在微服務架構下基于 Prometheus 構建一體化監控平臺的優秀實踐
精選隨著 Prometheus 逐漸成為云原生時代的可觀測事實標準,那么今天為大家帶來在微服務架構下基于 Prometheus 構建一體化監控平臺的最佳實踐和一些相關的思考,內容主要包括以下幾個部分:
- 微服務、容器化技術演進的監控之痛
- 云原生時代,為什么是 Prometheus
- 阿里云 Prometheus 在微服務場景的落地實踐
- 大規模落地實踐挑戰和解決方案
- 云原生可觀測性的發展趨勢和展望
一、微服務、容器化技術演進的監控之痛
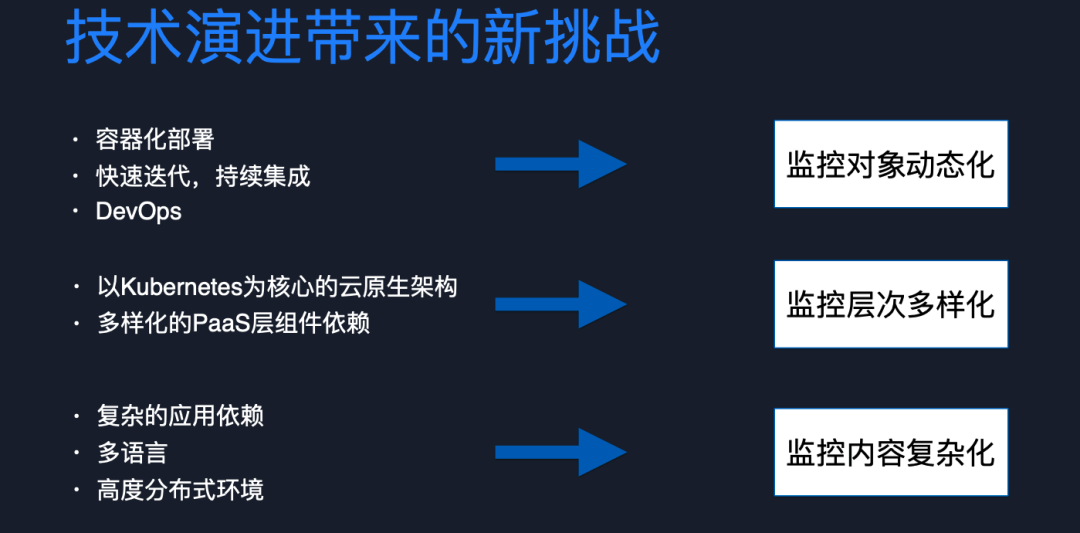
1.第一個挑戰:監控對象動態化
容器化部署使得我們的監控對象變得動態化。隨著 K8s 這種服務編排框架大規模落地,應用部署單元從原來的主機變成一個 Pod。Pod 在每次發布時銷毀重建,IP 也發生變化。在微服務體系下,我們講究快速迭代、持續集成,這使得發布變得愈發頻繁,Pod 生命周期變得非常短暫。據統計,平均每個 Pod 的生命周期只有兩三天,然后就會被銷毀,再去重建。而且隨著 DevOps 普及,負責應用發布的角色發生變化,應用發布變得弱管控和更加敏捷,一個應用會不斷的進行滾動發布,從而達成快速迭代的目標。
所以說,隨著軟件生產流程的變化和相關技術的成熟,我們的監控對象處于一個不斷頻繁變化的狀態之中。
2.第二個挑戰:監控層次/對象多樣化
首先,Kubernetes 相關的 kube 組件以及容器層是我們必須要監控的新對象。其次,微服務拆分之后,以及行業在中間件,DB 等領域的精細化發展使我們發現依賴的 PaaS 層組件越來越多樣化,對這些應用強依賴的 PaaS 組件也需要進行監控。最后就是多語言。當微服務拆分之后,每個團隊都可以選擇自己擅長的語言去進行應用開發。這就造成一個問題,即這些應用的監控指標需要支持各種語言的 client library 才能去生產和暴露。
3.第三個挑戰:監控內容復雜化
監控內容復雜化來源于以下幾點,第一個是復雜的應用依賴。第二個是在高度分布式環境下,我們需要非常復雜,細顆粒度的指標才能描繪整個系統狀態。
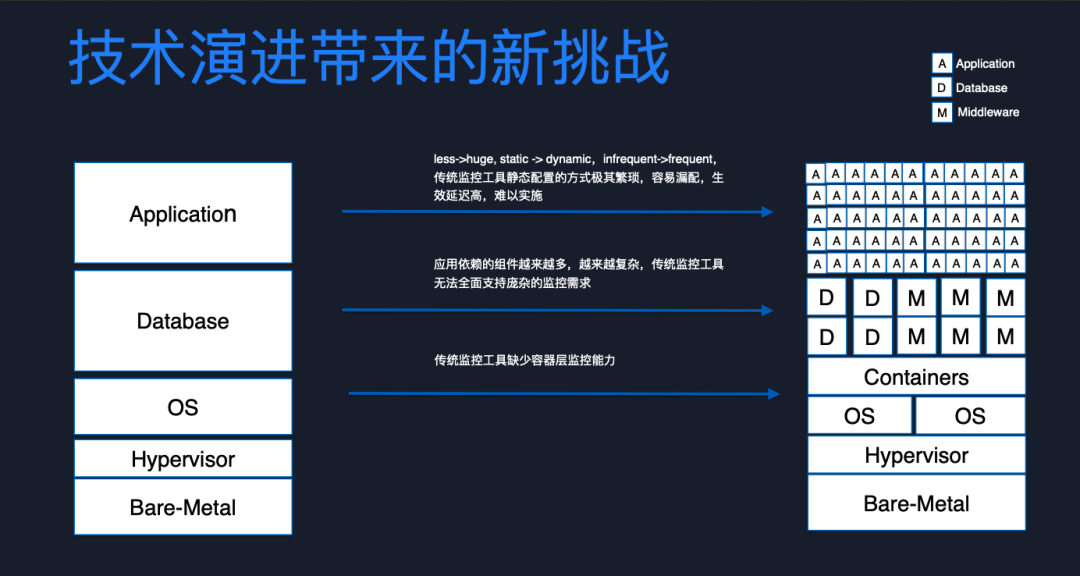
上面這張圖我們可以更直觀的感受到以上挑戰是如何產生的,左邊是傳統單體應用的部署架構,右邊是微服務部署的架構。原來只需監控一個應用對象,現在變成了幾十、上百個且不停的動態的發布,IP 地址不停變化。傳統監控工具可能會采用靜態配置的方式去發現這些監控目標。但在微服務場景下,這種方式已經無法實施。原來單體應用可能只需要依賴 MySQL 就可以了。但現在依賴的組件越來越多。傳統監控工具是沒有辦法全面支持這種龐大的監控需求,且傳統監控工具缺乏在容器層的監控能力。
