結果的層面上完成,也就是自動駕駛領域常說的 「后融合」。
這樣做可以盡可能地保證兩個系統(tǒng)之間的獨立性,并為彼此提供安全冗余。但后融合也導致神經(jīng)網(wǎng)絡無法充分利用兩個異構傳感器之間數(shù)據(jù)的互補性,來學習最有價值的特征。
融合感知模塊
前面提到了一個三位一體融合的概念,這也是 MANA 感知系統(tǒng)區(qū)別于其他感知系統(tǒng)的關鍵之處。正如毫末智行 CEO 顧維灝在 AI Day 上所說:目前大部分的感知系統(tǒng)都存在「時間上的感知不連續(xù)、空間上的感知碎片化」的問題。
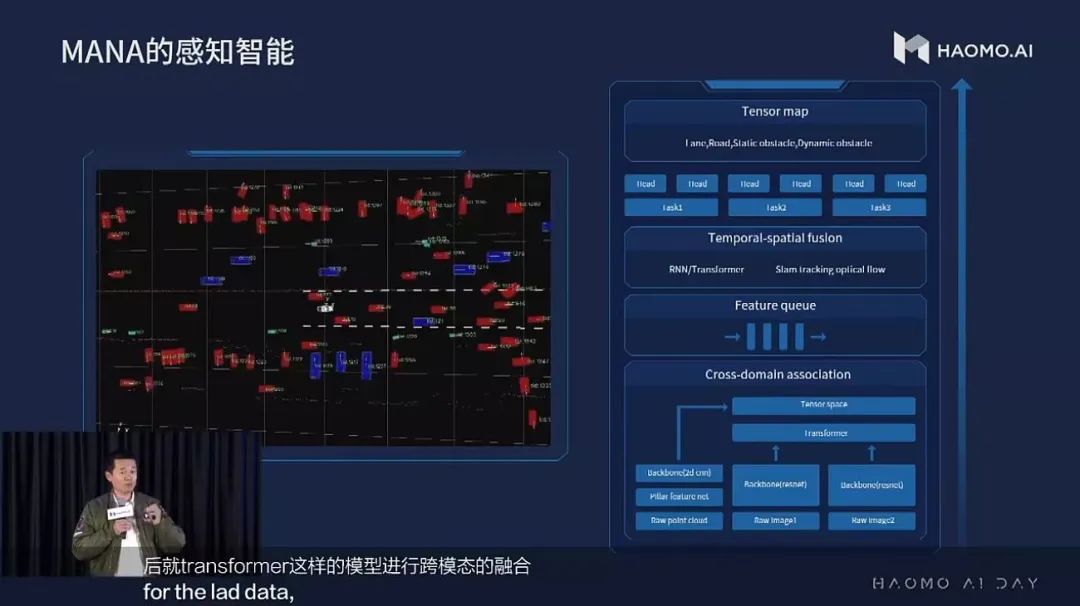 MANA 系統(tǒng)的融合感知模塊
MANA 系統(tǒng)的融合感知模塊
時間上的不連續(xù):是由于系統(tǒng)按照幀為單位進行處理,而兩幀之間的時間間隔可能會有幾十毫秒,系統(tǒng)更多地關注單幀的處理結果,將時間上的融合作為后處理的步驟。
比如,采用單獨的物體跟蹤模塊將單幀的物體檢測結果串聯(lián)起來,這也是一種后融合策略,因此無法充分利用時序上的有用信息。
空間上的碎片化:是由多個同構或異構傳感器所在的不同空間坐標系導致的。
對于同構傳感器(比如多個攝像頭)來說,由于安裝位置和角度不同,導致其可視范圍(FOV)也不盡相同。每個傳感器的 FOV 都是有限的,需要把多個傳感器的數(shù)據(jù)融合在一起,才可以得到車身周圍 360 度的感知能力,這對于 L2 以上級別的自動駕駛系統(tǒng)來說是非常重要的。
對于異構傳感器(比如攝像頭和激光雷達)來說,由于數(shù)據(jù)采集的方式不同,不同傳感器得到的數(shù)據(jù)信息和形式都有很大差別。
攝像頭采集到的是圖像數(shù)據(jù),具有豐富的紋理和語義信息,適合用于物體分類和場景理解;而激光雷達采集到的是點云數(shù)據(jù),其空間位置信息非常精確,適合用于感知物體的三維信息和檢測障礙物。
如果系統(tǒng)對每個傳感器進行單獨處理,并在處理結果上進行后融合,那么就無法利用多個傳感器的數(shù)據(jù)中包含的互補信息。
如何解決這兩個問題呢?
