聊聊前端數據流選型
1. 什么是數據流
什么是流?
在數學中,一個流用數學方式形式化了“取決于時間的變化”的一般想法。暫且定義流是響應時間變化的一個集合體。
什么是數據流
依據之前的定義,數據流即隨時間變化的一個數據集合。
前端針對于現狀mvvm模式下,數據即頁面,在多數情況下,數據不變頁面不變。那么我們轉換一下,數據==>頁面,數據流是否可以等價為一個頁面的變化集合。這個是什么,就是我們的業務邏輯。
當然,前面的假設,是經過很多轉化,其實有很多漏洞和錯誤。但是可以作為一個簡單的參考。
這個不是數據流的定義,只是作為一個引子思考。

2. 現行前端數據管理模式
現行三大數據管理方式
- 函數式、不可變、模式化。典型實現:Redux。
- 響應式、依賴追蹤。典型實現:Mobx。
- 響應式,以流的形式實現。Rxjs、xstream。
Redux模式(reduck)
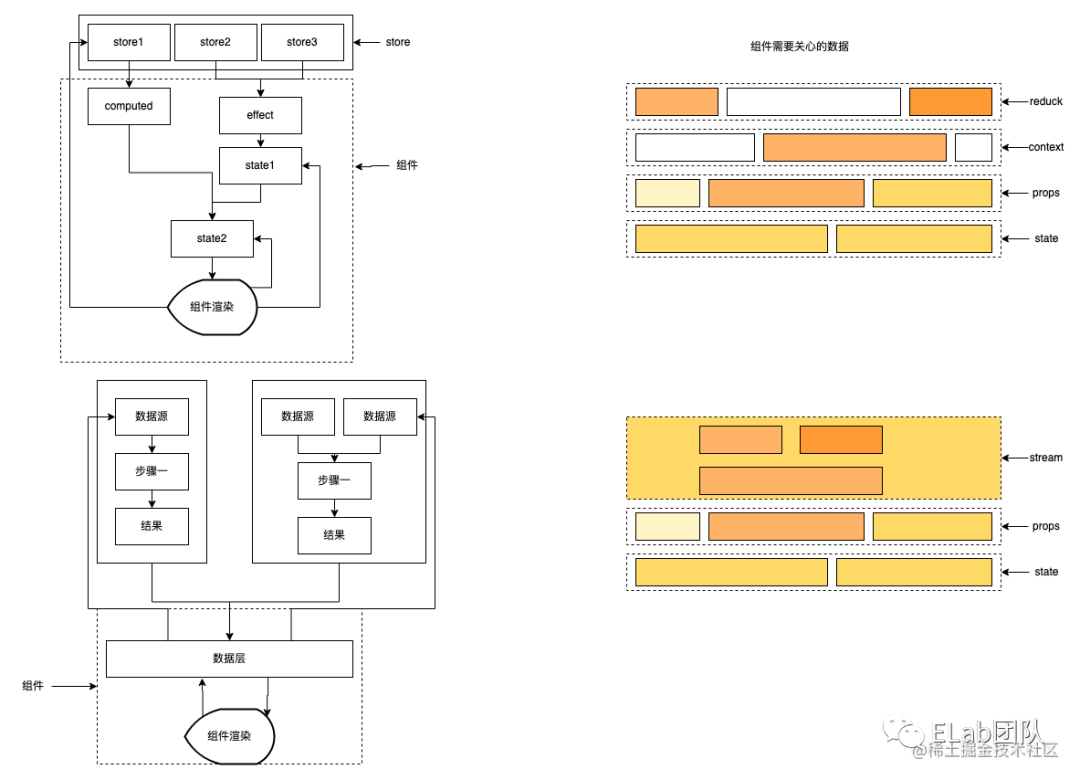
redux模式常規用法是作為整個應用全局狀態管理使用。這只是作為一個提高跨組件通信的能力的工具。redux的思想是作為獨立于組件的一個數據倉庫,對數據進行保護,保障數據穩定可靠。
可以簡單理解redux是一個帶保護的全局使用的Context(useContext)。
針對于原生的提供了數據保護(dispatch+reducer),對于更改只允許使用dispatch進行更改。能夠保障可回溯性,數據來源清晰,能夠十分良好的隔絕副作用。
使用方面:
- 優點:數據隔離,數據變化可溯源。
- 缺點:多redux直接完全隔離,小型化困難,action方法容易膨脹。
- 業務方面使用:對于大型項目拆分設計概念不足,store數據個人管控不友好,容易造成理解困難邏輯修改困難。
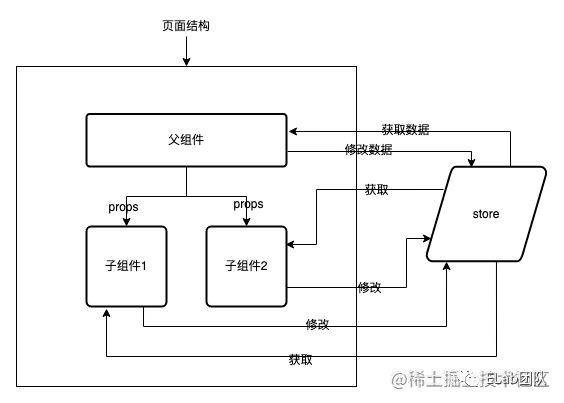
Mobx模式
mobx引入了全新的思想,將數據作為一個源頭,擁有當數據變化時,通過計算狀態,頁面進行變化,并且根據observable,自動根據依賴執行更新。雖然有了action,但還是沒有強制分離副作用。
