從「根」上找出模型的瓶頸!從第一原理出發(fā)剖析深度學(xué)習(xí)
如果想提升模型的性能,你的第一直覺是問搜索引擎嗎?
通常情況下你得到的建議只能是一些技巧性的操作,比如使用in-place operation,把梯度設(shè)置為None,或者是把PyTorch版本從1.10.1退回到穩(wěn)定版1.10.0等等。
這些臨時找到的騷操作雖然可以一時地解決當(dāng)下問題,但要是用了以后性能還沒提升到滿意的程度,那可能就有點「抓瞎」了。
雖然深度學(xué)習(xí)本身就是一個積木類的黑盒模型,但這種調(diào)試方法仿佛深度學(xué)習(xí)真的變成了煉丹術(shù),而非科學(xué)。
比如你的模型在訓(xùn)練集上的loss遠(yuǎn)遠(yuǎn)低于測試時的loss,說明模型已經(jīng)「過擬合」了,如果這個時候再盲目增大模型的參數(shù)量,那就純粹是浪費時間了。再比如模型的訓(xùn)練loss和驗證loss一樣的時候,如果再對模型加入正則化,那也是浪費時間。
所以為了讓AI從業(yè)者在遇到問題之后,能從根上解決,最近康奈爾大學(xué)人工智能(CUAI)的一位聯(lián)合創(chuàng)始人Horace He發(fā)表了一篇博客,把深度學(xué)習(xí)模型的時間損耗拆分成三部分:計算、內(nèi)存和其他開銷overhead,從「第一原理」出發(fā)來了解和改進(jìn)深度學(xué)習(xí)模型。
其中計算(Compute)指的是GPU在計算浮點操作時所消耗的時間,也就是FLOPS;內(nèi)存(Memory)指的是把tensors寫到GPU里消耗的時間。

如果模型把大部分的時間都花在了內(nèi)存?zhèn)鬏斏希敲丛黾覩PU的FLOPS是沒有用的。又或者如果你把所有的時間都花在執(zhí)行大塊的數(shù)學(xué)運算上,那么把你的模型邏輯改寫成C++來減少開銷也沒有用。