答案是:用 Transformer 做空間和時間上的前融合。
先說空間的前融合
與 Transformer 在一般的視覺任務(比如圖像分類和物體檢測)中扮演的角色不同,Transformer 在空間前融合中的主要作用并不是提取特征,而是進行坐標系的變換。
這與特斯拉所采用的技術有異曲同工之處,但是毫末進一步增加了激光雷達,進行多傳感器(跨模態(tài))的前融合,也就是圖 8 中的 Cross-Domain Association 模塊。
上面介紹了 Transformer 的基本工作原理,簡單來說就是 「計算輸入數(shù)據(jù)各個元素之間的相關性,利用該相關性進行特征提取」。
坐標系轉換也可以形式化為類似的流程。
比如,將來自多個攝像頭的圖像轉換到與激光雷達點云一致的三維空間坐標系,那么系統(tǒng)需要做的是找到三維坐標系中每個點與圖像像素的對應關系。傳統(tǒng)的基于幾何變換的方法會將三維坐標系中的一個點映射到圖像坐標系中的一個點,并利用該圖像點周圍一個小的鄰域(比如 3x3 像素)來計算三維點的像素值。
而 Transformer 則會建立三維點到每個圖像點的聯(lián)系,并通過自注意力機制,也就是相關性計算來決定哪些圖像點會被用來進行三維點的像素值。
如圖 9 所示,Transformer 首先編碼圖像特征,然后將其解碼到三維空間,而坐標系變換已經(jīng)被嵌入到了自注意力的計算過程中。
這種思路打破的傳統(tǒng)方法中對鄰域的約束,算法可以看到場景中更大的范圍,通過對場景的理解來進行坐標變換。同時,坐標變換的過程在神經(jīng)網(wǎng)絡中進行,可以由后端所接的具體任務來自動調(diào)整變換的參數(shù)。
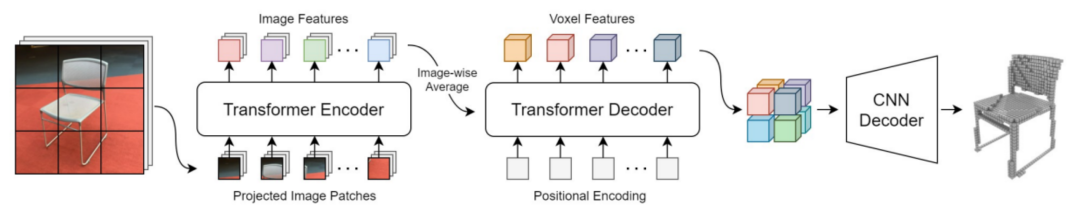
采用 Transformer 進行圖像坐標系到三維空間坐標系的轉換
因此,這個變換過程是完全由數(shù)據(jù)驅動的,也是任務相關的。在擁有超大數(shù)據(jù)集的前提下,基于 Transformer 來進行空間坐標系變換是完全可行的。
再說時間上的前融合
這個比空間上的前融合更容易理解一些,因為 Transformer 在設計之初就是為了處理時序數(shù)據(jù)的。