為了解決上述問題,我們發現 Prometheus 或許是一個理想的解決方案。
二、云原生時代,為什么是 Prometheus

- 動態化:Prometheus 具有先發優勢。在 Kubernetes 誕生之初,標配監控工具就是 Prometheus,天然契合 Kubernetes 的架構與技術特征,可以去自動發現監控目標。在大規模、監控目標不停變化的監控場景下,根據實踐經驗,主動拉取采集是一種比較好的實現方式,可以避免監控目標指標漏采,監控目標需要解決維護采集點配置以及 push 模式實現成本較大等一系列問題。其次,動態化的容器指標通過 Kubernetes 的 Kubelet/VK 組件采集,它們天然采用 Prometheus 格式生產和暴露指標數據。
- 多樣化:因為 Kubernetes 有很多的控制面組件,比如 API server 等組件,也是天然通過 Prometheus 數據格式來暴露監控指標,這使得 Prometheus 采集這些組件的監控指標非常標準和簡單。其次,Prometheus 是一個開放性社區,有 100+ 個官方或非官方 exporter 可以供大家使用。比如,你想監控數據庫、消息隊列、分布式存儲、注冊中心、網關,各種各樣的 exporter 開箱即用,可以把原組件非 Prometheus 標準的數據格式轉化成 Prometheus 的數據格式供采集器進行采集。再者,Prometheus 支持 go、Python、Java 等 20 多種語言,可以非常簡單的為應用生成和暴露監控的 metric。最后,Prometheus 可擴展性非常強,如果上面都滿足不了應用需求,它也有強大的工具可以幫助業務方輕松的寫出自己的 exporter。
- 復雜化:Prometheus 定義了一個多維模型。多維模型可以簡單理解為我可以給任何事情都打上標簽,通過標簽的方式來描述對象的系統狀態。多維模型聽起來比較簡單,但很多監控工具最開始無法用這種方式去描述它的監控目標。通過多維模型,我們可以很容易刻畫出整個監控目標的復雜狀態,還可以刻畫出應用之間的依賴關系。

其次,Prometheus 實現了一種稱為 PromQL 的查詢語言,非常強大,可以將復雜的指標進行過濾、聚合、計算。它內置有 20-30 種計算函數和算子,包括常見的累加,差值,平均值、最大最小值,P99,TopK 等,可以基于這些計算能力直接繪制指標視圖和配置告警,這可以省去原本需要的代碼開發工作,非常容易的得到想要的業務結果。
