聊聊 DBA 眼中的存儲監(jiān)控
數(shù)據(jù)庫和存儲是密切相關(guān)的兩個IT組件,很多數(shù)據(jù)庫的問題有可能和存儲的問題相關(guān)。不過在IT運維中,數(shù)據(jù)庫和存儲的運維管理一般屬于兩個互相獨立的部門,因此二者的配合總是無法達到十分默契的程度。
數(shù)據(jù)庫出現(xiàn)IO問題的時候,DBA總是希望能把問題推諉給存儲,說是存儲的IO能力不行。而存儲專業(yè)后面已經(jīng)沒有背鍋俠了,所以沒辦法再往后推,只能選擇反擊,自證自己沒問題,問題一定出在數(shù)據(jù)庫本身或者前面的應用。
存儲管理員一般會用一份DBA看的云山霧罩的報告來證明存儲本身沒有問題。DBA也因為專業(yè)知識不夠豐富而往往只能接受這個問題,集中精力去找前端應用的麻煩。這樣的例子在實際生活中比比皆是,不過這種情況存在,對于企業(yè)的IT運維來說并不是一件好事情,很多這樣的隱患都被這種退位埋藏下來,等到爆發(fā)的那一天一定是一件大事。
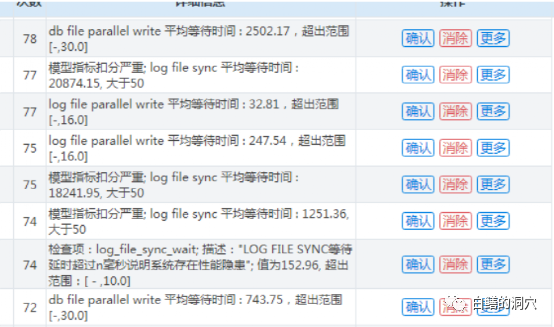
幾年前遇到一個案例,客戶的系統(tǒng)中的5套數(shù)據(jù)庫突然依次宕機,后來重啟后系統(tǒng)恢復正常。從D-SMART的歷史數(shù)據(jù)看,存在大量的寫IO的延時異常問題。
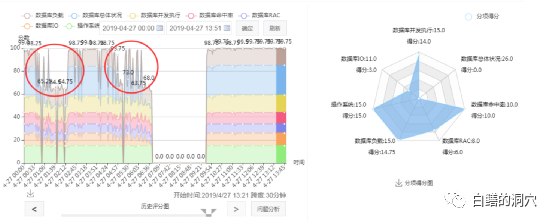
從健康模型上看,這個問題實際上在宕機前就已經(jīng)比較嚴重了。IO存在十分嚴重的問題。通過工具進行了一下IO診斷。

診斷工具分析后端存儲的IO性能存在問題。根據(jù)這種情況,我們認為存儲的鏈路可能存在問題,報給客戶后,客戶也找存儲廠商過來檢查了一番。因為這件事發(fā)生在早上業(yè)務高峰,對企業(yè)的一個核心外網(wǎng)APP造成了嚴重的影響,因此大家都在推諉。存儲廠商堅稱存儲絕對沒有問題,因為數(shù)據(jù)重啟后系統(tǒng)都很正常。我們通過D-SMART觀察發(fā)現(xiàn),數(shù)據(jù)看重啟后,寫IO的性能依然不是很正常,不過存儲廠家堅稱沒問題。于是客戶也就只能找了幾條寫的不好的SQL,讓開發(fā)商整改了事了。
事后我和負責系統(tǒng)運維的主管溝通了了一下,提醒他注意一下存儲的問題,我還是懷疑存儲的硬件或者SAN網(wǎng)絡的鏈路存在問題。不過那個哥們也沒太把我的話當回事。一個多月后,同樣的問題在此發(fā)生。上面大領(lǐng)導震怒,于是開展了排查工作,最終發(fā)現(xiàn)了存儲中一條鏈路不穩(wěn)定的隱患。
正是因為存儲對于數(shù)據(jù)看來說十分重要,因此很多企業(yè)希望能夠打通這一壁壘,讓DBA也能十分直觀的看到存儲的情況。那么現(xiàn)在問題就來了,作為DBA,你想怎么去看存儲系統(tǒng)呢?