圖 8 中的 Feature Queue 就是空間融合模塊在時序上的輸出,可以理解為一個句子中的多個單詞,這樣就可以自然的采用 Transformer 來提取時序特征。相比特斯拉采用 RNN 來進行時序融合的方案,Transformer 的方案特征提取能力更強,但是在運行效率上會低一些。
毫末的方案中也提到了 RNN,相信目前也在進行兩種方案的對比,甚至是進行某種程度的結合,以充分利用兩者的優(yōu)勢。
除此之外,由于激光雷達的加持,毫末采用了 SLAM 跟蹤以及光流算法,可以快速的完成自身定位和場景感知,更好的保證時序上的連貫性。
認知模塊
除了感知模塊以外,毫末在認知模塊,也就是路徑規(guī)劃部分也有一些特別的設計。
顧維灝在 AI Day 上介紹到,認知模塊與感知模塊最大的不同在于,認知模塊沒有確定的「尺子」來衡量其性能的優(yōu)劣,而且認知模塊需要考慮的因素比較多,比如安全,舒適和高效,這無疑也增加了認知模塊設計的難度。
針對這些問題,毫末的解決方案是場景數(shù)字化和大規(guī)模強化學習。
場景數(shù)字化,就是將行駛道路上的不同場景進行參數(shù)化的表示。參數(shù)化的好處在于可以對場景進行有效地分類,從而進行差異化的處理。
按照不同的粒度,場景參數(shù)分為宏觀和微觀兩種:宏觀的場景參數(shù)包括天氣,光照,路況等;微觀的場景參數(shù)則刻畫了自車的行駛速度,與周圍障礙物的關系等。
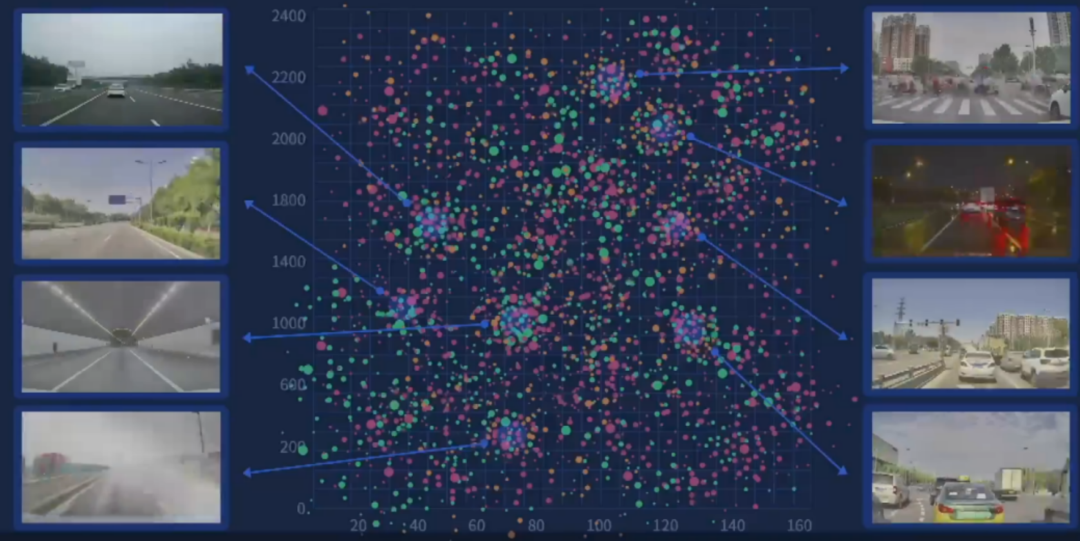 MANA 系統(tǒng)中的宏觀場景聚類
MANA 系統(tǒng)中的宏觀場景聚類
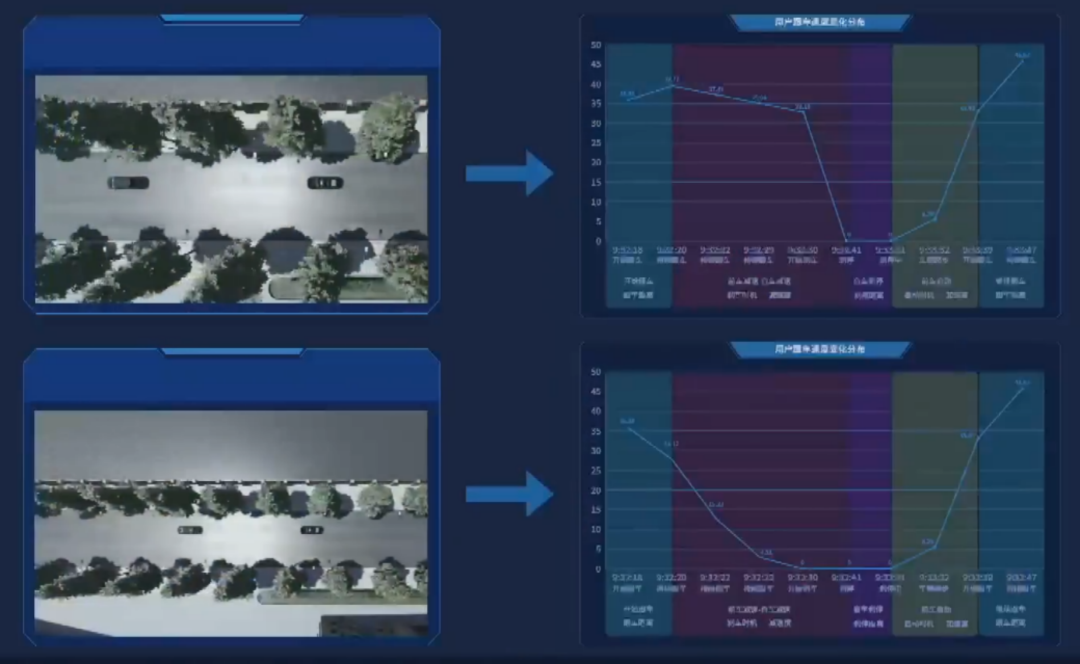 MANA 系統(tǒng)中的微觀場景(例子是跟車場景)
MANA 系統(tǒng)中的微觀場景(例子是跟車場景)
在將各種場景數(shù)字化了以后,就可以采用人工智能的算法來進行學習。一般情況下,強化學習是完成這個任務的一個比較好的選擇。
強化學習就是著名的 AlphaGo 中采用的方法,但是與圍棋不同,自動駕駛任務的評價標準不是輸和贏,而是駕駛的合理性和安全性。
如何對每一次的駕駛行為進行正確地評價,是認知系統(tǒng)中強化學習算法設計的關鍵。毫末采取的策略是模擬人類司機的行為,這也是最快速有效的方法。