可以看到上圖中一個真實的 PromQL 語句,http_request_duration_seconds_bucket 是一個 Histogram 類型的指標,它有多個 bucket,通過上面的 PromQL 語句,不用編寫任何代碼就可以計算出 RT 超過 500ms 和 1200ms 的請求占比,從而得出 Apdex Score,評價某個接口的服務能力。
三、Prometheus 落地實踐方案
接下來,我們看一個完整的落地實踐方案。其核心就是如何圍繞 Prometheus 來構建可觀測平臺,也就是如何把描述系統狀態的各個層次的指標數據都匯聚到 Prometheus 數據監控數據平臺上。
之前我們幾乎是不可能完成這種將各類指標進行匯聚的工作的。因為每個監控工具專注的領域不一樣,數據格式不一樣,工具之間的數據無法打通,即使匯聚在一起也無法產生 1+1>2 的效果。
但通過 Prometheus 可以把 IaaS、PaaS 層的各種組件的監控指標都匯聚在一起。如果需要采集一些業務指標、應用的健康狀態、云上應用所依賴的云產品是否正常,Kubernetes 組件有沒有在正常運行,容器的 CPU,內存水位是否符合預期,Node 節點 tcp 連接數分配有沒有風險,或者需要將 tracing 轉成 metric,log 轉成 metric,甚至一些 CI/CD 事件想要和核心監控視圖關聯起來,從而快速發現到底監控視圖的數據異常是不是由某次變更引起的。我們都有成熟的工具以將以上描述我們系統運行狀態的指標采集到 Prometheus 平臺。
另外,我們還可以把一些把無意義的計算單元,通過標記的方式標記成有意義的業務語義,然后把這些指標也匯聚到 Prometheus 上面來。
所以這里的核心思想就是打破數據邊界,把所有能夠真實反映我們當前運行系統狀態的指標匯聚在一起,無代碼編寫成本,就可以將這些數據關聯,生產出有效的監控視圖和告警。在具體實施方面我們總結出三個層次,以便更好的實施。
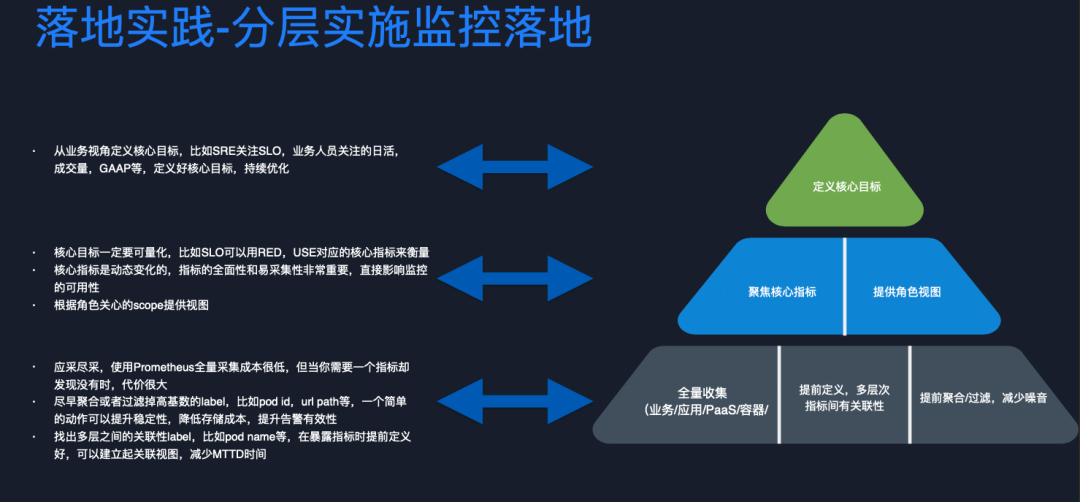
第一個層次:從業務視角定義核心目標
首先,我們需要定義核心目標,這些監控的指標一定是為業務服務,指標本身并無實際意義,只是一個數值,只有確定的業務目標才能賦予這些指標生命力。
第二個層次:聚焦核心指標&提供角色視圖
在制定核心目標后,我們需要確定核心目標可以被量化。需要特別注意,核心指標一定是動態變化的,因為微服務的特點就是要不停快速迭代。今天可能還沒有依賴某組件,可能下個迭代就依賴了,如果你沒有被依賴組件的指標,會非常痛苦。因為沒有辦法通過這些核心指標去完整映射核心目標到底有沒有異常。另外,需要根據角色去提供視圖,一個組織里不同角色關心的視圖是不一樣的,當出現問題時,角色視圖可以幫助更快地排查問題。
