













在Scaling Transformers用稀疏性就足夠了!我們以后或許能在筆記本電腦上托管 GPT-3
本文轉自雷鋒網,如需轉載請至雷鋒網官網申請授權。
1.Scaling Transformers:讓大型語言模型更易于管理
近年來,基于Transformer架構的大型神經網絡,自然語言處理領域取得了巨大的進步。前幾年在Reddit上發布大量灌水貼的thegentlemetre賬號一周后才被人類發覺:這竟然是一個應用程序在“作怪”!它正是以被稱為地表最強的語言模型GPT-3為基礎開發的程序。
GPT-3作為一個大型語言模型,可以創作出整篇文章,即使把這些文章和人類寫的文章相比較的話,都很難被區分出來。
但是這種“聰明”的模型卻有一個弊端。
因為它的訓練成本極高,不是每個人都有資源來訓練這種大型模型。
那么如何讓大型語言模型更易于管理以適用日常需要呢?
華沙大學,谷歌研究和OpenAI的學者們提出一個新的模型族-Scaling Transformers。

論文地址:https://arxiv.org/abs/2111.12763
文章提出了一種通過稀疏化網絡中線性層的激活(前饋和 Q、K、V 投影)來訓練大規模稀疏模型的方法。該方法特別吸引人,因為它似乎不需要任何特定于硬件或低級別的優化即可有效。控制器網絡在激活時生成一個塊式 one-hot 掩碼,并根據此掩碼動態選擇后續層的權重。當擴大模型大小時,用稀疏層來有效擴展并執行非批次解碼的速度比標準Transformer模型快的多。在參數數量相同的情況下,稀疏層足以獲得與標準Transformer相同的困惑度。
2.文章解讀
Fabio Chiusano在NLP上發表了對這篇論文的正面評價。Fabio Chiusano是Digitiamo 數據科學主管,也是人工智能領域的頂級媒體作家。AI科技評論對Chiusano的點評做了不改原意的整理:
Scaling Transformer 真的很有趣,因為當我們擴大模型大小時,它們允許有效地縮放語言模型并且比標準 Transformer 更快地執行非批處理解碼。嚴謹地說:
- 我們稱其?
?d?? 為 Transformer 模型的參數個數。 - 然后,一個標準的密集 Transformer 將需要近似?
?d^2??計算來進行預測。 - 相反,稀疏的 Scaling Transformer 將需要近似?
?d^1.5??計算。