當然,只有幾個司機的數(shù)據(jù)是遠遠不夠的,采用這種策略的基礎也是海量的人工駕駛數(shù)據(jù),而這恰恰又是毫末的優(yōu)勢所在,這就是基于長城汽車,毫末在智能駕駛系統(tǒng)上的交付能力會遠遠領先其他對手,而這背后的核心則是數(shù)據(jù)的收集能力,基于海量的數(shù)據(jù),毫末可以快速迭代算法交付覆蓋更多場景的自動駕駛系統(tǒng)。
寫在最后
隨著自動駕駛技術的快速發(fā)展和落地,越來越多的量產(chǎn)車型上開始搭載支持不同級別自動駕駛系統(tǒng)的軟件和硬件。在逐漸向商業(yè)化邁進的同時,量產(chǎn)車型的規(guī)模效應也可以為自動駕駛系統(tǒng)的迭代提供海量的數(shù)據(jù)支持。這也是業(yè)界普遍認可的通向高階自動駕駛的必經(jīng)之路。
在這種背景下,擁有潛在數(shù)據(jù)優(yōu)勢的量產(chǎn)車的企業(yè)該如何切入,特斯拉和依托長城汽車的毫末智行率先給出了方案。兩者的方案既有宏觀的神似之處,也有很多具體策略上的差異,既體現(xiàn)了共識,也展現(xiàn)了個性。
共識之處在于,兩家公司都采用了 Transformer 神經(jīng)網(wǎng)絡結構來提升在超大數(shù)據(jù)集上的學習能力,同時兩家公司也都認為數(shù)據(jù)的采集和自動標注是整個算法迭代的重要環(huán)節(jié),并為此進行了巨大的投入。
個性方面,特斯拉采用純視覺的方案,而毫末采用視覺加激光雷達的方案。在激光雷達量產(chǎn)成本不斷降低的背景下,毫末的方案是具有發(fā)展?jié)摿Φ摹4送猓聊┰?Transformer 的應用上更加深入。
除了融合空間信息以外,Transformer 在 MANA 系統(tǒng)中還被用來融合時序和多模態(tài)信息,將系統(tǒng)采集的各種離散數(shù)據(jù)統(tǒng)一起來,形成連貫的數(shù)據(jù)流,以更好地支持后端的不同應用。
不管采用何種實現(xiàn)方案,特斯拉和毫末智行在海量數(shù)據(jù)上進行的嘗試對于自動駕駛技術的發(fā)展和最終落地實現(xiàn)都是意義重大的。
也希望未來會有更多的企業(yè)加入進來,嘗試更多不同的可能性,互通有無,互相學習,甚至共享技術和數(shù)據(jù),讓自動駕駛能夠更好更快地為大眾服務。