如何在幾分鐘內搭建一個可擴展并且高可用的GraphQL API
譯文譯者 | 譚劍
審校 | 孫淑娟 梁策
對于云原生的應用來說,一個現代化的GraphQL API層需要具備兩個特征:水平可擴展性以及高可用性。
比如說,給一臺運行API層的現有機器設備增加更多的CPU、內存和其他資源,這是垂直擴展性。而水平擴展性會為你的API基礎設施添加更多的機器設備。
垂直擴展性主要是為了實現某種特定的擴展,而一個具備水平擴展性的API層可以發揮超越單臺機器的容積能力。
當談到高可用性的時候,GraphQL層需要無差錯地持續運轉(甚至在一些超出我們可控范圍的突發情況中)。這是判斷一個系統是否具備99.999%高可用特征的最佳考核指標。
這篇文章將為你介紹:如何使用一個基礎數據庫在幾分鐘內迅速搭建一個跨越同一個公共云片區的多個可用區域的GraphQL層。
最終的解決方案將會橫跨多個可用區域,并且可以經受區域級別的故障,以及水平地擴展。
下面我們拿AWS、Hasura云,以及Yugabyte云作為參考平臺來做案例演示。
跨多個可用區域來部署YugabyteDB
就從數據庫層開始吧,我們選擇??YugabyteDB??——一個開源的分布式SQL數據庫。
對于可擴展性和可快速恢復的API來說,它是一個理想的支撐服務。
YugabyteDB同時也是符合PostgreSQL語法習慣的一個數據庫。這意味著我們不需要學習另外一門SQL方言或者從零開始地重寫現有的應用。
那么需要花費多少時間來部署一個有彈性、跨多區域的YugabyteDB集群呢?
這要看情況而定,但如果你像我一樣懶,或者更傾向于直接使用云原生服務的話,那么Yugabyte云將會是完成這項任務的最簡單的方式:
1.對于初學者來說,創建或者注冊你的Yugabyte云賬號。
2.然后,準備一個多節點的跨越若干個可用區域的YugabyteDB集群:
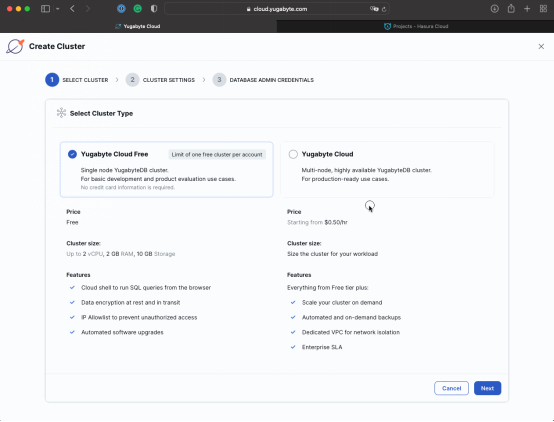
a. 選用一個自定義的集群名字,比如 multi-zone-cluster,把集群服務安放在離你最近的AWS片區(對我來說,N.Virginia - us-east-1是最近的),然后確保把Fault Tolerance這項參數設置為Availability Zone Level。
b. 點擊Download credentials下載證書。然后點擊"Create Cluster"(創建集群)。
那我們怎么利用YugabyteDB來實現高可用呢?
這個集群有三個節點,部署在三個可用區域的其中一個里面。備份因子同樣已設置為3。
這意味著每一個節點(而實際上是在每個區域)都會維護著一份數據記錄的拷貝。在我的例子中,分別位于us-east-1b、us-east-1c、以及us-east-1a等可用區域里都分別有一個節點:
節點
YugabyteDB是基于Raft一致性協議的。因此,按當前已有三個節點的配置,我們可以釋放為一個節點(或者說,一個可用區間——只要在每個片區都有一個節點),這個節點仍然是可運行的。
為什么YugabyteDB不選擇只用一個節點來處理請求服務呢?