了解你所處的狀態(tài)可以讓你縮小優(yōu)化的范圍,節(jié)省下來的時間就可以愉快地摸魚了。
計算
通常深度學(xué)習(xí)模型運算速度不夠快的原因都是顯卡性能不夠,加卡解千愁啊!
但現(xiàn)實很骨感,越強(qiáng)的卡,價格也更美麗。所以為了錢花的更值,需要盡可能地提升顯卡的運行效率,不斷地讓顯卡進(jìn)行矩陣運行。
并且計算比內(nèi)存帶寬更重要的原因還有一個,就是模型訓(xùn)練過程中所需的計算量不管通過何種手段,基本都不會降低,所以最大限度提升計算能力才能提升效率。
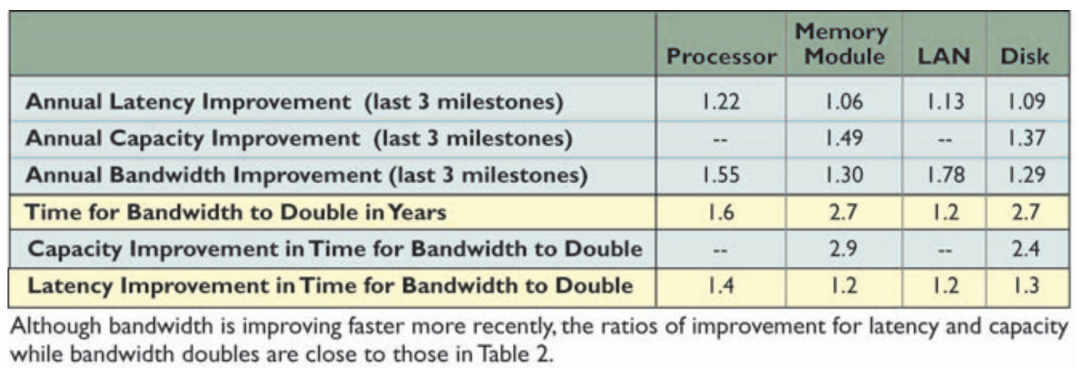
但計算量如果增長速度過快,也會加劇最大化計算利用率的難度。就拿這個關(guān)于CPU FLOPS翻倍時間與內(nèi)存帶寬翻倍時間的表格來說。
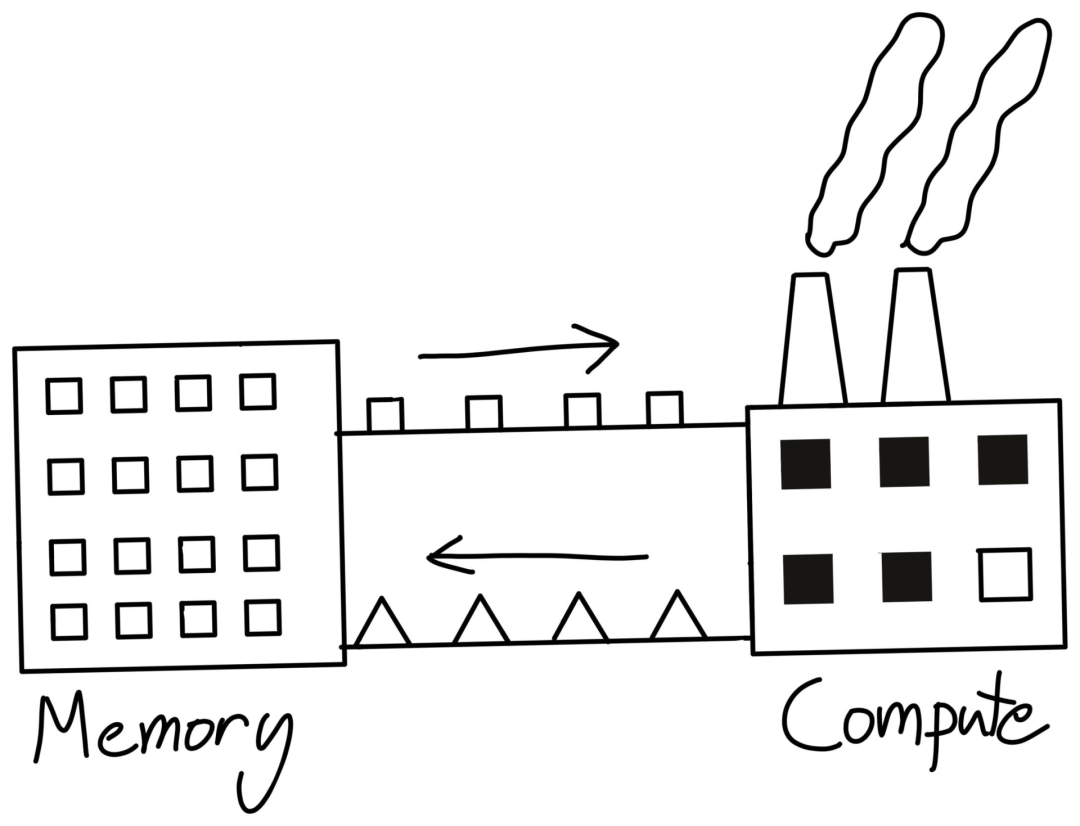
一種思考計算的方式是把CPU當(dāng)作一個工廠。用戶向工廠發(fā)送指令(開銷)和原材料(內(nèi)存帶寬),所有這些都是為了保持工廠高效運行(計算)。
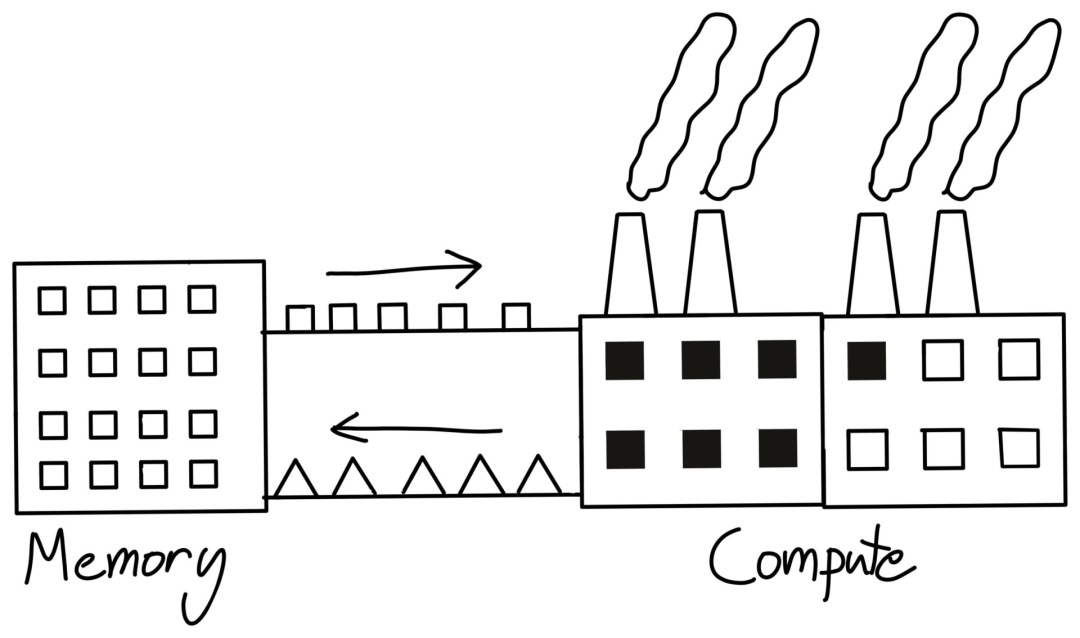
如果工廠提高效率的速度超過了為其提供原材料的速度,那么工廠就更難達(dá)到其峰值效率。即使工廠的規(guī)模(FLOPS)增加了一倍,如果帶寬不能同步提升,那性能也不會增加一倍。
關(guān)于FLOPS還有一個補(bǔ)充。現(xiàn)代機(jī)器學(xué)習(xí)加速硬件都有專門用于矩陣乘法的硬件,比如Nvidia的Tensor Cores。
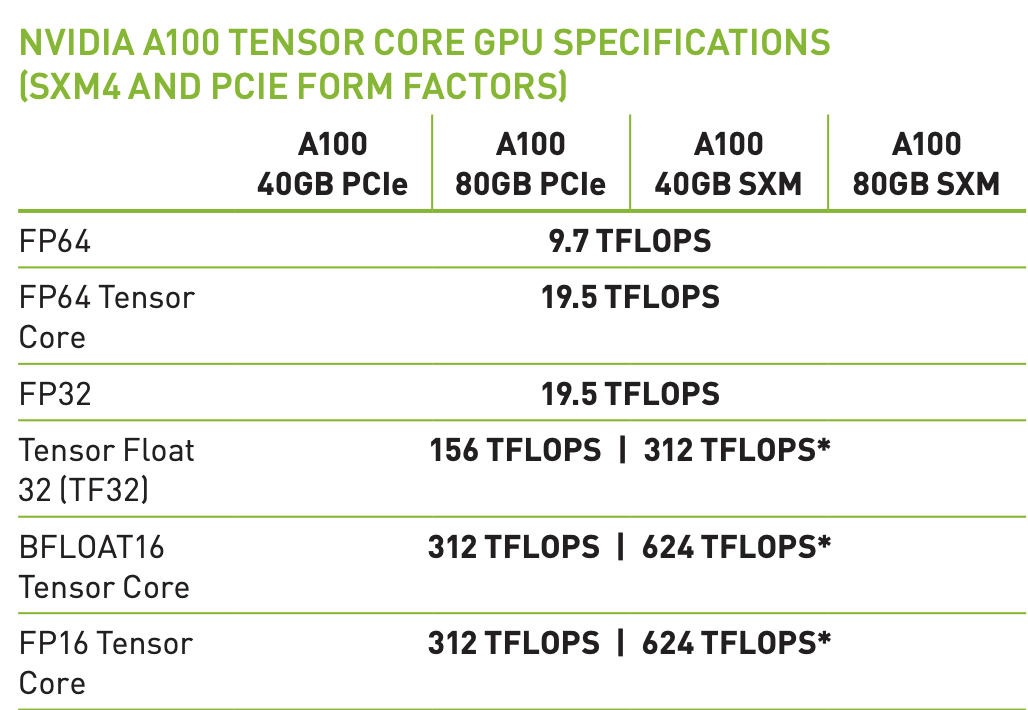