第三個層次:全量收集&提前定義&提前聚合/過濾
想要實現上面兩層的核心基礎其實就是是全量收集,即能采集的指標一定要應采盡采。全量采集的技術基礎是 metric 指標的存儲成本是相對于 log 還有 trace 而言最小,即使全量采集也不會讓成本膨脹太多,卻能讓你的核心目標度量效果即使在快速迭代的過程也不受損。
在全量采集前提下,我們要盡早去聚合或過濾掉高基數的 label。高基數問題是時序場景常遇到的問題,我們會看到采集的容器層指標帶一些 Pod ID,但這種 label 是沒有實際業務意義,再比如 URL path 會發散,帶上了 uid 或者 order id 之類的業務 id,我們可能關心的是整個接口的健康狀態,而不是某一個 path 的,這時就需要把 path 聚合一下,通過這種聚合可以減少存儲成本,提升存儲穩定性,也不會影響核心目標的達成。
另外,在我們采集指標時,盡量找出多層之間有關聯關系的 label。比如在采集一些應用指標時,我們可以通過 Prometheus relabel 的功能把 pod name 一起采集過來,這樣就可以直接建立應用和容器層的關聯視圖,在排查問題時通過關聯分析減少 MTTD 時間。
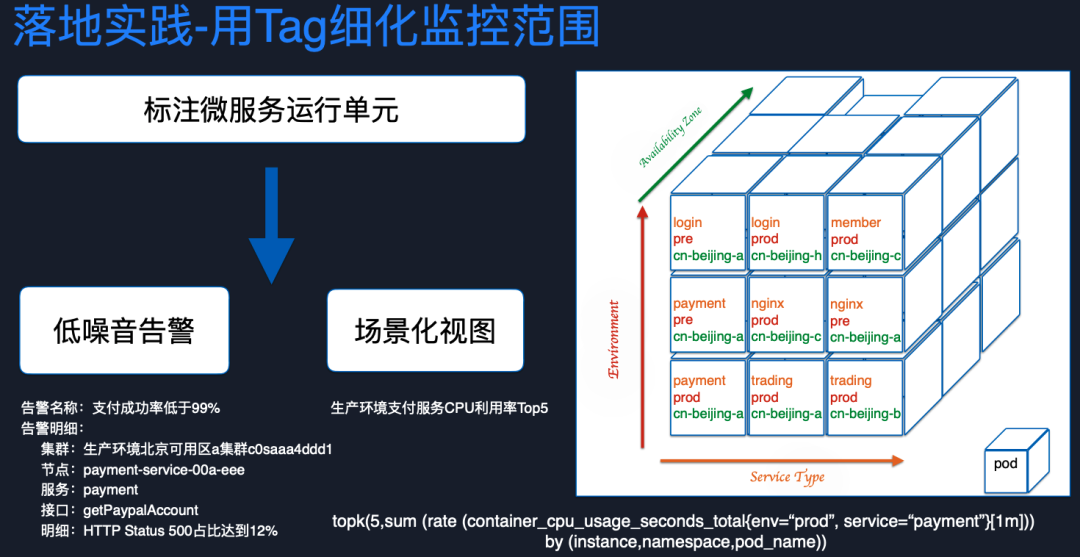
接下來,我們講一下如何利用 Tag 細化監控范圍。Pod 本身是沒有實際的業務語義的,但打上一些標簽后,比如 某個 Pod 屬于登錄服務還是支付服務,屬于生產環境還是測試、預發環境。就使得 Pod 這個計算單元有了實際業務語義。當有了業務語義之后,就可以配置出低噪音的告警。比如當我們支付成功率低于三個 9 的時候,認為核心目標已經受損了,需要馬上告警出來。告警之后通過 Tag,就可以迅速定位到底是生產環境還是測試環境的問題。
如果是生產環境就要馬上去處理,可以定位到底在北京哪個可用區,告警的原因到底是因為哪個服務的接口出現了異常。所以說告警的有效性也非常重要,因為我們在實踐中都知道,如果告警一直是處于流量轟炸狀態,告警最后就會變得沒有意義。
通過 Tag,我們可以提供場景化的視圖,假設老板想要去撈取生產環境下支付服務 CPU 利用率 Top5 的 Pod 列表,通過 Tag 加上 PromQL 語言,我們一條語句就可以把這個視圖馬上撈取出來。
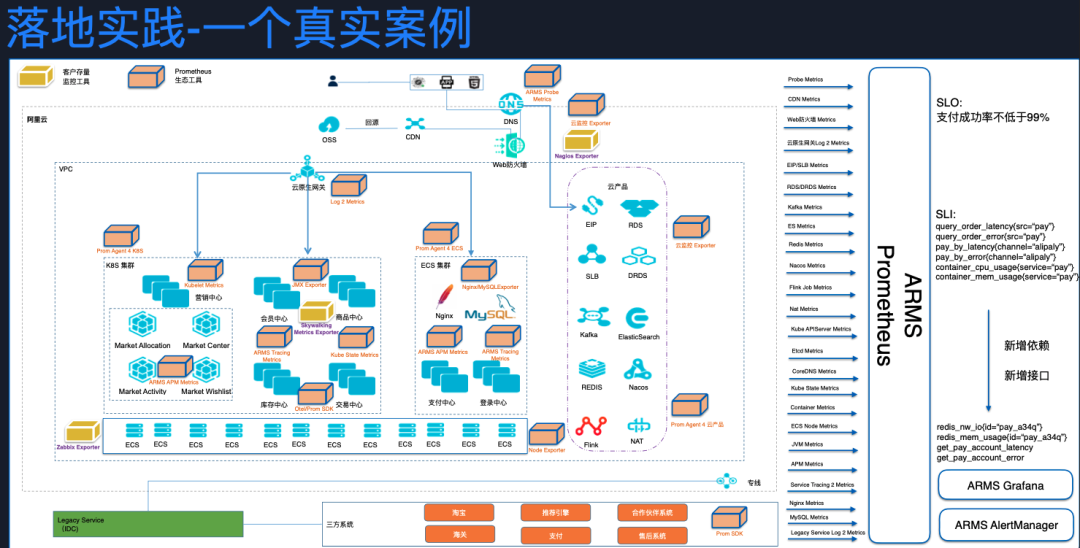