依據CAP定理(又稱作布魯爾定理),YugabyteDB??是一個遵循一致性和分區容錯性(CP)的數據庫??。
下面的公式定義了容錯變量K和備份因子RF之前的依賴關系:
RF=(2k + 1)
在我的例子中,K=1(意思是,集群可以釋放為1個節點),而因此,RF結果為3(3份數據拷貝)。
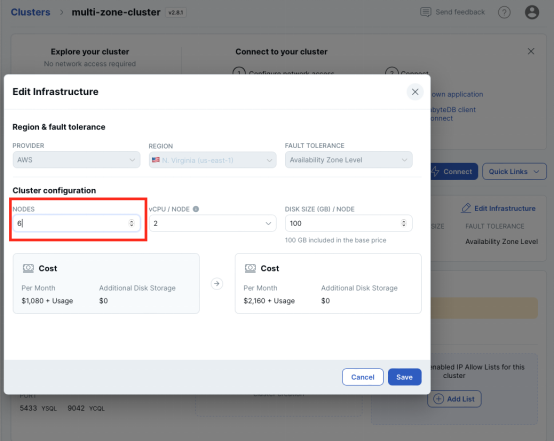
問題來了,如果數據庫需要處理100倍的查詢次數或者存儲更多的數據,那我們怎么樣利用YugabyteDB來完成水平擴展呢?只需要在集群的Setting界面添加更多的節點到基礎設施里。
打造一個可擴展以及富有彈性的 Hasura GraphQL層
Hasura 是一個高級的GraphQL服務器,它基于符合PostgreSQL方言的數據庫(比如YugabyteDB),提供了快速實時的GraphQL API。
Hasura有一個完全可管理的云版本。創建一個Hasura項目,具有水平擴展性和高可用性,開箱即用:
- 創建或登錄你的Hasura Cloud賬號;
- 創建一個Standard Tier項目:
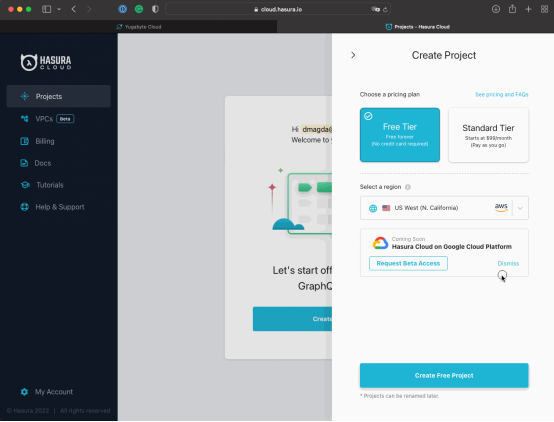
- 選擇一個AWS片區,類似部署YugabyteDB那樣——在我的例子中,是US East (N. Virginia)。
- 點擊Create Project按鈕,繼續部署操作。
就像我們所看到的,Hasura沒有任何與擴展性或區域級別可用性相關的設置。那么,在可能發生區域故障或者哪天有必要做水平擴展的時候,我們如何確定API層能夠繼續保持可運行呢?
實際上,只要我們選擇了Standard Tier,這兩個特性就都會有的。這就是Hasura在文檔所說的:
- 水平擴展:??Hasura Cloud能夠自動地擴展你的應用??而不用去考慮實例的數量、內核、內存或者閾值。你可以保持增加并發用戶的數量以及API的調用次數,同時,Hasura Cloud將會自動幫你實現優化。
- **高可用:**Hasura的多實例可以運行于graphql引擎。??在Hasura Cloud里,自動化的擴展處理以及支持運行所必需的基礎設施,都會被安排妥當,不需要人工干預。??