也就是說,如果你不做矩陣乘法,你就只能獲得19.5 teraflops,而非宣傳的312。并且這并非是GPU所獨有的缺陷,TPU甚至比GPU更不通用。
事實上,GPU在所有非矩陣乘法的操作上都很慢,乍一看可能影響很大,但實際上神經(jīng)網(wǎng)絡(luò)模型里基本都是矩陣乘法。
在一篇關(guān)于BERT模型的flop研究中可以發(fā)現(xiàn),BERT中99.8%都是矩陣乘法(Tensor Contraction)操作,所以雖然非矩陣乘法的速度要慢15倍,但也無傷大雅。
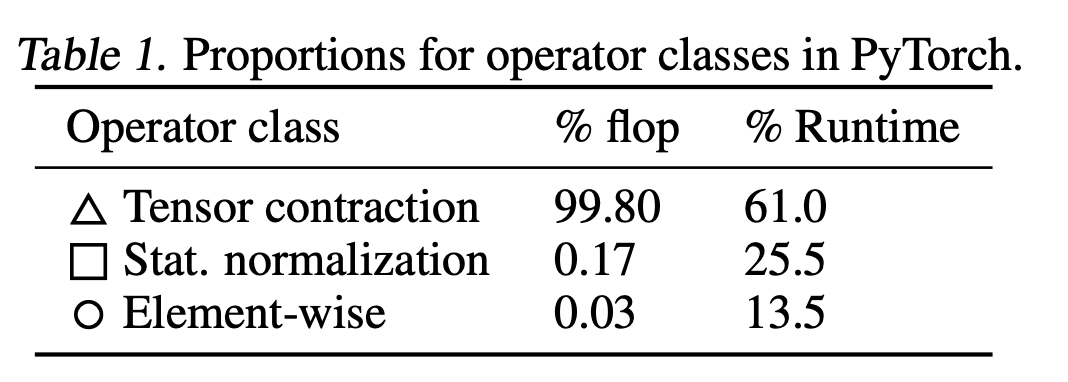
但在這種情況下,歸一化和點式運算實際上比矩陣乘法運算少了250倍的FLOPS和700倍的FLOPS。
至于為什么非矩陣乘法的理論性能和現(xiàn)實相差這么多,研究人員給出的答案是:內(nèi)存帶寬(memory bandwidth)。
內(nèi)存
帶寬成本本質(zhì)上是將數(shù)據(jù)從一個地方移動到另一個地方所支付的成本,包括將數(shù)據(jù)從CPU轉(zhuǎn)移到GPU,從一個節(jié)點轉(zhuǎn)移到另一個節(jié)點,二者通常稱為「數(shù)據(jù)傳輸成本」和「網(wǎng)絡(luò)成本」。
深度學(xué)習(xí)模型優(yōu)化關(guān)注的帶寬成本主要是從CUDA全局內(nèi)存轉(zhuǎn)移到CUDA共享內(nèi)存。
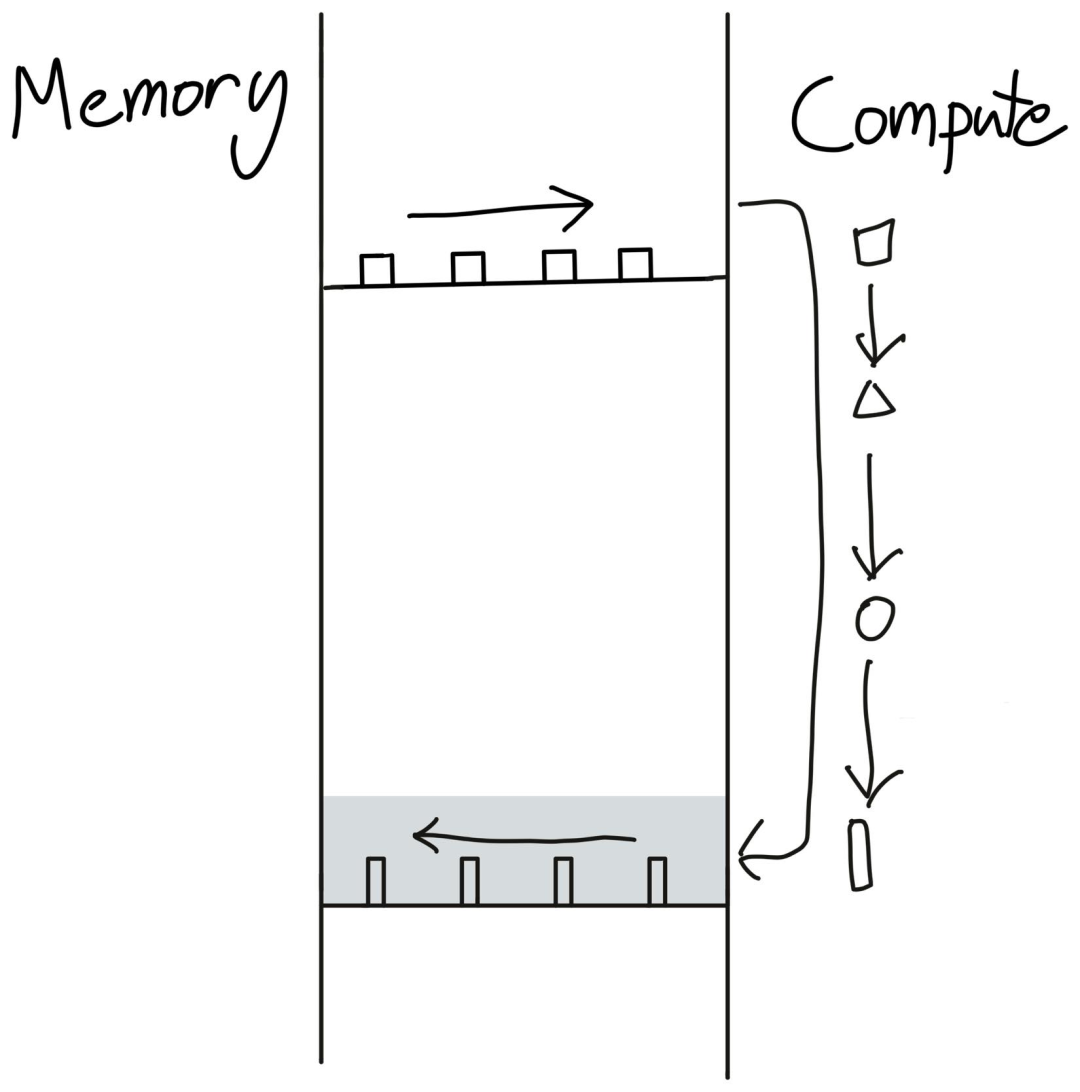
回到工廠那個例子,雖然工廠可以完成一些計算任務(wù),但它并不是一個適合存儲大量數(shù)據(jù)的地方。典型的做法是利用更便宜的硬件來建立一個數(shù)據(jù)倉庫(DRAM),然后在倉庫和工廠之間運送物資,也就是內(nèi)存帶寬。