講一個真實的電商場景如何通過 Prometheus 構建統一監控平臺的。從圖中看到,電商系統的主體已經遷移到阿里云上,分兩部分,一部分是在 Kubernetes 集群,另一部分是在 ECS 的虛機集群。每個服務依賴不同的中間件或 DB 組件,有些依賴云產品,還有一些依賴原有自建 DB 或組件。
我們可以看到使用之前的監控方案,很難實現全面的監控指標采集。應用層的同學通常只關心應用層正不正常,有哪些指標可以反映健康狀態,他們可能會選擇一些 APM 工具,或者其使用的開發語言相關的特定監控工具,比如使用 Spring Boot 的開發同學會通過 Actuator 監控應用狀態。而負責 SRE 的同學通常會關心基礎設施正不正常,怎么監控 Kubernetes 組件,容器的黃金指標水位是否正常。他們可能是不同的部門,會通過不同監控工具實現不同的監控系統,這些系統之間是割裂的,所以你去排查一個問題,我們都有一個體感,很多時候可能是網絡問題,有些時候可能是某一臺主機有問題,影響了應用性能,如果只看應用層,會覺得應用代碼沒有問題,但是有了這樣一個全局的視圖,就會很快排查到影響你應用的問題點到底在哪。
我們可以通過 node exporter 去采集 VM 層面 CPU、內存、 IO 黃金三指標,也可以通過云監控的 exporter,監控應用依賴的云服務健康狀態。當然 Kubernetes 和容器這一層 Prometheus 提供的能力更加全面,比如 kube-state-metrics 可以監控 Kubernetes 的元信息,通過 cadvisor 可以采集容器運行時指標,還有各種 kube 組件的監控,動動手指頭配置幾個采集 job,或者直接用開源或者云產品,開箱即用。
另外我們團隊提供了 ARMS APM,以無侵入的方式去生產,暴露應用的指標,全面監控應用健康狀態。如果不能滿足需求的話,你也可以使用 Prometheus 官方的多語言 client library 或者三方提供的一些 client library 很方便的去生產和暴露你的指標。還有很多官方或者三方的 exporter 可以用來監控 mysql,redis,nginx,kafka 等 DB 和中間件。除此之外,針對特定語言開發,比如 JVM,還有 JMX exporter 可以使用,查看堆內存有使用正不正常,GC 是不是在頻繁的發生。
通過 Prometheus 及其生態,規范化,統一的指標可以很容易的匯聚在一起,接下來我們就可以定義 SLO。在電商系統場景下,以支付成功率為例,這是很要命的一個指標,如果你的支付成功率低了,可能今天 gaap 就會損失很大。通過 SLI 去準確衡量核心目標是否受損。比如 SLI 是應用層面的接口 error 這種指標,可能還需要關注應用運行的容器,其內存、CPU 是否在健康水位,如果超出健康水位,這可能就是預警,在接下來某段時間就會發生故障。有了這些指標,使用 Grafana 和 AlertManager,就可以輕松完成可視化和告警配置,在應用異常不符合預期時及時告警,快速定位問題范圍。