mobx就好像將數據和組件進行綁定,形成依賴關系,自動訂閱和自動發布,狀態變更組件就變更。將邏輯和視圖直接綁定在一起,這本應該是十分高效的情況,但是因為深入了組件,副作用的處理還是不夠清晰,對于個人把控還是不夠友好。
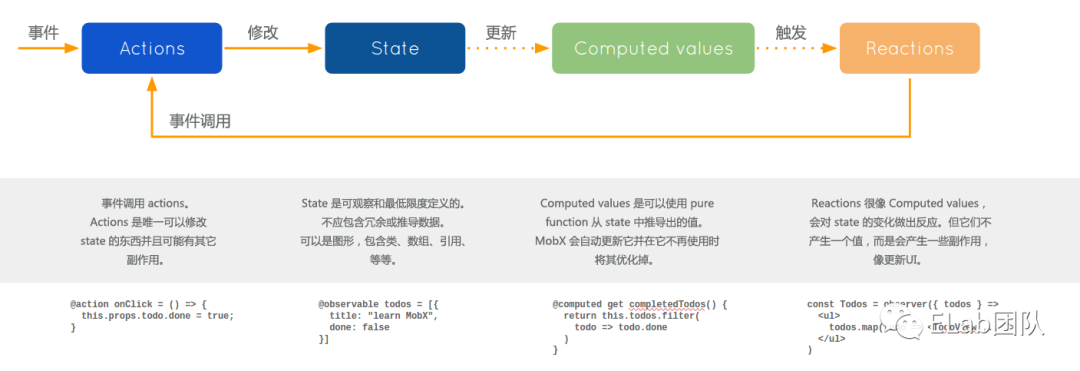
流模式(rxjs)
rxjs和mobx有些相似。rxjs將所有的數據都可以隨意的拆散和組合成一個新的節點,可以簡單理解為將redux的state進行了打散成多個數據節點,每一個任意節點都可以進行類似computed的計算生成新的節點。
流模式相較于redux模式沒有action的規范,卻定義了更改的節點范圍,只能更改定義的入口節點(一條流的起始節點)。rxjs沒有mobx從數據變化到頁面變化這個功能,可以使用useState和useEffect實現或者現成的三方庫rxjs-hooks。
rxjs的優勢是,抽離所有數據源之后,剩余全部都是邏輯問題,副作用在抽離數據源的時候就已經剝離干凈了(因為外部副作用數據也可以抽離成rxjs的節點),剩下就通過api和純函數來編寫具體的邏輯了。
又因為大量的api,拆解observable節點的成本極低,所以邏輯拆分十分容易,可讀性十分高。
rxjs有推和拉的概念,在正常邏輯十分流暢的情況下,程序的代碼應該是每個節點轉變都會推動下一個節點的執行。在rxjs中將數據流進行串流好后,組件只要對于頭部節點進行讀寫數據,對于尾部節點直接讀取數據就可以,大部分邏輯全部被抽離出了組件。
使用方面:
- 優點:邏輯拆分簡便,純函數式編程。
- 缺點:數據拆分復雜,重設計,api學習和理解成本高。
理想情況下,頁面就是一個個無狀態組件,行為改變數據。數據變化又觸發邏輯變更,邏輯變更數據。數據又回流到頁面,這是一個整體的閉環,以數據為核心,完美的做到數據驅動頁面。

新星 Recoil
recoil是facebook官方推薦的一個狀態管理庫,作為一個“新成員”,recoil相比于之前的三種狀態管理方式,做了很多取舍。它有節點的概念,有atom(原子數據)和selector(派生數據)但是不和mobx一樣,recoil是基于Immutable(不變)模式。