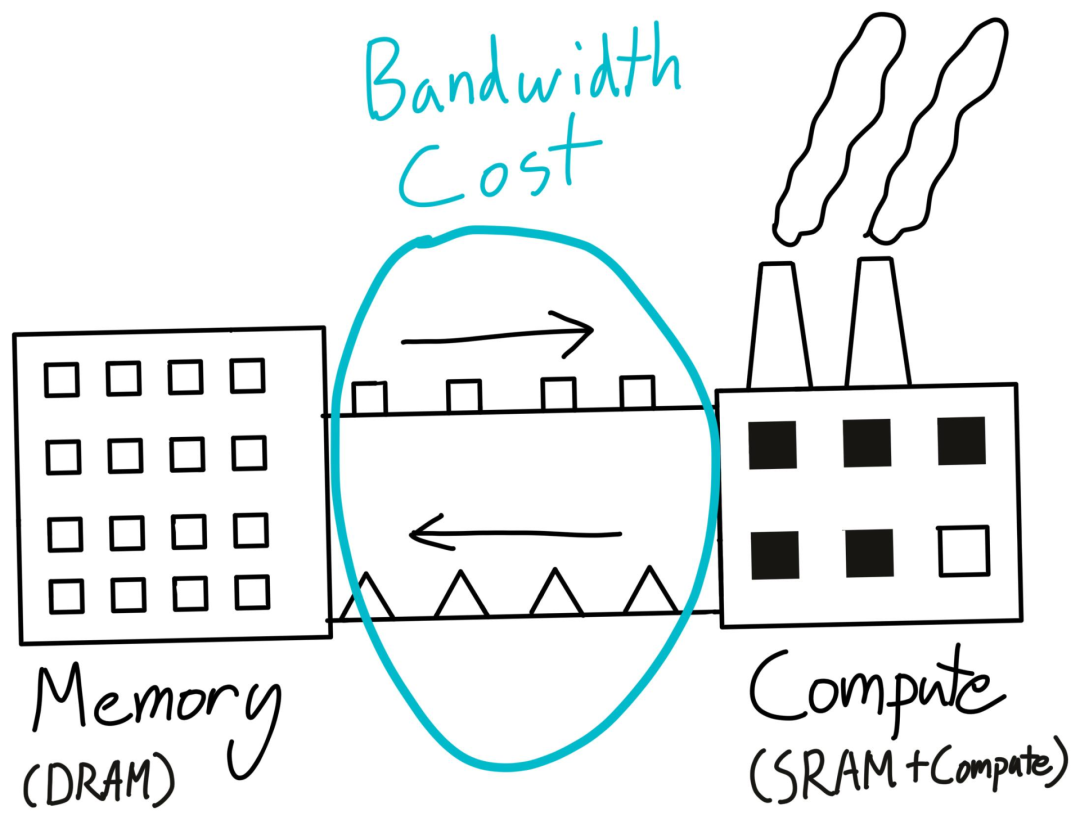
GPU的DRAM大小可以通過nvidia-smi命令獲得,倉庫容量不夠也是導(dǎo)致CUDA Out of Memory錯誤的主要原因。
需要注意的是,每次執(zhí)行GPU內(nèi)核時,都需要將數(shù)據(jù)從GPU的DRAM移出和移回。
現(xiàn)在我們就知道執(zhí)行torch.cos這樣的單個操作時,幾乎每做一次這樣的簡單運算,數(shù)據(jù)都需要從內(nèi)存運到GPU里,運送成本比計算成本要高很多,所以時間幾乎都花在內(nèi)存上了,這種情況也稱為memory-bound operation。
錯誤的做法就是每次都把數(shù)據(jù)送到GPU計算后返回結(jié)果,再把結(jié)果送給GPU再次計算,可以看到,大量的時間都耗費在數(shù)據(jù)傳輸上了。
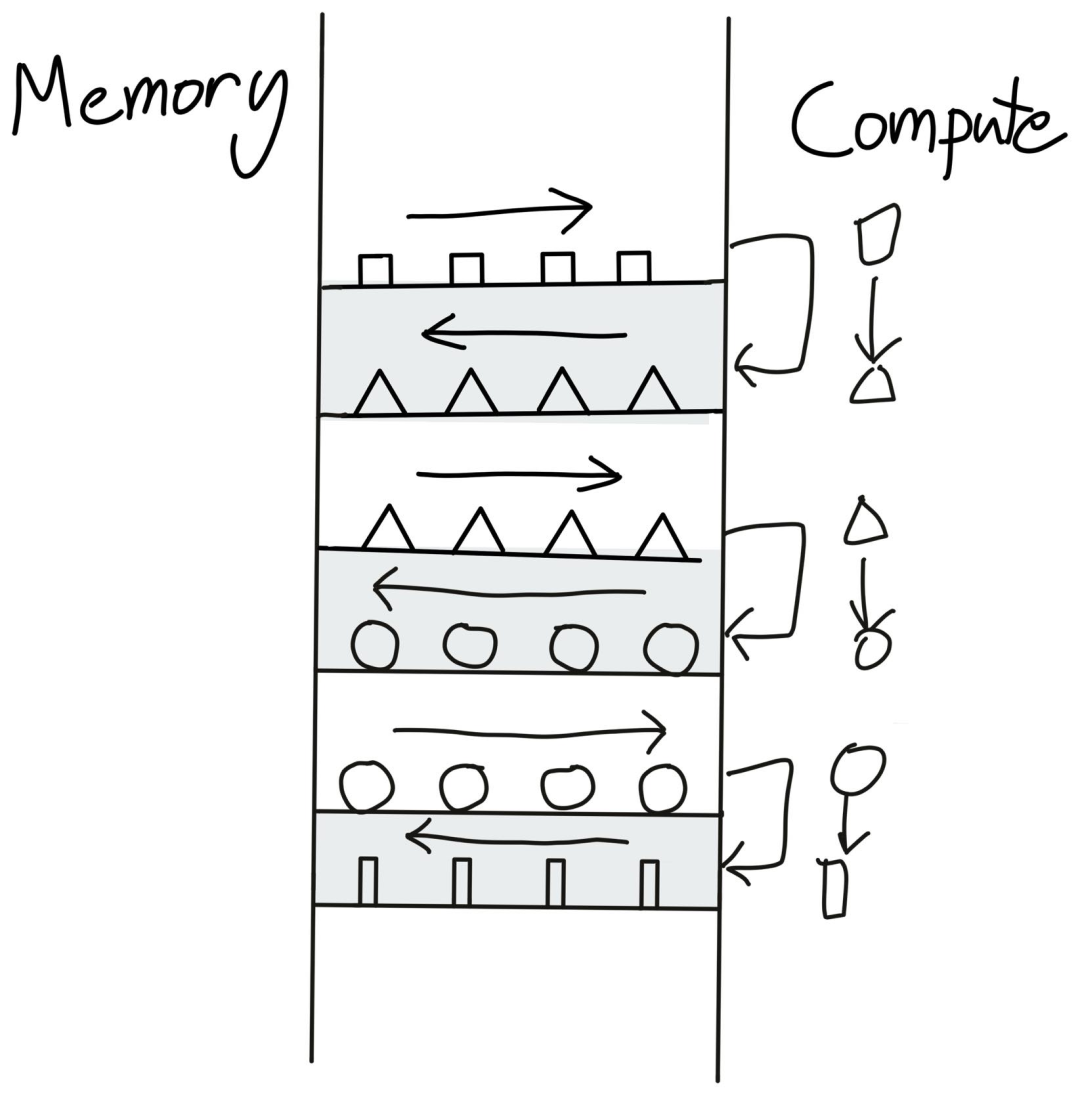
稍作調(diào)整之后,當(dāng)預(yù)先把指令都放入計算時,內(nèi)存的傳輸降為一次即可完成相同的任務(wù)。
如果換成pyTorch的代碼就是把兩行代碼轉(zhuǎn)為一行x.cos().cos(),效率能夠提升兩倍。

不過這種優(yōu)化措施并不是在所有場景下都適用。因為GPU預(yù)先需要知道所有執(zhí)行的指令,并生成CUDA代碼,所以無法在eager-mode下使用。而且并非所有的運算符融合都像pointwise操作符這么簡單。
如果你曾經(jīng)寫過CUDA內(nèi)核代碼的話,就可以知道任何兩個PyTorch都有機(jī)會進(jìn)行融合來節(jié)省全局內(nèi)存的讀寫成本。現(xiàn)有的編譯器如NVFuser和XLA通常只能進(jìn)行一些簡單的融合,肯定比不上AI工程師的設(shè)計。如果你想嘗試自己編寫一些定制的CUDA內(nèi)核,Triton就比較適合新手入門。