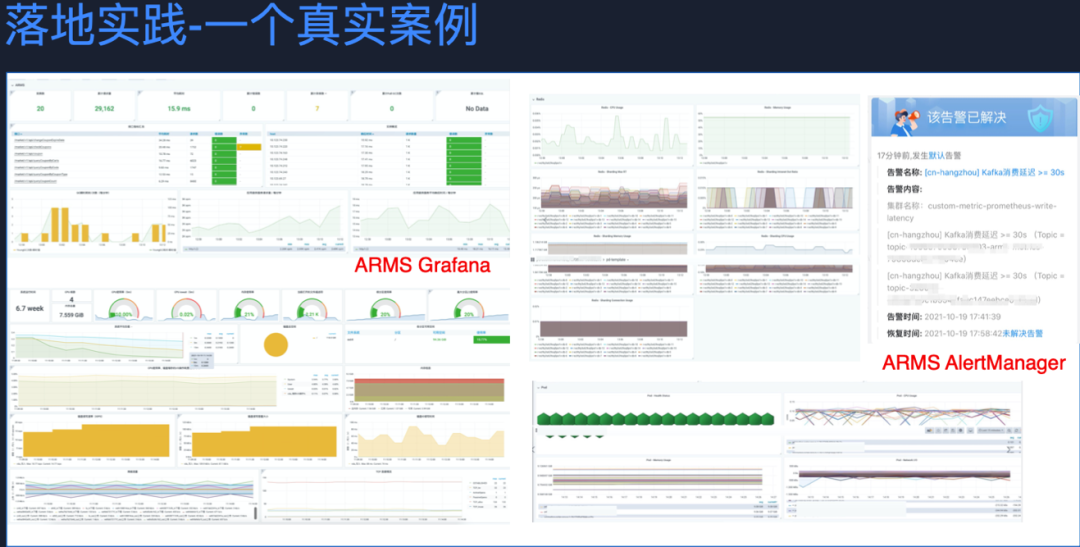
如圖,我們可以看到 Grafana 全面的展示了應用層,依賴的中間件、容器層、以及主機層的全量視圖。
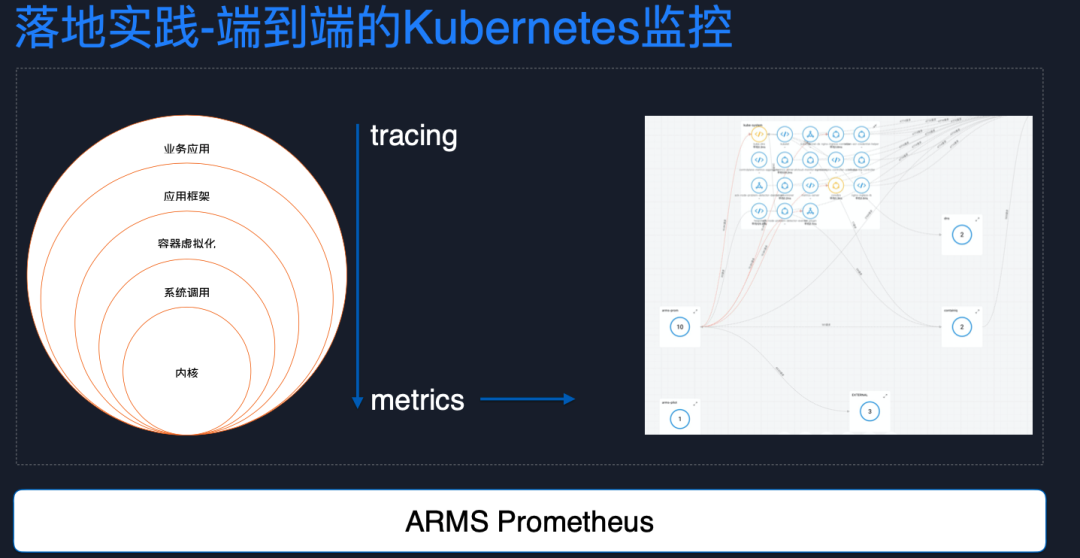
基于 Prometheus,我們還可以衍生出非常多的應用。舉個例子,Kubernetes 上的網絡拓撲是很難刻畫出來的,但基于 epbf 技術可以采集 Kubernetes 工作負載間的各種關聯關系,可以把這種關聯關系轉換成 metrics,結合 Prometheus 采集 Kubernetes 集群元信息指標,可以非常方便的刻畫出整個網絡拓撲,方便定位集群內的網絡問題。我們已經提供了相關的云產品,并且由于基于 ebpf 實現,也是多語言適用且完全無侵入的。

還有一個例子和資源使用成本相關,由于云原生架構的彈性和動態化,我們很難計量各個應用消耗了多少資源,付出多少成本。但通過 Prometheus 加上自己的賬單系統,定義好每個資源的計費,很容易去刻畫出來一個部門和各個應用的成本視圖。當應用出現資源消耗不合理時,我們還可以給出優化建議。
四、大規模落地實踐挑戰和解決方案
接下來我們討論下,落地 Prometheus 有哪些技術上的挑戰以及相應的解決方案,這其中包括:
- 多云、多租場景
- 規模化運維
- 可用性降低,MTTD 和 MTTR 時間長
- 大數據量、大時間跨度查詢性能差
- GlobalView
- 高基數問題
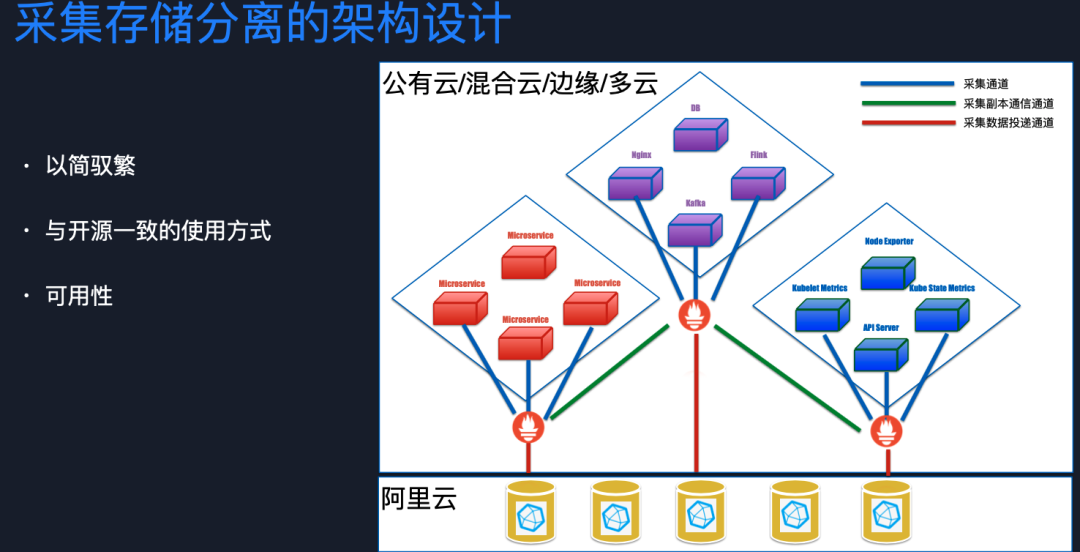
為了應對以上挑戰,我們對采集和存儲進行了分離。這樣的好處就是采集端做的盡量輕,存儲端可用性做的足夠強,這樣就可以支持公有云、混合云、邊緣或者多元環境。在分離之后,我們針對采集、存儲分別進行可用性優化,并保持與開源一致的使用方式。
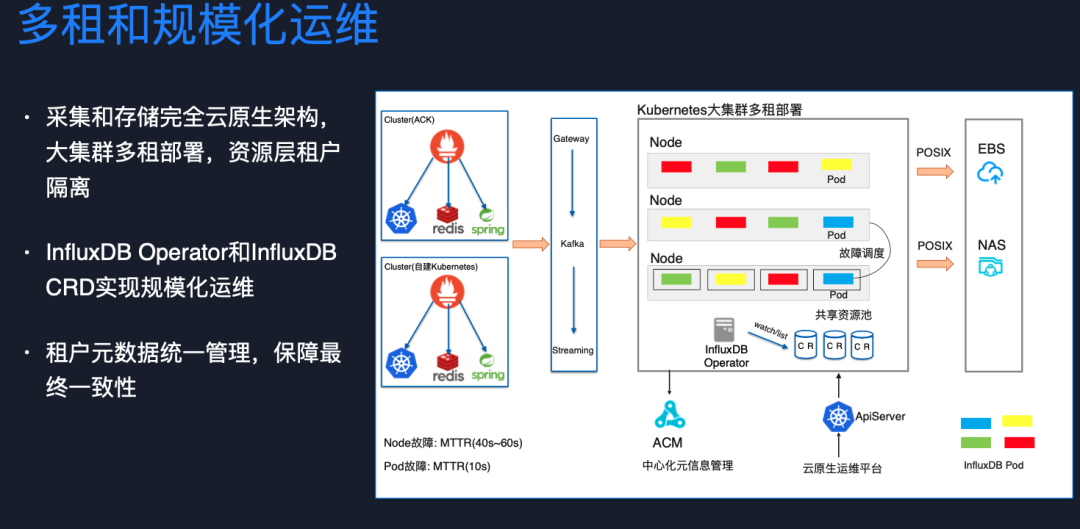
接下來,可以看到部署拓撲圖,采集端就是部署在業務方的集群里面,所以天然就是多租的,存儲端我們用超大規模 Kubernetes 集群進行多租部署,計算存儲分離,這些租戶共享資源池,在容器層物理隔離,通過云盤和 NAS 存儲索引和指標數值文件,可以保證一定彈性和單租戶水平擴容能力,同時我們對每個租戶使用的資源又有限制,避免某個租戶對資源的消耗影響到其他租戶。