recoil的基礎思想是atom數據之間沒有關聯,產生的關聯數據全部由selector來產生,atom的變動,相關的selector隨之變動,這個和響應式流的思想一致的。
recoil的優勢,貼合react,可以將recoil的實現當作通過useMemo包裝的context,api使用可以滿足只讀,只寫進行拆分,可以十分貼合最優渲染,降低無用的渲染。
上述前三種數據流沒有什么優劣好壞之分,只是在不同場景中使用各有各的優勢而已。
3. 理想中的源數據編程
數據與數據之間的關系
數據不是憑空產生的數據,數據可能又會產生新的數據。
數據之間推行的是最小可用原則,分而治之,這才更利于我們開發和維護。
個人把產生數據的起始數據定義為源數據。有些數據可以互相轉換,那如何定義源數據???
定義源數據
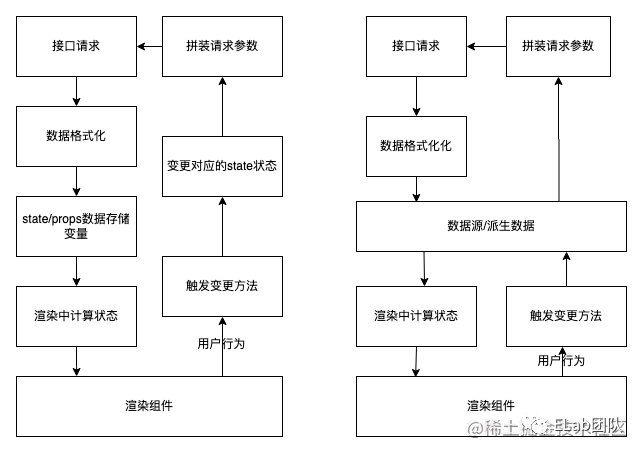
從組件(頁面)視角看一下數據。
- 面向接口編程
大部分情況下前端和后端之間的數據交互就只有接口這一種。又因為真實的所有數據都是從服務端獲取的數據,所以下意識的以服務端接口為數據起始。數據處理的鏈路較長,范圍變大對于個人的理解要求是十分高的,個人認為這對于一個大型應用是不健康的。
- 面向數據編程
分離接口請求,只關心組件狀態,對于組件方面,任何數據不將其做區分,數據來就渲染。
個人將用戶可交互的數據可以定義為源數據。因為前端接口請求也是由用戶的信息請求來的。對于應用來說,只有用戶的操作不可預知,其余操作都是可控的。
如果將可控的邏輯封裝后抽離,管理的時候不需要再直接感知到這些,我們直面的就是用戶的操作和頁面的響應。
例如: 以單個列表頁來說,用戶選擇的篩選項就是源數據,而接口請求回來的列表數據就是派生數據,由接口請求產生的頁面loading態也可以是派生數據也可以是源數據。
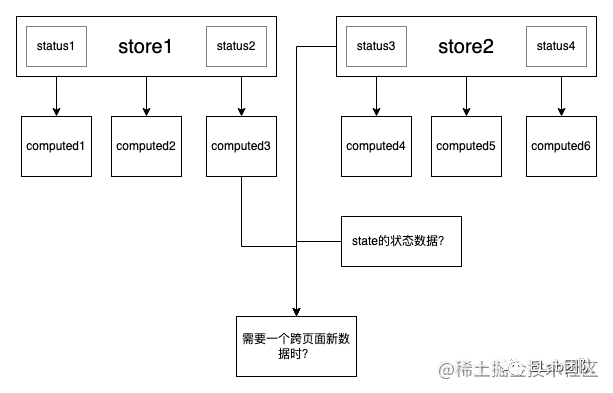
redux數據模型
在使用redux的時候沒有很好的辦法處理數據的層級關系,導致store中數據的池子越來越大,沒有很強分層的概念,這也是redux小型化困難帶來的,使用的時候會下意識將跨層級的數據存入store。