運算符融合的效果就是更多的操作,時間成本相同,這也是為什么激活函數(shù)的計算成本幾乎都是一樣的,盡管gelu顯然比relu多了很多操作。
當(dāng)需要推理你的操作是否有內(nèi)存帶寬限制時,calculator可以發(fā)揮很大的作用。
對于簡單的算子來說,可以直接推理內(nèi)存帶寬。例如,A100有1.5T字節(jié)/秒的全局內(nèi)存帶寬,可以進(jìn)行19.5T FLOPS的計算。因此,如果你使用32位浮點(即4個字節(jié)),GPU可以執(zhí)行20萬億次操作的相同時間內(nèi)加載4000億個數(shù)字。此外,為了執(zhí)行一個簡單的單項運算(如把一個tensor乘2),實際上需要將tensor寫回全局內(nèi)存。所以將單項運算做了大約一百次以后,才能夠等到內(nèi)存數(shù)據(jù)送進(jìn)來。
在像NVFuser這樣的融合編譯器的幫助下,實際上可以很容易地測量成本。
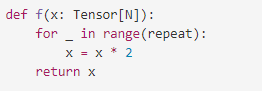
以一個PyTorch函數(shù)為例,并用融合編譯器對其進(jìn)行基準(zhǔn)測試,然后就可以計算出不同的重復(fù)值所達(dá)到的FLOPS和內(nèi)存帶寬。
增加重復(fù)次數(shù)是在不增加內(nèi)存訪問的情況下增加計算量的一個簡單方法,這也被稱為增加計算強(qiáng)度。
因為tensor的大小為N,需要將執(zhí)行2*N次內(nèi)存訪問,以及N*repeat FLOP。因此,實現(xiàn)的內(nèi)存帶寬將是byte_per_elem * 2 * N / itrs_per_second,而實現(xiàn)的FLOPS將是N * repeat / itrs_per_second。