最后為了解決多租問題,我們做了中心化的元信息管理,保證租戶數據的最終一致性。在進行故障調度時,可以通過中心化的元信息管理,非常方便進行故障轉移。改造之后,當 node 發生故障,在一分鐘之內就可以恢復,Pod 發生故障,10s 可以恢復。
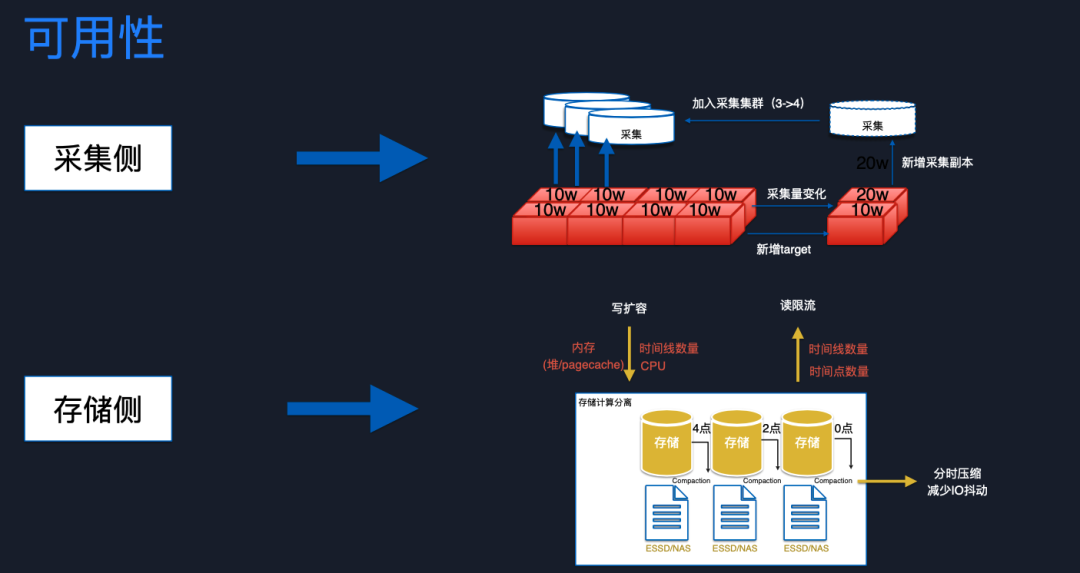
我們對采集側進行了可用性改造,因為開源 Prometheus 是一個單體應用,單副本是無法保障高可用的。我們把采集端改造成一個多副本模型,共享同樣的采集配置,根據采集量將采集目標調度到不同的副本上。當采集量發生變化或有新增的采集目標時,會計算副本的采集水位,進行動態擴容,保證采集可用性。
在存儲側,我們也做了一些可用性保障措施。在寫的時候,可以根據時間線的數量來動態擴容存儲節點,也可以根據索引所使用的 pagecache 有沒有超限來進行擴容。在讀的時候,也會根據時間線數量,還有時間點的數量進行限制,保證查詢和存儲節點的可用性。另外我們知道時序數據庫都會做壓縮,如果集中壓縮的話,IO 抖動非常厲害,所以我們做了一個調度算法把節點進行分批壓縮,這樣就可以減少抖動。
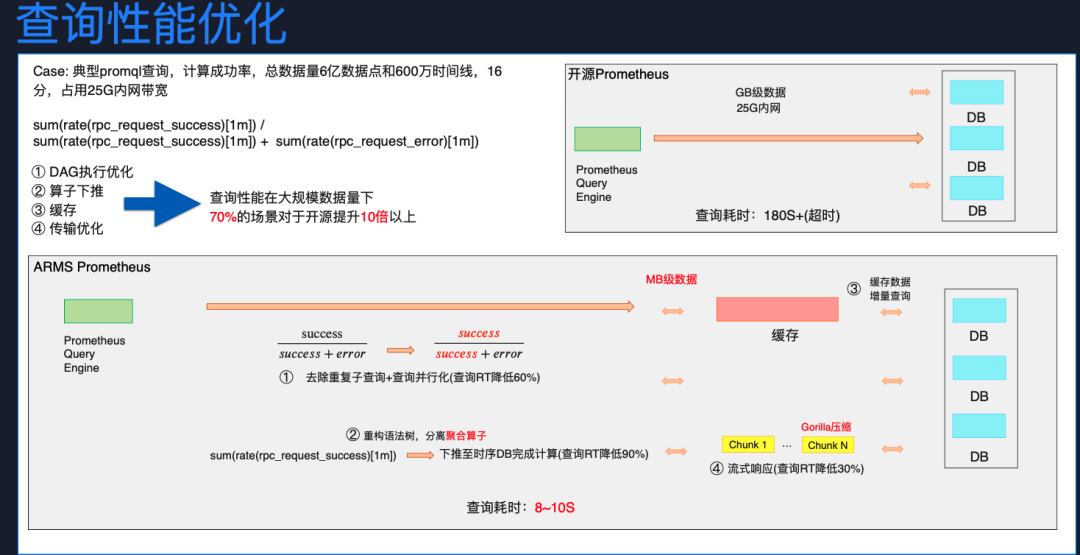
在大數據量查詢性能方面,我們可以看一個比較典型的 PromQL 查詢案例。總數據量有 6 億個時間點,600 萬個時間線。如果使用開源系統進行查詢,要占用 25G 的帶寬,查詢耗時可能是三分鐘。但我們做了一些優化,比如 DAG 執行優化,簡單講就是對執行語句進行解析,如果發現有重復的子查詢,就去重,然后并行化查詢降低 RT。
還有算子下推,將一些算子計算邏輯從查詢節點下推到存儲節點實現,可以減少原始指標數據的傳輸,大幅度降低 RT。
針對大促場景,應用開發者或 SRE 在大促之前頻繁查詢大盤,執行的 PromQL 除了起止時間有些微差別,其他都是一樣的,因此,我們做了場景化設計,將計算結果緩存,對超出起止時間緩存范圍的部分進行增量查詢。
最后通過 Gorilla 壓縮算法結合流式響應,避免批量一次性的加載到內存里面進行計算。經過優化之后,對大規模、大數據量的查詢性能優化到 8~10 秒,并對 70% 場景都可以提升 10 倍以上性能。
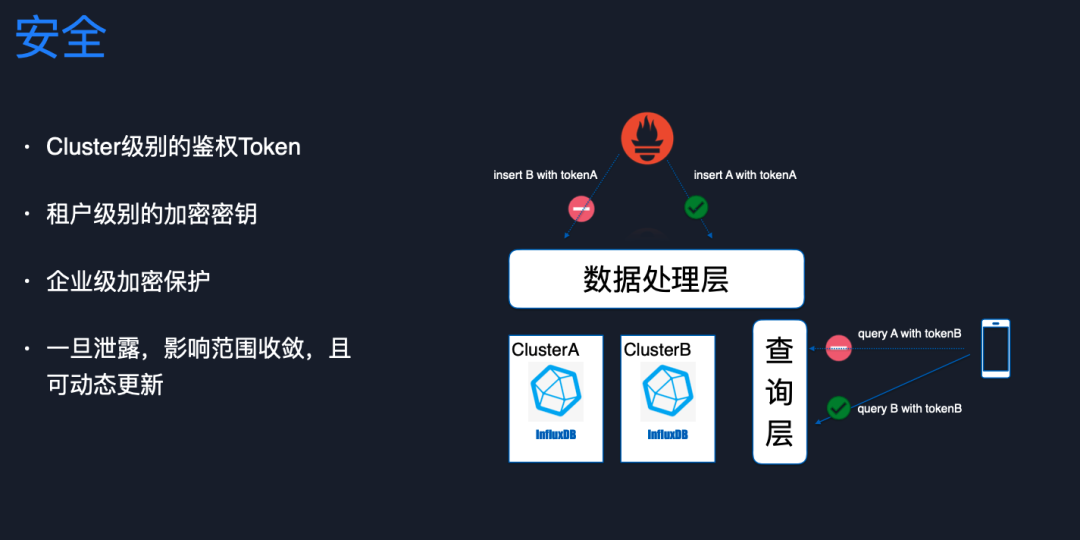
這一部分簡單聊一下安全問題。云上應用是非常注重安全的,有些指標數據比較敏感,可能不希望被無關業務方抓取到。因此,我們設計了租戶級別的鑒權機制,會對生成 Token 的密鑰進行租戶級別加密,加密流程是企業級安全的。如果出現 Token 泄露,可以收斂影響范圍到租戶級別,只需要受影響的租戶換一下加密密鑰生成新的 Token,廢棄掉舊 Token 就可以消除安全風險。
