老碼農眼中的存儲是什么樣子
存儲,是我們碼農每天都要打交道的事情,而當我們面對RAID,SAN,對象存儲,分布式數據庫等技術的時候,又往往似是而非,存儲成了我們熟悉的陌生人。
在老碼農眼中,存儲仿佛是這個樣子的。
從計算機結構出發
存儲是計算機的一部分,在馮諾伊曼體系結構中,有一個重要的單元即存儲器,它連接了輸入/輸出,以及控制器和運算器,處于核心紐帶的位置。
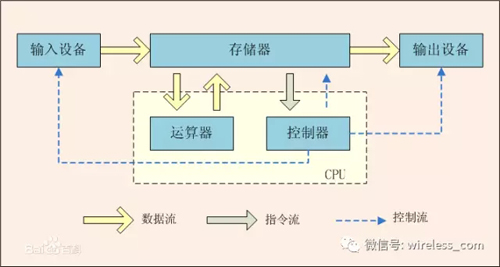
與存儲中的數據交互是通過IO實現的,IO的性能直接影響著系統的性能,甚至我們往往把應用分為IO密集型和CPU密集型等等。
從IO的訪問方式來看,可以分為阻塞/非阻塞,同步/異步。在Linux,提供了5種IO模型:
- 阻塞I/O:blocking I/O
- 非阻塞I/O :nonblocking I/O
- I/O復用:I/O multiplexing (select 和poll)
- 信號驅動I/O :signal driven I/O (SIGIO)
- 異步I/O :asynchronous I/O (the POSIX aio_functions)
從性能上看,異步 IO 的性能無疑是***的。
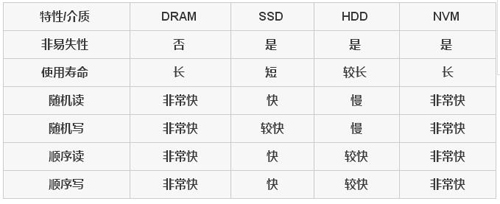
對IO進行抽象,分為邏輯IO和物理IO兩類,分為磁盤,卷和文件系統三層。做一個簡單的比喻,磁盤象空地,卷如同小區,而文件系統就是小區里的樓房和房間。卷位于操作系統和硬盤之間,屏蔽了底層硬盤組合的復雜性,使得多塊硬盤在操作系統來看就像一塊硬盤。鏡像,快照,磁盤的動態擴展,都可以通過卷來實現。而文件系統最主要的目標就是對磁盤空間的管理。
對程序員而言,我們所面對的一般是文件系統,通過文件系統感知存儲中的數據。
提高存儲的可靠性—— 磁盤陣列
一旦硬盤故障,面臨的很可能就是數據的丟失,將演變成一場災難。對很多的企業應用而言,直接提高存儲可靠性的方式是通過磁盤陣列——RAID。
RAID是Redundant Arrays of Independent Disks的縮寫,是把相同的數據存儲在多個硬盤的不同的地方。通過把數據放在多個硬盤上,輸入輸出操作能以平衡的方式交疊,改良性能,也延長了平均故障間隔時間(MTBF),儲存冗余數據也增加了容錯, 從而提高了存儲的可靠性。
常見的RAID類型如下:
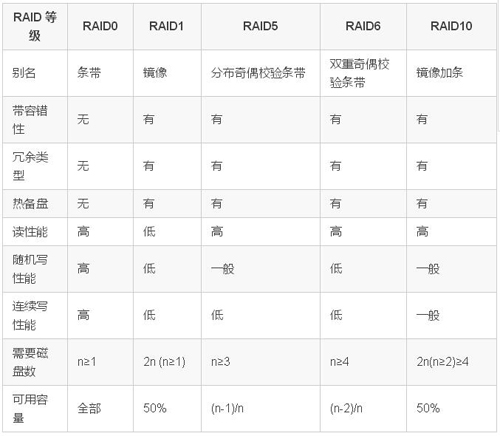
RAID 的兩個關鍵目標是提高數據可靠性和 I/O 性能。實際上, 可以把RAID 看作成一種虛擬化技術,它對多個物理磁盤虛擬成一個大容量的邏輯驅動器。
提高存儲的容量——存儲網絡
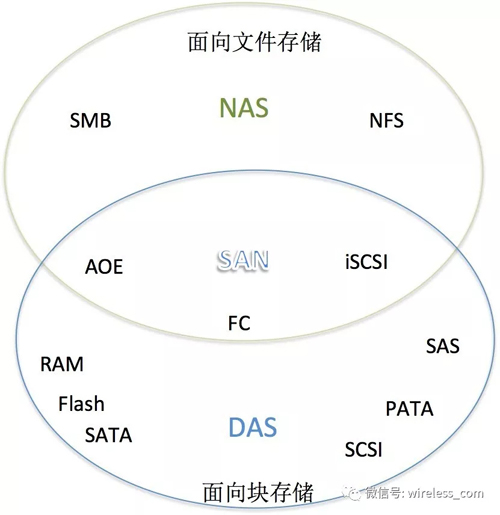
盡管磁盤陣列也在一定程度上提高了存儲的容量, 但是難以滿足人們對存儲容量的需求。為了解決存儲空間的問題, 采用分而治之的方式,通過DAS將硬盤獨立為存儲空間。 DAS(Direct Attached Storage—直接連接存儲)是指將存儲設備通過SCSI接口或光纖通道等直接連接到一臺主機上。DAS 就是一組磁盤的集合體,數據讀取和寫入等也都是由主機來控制。 然而,DAS 沒法實現多主機共享磁盤空間的問題。
為了解決共享的問題,于是有了 SAN ( Storage Area Network)————存儲網絡。SAN 網絡由于不會直接跟磁盤交互,而是解決數據存取的問題,使用的協議比 DAS 的層面要高。對于存儲網絡而言,對帶寬的要求非常高,因此 SAN 網絡下,光纖成為連接的基礎。光纖上的協議比以太網協議更簡潔,性能也更高。