把運行時間、flops和實現(xiàn)的內(nèi)存帶寬取對數(shù)后繪制出來的結(jié)果可以看到,執(zhí)行64次乘法之前,運行時間并沒有明顯的增加。這也意味著,在這之前,內(nèi)存帶寬是有限的,計算大部分是閑置的。
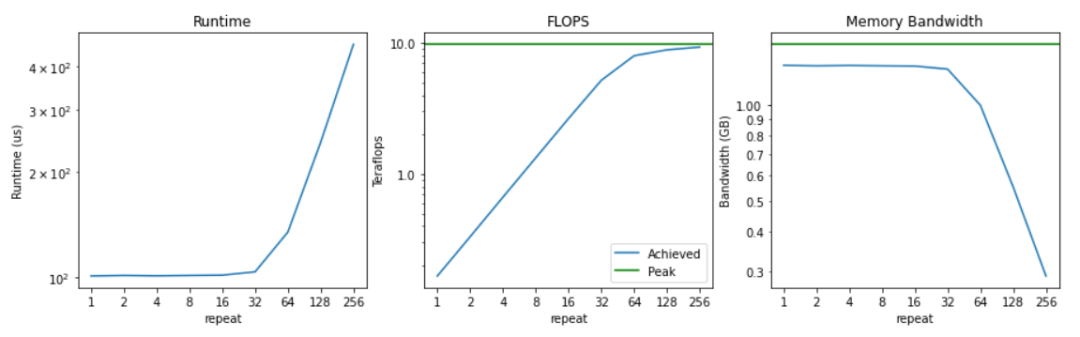
因此,一開始只實現(xiàn)了0.2 teraflops。當(dāng)我們把計算強(qiáng)度提高一倍時,這個數(shù)字就會線性增長,直到我們接近9.75 teraflops的峰值,也就是「計算極限」。
內(nèi)存帶寬開始時接近峰值,隨著計算強(qiáng)度的增加,開始下降。這也符合預(yù)期,因為實際上更多的時間花在了實際的計算上,而非訪問內(nèi)存。
在這種情況下可以很容易看到什么時候是計算約束,什么時候是內(nèi)存約束。
對于重復(fù)次數(shù)小于32次時,內(nèi)存帶寬已經(jīng)飽和,而計算能力卻沒有得到充分利用。相反,一旦重復(fù)大于64次,會發(fā)現(xiàn)計算量已經(jīng)飽和(即達(dá)到接近峰值FLOPS),而內(nèi)存帶寬利用率開始下降。
對于更大的系統(tǒng),通常很難說是計算約束還是內(nèi)存帶寬約束,因為可能同時包含了計算約束和內(nèi)存約束。
衡量計算約束程度的一個常見方法是,將你實現(xiàn)的FLOPS作為峰值FLOPS的一個百分比作為指標(biāo)。如果實現(xiàn)了峰值FLOPS的80%,那就說明計算資源利用的比較充分,其余的時間可能是花在內(nèi)存帶寬上了。
其他開銷
