碎片化的數據庫世界,你了解幾分?
數據庫的歷史已經有50多年了,似乎這50年里數據庫從一個輪回走向了另外一個輪回。最初的數據庫世界是碎片化的,每個硬件廠商都有自己的數據庫系統,我用過的最古老的數據庫系統是一臺ICL小型機上的記錄式數據庫系統,用COBOL來讀寫。
隨著計算機網絡的發展,特別是互聯網的普及,數據庫被幾大通用關系型數據庫壟斷了,數據庫世界有被Oracle等大廠一統天下的趨勢。有幾年,我甚至認為關系型數據庫已經沒有什么可以創新的了。不過這些年數據庫領域的發展讓我這個十分淺陋的想法變得如此的可笑。
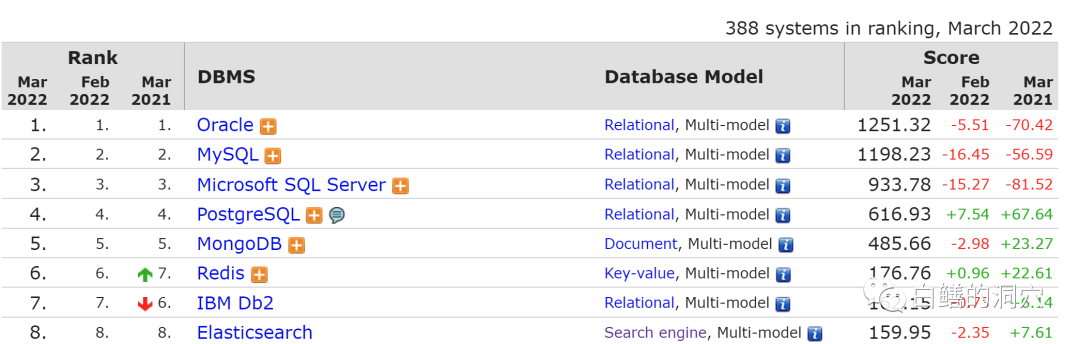
隨著企業信息化對數據處理要求的不斷提高,我們有太多種類的數據需要處理了。應用的類型也是豐富多彩。某些應用程序需要同時訪問用于存儲結構化數據的關系數據庫(例如 PostgreSQL)、用于內容緩存的內存數據庫(例如 Redis)、存儲海量物聯網數據的時間序列數據庫和用于分析的數據倉庫。現在僅在DB-ENGINES上就收錄了352種數據庫,其中147種是關系型數據庫(這些關系型數據庫中,很多還是多模數據庫)。
不同業務類別的企業,也可能更傾向于選擇某種不同的數據庫。比如銀行或金融機構可能會選擇 Oracle 或 PostgreSQL 等關系 DBMS 來確保其結構化數據的 ACID事務;運營大型在線多人游戲的互聯網服務商更喜歡使用 Redis 等鍵值 NoSQL 數據庫;
社交媒體分析企業通常會選擇圖數據庫;而物聯網 企業會選擇時間序列數據庫來支持其傳感器或網絡數據。這并不是完全出于應用特點的選擇,而更多的是習慣與歷史傳承。對于一個企業來說,選對了數據庫,那么你的信息系統建設就成功了一小半了。
前幾天我在REDDIT上參與了一個帖子,有個朋友問了一個數據庫選型的問題,他在做一個市場項目,需要管理用戶、身份、產品、評論、點贊、標簽、搜索等功能。他在PostgreSQL和Mongodb之間彷徨,希望得到大家的幫助。
如果按照應用場景來劃分,這個系統主要是一個關系型數據為核心的系統,不過也會涉及到一部分文檔數據。從架構師設計上來看,習慣于關系型數據庫的團隊很可能會選擇PostgreSQL,再加上ES或者Mongodb來存儲一些文檔類的數據。
而如果是一個受過比較多的互聯網思維熏陶的設計師,有可能會直接選擇Mongodb單一的解決方案來做這個項目了。當然做出任何一種選擇,只要團隊對數據庫以及相關的開發是擅長的,那么哪怕遇到一些問題,也是能解決的。不過如果一個對Mongodb知之甚少的團隊,貿然選擇Mongodb,那么可能他們會吃很多苦頭。
實際上,在早期我們的數據庫選型并沒有那么麻煩,因為關系型數據庫主要就是做關系處理的,文檔數據庫也只是專注于文檔處理。而隨著數據庫產業的內卷,一個功能單一的數據庫產品可能可以在開源社區獲得青睞,但是無法在商業上獲得成功。從DB-ENGINES上可以看到,排名前八位的數據庫無一不是多模數據庫。
經過多年的發展,文檔數據庫MongoDB也變成了一種多模數據庫,甚至在一些簡單的事務的支持上也相對不錯。如果你的團隊喜歡node.js,熟練掌握Mongoose組件,那么這個項目使用MongoDB也沒啥大問題。
不過從另外一個方面來說,PostgreSQL從出生起就是一個學院派的數據庫,其多模數據庫特性依然十分明顯。在內卷和碎片化的數據庫領域演進過程中,PostgreSQL在文檔數據支持方面也變得越來越出色,MongoDB能做的很多工作,PG做的也不賴。這也是目前我們出現數據庫選擇性障礙的主要因素之一。
如果這個項目今后的用戶不大,那么從數據庫選擇的角度上看,選任何一個都不算錯誤,選哪個要看開發團隊對這兩種數據庫的掌握和熟悉程度了。不過如果這個項目最后要服務的用戶群體十分巨大,那么這個選擇將十分重要,這決定了今后項目開發的難度。如果這個項目今后的交易型功能十分復雜,那么如果選擇MongoDB,開發團隊將會遇到很多mongoDB原生態功能無法支撐的處理。
雖然如此,只要研發團隊夠強大,這些僅僅是會成為障礙,并不能成為決定項目成敗的關鍵。數據庫搞不定的事情,通過應用代碼去搞定,就不會有任何問題了。
前兩年我有一個客戶上一個新系統,當時整體框架設計就是采用微服務,于是引入了領域建模,將整個系統劃分為近30個領域。原本計劃應用采用阿里云的微服務框架,數據庫使用RDS。不過開發過程中,研發團隊發現開發人員能力不足,于是數據庫仍然恢復使用Oracle,并將30個領域數據庫合并為6個Oracle數據庫。
這種臨陣退縮導致了開發團隊在微服務架構下的大撤退,雖然應用服務仍然按照30個領域跑在容器里,不過大量的業務邏輯依然下沉到了數據庫里。
因為微服務架構下的IT技術政策不允許使用Oracle dblink,開發團隊又沒有能力將很多數據關聯全部拆分為接口和服務調用,于是天才的架構師想出了數據復制,在6套數據庫之間創建了上百條復制鏈路,確保每個微服務都不跨庫訪問。我想這樣的披著微服務外衣的集中式架構的應用系統,今后就是運維的災難。
在這個數據庫產業碎片化的內卷時代,數據庫選擇確實不是一件十分簡單的事情,既然如此復制,有些時候甚至無法把它當成一件事情,研發團隊對數據庫的掌握能力才是最為關鍵的事情。
是選擇一個更合適的數據庫產品,還是提升開發團隊駕馭微服務應用的能力,抑或是請高水平的數據架構師來做設計,這些都是解決問題的方法,具體用哪一種,每個企業的IT部門都有一把辛酸淚需要傾訴。有時候作為門外的人,是不一定看得清楚的。