其次redux沒法很好的描述數據與數據之間的關系,有人說computed可以描述數據與數據之間的關聯,簡單意義上是沒問題的,但是computed的局限性,跨redux無法支撐,如果要使用,必須將所有源數據匯集到同一個redux之間,這與最小可用原則是相違背的。
就是因為redux的設計模式不夠靈活,導致會將大量數據與數據之間的轉化邏輯積壓在頁面或者組件內部,這對于視圖層是一種負擔。
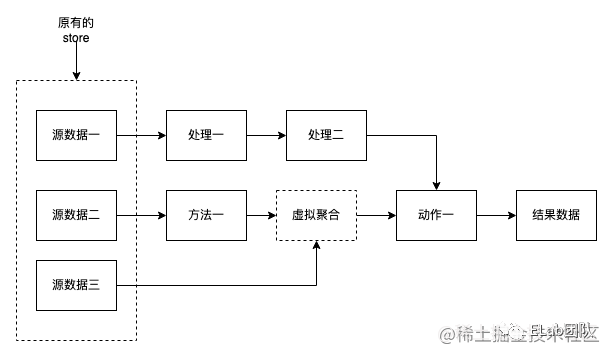
響應式流數據模型
為了方便理解,可以和之前一樣將數據處理理解為computed,每一個節點都可以隨意衍生出一個新的節點,但是觸發整條流的變化又只會在初始節點(源數據)節點,使用整條流的結果。
在流模式中對于組件或頁面外層的數據沒有任何層次之分,每個節點都是平級的,如果分層,可以在業務上分層,通過不斷的拼接,將業務邏輯進行串聯,得出你想要的結果,相較于原先散亂在各地的邏輯,串聯的流式邏輯在可讀性上也更優。
流式數據的優點是拆分成本極低,這樣也更符合我們的思想,代碼塊拆分,這樣每一小塊邏輯拆分出一個節點,邏輯復雜度就通過不斷的拆解,變得十分低了,但是又不會因為拆解的過多,邏輯散亂。
- 沒有固化數據的層級,離散的數據,可以自由定義和拼接。
- 以離散的數據,將邏輯串流,數據靈活之后,邏輯卻是收斂,不會分散,做到了數據精準的使用。
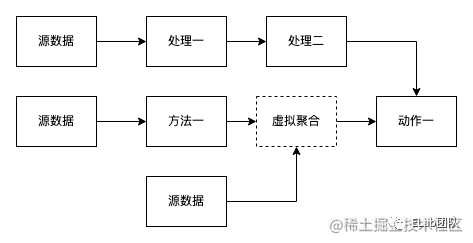
reducx和rxjs的數據管理范圍
總結
綜上所述,其實不同的模式帶來的是針對不同場景的應用,redux的快捷應用,快捷開發,數據變化的穩定,mobx對于響應式的變化,都是各有各的特色。
在寫代碼的時候,我的感覺像是在構建一個動畫的每一幀(視圖),又要給出每一幀為什么變化(寫邏輯,事件)的感覺,邏輯和視圖混合在一起,對于整體的把控十分難處理,就像你需要對于整個動畫的變化都掌握,抽離了視圖和邏輯,邏輯只需要變化數據,視圖只需要針對對應的數據變化而已。
參考文章
流動的數據——使用 RxJS 構造復雜單頁應用的數據邏輯
精讀《前端數據流哲學》