代碼中沒有花在傳輸或計算tensor的時間都稱為開銷(overhead),比如花在Python解釋器上的時間,花在PyTorch框架上的時間,花在啟動CUDA內(nèi)核(但不執(zhí)行)的時間都是開銷。
開銷之所以成為一個問題,主要原因是現(xiàn)代GPU的速度非常快。一個A100可以每秒進(jìn)行312萬億次的浮點運算(312 TeraFLOPS)。相比之下,Python的運行速度就相當(dāng)慢了,一秒鐘內(nèi)只能進(jìn)行3200萬次加法運算。
這也意味著,在Python可以執(zhí)行一個FLOP的時間里,A100可以運行975萬FLOPS。
像PyTorch這樣的框架在進(jìn)入實際內(nèi)核之前也有很多層調(diào)度。如果你用PyTorch做同樣的實驗,每秒只能得到28萬次操作。當(dāng)然,執(zhí)行小tensor并不是建立PyTorch的目的,但是如果確實在科學(xué)計算中使用小tensor,你就會發(fā)現(xiàn)PyTorch與C++相比慢得驚人。
一個更直觀的圖可以看到,PyTorch執(zhí)行一個加法時產(chǎn)生的配置文件,除了一個小方塊外,其余所有的都是純開銷。
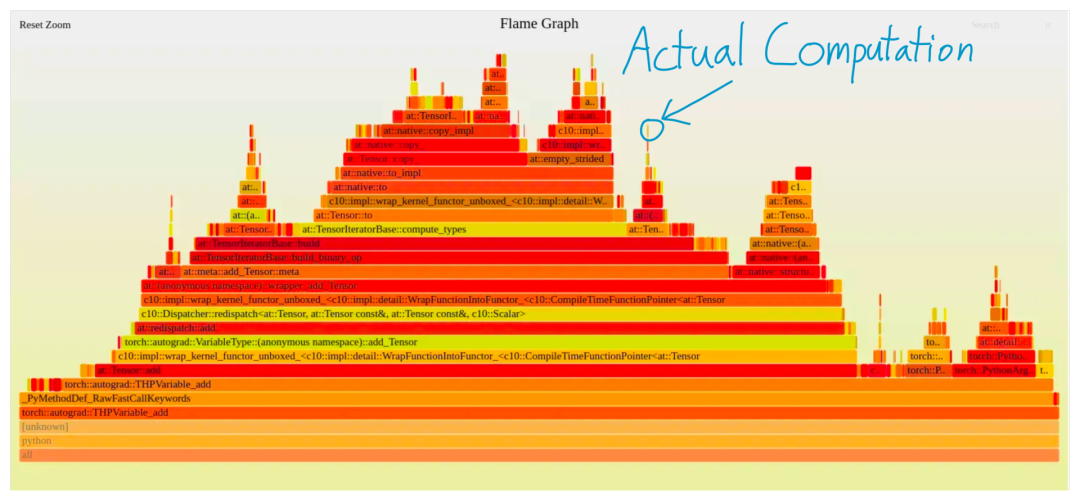
現(xiàn)代深度學(xué)習(xí)模型通常都在進(jìn)行大規(guī)模的計算操作,并且像PyTorch這樣的框架是異步執(zhí)行的。也就是說,當(dāng)PyTorch正在運行一個CUDA內(nèi)核時,它可以繼續(xù)運行并在后面排起更多的CUDA內(nèi)核。因此,只要PyTorch能夠「提前」運行CUDA內(nèi)核,大部分的框架開銷就會被完全隱藏起來
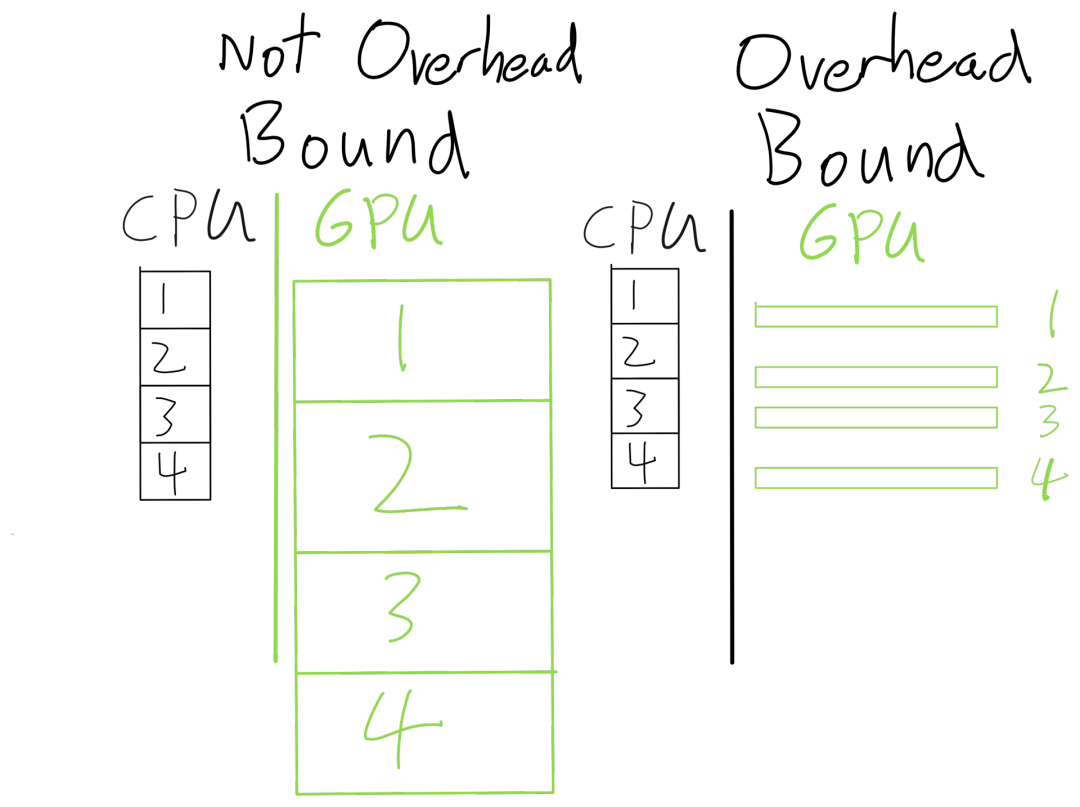