從數據層面來看,存儲空間的共享可以體現為文件的共享。NAS(Network Attached Storage)是將存儲設備通過標準的以太網,連接到一組主機上,N是組件級的存儲方法,能夠解決迅速增加存儲容量的需求。也就是說,NAS從文件系統層面解決存儲的擴容問題。
NAS和SAN本質的不同在文件管理系統的不同。在 SAN中,文件管理系統分別在每一個應用服務器上;而NAS是每個應用服務器通過網絡共享協議(如NFS等)使用同一個文件管理系統。NAS的出發點是在應用、用戶和文件以及它們共享的數據上;而SAN的出發點在磁盤以及聯接它們的基礎設施架構。
三者之間的關系如下圖所示:
一般存儲系統的應用
存儲是我們軟件產品和服務的必備環節,常見的存儲系統應用有:
- 配置數據服務:只讀訪問
- 緩存系統:有/無持久化
- 文件系統:目錄/POSIX
- 對象系統:Blob/KV
- 表格系統:Column/SQL
- 數據庫系統:滿足ACID
- 備份系統:冷存儲/延遲讀
- ......
在使用存儲系統的時候,我們可能需要關注的指標:
- 存儲成本
- 功能: 讀/寫/列索引/條件查詢/事務/權限。。
- 性能:讀寫的 吞吐/IOPS/延時/負載均衡。。。
- 可用性
- 可靠性
- 可擴展性
- 一致性
存儲引擎是存儲系統中的發動機,直接決定存儲系統的性能和功能,實現了存儲系統的增/刪/改/查,在數據庫系統中廣泛采用。 常見的存儲引擎有:哈希存儲引擎,B樹存儲引擎(磁盤索引節省內存)和 LSM樹存儲引擎(隨機寫轉為順序寫)。
分布式存儲系統應用——云服務
分布式存儲系統一般采用可擴展的系統結構,利用多臺存儲服務器分擔存儲負載,利用位置服務器定位存儲信息,不但提高了系統的可靠性、可用性和存取效率,而且易于擴展。
分布式存儲的應用場景一般分為三種:
- 對象存儲: 也就是通常的鍵值存儲,其接口就是簡單的GET,PUT,DEL和其他擴展
- 塊存儲: 通常以QEMU Driver或者Kernel Module的方式存在,需要實現Linux的Block Device接口或者QEMU提供的Block Driver接口,如AWS的EBS,青云的云硬盤,百度云的云磁盤等等
- 文件存儲: 支持POSIX的接口,提供了并行化的能力,如Ceph的CephFS,但是有時候又會把GFS,HDFS這種非POSIX接口的類文件存儲接口算成此類。
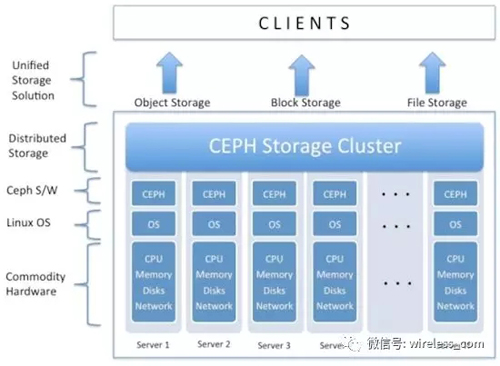
一般地,對象存儲通常以大文件為主,要求足夠的IO帶寬。塊存儲:即能應付大文件讀寫,也能處理好小文件讀寫,塊存儲要求的延遲是***的。文件存儲需要考慮目錄、文件屬性等等的支持,對并行化的支持難度較大,通過具體實現來定義接口,可能會容易一點。
實現一個分布式存儲系統,通常會涉及到元數據,分區,復制,容錯等諸多方面。分布式設計采用主從、全分布式或者是兼而有之, 底層的存儲可以依賴本地文件系統的接口,或者實現一個簡單的物理塊管理,但都不是相對容易的事。
幸運的是,分布式存儲系統已經成為了云服務的基礎能力,尤其是對象存儲,如七牛、S3、OSS、BOS 等等, 已經是標配了。有了面向云服務的存儲, 使我們更多聚焦在業務本身,各種存儲帶來的煩惱會逐漸隨風而逝么?!
【本文來自51CTO專欄作者“老曹”的原創文章,作者微信公眾號:喔家ArchiSelf,id:wrieless-com】