把Hasura鏈接到YugabyteDB
到目前為止,我們已經部署了一個Hasura GraphQL層和YugabyteDB集群,可以支撐水平擴展以及區域級別的突發故障了。剩下要做的,就是把這兩個組件連接起來,為我們的應用提供一個最終解決方案。
把Hasura添加到YugabyteDB白名單里
YugabyteDB集群實例要求我們設定所訪問數據庫的應用IP地址。對我們的Hasura實例來說這并不難。
把Hasura Cloud IP添加到Yugabyte Cloud終端的Allow IP List里:
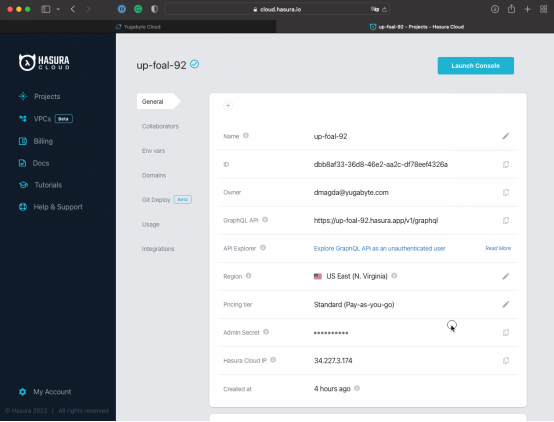
- 從你的Hasura項目界面里復制Hasura Cloud IP。
- 轉到YugabyteDB Cloud,把IP添加到IP Allow List里。
建立連接
在授權Hasura訪問YugabyteDB實例后,我們需要在兩個服務之間建立連接。這需要兩個步驟:
1. 打開Yugabyte Cloud,然后復制一個鏈接URL:
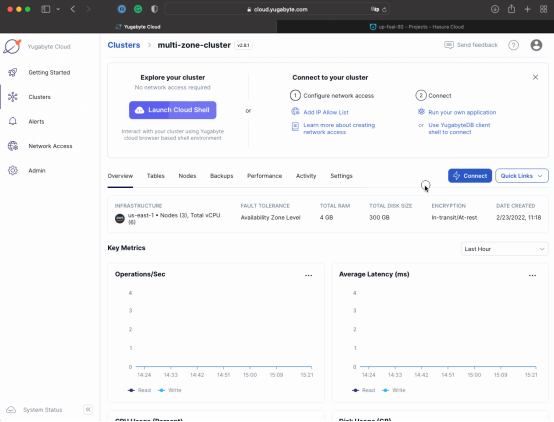
- 點擊Connect按鈕,選擇Connect to your Application選項。
- 勾選Optimize。
- 復制鏈接YSQL(Yugabyte SQL)的唯一URL。
- 確保使用之前從YugabyteDB集群部署那個步驟下載的證書里面的信息,替換掉數據庫用戶和密碼。
3. 轉到Hasura云,與YugabyteDB建立一個連接:
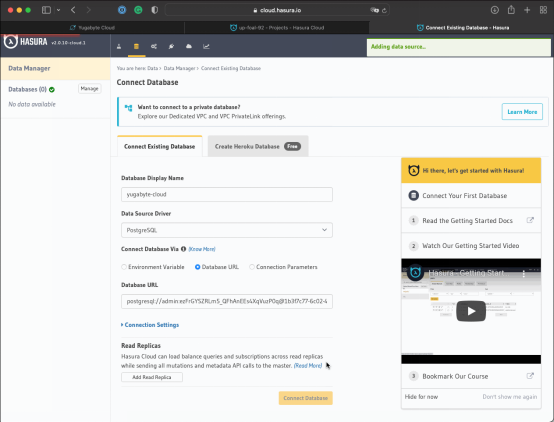
- 點擊Launch Console按鈕,跳轉到Data & Schema 管理界面。
- 填寫YugabyteDB鏈接參數,建立一個鏈接。
- 點擊Connect Database按鈕,建立鏈接。
我們剛剛已經完成一個Graphql API層的搭建,它可以支撐區域級別的故障以及水平擴展能力。現在,我們用一些樣例數據和請求來做一個健全性測試。
創建一個樣例數據庫
按照以下的步驟,在YugabyteDB里創建用戶表和消息表:
1. 在YugabyteDB Cloud終端里,點擊Launch the Cloud Shell。
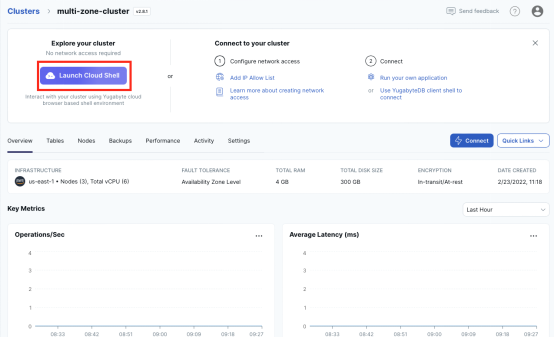
2. 創建用戶表Users和消息表Messages:
3. SQL:
CREATE SEQUENCE users_pk_seq CACHE 100;
CREATE SEQUENCE messages_pk_seq CACHE 100;
CREATE TABLE Users (
id int NOT NULL DEFAULT nextval('users_pk_seq'),
name text,
age int,
city text,
PRIMARY KEY(id));
CREATE TABLE Messages (
id int NOT NULL DEFAULT nextval('messages_pk_seq'),
sender_id int REFERENCES Users(id),
recipient_id int REFERENCES Users(id),
payload text,
PRIMARY KEY (id)
);
4.最后,初始化用戶表,創建兩條記錄:
SQL:
INSERT INTO USERS (name, age, city) VALUES
('John', 35, 'Austin'),
('Mark', 36, 'Seattle');