除了以上部分,我們也做了一些其他技術優化,下面簡單介紹一下。
- 高基數問題
通過預聚合,把發散指標進行收斂,在減少存儲成本的同時,一定程度上緩解高基數問題。另外我們做了全局索引的優化,將時間線索引拆分到 shard 級別,當 shard 過期之后,索引也會隨之刪除,減少了短時間跨度查詢時需要加載的時間線數量。
- 大時間跨度查詢
實現 Downsampling,犧牲一定精度來換取查詢性能與可用性。
- 采集能力
提升單副本采集能力,可以減少 agent 用戶側的資源消耗。
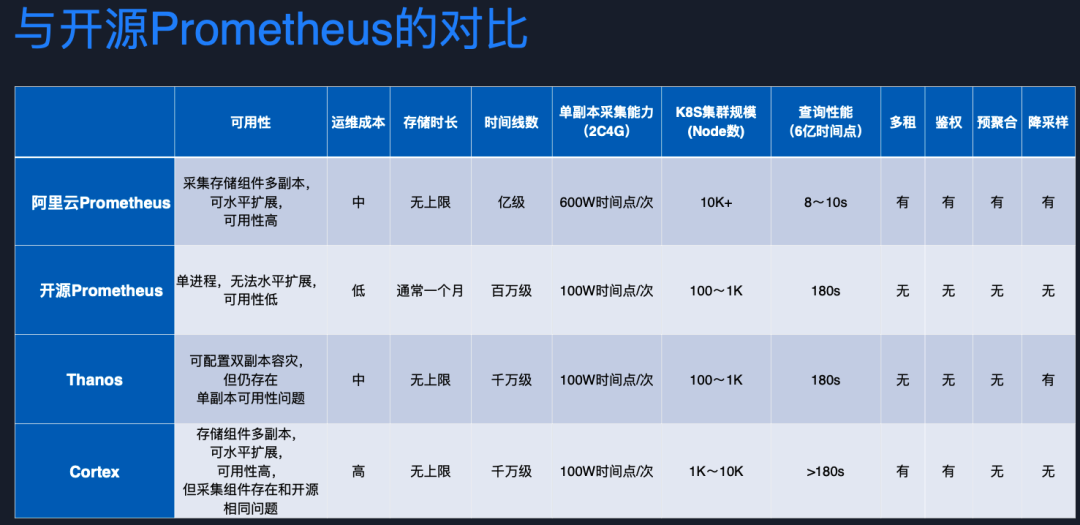
最后是阿里云 Proemtheus 監控與開源版本的對比。
在可用性方面,開源版本到了百萬級時間線,內存消耗會出現暴漲,基本上是不可用的。而且因為是單副本,如果出現一些網絡異常或者所在的宿主機出現問題,整個監控系統就是不可用的。
雖然開源的 Thanos、Cortex 做了一些可用性增強,但總體來講他們并沒有完全解決可用性問題。我們做了采集存儲架構分離,采集存儲端理論上可以無限水平擴容,可用性比較高。而且存儲時長理論上也沒有上限,而開源版本存儲一個月指標,時間線就會膨脹得非常厲害,查詢和寫入基本上都是不可用的。
五、云原生可觀測性的發展趨勢和展望
最后聊一聊云原生可觀測性的發展趨勢,個人認為將來可觀測性一定是標準化且由開源驅動的。現在整個軟件架構體系變得越來越復雜,我們要監控的對象越來越多,場景也越來越廣。封閉的單一廠商很難面面俱到的去實現全局可觀測能力,需要社區生態共同參與,用開放、標準的方法來構建云原生可觀測性。
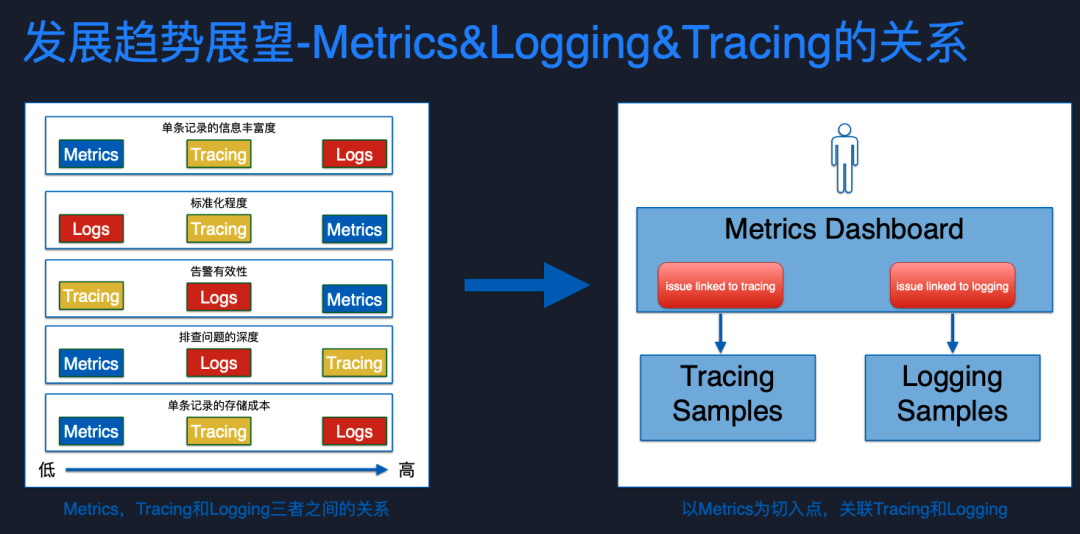
我們可以看一下 metric、log、tracing 的關系,這三者在不同維度上從低到高,各有特長。
在告警有效性上來說,metric 是最有效的,因為 metric 最能真實反映系統狀態,不會因為偶發抖動造成告警轟炸,告警平臺完全失效的問題。但在排查問題的深度上,肯定還是需要去看 tracing 和 log。另外在單條記錄存儲成本上,metric 遠低于 tracing 和 log。所以基于此,個人認為將來會以 metric 為接入點,再去關聯 tracing 和 log,tracing 和 log 只在 metric 判定系統異常時才需要采集存儲。這樣就可以既保證問題拋出的有效性,又能降低資源使用成本,這樣的形態是比較理想合理,符合未來發展趨勢的。