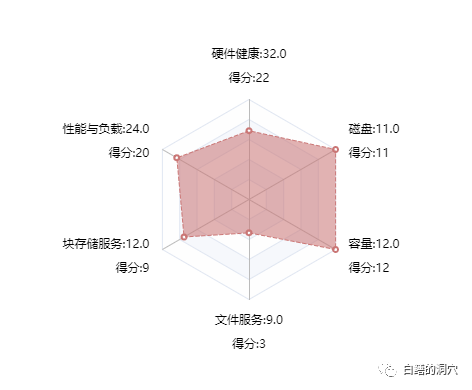
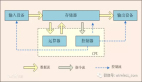
這是D-SMART的存儲的健康模型,作為一個從數(shù)據(jù)庫監(jiān)控發(fā)展起來的運維工具,雖然現(xiàn)在D-SMART已經(jīng)支持了大量的非數(shù)據(jù)庫組件,不過這個系統(tǒng)的核心開發(fā)者是一群DBA,這種視角來看存儲絕對是和大多數(shù)存儲管理員不同的。硬件健康十分明確,任何軟硬件一體化的IT基礎(chǔ)設施的硬件健康是必須去監(jiān)控的。
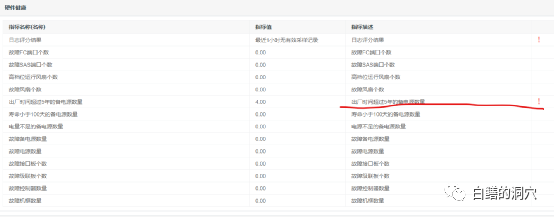
這套存儲的硬件總體健康度還可以,不過有四個備電源出廠時間已經(jīng)超過5年,存在老化的隱患,如果這是一套十分重要的存儲系統(tǒng),需要及時更換老化的備點,從而避免系統(tǒng)出問題。
當然磁盤的健康狀態(tài)也是我們所關(guān)注的。現(xiàn)在的中高端存儲系統(tǒng)的底層軟件做的很好,某塊磁盤故障雖然不會引起應用的問題,不過磁盤故障后的磁盤組的REBUILD還是會引起一些IO性能問題的。如果業(yè)務高峰期的IO十分大,這種磁盤引起的故障很可能會引發(fā)應用的性能問題。
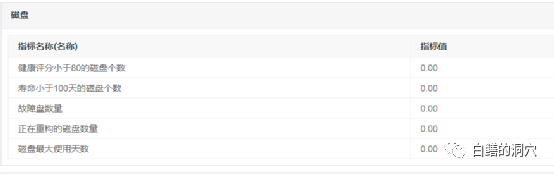
在磁盤方面我們選取了一些經(jīng)過評估的指標,磁盤健康分是對磁盤的SMART數(shù)據(jù)進行綜合評估后的結(jié)果,有些高端存儲中也自帶評估值。另外容量、性能、負載等也是我們關(guān)注的磁盤的指標。除了這些指標之外,我們還需要根據(jù)以往DBA的經(jīng)驗來構(gòu)建一些存儲的故障告警的模型,因為存儲系統(tǒng)十分復雜,某些硬件健康可能會帶來哪些后果,哪些可能會影響數(shù)據(jù)庫的健康,這些問題作為DBA實際上并不清楚。
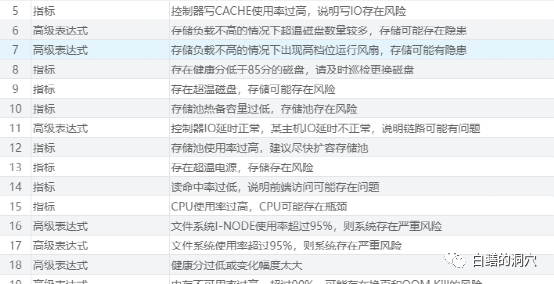
基于上述原因,DBA監(jiān)控存儲系統(tǒng),需要總結(jié)一系列的經(jīng)驗,通過這些經(jīng)驗來幫助我們發(fā)現(xiàn)存儲中存在的問題,否則DBA就會像一個土老帽一樣,在存儲工程師的厚厚的報告中敗下陣來。實際上,在絕大多數(shù)的IT運維甩鍋行動中,DBA很少能夠戰(zhàn)勝存儲管理員。
比如說,“如果控制器IO延時正常,某個主機延時異常,那么可能說明問題是在鏈路上”,這一點仔細想一想,任何一個DBA都能想清楚吧。實際上,存儲管理員很清楚這一點,不過他們不會告訴DBA,而是很可能會找個時間,偷偷的把有問題的鏈路找出來,然后換掉。另外如果出現(xiàn)“IO負載不高,但是存在大量轉(zhuǎn)速過高的風扇”,那是不是意味著存儲存在隱患呢?
實際上,我們需要大量的積累類似的運維經(jīng)驗,從而可以從一些很可能存儲管理員都沒有意識到的現(xiàn)象中看出存儲可能存在的問題。如果DBA能夠掌握這些主動,在這場運維甩鍋大賽中,會占據(jù)主動。
當然,今天講的背鍋俠的事情大多數(shù)都是玩笑話,一個IT團隊中,DBA和存儲管理員是協(xié)作最多的,他們緊密的配合才能讓我們的數(shù)據(jù)庫系統(tǒng)變得更為穩(wěn)定。而在一個企業(yè)中,能夠用DBA比較容易看懂的方式來監(jiān)控存儲系統(tǒng),絕對是十分必要的。希望今天我分享的這些內(nèi)容會給大家?guī)硪恍﹩l(fā)。