由于開銷通常不隨問題的大小而變化(計算和內(nèi)存則成比例增加),一個簡單的判斷方法是你的batch size規(guī)模增加一倍,但運行時間只增加了10%(預(yù)期是增加一倍的運行時間),那么就很可能是開銷過大了。
另一種方法是使用PyTorch profiler。粉色線條顯示了CPU內(nèi)核與GPU內(nèi)核的匹配情況。當(dāng)GPU在等待CPU的開銷時,就有很多空隙。
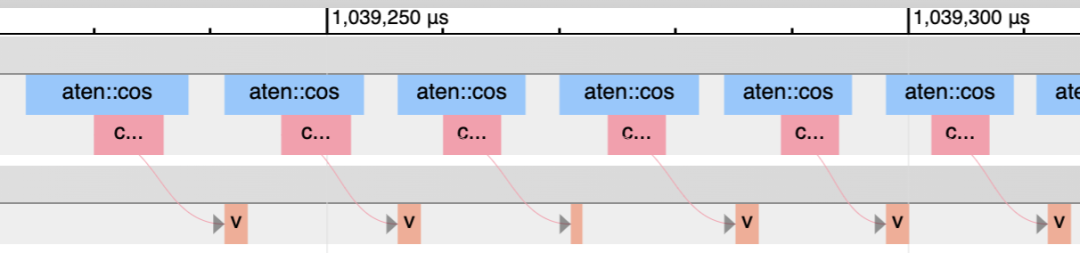
CPU比GPU運行得更快時空隙就少很多。

nvidia-smi中的GPU-Util就是在測量實際運行GPU內(nèi)核的百分比,這也是一種衡量開銷的好方法。
開銷大部分都來自PyTorch等框架的靈活性,需要花費大量時間來「弄清該做什么」
比如當(dāng)執(zhí)行a+b時,需要三個步驟:
1. Python 需要查找 __add__ 在 a 上派發(fā)的內(nèi)容
2. PyTorch需要確定張量的許多屬性(如dtype、device以及是否需要Augrad)以確定調(diào)用哪個內(nèi)核
3. PyTorch需要實際啟動內(nèi)核
每步都需要靈活性來支持不同操作,解決靈活性的一個方法是追蹤,比如用jit.tract, FX或jax.jit,或者用CUDA Graphs在更低的層次實現(xiàn)。
提升模型效率,最重要的就是了解模型的性能瓶頸。
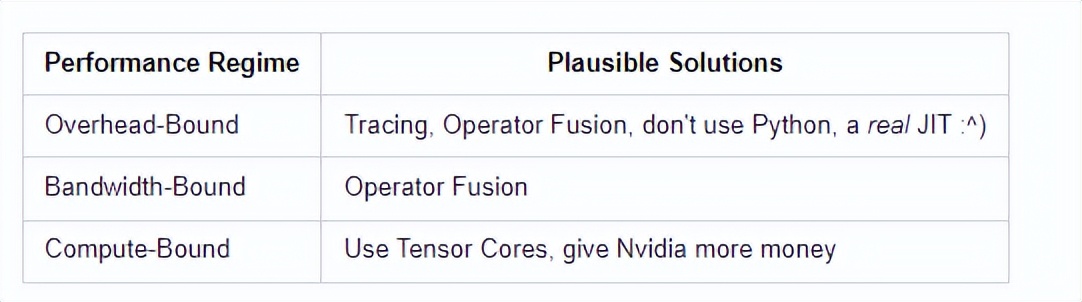
當(dāng)然了,編寫一個神經(jīng)網(wǎng)絡(luò)模型還需要考慮這么多開銷問題,也可以說是這些系統(tǒng)、框架設(shè)計上的失敗,因為這些本來應(yīng)該是對用戶透明的。
但懂得這些基本原理肯定是有意義的,可以幫助你從「根」上解決性能瓶頸。