用GraphQL來查詢數據
往YugabyteDB里載入樣例數據庫后,我們可以體驗到Hasura提供的GraphQL API層帶來的便利。
把數據表暴露到GraphQL層
即使Hasura自動檢測數據庫端的結構更改,我們仍然需要明確指定哪些表可以通過GraphQL API查詢:
1. 在Hasura Console里打開Data & Schema Management。
2. 點擊Track All按鈕,通過YugabyteDB API展示出兩個數據表:
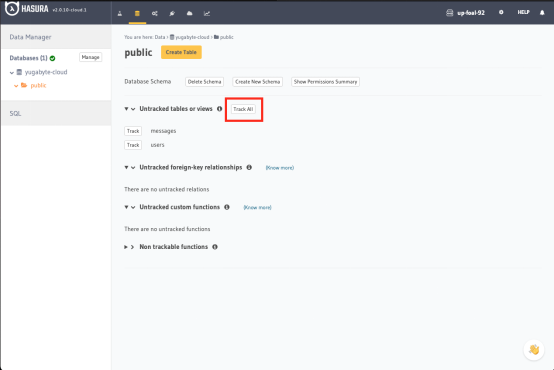
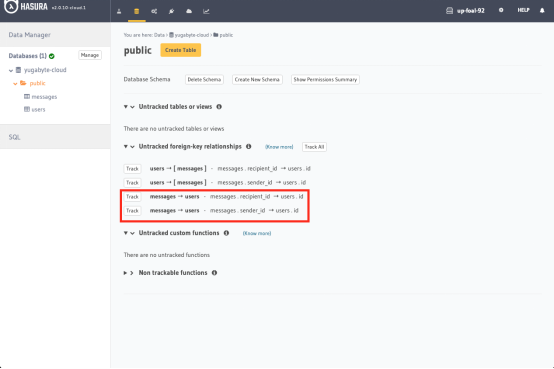
3. 最后,點擊Track按鈕,建立從message表到users表的外鍵關聯關系:
查詢數據
下一步,我們來用GraphQL讀取用戶表里面的記錄:
1. 打開Hasura Console界面的Api Explorer標簽:

2. 查詢全部用戶:
query {
users {
id
name
age
city
}
}
3.最后,確認輸出如下:
{
"data": {
"users": [
{
"id": 1,
"name": "John",
"age": 35,
"city": "Austin"
},
{
"id": 2,
"name": "Mark",
"age": 36,
"city": "Seattle"
}
]
}
}
更新數據
最后,來確認一下我們的GraphQL API能夠順利處理寫入問題。
1. 使用以下的GraphQL變種語法,添加一條消息記錄到數據庫里:
mutation {
insert_messages_one(object: {recipient_id: 2, sender_id: 1, payload: "Hi, Mark! How are you doing?"}) {
id
}
}
2.從YugabyteDB反向讀取消息:
query {
messages {
payload
userBySenderId {
name
city
}
user {
name
city
}
}
}
3.確認輸出如下:
{
"data": {
"messages": [
{
"payload": "Hi, Mark! How are you doing?",
"userBySenderId": {
"name": "John",
"city": "Austin"
},
"user": {
"name": "Mark",
"city": "Seattle"
}
}
]
}
}
結論
正如我們在這篇文章里所看到的,正確地融合現代的云原生服務,可以搭建一個水平可擴展和一個高可用的GraphQL API層。
在幾分鐘的時間里,我們已經得到一個可以處理請求增加的API層,并把它的容積能力從10GB擴展到100GB,甚至更大的容量。此外,最重要的是,它能夠持續服務應用的請求,哪怕突發區域級別故障也可以做到。
最后,如果你的GraphQL API層需要跨多個云片區工作,并能實現片區級別的突發狀況容錯,那么你仍然可以使用Hasura和YugabyteDB。目前,這項能力可在自管理安裝選項中獲取(可參考 ??YugabyteDB的多區域部署??)。
相信在不久的將來,它也會往完全管理版本的技術方向發展。
譯者介紹
譚劍,畢業于廣東財經大學,現自主創業。喜歡編程、外語、閱讀。
原文標題:??How To Set Up a Scalable and Highly-Available GraphQL API in Minutes??,作者:Denis Magda