如果說這樣的改進看起來不明顯,請考慮一下這??d??通常是一個非常高的數字,大約數十億,實際上實驗表明,Scaling Transformer 為單個令牌帶來了近 20 倍的預測加速(從 3.690s 到 0.183 s) 關于具有 17B 個參數的密集 Transformer。注意:這些加速是針對未批量預測的。
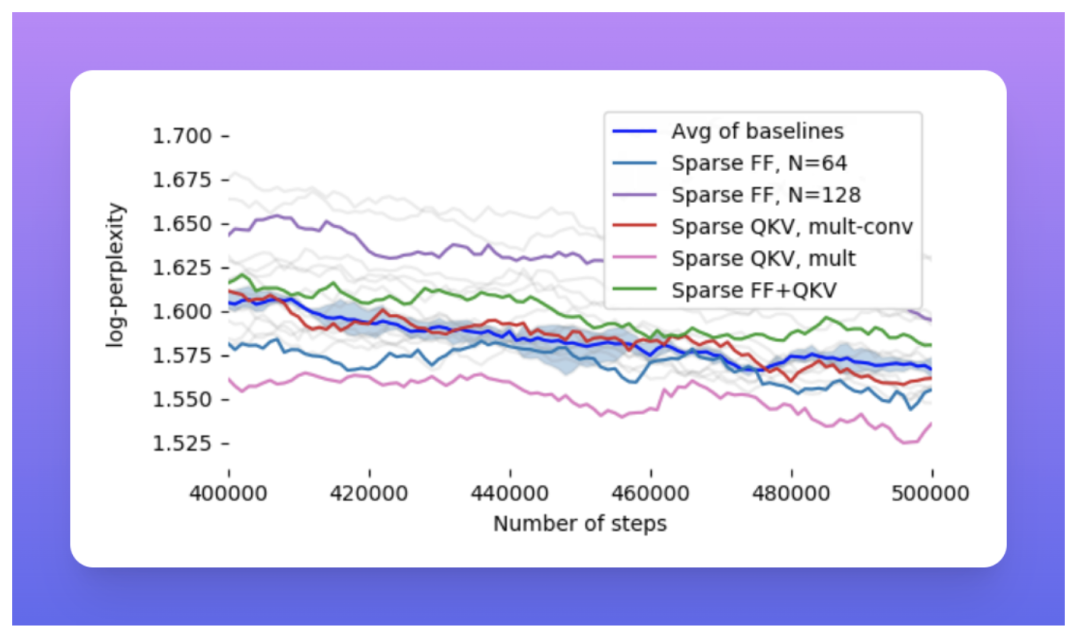
在具有建議的稀疏機制(FF、QKV、FF+QKV)的 C4 數據集上,Scaling Transformers(相當于 T5 大小,具有大約 800M 參數)的對數困惑度類似于基線密集模型。
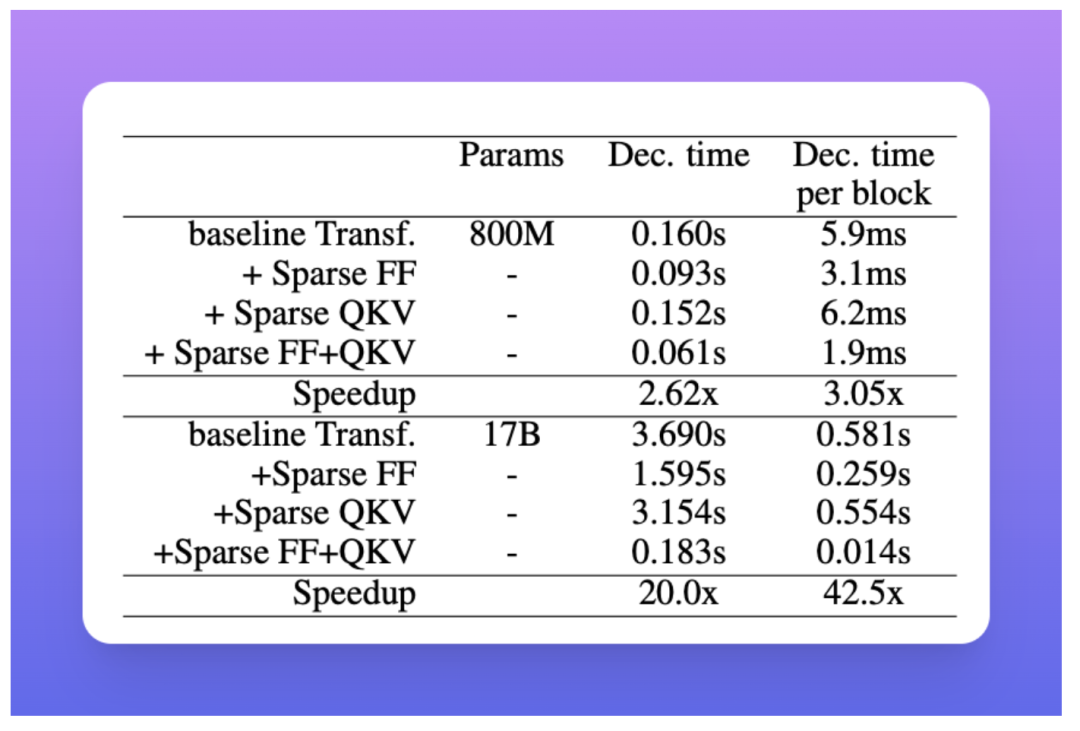
具有 17B 參數的 Terraformer 的單個令牌的解碼速度比密集基線模型快 37 倍,推理所需的時間少于 100 毫秒/令牌。這里注意力稀疏 = 64,ff-稀疏 = 256,損失稀疏 = 4
稀疏化的收益非常好。然而,當解碼較長的序列時,它們會更糟,因為解碼時間將由注意力操作控制。
幸運的是,已經提出了許多方法來解決 Transformer 的這個問題,例如LSH(Locality-Sensitive Hashing)注意處理長序列和可逆層以提高內存效率。我會說這不是個微不足道的結果!
這篇論文還對用于提高 Transformer 效率的其他技術進行了有趣的概述。我在這里報告了它的一些摘錄,我認為它可以作為那些不熟悉 Transformer 技術效率的人的參考。
- 模型壓縮。模型修剪通過在訓練之后或訓練期間移除不需要的權重來使矩陣更小。
- 模型蒸餾。模型蒸餾包括在先前訓練的大模型(即教師)的輸出上訓練一個小模型(即學生)。用于移動推理的幾種自然語言模型依靠蒸餾來加速從預先訓練的大型模型中進行推理。
- 稀疏注意力。基于稀疏注意力的方法通過合并額外的組合機制或選擇該層所關注的標記子集,使注意力層更加高效,尤其是對于長序列。
- 稀疏前饋。關鍵思想是將前饋層劃分為多個部分(稱為專家),每個令牌只檢索一個部分,這降低了前饋塊的復雜性。這些加速主要以訓練速度來衡量,并且該方法側重于前饋塊。專家方法的混合已被證明可以在訓練中實現計算效率,擴展到一萬億個參數。
雖然目前的結果有許多局限性。盡管如此,這篇論文可以被認為是通往可持續大型模型的第一步。
大家怎么看?












